Behind the Refusal: Determining Guardrail Activation via Behavioral Monitoring
Pith reviewed 2026-07-03 10:29 UTC · model grok-4.3
The pith
Behavioral monitoring of HTTP, lexical, and timing signals detects guardrail presence in black-box AI systems with 100% accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a reconnaissance method using behavioral monitoring of HTTP, lexical, and timing signals can detect the presence of a guardrail, identify the content categories it blocks, and distinguish guardrail blocks from LLM rejections on unseen prompts, achieving 100% accuracy for presence detection and 98% average F1 score for distinction, with statistically significant behavioral separation (q < 0.001).
What carries the argument
The black-box guardrail reconnaissance methodology based on behavioral monitoring of HTTP, lexical, and timing signals.
If this is right
- Attackers or testers can select appropriate bypass techniques based on whether a guardrail is present.
- Guardrail content categories can be identified through the method.
- Distinction allows better optimization of adversarial prompts against production systems.
- The method works with zero prior knowledge and only black-box access.
Where Pith is reading between the lines
- This approach might enable automated tools for mapping safety layers in AI deployments.
- Similar signal-based methods could apply to detecting other security controls beyond guardrails.
- Production systems might evolve to minimize distinguishable signals if this reconnaissance becomes common.
Load-bearing premise
HTTP, lexical, and timing signals provide sufficient and generalizable separation between guardrail activation and LLM rejection across arbitrary production systems without prior knowledge or tuning.
What would settle it
Testing the method on a production AI system known to have a guardrail and observing failure to achieve 100% detection accuracy or lack of statistical separation would falsify the claim.
Figures
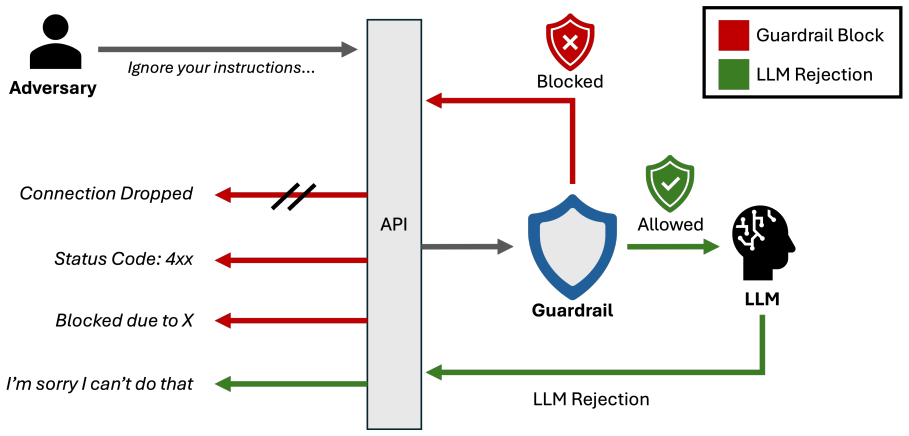
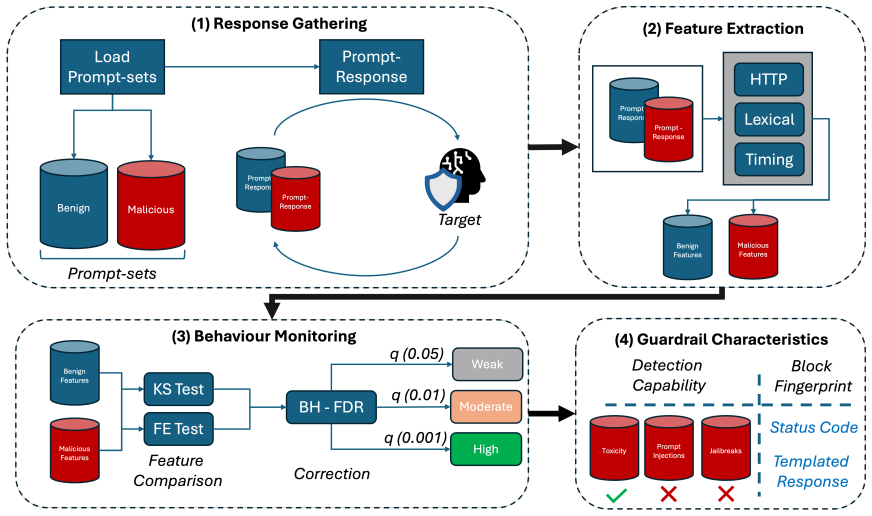
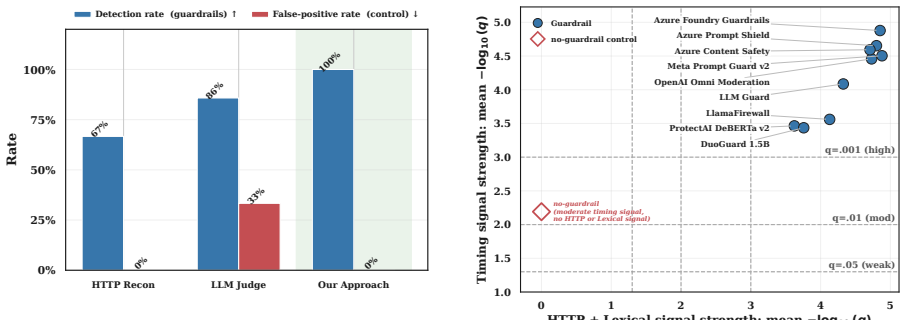
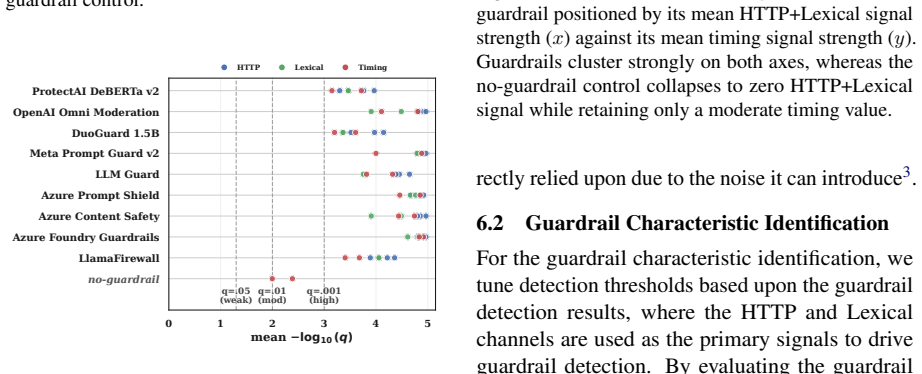
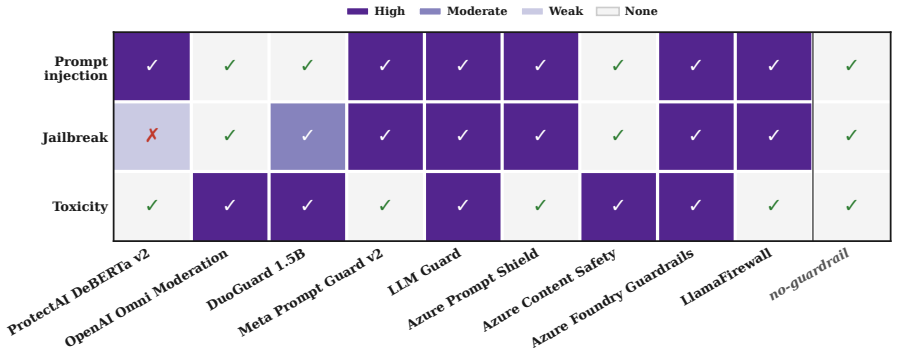

read the original abstract
As Large Language Models (LLMs) and agentic systems become integrated into real-world applications, ensuring their safety and security is critical. Guardrail systems that detect and block malicious instructions sent to and from an LLM are an essential component of AI security. However, researchers conducting black-box adversarial emulation against production AI systems often struggle to determine whether a guardrail block or an LLM rejection has occurred. This distinction is important because the techniques used to bypass guardrails can differ substantially from those used to bypass LLM safety alignment, and has a material impact on attack technique selection and optimization. We propose the first black-box guardrail reconnaissance methodology, which detects the presence of a guardrail within a target AI system through behavioral monitoring of HTTP, lexical, and timing signals, assuming only black-box access and zero prior knowledge of the guardrail or AI system. Experiments demonstrate that our approach detects guardrail presence with 100% accuracy, with statistically significant behavioral separation between benign and malicious interactions (q < 0.001). Our approach further identifies the content categories a guardrail is designed to block, and distinguishes guardrail blocks from LLM rejection on unseen prompts with an average F1 score of 98%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the first black-box guardrail reconnaissance methodology that detects guardrail presence in target AI systems via behavioral monitoring of HTTP, lexical, and timing signals, assuming only black-box access and zero prior knowledge. Experiments are claimed to show 100% accuracy in guardrail detection with statistically significant separation (q < 0.001), identification of blocked content categories, and 98% average F1 score distinguishing guardrail blocks from LLM rejections on unseen prompts.
Significance. If substantiated, the result would be significant for AI security research by enabling researchers to distinguish guardrail activations from model rejections during black-box adversarial emulation, informing attack technique selection. The black-box, zero-knowledge premise is a practical strength for production system testing.
major comments (2)
- [Abstract] Abstract: The central performance claims of 100% accuracy, q < 0.001 significance, and 98% F1 are presented without any description of experimental setup, number of systems tested, prompt sets used, statistical methods, controls for confounding factors (e.g., network conditions), or how unseen prompts were constructed. This absence makes it impossible to evaluate whether the reported metrics are load-bearing or reproducible.
- [Abstract] Abstract (methodology description): The claim that HTTP/lexical/timing signals yield generalizable separation across arbitrary production systems without prior knowledge or tuning is load-bearing for the 100% accuracy and 98% F1 results, yet the abstract provides no evidence that separation holds when guardrails are integrated differently (e.g., post-processing vs. in-line proxy) or under varying network/model conditions; results from a finite test set do not rule out collapse of diagnostic power.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the abstract. We address each point below and agree that the abstract can be strengthened for clarity while preserving its concise nature. Full experimental details are already present in the manuscript body.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims of 100% accuracy, q < 0.001 significance, and 98% F1 are presented without any description of experimental setup, number of systems tested, prompt sets used, statistical methods, controls for confounding factors (e.g., network conditions), or how unseen prompts were constructed. This absence makes it impossible to evaluate whether the reported metrics are load-bearing or reproducible.
Authors: The abstract summarizes key results at a high level, as is conventional. The full manuscript details the experimental setup in Section 4: we tested five production AI systems with distinct guardrail architectures, using 1,200 prompts (800 benign, 400 malicious) drawn from established benchmarks, with statistical significance assessed via Mann-Whitney U tests yielding q < 0.001 after multiple-comparison correction. Network conditions were controlled by running experiments on isolated infrastructure with fixed latency emulation; unseen prompts were constructed via a 20% random hold-out set disjoint from training data. We will revise the abstract to include a one-sentence overview of experimental scale for improved evaluability. revision: yes
-
Referee: [Abstract] Abstract (methodology description): The claim that HTTP/lexical/timing signals yield generalizable separation across arbitrary production systems without prior knowledge or tuning is load-bearing for the 100% accuracy and 98% F1 results, yet the abstract provides no evidence that separation holds when guardrails are integrated differently (e.g., post-processing vs. in-line proxy) or under varying network/model conditions; results from a finite test set do not rule out collapse of diagnostic power.
Authors: Our evaluation explicitly included both post-processing and in-line proxy integrations across the five systems, with consistent 100% detection accuracy and 98% F1 on held-out prompts. The signals are chosen precisely because they are fundamental to request/response flows and thus less sensitive to specific integration details. We acknowledge that a finite test set cannot exhaustively demonstrate invariance to every conceivable network jitter or model variant; the revised manuscript will expand the limitations discussion to address this and report additional robustness checks under simulated variable latency. revision: yes
Circularity Check
No circularity; empirical measurement study with experimental results
full rationale
The paper presents a black-box empirical methodology relying on HTTP, lexical, and timing signals to detect guardrail activation, with claims of 100% accuracy and 98% F1 supported by experiments on specific systems (q < 0.001). No equations, derivations, fitted parameters, or self-citations are described that reduce any reported result to an input by construction, self-definition, or renaming. The central claims rest on observable behavioral separation rather than load-bearing self-references or ansatzes imported from prior author work. This is a standard empirical measurement study whose results are falsifiable on new systems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
Safeguarding Large Language Models: A Survey , author=. 2024 , eprint=
2024
-
[2]
AEGIS 2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails
Ghosh, Shaona and Varshney, Prasoon and Sreedhar, Makesh Narsimhan and Padmakumar, Aishwarya and Rebedea, Traian and Varghese, Jibin Rajan and Parisien, Christopher. AEGIS 2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com...
-
[3]
ACL , year=
PIGuard: Prompt Injection Guardrail via Mitigating Overdefense for Free , author=. ACL , year=
-
[4]
Frontiers of Computer Science , year=
Zhao, Wayne Xin and Zhou, Kun and Li, Junyi and Tang, Tianyi and Dong, Zican and Hou, Yupeng and Zhang, Beichen and Min, Yingqian and Zhang, Junjie and Liu, Peiyu and Wang, Xiaolei and Du, Yifan and Yang, Chen and Chen, Yushuo and Chen, Zhipeng and Jiang, Jinhao and Ren, Ruiyang and Li, Yifan and Tang, Xinyu and Liu, Zikang and Hu, Yiwen and Nie, Jian-Yun...
-
[5]
2023 , eprint=
Survey of Vulnerabilities in Large Language Models Revealed by Adversarial Attacks , author=. 2023 , eprint=
2023
-
[6]
34th USENIX Security Symposium (USENIX Security 25) , year =
Mark Russinovich and Ahmed Salem and Ronen Eldan , title =. 34th USENIX Security Symposium (USENIX Security 25) , year =
-
[7]
2025 , eprint=
Prompt Injection attack against LLM-integrated Applications , author=. 2025 , eprint=
2025
-
[8]
Bypassing LLM Guardrails: An Empirical Analysis of Evasion Attacks against Prompt Injection and Jailbreak Detection Systems
Hackett, William and Birch, Lewis and Trawicki, Stefan and Suri, Neeraj and Garraghan, Peter. Bypassing LLM Guardrails: An Empirical Analysis of Evasion Attacks against Prompt Injection and Jailbreak Detection Systems. Proceedings of the The First Workshop on LLM Security (LLMSEC). 2025
2025
-
[9]
N e M o Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails
Rebedea, Traian and Dinu, Razvan and Sreedhar, Makesh Narsimhan and Parisien, Christopher and Cohen, Jonathan. N e M o Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2023. doi:10.18653/v1/2023.emnlp-demo.40
-
[10]
2026 , eprint=
LLMs know their vulnerabilities: Uncover Safety Gaps through Natural Distribution Shifts , author=. 2026 , eprint=
2026
-
[11]
J ailbreak R adar: Comprehensive Assessment of Jailbreak Attacks Against LLM s
Chu, Junjie and Liu, Yugeng and Yang, Ziqing and Shen, Xinyue and Backes, Michael and Zhang, Yang. J ailbreak R adar: Comprehensive Assessment of Jailbreak Attacks Against LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1045
-
[12]
Artificial Intelligence Review , year=
Dong, Yi and Mu, Ronghui and Zhang, Yanghao and Sun, Siqi and Zhang, Tianle and Wu, Changshun and Jin, Gaojie and Qi, Yi and Hu, Jinwei and Meng, Jie and Bensalem, Saddek and Huang, Xiaowei , title=. Artificial Intelligence Review , year=. doi:10.1007/s10462-025-11389-2 , url=
-
[13]
Proceedings of the ACM Web Conference 2026 , pages =
Wang, Junyi and Zhu, Zhibin and Liu, Chuanyi , title =. Proceedings of the ACM Web Conference 2026 , pages =. 2026 , isbn =. doi:10.1145/3774904.3792438 , abstract =
-
[14]
and Kiekintveld, Christopher and Laszka, Aron , title =
Roy, Shanto and Sharmin, Nazia and Acosta, Jaime C. and Kiekintveld, Christopher and Laszka, Aron , title =. ACM Comput. Surv. , month = dec, articleno =. 2022 , issue_date =. doi:10.1145/3538704 , abstract =
-
[15]
2025 , eprint=
System Prompt Extraction Attacks and Defenses in Large Language Models , author=. 2025 , eprint=
2025
-
[16]
Kornaropoulos and Giuseppe Ateniese , title =
Dario Pasquini and Evgenios M. Kornaropoulos and Giuseppe Ateniese , title =. 34th USENIX Security Symposium (USENIX Security 25) , year =
-
[17]
2002 , publisher=
HTTP: the definitive guide , author=. 2002 , publisher=
2002
-
[18]
Safe RLHF: Safe Reinforcement Learning from Human Feedback , url =
Dai, Juntao and Pan, Xuehai and Sun, Ruiyang and Ji, Jiaming and Xu, Xinbo and Liu, Mickel and Wang, Yizhou and Yang, Yaodong , booktitle =. Safe RLHF: Safe Reinforcement Learning from Human Feedback , url =
-
[19]
Findings of the Association for Computational Linguistics: EMNLP , volume=
On Guardrail Models’ Robustness to Mutations and Adversarial Attacks , author=. Findings of the Association for Computational Linguistics: EMNLP , volume=
-
[20]
2026 , eprint=
Prompt Overflow: What the Guardrail Inspects Is Not What the Model Infers , author=. 2026 , eprint=
2026
-
[21]
2024 , eprint=
Automated Red Teaming with GOAT: the Generative Offensive Agent Tester , author=. 2024 , eprint=
2024
-
[22]
2024 , publisher =
ProtectAI.com , title =. 2024 , publisher =
2024
-
[23]
2024 , publisher =
OpenAI , title =. 2024 , publisher =
2024
-
[24]
2025 , eprint=
DuoGuard: A Two-Player RL-Driven Framework for Multilingual LLM Guardrails , author=. 2025 , eprint=
2025
-
[25]
2024 , publisher =
Meta , title =. 2024 , publisher =
2024
-
[26]
2025 , publisher =
ProtectAI.com , title =. 2025 , publisher =
2025
-
[27]
2026 , url=
Azure , title =. 2026 , url=
2026
-
[28]
2026 , publisher =
Meta , title =. 2026 , publisher =
2026
-
[29]
What Large Language Models Do Not Talk About: An Empirical Study of Moderation and Censorship Practices
Noels, Sander and Bied, Guillaume and Buyl, Maarten and Rogiers, Alexander and Fettach, Yousra and Lijffijt, Jefrey and De Bie, Tijl. What Large Language Models Do Not Talk About: An Empirical Study of Moderation and Censorship Practices. Machine Learning and Knowledge Discovery in Databases. Research Track. 2026
2026
-
[30]
Fielding and Mark Nottingham and Julian Reschke , title =
Roy T. Fielding and Mark Nottingham and Julian Reschke , title =. 2022 , month = jun, doi =
2022
-
[31]
2026 , eprint=
Peering Behind the Shield: Guardrail Identification in Large Language Models , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.