Geometric Signatures of Reasoning: A Spectral Perspective on Task Hardness
Pith reviewed 2026-07-03 17:34 UTC · model grok-4.3
The pith
Reasoning trajectories with flatter eigenvalue spectra correspond to harder tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
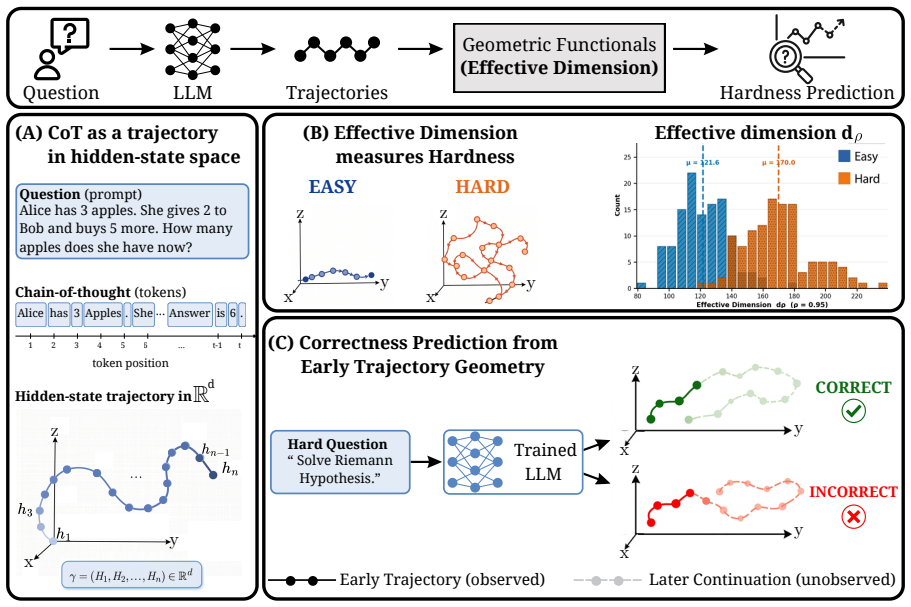
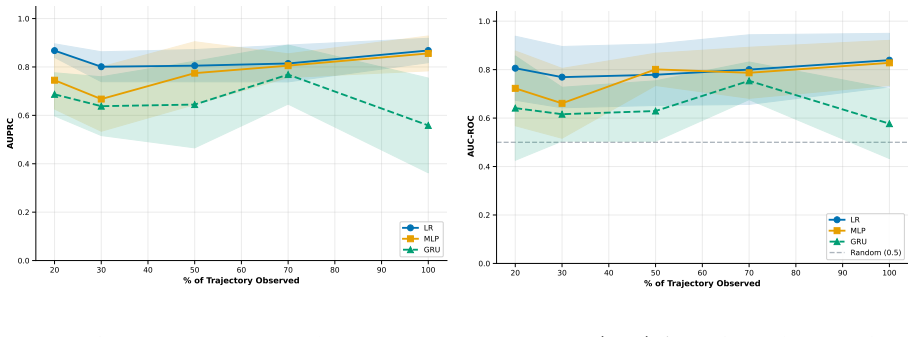
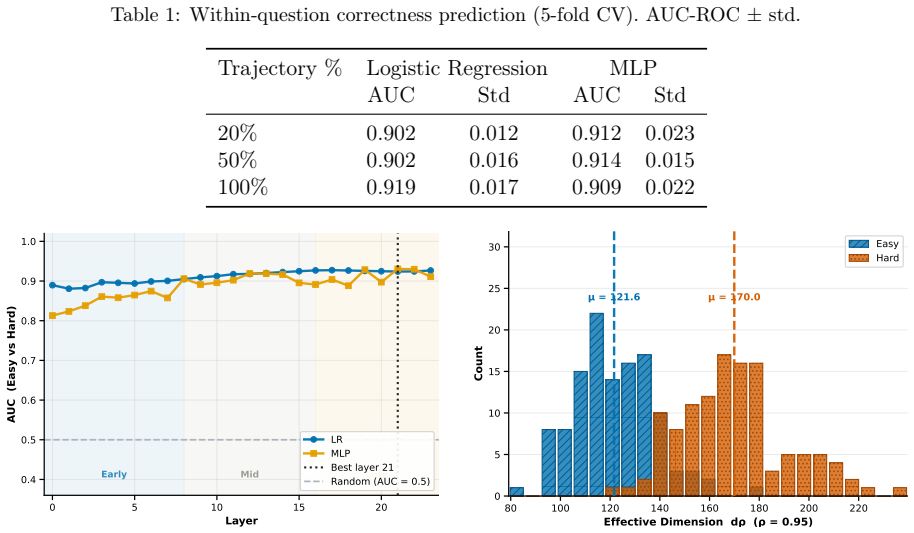
By formalizing each chain-of-thought sequence as a discrete curve in hidden-state space, the authors show that the eigenvalue spectrum of its covariance matrix yields an effective dimension d_ρ whose value tracks task hardness: flatter spectra (higher d_ρ) arise on harder problems because the trajectory explores more hidden dimensions. On the MATH500 benchmark this scalar distinguishes easy from hard problems at 0.93 AUC, while kinematic statistics (mean position, velocity, speed dispersion) extracted from the first 20 % of tokens already predict final correctness, and these signatures transfer across questions of varying difficulty.
What carries the argument
The effective dimension d_ρ derived from the eigenvalue spectrum of the trajectory covariance matrix in hidden state space.
If this is right
- Harder tasks produce trajectories that occupy a larger effective subspace of the hidden dimensions.
- Kinematic features computed early in generation can be used to decide whether to continue or stop before the full answer is produced.
- The geometric shape of an internal reasoning path supplies an intrinsic signal for both hardness and correctness that does not rely on surface features of the question.
- Correctness signatures observed on one difficulty level generalize to questions of other difficulties within the same model.
Where Pith is reading between the lines
- If the spectral measure generalizes, it could supply a model-agnostic way to rank problem difficulty without reference to human labels.
- Early trajectory monitoring might be combined with existing decoding strategies to improve efficiency on long reasoning chains.
- The same geometric lens could be applied to non-mathematical generation tasks to test whether spectral flatness likewise tracks difficulty.
- Connections between trajectory geometry and dynamical systems in recurrent networks remain open for further exploration.
Load-bearing premise
The effective dimension d_ρ extracted from the trajectory spectrum is assumed to be a faithful, non-circular indicator of task hardness that holds beyond the MATH500 set and the models tested.
What would settle it
Finding that d_ρ no longer separates easy from hard problems when the same analysis is run on a new benchmark or a different model family would falsify the central claim.
Figures
read the original abstract
Chain-of-thought (CoT) reasoning enables large language models (LLMs) to solve complex problems by generating intermediate reasoning steps. While much attention has been paid to the length and content of these reasoning chains, far less is known about their internal geometry. We study the \emph{geometry} of CoT trajectories in the hidden state space of transformer models, formalizing each reasoning chain as a discrete curve in $\mathbb{R}^d$ and characterizing it through spectral, positional, and kinematic geometric functionals. We introduce the effective dimension $d_\rho$ as a measure of trajectory complexity and show theoretically that trajectories with flatter eigenvalue spectra correspond to harder tasks, as they explore more of the hidden dimensions. Lastly, we explore how kinematic features of the trajectory, mean position, positional dispersion, initial and current hidden states, mean velocity, mean speed, and speed dispersion, can be used to predict solution correctness before generation is complete, and may inform future early-stopping strategies. Experimentally, on mathematical reasoning problems from the MATH500 dataset, $d_\rho$ achieves $0.93$ AUC in distinguishing easy from hard problems, while kinematic features potentially can predict correctness from only the first $20\%$ of generated tokens. These correctness signatures transfer across questions of varying difficulty, establishing that the shape of a model's internal reasoning trajectory is a principled window into both task hardness and solution quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes chain-of-thought reasoning trajectories as discrete curves in the hidden-state space of transformers and introduces spectral, positional, and kinematic functionals to characterize them. It defines an effective dimension d_ρ derived from the eigenvalue spectrum of the trajectory covariance and claims a theoretical link showing that flatter spectra correspond to harder tasks because they explore more hidden dimensions. Empirically, on the MATH500 dataset, d_ρ distinguishes easy from hard problems with 0.93 AUC, while kinematic features (mean position, velocity, speed dispersion, etc.) are shown to predict solution correctness from only the first 20% of generated tokens, with signatures that transfer across difficulty levels.
Significance. If the non-circularity of d_ρ and the theoretical derivation can be established, the work supplies a geometric lens on internal reasoning dynamics that could support early-stopping strategies and finer-grained analysis of LLM problem-solving. The reported transfer of kinematic predictors across difficulty levels and the high AUC on a standard benchmark are potentially useful contributions, though the absence of derivation details, error bars, and baseline comparisons in the presented material limits immediate assessment of robustness.
major comments (3)
- [Abstract / Theory] Abstract and theory section: the claim that trajectories with flatter eigenvalue spectra correspond to harder tasks is presented without any derivation details, explicit definition of the covariance matrix whose spectrum is used, or proof that d_ρ is independent of the hardness labeling procedure; this directly affects the central theoretical contribution.
- [Experiments] Experimental results: the 0.93 AUC for d_ρ on MATH500 is reported without error bars, baseline comparisons (e.g., against trajectory length, token entropy, or standard difficulty proxies), or information on how d_ρ is exactly computed (eigenvalue threshold, normalization, data exclusions); these omissions make it impossible to evaluate whether the measure is load-bearing or circular.
- [Experiments] Kinematic prediction experiments: the claim that correctness can be predicted from the first 20% of tokens relies on kinematic features whose definitions (mean velocity, speed dispersion) are not shown to be computed on held-out data or shown to be non-redundant with the spectral measure; this weakens the early-stopping implication.
minor comments (2)
- [Abstract] Notation for d_ρ and the eigenvalue spectrum should be introduced with an explicit equation rather than left implicit in the abstract.
- [Methods] The manuscript should clarify whether the same trajectory data used to label hardness is also used to compute d_ρ, to address potential definitional overlap.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on the manuscript. We address each major comment below and will incorporate the requested clarifications and additions in the revised version.
read point-by-point responses
-
Referee: [Abstract / Theory] Abstract and theory section: the claim that trajectories with flatter eigenvalue spectra correspond to harder tasks is presented without any derivation details, explicit definition of the covariance matrix whose spectrum is used, or proof that d_ρ is independent of the hardness labeling procedure; this directly affects the central theoretical contribution.
Authors: We agree that the current draft presents the theoretical link at a high level. In the revision we will expand the theory section with: the explicit definition of the covariance matrix as the empirical covariance of hidden states along the trajectory; the precise formula for d_ρ derived from the normalized eigenvalue spectrum; and a short proof that d_ρ is computed solely from the geometry of the hidden-state curve and does not reference any external hardness labels, thereby establishing independence. revision: yes
-
Referee: [Experiments] Experimental results: the 0.93 AUC for d_ρ on MATH500 is reported without error bars, baseline comparisons (e.g., against trajectory length, token entropy, or standard difficulty proxies), or information on how d_ρ is exactly computed (eigenvalue threshold, normalization, data exclusions); these omissions make it impossible to evaluate whether the measure is load-bearing or circular.
Authors: We will add error bars via bootstrapping over MATH500 problems, baseline comparisons against trajectory length, token entropy, and dataset difficulty proxies, and full computational details: covariance normalized by trace, d_ρ defined as the count of eigenvalues exceeding 1% of the largest after normalization, with no exclusions beyond trajectories shorter than five tokens. These changes will allow direct assessment of robustness and non-circularity. revision: yes
-
Referee: [Experiments] Kinematic prediction experiments: the claim that correctness can be predicted from the first 20% of tokens relies on kinematic features whose definitions (mean velocity, speed dispersion) are not shown to be computed on held-out data or shown to be non-redundant with the spectral measure; this weakens the early-stopping implication.
Authors: Kinematic features are computed exclusively on the partial trajectories from the first 20% of tokens. The revision will state that all classifiers use 5-fold cross-validation on held-out problems and will add an ablation demonstrating that the kinematic feature set improves accuracy beyond d_ρ alone. Explicit definitions of mean velocity (average consecutive hidden-state difference) and speed dispersion (standard deviation of instantaneous speeds) will also be supplied. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract presents d_ρ as derived from the eigenvalue spectrum of CoT trajectories in hidden state space and claims a theoretical link to task hardness (flatter spectra explore more dimensions). Hardness labels for the 0.93 AUC evaluation on MATH500 and correctness labels for kinematic prediction appear to be external dataset properties, not constructed from the spectral or kinematic quantities themselves. No equations, self-citations, or fitted-input reductions are quoted or visible in the supplied text that would make the central claims equivalent to their inputs by definition. The derivation is therefore treated as self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Chain of thought empowers transformers to solve inherently serial problems , author=. International Conference on Learning Representations , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Measuring Faithfulness in Chain-of-Thought Reasoning
Measuring faithfulness in chain-of-thought reasoning , author=. arXiv preprint arXiv:2307.13702 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
2020 , url=
nostalgebraist , title=. 2020 , url=
2020
-
[6]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2401.06102 , year=
Patchscopes: A unifying framework for inspecting hidden representations of language models , author=. arXiv preprint arXiv:2401.06102 , year=
-
[8]
arXiv preprint arXiv:2209.02535 , year=
Analyzing transformers in embedding space , author=. arXiv preprint arXiv:2209.02535 , year=
-
[9]
arXiv preprint arXiv:2406.02060 , year=
I've got the ``Answer''! Interpretation of LLMs Hidden States in Question Answering , author=. arXiv preprint arXiv:2406.02060 , year=
-
[10]
arXiv preprint arXiv:2511.04527 , year=
Are language models aware of the road not taken? Token-level uncertainty and hidden state dynamics , author=. arXiv preprint arXiv:2511.04527 , year=
-
[11]
Conference on Learning Theory , pages=
Implicit regularization for deep neural networks driven by an Ornstein-Uhlenbeck like process , author=. Conference on Learning Theory , pages=. 2020 , organization=
2020
-
[12]
Neural Networks , volume=
Anomalous diffusion dynamics of learning in deep neural networks , author=. Neural Networks , volume=. 2022 , publisher=
2022
-
[13]
Biological Cybernetics , volume=
The Ornstein-Uhlenbeck process as a model for neuronal activity , author=. Biological Cybernetics , volume=. 1979 , publisher=
1979
-
[14]
Psychological Research , volume=
The Ornstein-Uhlenbeck model for decision time in cognitive tasks , author=. Psychological Research , volume=. 2000 , publisher=
2000
-
[15]
Advances in Neural Information Processing Systems , volume=
Diffusion of Thoughts: Chain-of-Thought Reasoning in Diffusion Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models , author=. arXiv preprint arXiv:2505.10446 , year=
-
[17]
Annalen der Physik , volume=
On the movement of small particles suspended in stationary liquids required by the molecular-kinetic theory of heat , author=. Annalen der Physik , volume=
-
[18]
Physics Reports , volume=
The random walk's guide to anomalous diffusion: a fractional dynamics approach , author=. Physics Reports , volume=. 2000 , publisher=
2000
-
[19]
Nature Communications , volume=
Objective comparison of methods to decode anomalous diffusion , author=. Nature Communications , volume=. 2021 , publisher=
2021
-
[20]
Nature Communications , volume=
Bayesian deep learning for error estimation in the analysis of anomalous diffusion , author=. Nature Communications , volume=. 2022 , publisher=
2022
-
[21]
2009 , series=
Mathematical Methods for Financial Markets , author=. 2009 , series=
2009
-
[22]
International Conference on Learning Representations , year=
What learning algorithm is in-context learning? Investigations with linear models , author=. International Conference on Learning Representations , year=
-
[23]
2021 , url=
A mathematical framework for transformer circuits , author=. 2021 , url=
2021
-
[24]
Advances in Neural Information Processing Systems , volume=
What can transformers learn in-context? A case study of simple function classes , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
Advances in Neural Information Processing Systems , volume=
Measuring mathematical problem solving with the MATH dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
arXiv preprint arXiv:2510.03605 , year=
Understanding the role of training data in test-time scaling , author=. arXiv preprint arXiv:2510.03605 , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
Large language models are zero-shot reasoners , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
International Conference on Machine Learning , pages=
Similarity of neural network representations revisited , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[29]
International Conference on Machine Learning , year=
Emergence of separable manifolds in deep language representations , author=. International Conference on Machine Learning , year=
-
[30]
Inequalities: Theory of Majorization and Its Applications , author=
-
[31]
2024 , url=
Learning to reason with LLMs , author=. 2024 , url=
2024
-
[32]
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Advances in Neural Information Processing Systems , volume=
SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
arXiv preprint , year=
Scaling LLM test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint , year=
-
[35]
International Conference on Machine Learning , year=
Transformers learn in-context by gradient descent , author=. International Conference on Machine Learning , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
arXiv preprint arXiv:2406.16838 , year=
From decoding to meta-generation: Inference-time algorithms for large language models , author=. arXiv preprint arXiv:2406.16838 , year=
-
[38]
arXiv preprint arXiv:2505.00127 , year=
Between underthinking and overthinking: An empirical study of reasoning length and correctness in llms , author=. arXiv preprint arXiv:2505.00127 , year=
-
[39]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
s1: Simple test-time scaling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[40]
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Chain of thought monitorability: A new and fragile opportunity for ai safety , author=. arXiv preprint arXiv:2507.11473 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
LLM Reasoning as Trajectories: Step-Specific Representation Geometry and Correctness Signals
LLM Reasoning as Trajectories: Step-Specific Representation Geometry and Correctness Signals , author=. arXiv preprint arXiv:2604.05655 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Effective Reasoning Chains Reduce Intrinsic Dimensionality
Effective Reasoning Chains Reduce Intrinsic Dimensionality , author=. arXiv preprint arXiv:2602.09276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Advances in neural information processing systems , volume=
Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability , author=. Advances in neural information processing systems , volume=
-
[44]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
arXiv preprint arXiv:2510.09782 , year=
The geometry of reasoning: Flowing logics in representation space , author=. arXiv preprint arXiv:2510.09782 , year=
-
[46]
Steering Language Models With Activation Engineering
Steering language models with activation engineering , author=. arXiv preprint arXiv:2308.10248 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
2011 , doi=
Inequalities: Theory of Majorization and Its Applications , author=. 2011 , doi=
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.