Oversight Has a Capacity: Calibrating Agent Guards to a Subjective, Fatiguing Human
Pith reviewed 2026-06-27 17:08 UTC · model grok-4.3
The pith
Human fatigue turns more oversight into less safety for LLM agent guards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
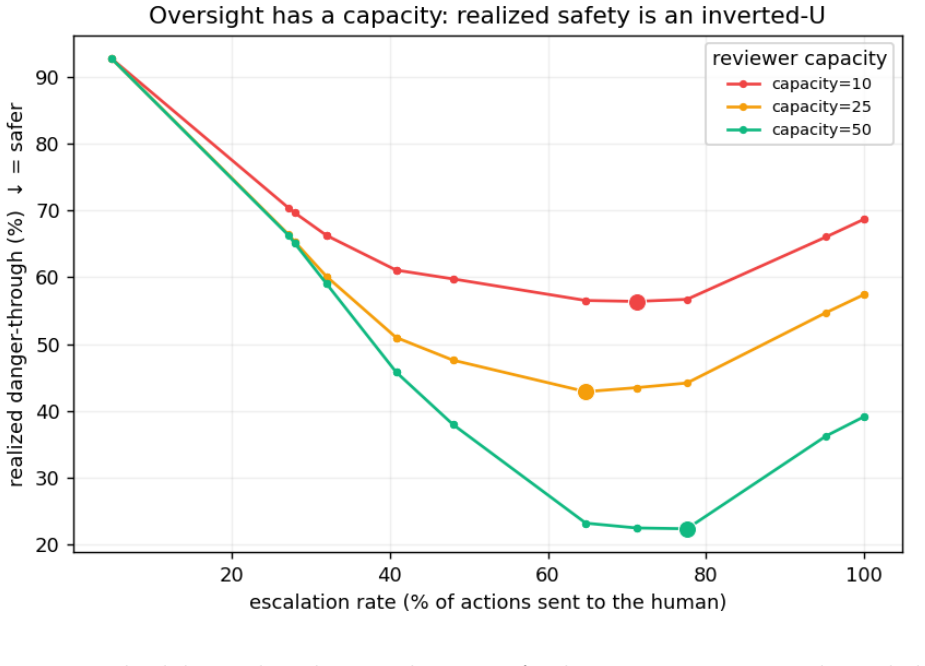
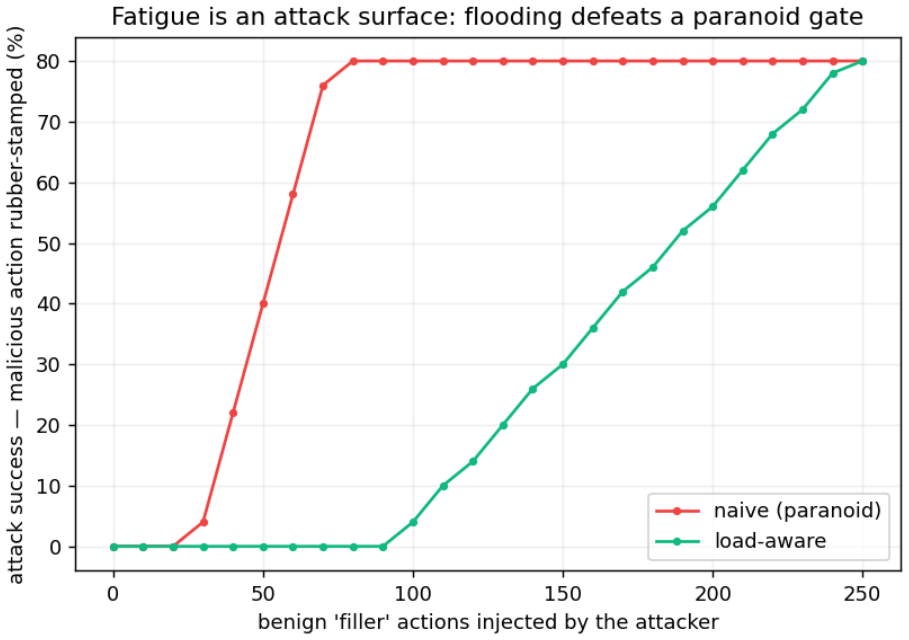
When the reviewer is modeled as endogenous (fatiguing as escalation load grows), realized safety becomes an inverted-U in the escalation rate: more human oversight can make a system less safe, and the safety-optimal guard escalates below full escalation - a setting a load-aware policy also uses to resist a flooding attack that slips a malicious action past a fatigued reviewer.
What carries the argument
Endogenous fatigue model of the human reviewer that converts escalation rate into an inverted-U safety curve under asymmetric-cost selective classification.
If this is right
- The safety-optimal escalation rate lies below full escalation.
- Load-aware escalation policies can resist flooding attacks that exploit reviewer fatigue.
- Agent oversight functions as a resource-allocation problem whose policy spends finite human attention.
- On hard inputs the guard cannot safely auto-decide without human review.
- Moderate reviewer agreement means no single ground-truth risk label exists.
Where Pith is reading between the lines
- Deployment systems could add real-time load monitoring to adjust escalation thresholds dynamically.
- The same capacity-limit logic may apply to other subjective human judgment tasks such as content moderation or medical review.
- The open-source measurement system enables direct comparison of different fatigue models against future human data.
Load-bearing premise
The fatigue model used to generate the inverted-U curve accurately captures how real human reviewers' judgment quality declines with increasing escalation load.
What would settle it
A controlled human study that measures reviewer accuracy on successive batches of agent actions and checks whether the observed accuracy drop produces the predicted inverted-U in overall system safety.
Figures
read the original abstract
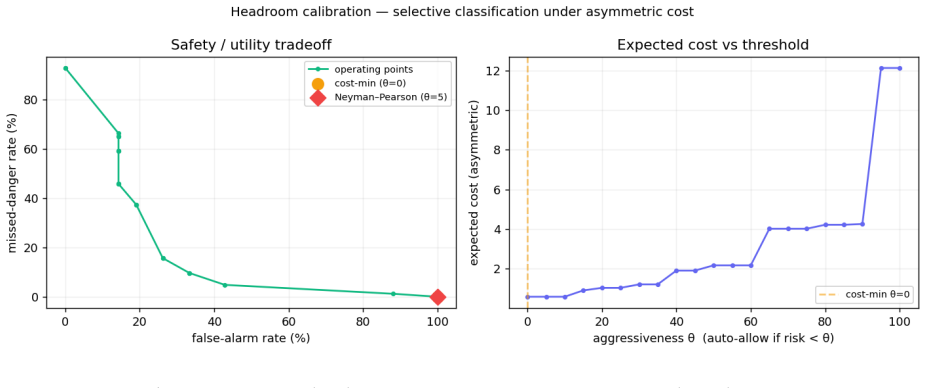
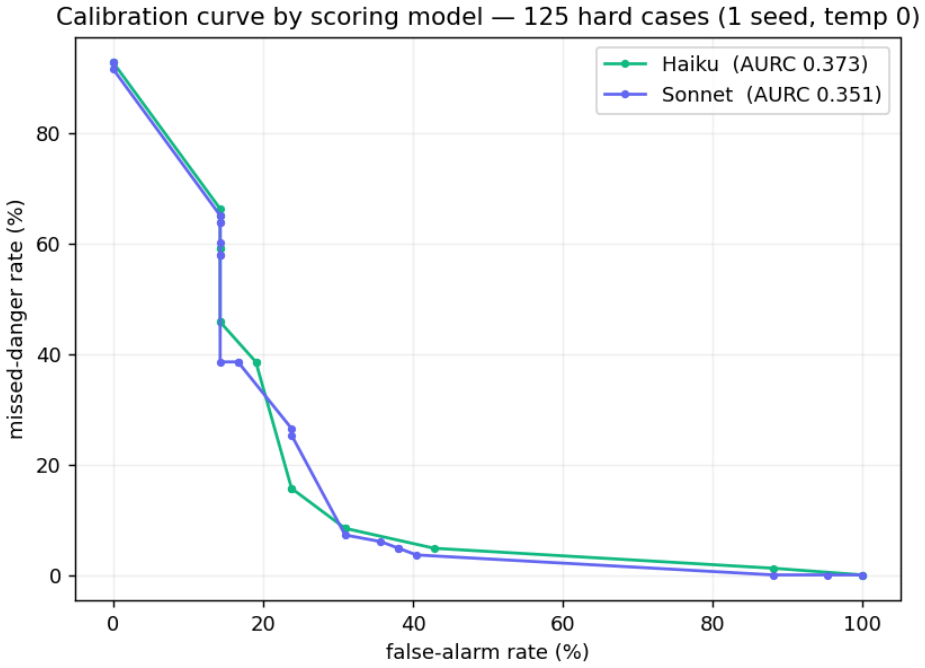
As LLM agents begin to take real, irreversible actions (shell commands, file edits, deploys), the standard safety pattern is a human-in-the-loop approval gate: risky actions pause and wait for a person. We argue the gate is the easy part; the hard part is the judgment - which actions to stop - which the field evaluates against two false assumptions: that there is a ground-truth notion of "risky," and that the human reviewer is a perfect, infinitely-available oracle. On a hand-labeled set of 125 adversarially-weighted agent actions we show that (i) reviewers only moderately agree on what is risky (Fleiss' kappa = 0.52), so there is no single correct label; (ii) framing the guard as selective classification under asymmetric cost makes its operating limits measurable, and on hard inputs the guard cannot safely auto-decide; and (iii) when the reviewer is modeled as endogenous (fatiguing as escalation load grows), realized safety becomes an inverted-U in the escalation rate: more human oversight can make a system less safe, and the safety-optimal guard escalates below full escalation - a setting a load-aware policy also uses to resist a flooding attack that slips a malicious action past a fatigued reviewer. Agent oversight, framed this way, is not only a classification problem but a resource-allocation one: human attention is finite, and the guard's escalation policy spends it. We claim none of these mechanisms as novel - fatigue-aware learning-to-defer (FALCON), cost-sensitive deferral under workload constraints (DeCCaF), trajectory-level guarding, and reviewer-fatigue/flooding attacks are all prior art we cite. Our contribution is an open-source agent-oversight system that operationalizes and measures them in the LLM-agent action-gating setting, turning "is my guard good?" from a guess into a curve. The inverted-U and the flooding attack are modeling results that motivate a human study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that human oversight for LLM agent actions rests on false assumptions of ground-truth risk labels and perfect, infinitely available reviewers. On a hand-labeled set of 125 adversarially-weighted actions, inter-reviewer agreement is only moderate (Fleiss' kappa = 0.52). Framing the guard as selective classification under asymmetric cost shows that hard inputs cannot be safely auto-decided. When the reviewer is modeled as endogenous and fatiguing with growing escalation load, realized safety follows an inverted-U in escalation rate, so that the safety-optimal guard escalates below full escalation; a load-aware policy using this optimum also resists a flooding attack. The contribution is an open-source agent-oversight system that operationalizes these mechanisms (citing but not claiming novelty for FALCON, DeCCaF, etc.) in the LLM-agent gating setting, turning guard evaluation into measurable curves; the inverted-U and flooding results are explicitly modeling outcomes intended to motivate future human studies.
Significance. If the modeling assumptions hold, the result establishes that oversight is a finite-capacity resource-allocation problem rather than a pure classification problem, with the concrete demonstration that increasing escalation can decrease safety. The open-source implementation supplies a reproducible, falsifiable framework for evaluating guards under workload constraints and supplies a modeling route to load-aware policies. The paper's explicit framing of its results as simulation outcomes to motivate empirical work is a strength that keeps the central claim internally consistent without unsupported extrapolation to real reviewers.
minor comments (2)
- [Abstract] Abstract: the fatigue functional form, data exclusion rules, and validation procedure against the hand-labeled set are referenced only at a high level; a one-sentence pointer to the section containing the exact functional form and simulation parameters would improve immediate reproducibility.
- The manuscript states that the inverted-U is generated by the endogenous fatigue model; confirm that the modeling section supplies the precise functional form, any fitted parameters, and the simulation code path so that the curve can be regenerated from the open-source release.
Simulated Author's Rebuttal
We thank the referee for the accurate and positive summary of our work, the recognition of its internal consistency in framing results as modeling outcomes, and the recommendation for minor revision. No major comments were enumerated in the report.
Circularity Check
No significant circularity; modeling results are self-contained
full rationale
The paper presents the inverted-U safety curve and flooding resistance explicitly as simulation outcomes from an endogenous fatigue model, used only to motivate future human studies rather than as fitted predictions from the 125-action labels. Those labels serve solely to establish moderate agreement (Fleiss' kappa = 0.52) and the absence of ground truth; the fatigue model itself is not described as calibrated to the same subjective labels. No equation or derivation reduces a claimed result to its inputs by construction, and the cited prior mechanisms (FALCON, DeCCaF) are external references rather than load-bearing self-citations. The central contribution—an open-source operationalization that produces measurable curves—remains independent of any self-referential loop.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Risk labels for agent actions are subjective with no ground-truth single correct label
- domain assumption Human reviewer performance declines with increasing escalation load (fatigue is endogenous)
Reference graph
Works this paper leans on
-
[1]
Advani, L.Trajectory Guard: A Lightweight, Sequence-Aware Model for Real-Time Anomaly Detection in Agentic AI.arXiv:2601.00516, 2026
arXiv 2026
-
[2]
Chen, Z., Kang, M., and Li, B.ShieldAgent: Shielding Agents via Verifiable Safety Policy Reasoning.ICML 2025. arXiv:2503.22738
arXiv 2025
-
[3]
Mou, Y., Xue, Z., Li, L., Liu, P., Zhang, S., Ye, W., and Shao, J.ToolSafe: Enhancing Tool Invocation Safety of LLM-based Agents via Proactive Step-level Guardrail and Feedback. arXiv:2601.10156, 2026
arXiv 2026
-
[4]
Andriushchenko, M., Souly, A., Dziemian, M., Duenas, D., Lin, M., Wang, J., Hendrycks, D., Zou, A., Kolter, Z., Fredrikson, M., Winsor, E., Wynne, J., Gal, Y., and Davies, X.AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents.ICLR 2025. arXiv:2410.09024
Pith/arXiv arXiv 2025
-
[5]
Madras, D., Pitassi, T., and Zemel, R.Predict Responsibly: Improving Fairness and Accuracy by Learning to Defer.NeurIPS 2018. arXiv:1711.06664
Pith/arXiv arXiv 2018
-
[6]
Charusaie, M.-A., Mozannar, H., Sontag, D., and Samadi, S.Sample Efficient Learning of Predictors that Complement Humans.ICML 2022. arXiv:2207.09584
arXiv 2022
-
[7]
Pugnana, A., De Toni, G., Barbera, C., Pellungrini, R., Lepri, B., and Passerini, A.To Ask or Not to Ask: Learning to Require Human Feedback.arXiv:2510.08314, 2025
arXiv 2025
-
[8]
Hemmer, P., Schemmer, M., Kühl, N., Vössing, M., and Satzger, G.Complementarity in Human-AI Collaboration: Concept, Sources, and Evidence.arXiv:2404.00029, 2024
arXiv 2024
-
[9]
Schemmer, M., Bartos, A., Spitzer, P., Hemmer, P., Kühl, N., Liebschner, J., and Satzger, G. Towards Effective Human-AI Decision-Making: The Role of Human Learning in Appropriate Reliance on AI Advice.arXiv:2310.02108, 2023
arXiv 2023
-
[10]
Geifman, Y., and El-Yaniv, R.Selective Classification for Deep Neural Networks.NeurIPS
-
[11]
arXiv:1705.08500. 11
-
[12]
Angelopoulos, A. N., and Bates, S.A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification.arXiv:2107.07511, 2021
Pith/arXiv arXiv 2021
-
[13]
European Data Protection Supervisor.TechDispatch #2/2025: Human Oversight of Automated Decision-Making.2025
2025
-
[14]
Zhang, Z., et al.Fatigue-Aware Learning to Defer via Constrained Optimisation. arXiv:2604.00904, 2026
Pith/arXiv arXiv 2026
-
[15]
V., Leitão, D., Jesus, S., Sampaio, M
Alves, J. V., Leitão, D., Jesus, S., Sampaio, M. O. P., Liébana, J., Saleiro, P., Figueiredo, M. A. T., and Bizarro, P.Cost-Sensitive Learning to Defer to Multiple Experts with Workload Constraints.TMLR 2024. arXiv:2403.06906
arXiv 2024
-
[16]
Alert fatigue in security operations centres: Research challenges and opportunities,
Tariq, S., et al.Alert Fatigue in Security Operations Centres: Research Challenges and Opportunities.ACM Computing Surveys 57, 2025. doi:10.1145/3723158
-
[17]
Wang, P., Li, Y., and Tian, Y.Reframing LLM Agent Security as an Agent–Human Interaction Problem.arXiv:2605.24309, 2026. 12
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.