DMV-Bench: Diagnosing Long-Horizon Multimodal Agents' Visual Memory with Incidental Cue Injection
Pith reviewed 2026-06-29 02:03 UTC · model grok-4.3
The pith
Multimodal agents recall incidental visual cues more reliably when they store parallel visual and verbal memory codes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
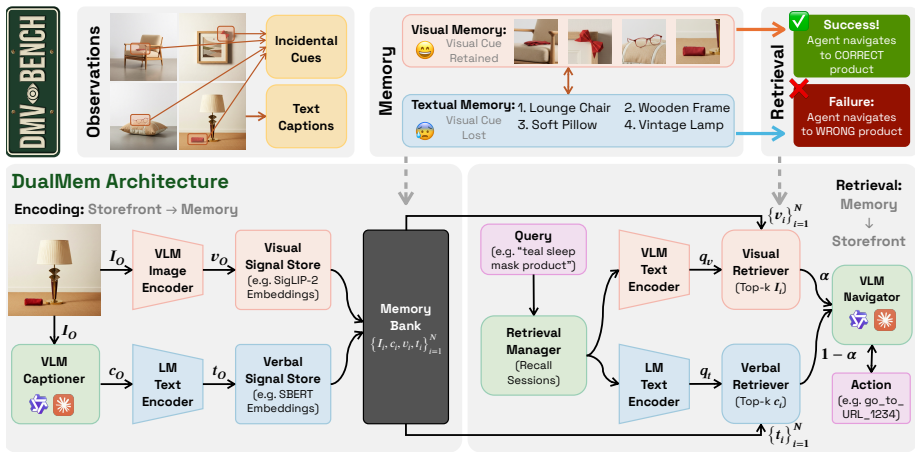
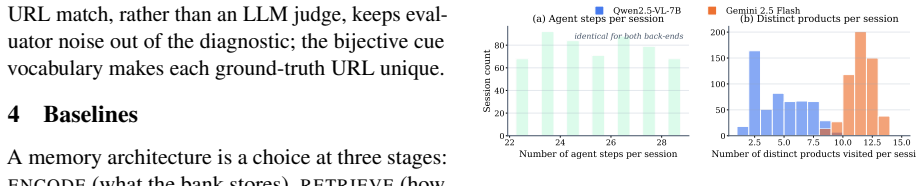
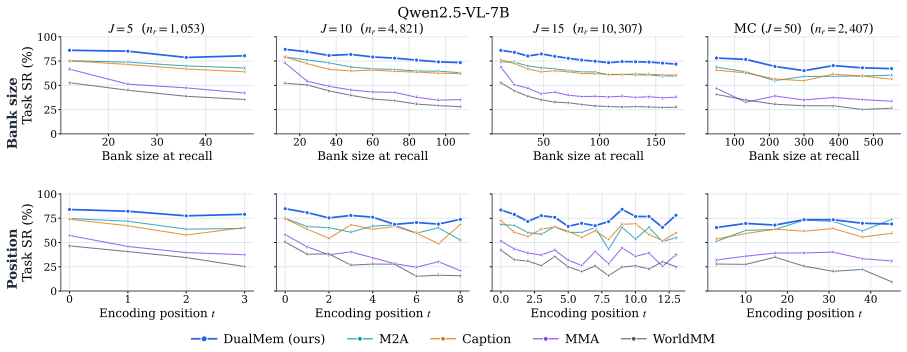
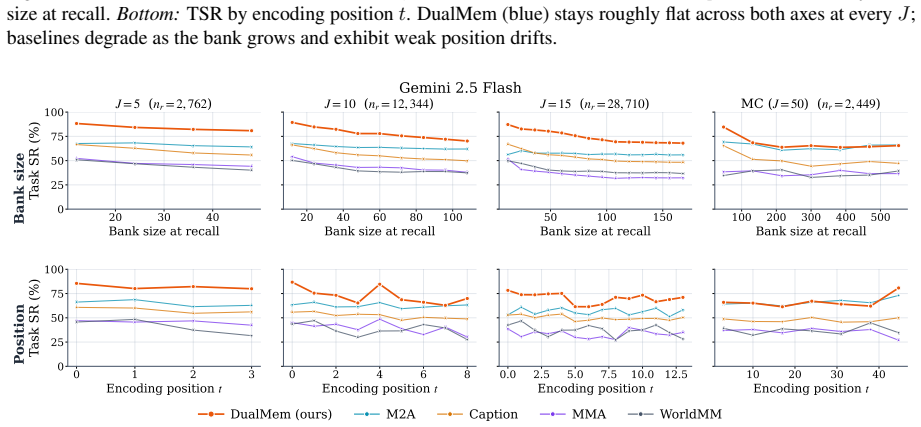
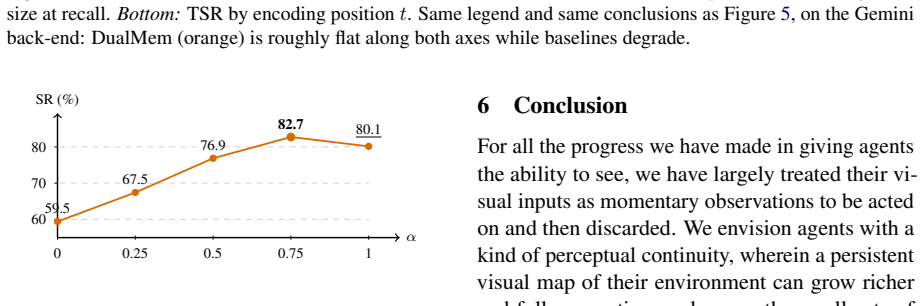
DMV-Bench is built on a controlled catalogue of 1,000 product variants in which each visited product image carries a unique pre-rendered incidental cue and the agent must later recall the cued product and navigate to its URL. DualMem maintains a visual and a verbal code in parallel and outperforms a caption baseline and three recent multimodal agent-memory systems at every chain length J in {5, 10, 15, 50} on both Gemini 2.5 Flash and Qwen2.5-VL-7B, with the lead surviving controls for memory-bank size and encoding-position bias under an asymmetric dual-coding regime in which vision carries the cue end-to-end while the verbal channel plays a smaller query-grounding role.
What carries the argument
DualMem, a memory architecture that maintains a visual code and a verbal code in parallel for each encountered product image.
If this is right
- DualMem produces higher recall accuracy than caption-only or single-code baselines at every tested chain length up to 50 steps.
- The performance margin remains after equalizing memory-bank size and after removing encoding-position bias.
- Vision carries the incidental cue through the entire chain while the verbal code mainly supports later query matching.
- The same ordering of systems holds on both Gemini 2.5 Flash and Qwen2.5-VL-7B.
Where Pith is reading between the lines
- The same incidental-cue design could be reused to test visual memory demands in navigation or manipulation agents.
- Caption-based memory systems may lose fine-grained visual distinctions that cannot be recovered from text alone.
- Longer chains or richer visual environments could expose capacity limits of current vision encoders in dual-memory setups.
- Hybrid visual-verbal memory may become a default component for agents that must act on previously seen visual details.
Load-bearing premise
The text-leakage contract ensures that no information in the images or their captions reveals the incidental cue, so the discriminative signal stays only in the pixels.
What would settle it
An experiment in which agents achieve equivalent recall accuracy when the incidental cues are removed from the images but retained in the accompanying text captions would falsify the claim that visual memory is required.
Figures

read the original abstract
Research on agent memory has matured rapidly, but almost entirely on the text side: few existing benchmarks ask, in an interactive environment, when an agent genuinely needs to remember what it saw rather than what it could write down. We introduce DMV-Bench (Code: https://github.com/yyyujintang/DMV-Bench), the first interactive benchmark for multimodal-agent visual memory. DMV-Bench is built on a controlled home-furnishing e-commerce catalogue of 1,000 product variants in which a text-leakage contract keeps the discriminative signal of each task in the pixels alone. Across a chain of autonomous shopping sessions, every visited product image carries a unique, pre-rendered incidental cue, and the agent is later asked to recall a particular cued product and navigate to its URL. Inspired by dual-coding theory, we propose DualMem, a memory architecture that maintains a visual and a verbal code in parallel. On DMV-Bench, DualMem outperforms a caption baseline and three recent multimodal agent-memory systems at every chain length J in {5, 10, 15, 50} on both Gemini 2.5 Flash and Qwen2.5-VL-7B, with the lead surviving controls for memory-bank size and encoding-position bias, and an asymmetric dual-coding regime in which vision carries the cue end-to-end while the verbal channel plays a smaller query-grounding role.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DMV-Bench, the first interactive benchmark for long-horizon visual memory in multimodal agents, constructed from a 1,000-variant home-furnishing catalogue under an asserted text-leakage contract that confines discriminative signals to pixels via pre-rendered incidental cues. It proposes DualMem, an asymmetric dual visual-verbal memory architecture, and reports that DualMem outperforms a caption baseline and three recent multimodal agent-memory systems at every chain length J in {5, 10, 15, 50} on Gemini 2.5 Flash and Qwen2.5-VL-7B, with the advantage persisting after controls for memory-bank size and encoding-position bias.
Significance. If the text-leakage contract is verifiably enforced and the empirical comparisons hold, the benchmark fills a clear gap in evaluating genuine visual recall versus textual shortcuts in agent memory systems. The public code release (https://github.com/yyyujintang/DMV-Bench) is a positive contribution to reproducibility. The asymmetric dual-coding finding, if robust, would offer a concrete architectural insight for multimodal agents.
major comments (1)
- [abstract and benchmark construction] The text-leakage contract is load-bearing for the central claim that outperformance reflects visual memory rather than textual shortcuts (abstract; benchmark construction section). The manuscript asserts the contract on the 1,000-variant catalogue but supplies no concrete enforcement details such as cue rendering method, caption template, or OCR audit procedure. Without these, the reported lead of DualMem cannot be unambiguously attributed to the proposed architecture.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of verifiable enforcement of the text-leakage contract. We agree that additional concrete details are required to fully support the central claim and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [abstract and benchmark construction] The text-leakage contract is load-bearing for the central claim that outperformance reflects visual memory rather than textual shortcuts (abstract; benchmark construction section). The manuscript asserts the contract on the 1,000-variant catalogue but supplies no concrete enforcement details such as cue rendering method, caption template, or OCR audit procedure. Without these, the reported lead of DualMem cannot be unambiguously attributed to the proposed architecture.
Authors: We agree that the manuscript would benefit from explicit enforcement details to allow unambiguous attribution of DualMem's gains to visual memory. In the revised version we will expand the benchmark construction section with: (1) the precise cue rendering pipeline (including the e-commerce image generator parameters and incidental cue placement rules used to produce the 1,000-variant catalogue); (2) the exact caption template applied to any textual descriptions, confirming that no task-discriminative information appears in text; and (3) the OCR audit procedure (tool, regions inspected, and zero-text threshold). These additions, together with the already-released code repository containing the rendering scripts, will enable independent verification that discriminative signals reside only in the pixels. revision: yes
Circularity Check
No circularity; empirical benchmark and architecture evaluation
full rationale
The paper constructs a new benchmark (DMV-Bench) under an explicit text-leakage contract and evaluates a proposed DualMem architecture via direct performance comparisons against baselines at fixed chain lengths J. No equations, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatzes imported from prior author work appear in the provided text. The central claims rest on empirical results rather than any reduction of outputs to inputs by construction, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dual-coding theory applies to multimodal AI memory systems, justifying parallel visual and verbal codes.
invented entities (1)
-
DualMem
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2508.09736 , year=
Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory , author=. arXiv preprint arXiv:2508.09736 , year=
-
[2]
Auto-scaling Continuous Memory for
Wu, Wenyi and Zhou, Kun and Yuan, Ruoxin and Yu, Vivian and Wang, Stephen and Hu, Zhiting and Huang, Biwei , booktitle=. Auto-scaling Continuous Memory for
-
[3]
Hybrid Self-evolving Structured Memory for
Zhu, Sibo and Wu, Wenyi and Zhou, Kun and Wang, Stephen and Huang, Biwei , booktitle=. Hybrid Self-evolving Structured Memory for
-
[4]
Yang, Jingkang and Liu, Shuai and Guo, Hongming and Dong, Yuhao and Zhang, Xiamengwei and Zhang, Sicheng and Wang, Pengyun and Zhou, Zitang and Xie, Binzhu and Wang, Ziyue and Ouyang, Bei and Lin, Zhengyu and Cominelli, Marco and Cai, Zhongang and Li, Bo and Zhang, Yuanhan and Zhang, Peiyuan and Hong, Fangzhou and Widmer, Joerg and Gringoli, Francesco and...
-
[5]
Yeo, Woongyeong and Kim, Kangsan and Yoon, Jaehong and Hwang, Sung Ju , booktitle=
-
[6]
He, Bo and Li, Hengduo and Jang, Young Kyun and Jia, Menglin and Cao, Xuefei and Shah, Ashish and Shrivastava, Abhinav and Lim, Ser-Nam , booktitle=
-
[7]
Feng, Junyu and Xu, Binxiao and Chen, Jiayi and Dai, Mengyu and Wu, Cenyang and Li, Haodong and Zeng, Bohan and Xie, Yunliu and Liang, Hao and Lu, Ming and Zhang, Wentao , booktitle=
-
[8]
Lu, Yihao and Cheng, Wanru and Zhang, Zeyu and Tang, Hao , booktitle=
-
[9]
and Stoica, Ion and Gonzalez, Joseph E
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , booktitle=
-
[10]
Zhong, Wanjun and Guo, Lianghong and Gao, Qiqi and Ye, He and Wang, Yanlin , booktitle=
-
[11]
Xu, Wujiang and Liang, Zujie and Mei, Kai and Gao, Hang and Tan, Juntao and Zhang, Yongfeng , booktitle=
-
[12]
Wang, Yu and Chen, Xi , booktitle=
-
[13]
Chhikara, Prateek and Khant, Dev and Aryan, Saket and Singh, Taranjeet and Yadav, Deshraj , booktitle=
-
[14]
NeurIPS , year=
Guti. NeurIPS , year=
-
[15]
NeurIPS , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. NeurIPS , year=
-
[16]
Agent Workflow Memory , author=. arXiv preprint arXiv:2409.07429 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
and Daruki, Samira and Tang, Xiangru and Tirumalashetty, Vishy and Lee, George and Rofouei, Mahsan and Lin, Hangfei and Han, Jiawei and Lee, Chen-Yu and Pfister, Tomas , booktitle=
Ouyang, Siru and Yan, Jun and Hsu, I-Hung and Chen, Yanfei and Jiang, Ke and Wang, Zifeng and Han, Rujun and Le, Long T. and Daruki, Samira and Tang, Xiangru and Tirumalashetty, Vishy and Lee, George and Rofouei, Mahsan and Lin, Hangfei and Han, Jiawei and Lee, Chen-Yu and Pfister, Tomas , booktitle=
-
[18]
Liu, Junming and Sun, Yifei and Cheng, Weihua and Lei, Haodong and Chen, Yirong and Wen, Licheng and Yang, Xuemeng and Fu, Daocheng and Cai, Pinlong and Deng, Nianchen and Yu, Yi and Hu, Shuyue and Shi, Botian and Wang, Ding , booktitle=
-
[19]
Evaluating Very Long-Term Conversational Memory of
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , booktitle=. Evaluating Very Long-Term Conversational Memory of
-
[20]
Wu, Di and Wang, Hongwei and Yu, Wenhao and Zhang, Yuwei and Chang, Kai-Wei and Yu, Dong , booktitle=
-
[21]
Evaluating Memory in
Hu, Yuanzhe and Wang, Yu and McAuley, Julian , booktitle=. Evaluating Memory in
-
[22]
Li, Xinze and Zhu, Ziyue and Liu, Siyuan and Ma, Yubo and Zang, Yuhang and Cao, Yixin and Sun, Aixin , booktitle=
-
[23]
Yadav, Karmesh and Ali, Yusuf and Gupta, Gunshi and Gal, Yarin and Kira, Zsolt , booktitle=
-
[24]
He, Zexue and Wang, Yu and Zhi, Churan and Hu, Yuanzhe and Chen, Tzu-Ping and Yin, Lang and Chen, Ze and Wu, Tong Arthur and Ouyang, Siru and Wang, Zihan and Pei, Jiaxin and McAuley, Julian and Choi, Yejin and Pentland, Alex , booktitle=
-
[25]
Liu, Guangyi and Zhao, Pengxiang and Liang, Yaozhen and Luo, Qinyi and Tang, Shunye and Chai, Yuxiang and Lin, Weifeng and Xiao, Han and Wang, WenHao and Chen, Siheng and Lu, Zhengxi and Wu, Gao and Wang, Hao and Liu, Liang and Liu, Yong , booktitle=
-
[26]
and Tang, Ruixiang , booktitle=
Guo, Minghao and Jiao, Qingyue and Shi, Zeru and Quan, Yihao and Zhang, Boxuan and Li, Danrui and Che, Liwei and Xu, Wujiang and Liu, Shilong and Liu, Zirui and Kapadia, Mubbasir and Pavlovic, Vladimir and Liu, Jiang and Wang, Mengdi and Shi, Yiyu and Metaxas, Dimitris N. and Tang, Ruixiang , booktitle=
-
[27]
Fu, Chaoyou and Dai, Yuhan and Luo, Yongdong and Li, Lei and Ren, Shuhuai and Zhang, Renrui and Wang, Zihan and Zhou, Chenyu and Shen, Yunhang and Zhang, Mengdan and Chen, Peixian and Li, Yanwei and Lin, Shaohui and Zhao, Sirui and Li, Ke and Xu, Tong and Zheng, Xiawu and Chen, Enhong and Shan, Caifeng and He, Ran and Sun, Xing , booktitle=
-
[28]
Li, Kunchang and Wang, Yali and He, Yinan and Li, Yizhuo and Wang, Yi and Liu, Yi and Wang, Zun and Xu, Jilan and Chen, Guo and Luo, Ping and Wang, Limin and Qiao, Yu , booktitle=
-
[29]
and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle=
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle=
-
[30]
Koh, Jing Yu and Lo, Robert and Jang, Lawrence and Duvvur, Vikram and Lim, Ming Chong and Huang, Po-Yu and Neubig, Graham and Zhou, Shuyan and Salakhutdinov, Ruslan and Fried, Daniel , booktitle=
-
[31]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: A Family of Highly Capable Multimodal Models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Z...
-
[33]
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle=
-
[34]
Sentence-
Reimers, Nils and Gurevych, Iryna , booktitle=. Sentence-
-
[35]
Tschannen, Michael and Gritsenko, Alexey and Wang, Xiao and Naeem, Muhammad Ferjad and Alabdulmohsin, Ibrahim and Parthasarathy, Nikhil and Evans, Talfan and Beyer, Lucas and Xia, Ye and Mustafa, Basil and H. arXiv preprint arXiv:2502.14786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
2025 , howpublished=
Introducing Gemini 2.5 Flash Image (Nano-Banana), Our State-of-the-Art Image Model , author=. 2025 , howpublished=
2025
-
[37]
Holt, Rinehart and Winston , year=
Imagery and Verbal Processes , author=. Holt, Rinehart and Winston , year=
-
[38]
Psychological Review , year=
Encoding specificity and retrieval processes in episodic memory , author=. Psychological Review , year=
-
[39]
Journal of Experimental Psychology , year=
Differential effects of incidental tasks on the organization of recall of a list of highly associated words , author=. Journal of Experimental Psychology , year=
-
[40]
Journal of Verbal Learning and Verbal Behavior , year=
Levels of processing: A framework for memory research , author=. Journal of Verbal Learning and Verbal Behavior , year=
-
[41]
Philosophical Transactions of the Royal Society of London
Simple memory: A theory for archicortex , author=. Philosophical Transactions of the Royal Society of London. Series B , year=
-
[42]
and Chitwood, Raymond A
Nakazawa, Kazu and Quirk, Michael C. and Chitwood, Raymond A. and Watanabe, Masahiko and Yeckel, Mark F. and Sun, Linus D. and Kato, Akira and Carr, Candice A. and Johnston, Daniel and Wilson, Matthew A. and Tonegawa, Susumu , booktitle=. Requirement for hippocampal
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.