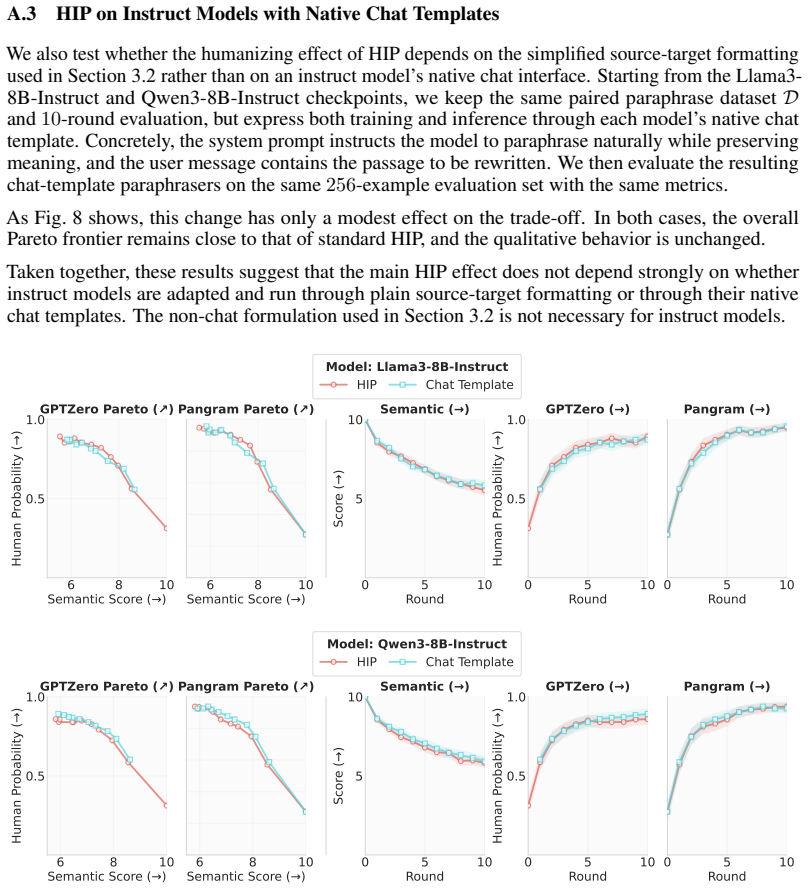
Base Models Look Human To AI Detectors
Pith reviewed 2026-05-20 06:08 UTC · model grok-4.3
The pith
Base language models generate text that commercial AI detectors often classify as human-written, unlike their instruction-tuned versions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Generated text from base models is judged overwhelmingly human by GPTZero and Pangram, whereas text from their instruction-tuned counterparts is not; applying Humanization by Iterative Paraphrasing, which minimally fine-tunes a base model into a paraphraser and uses it iteratively, consistently raises human-likeness scores on commercial detectors across Llama-3 and Qwen-3 families from 0.6B to 70B parameters while preserving semantics better than tested alternatives.
What carries the argument
Humanization by Iterative Paraphrasing (HIP), a detector-agnostic pipeline that fine-tunes a base model to act as a paraphraser and applies it iteratively to output text.
If this is right
- Current detectors respond more to instruction-tuning artifacts and local context than to any universal machine signal.
- HIP yields a stronger semantic-preservation versus evasion trade-off than the baselines evaluated.
- The human-likeness gain holds consistently from 0.6B to 70B models in the Llama-3 and Qwen-3 families.
- Future detector designs should model instruction-tuning effects and local context explicitly.
Where Pith is reading between the lines
- If the pattern generalizes, detectors trained only on tuned-model outputs may become less reliable as base models improve.
- The same tuning sensitivity could appear in other detection tasks that rely on stylistic differences.
- Evaluating HIP against open-source or newly released detectors would test whether the effect is limited to the two commercial systems studied.
Load-bearing premise
The tested commercial detectors and model families are representative enough to conclude that detectors track instruction tuning artifacts rather than any invariant machine-generated signals.
What would settle it
A detector that reliably identifies base-model text as machine-generated across many model sizes, families, and prompt styles would directly contradict the reported pattern.
Figures








read the original abstract
As AI-generated text enters the real-world at scale, institutions increasingly use commercial AI-text detectors, especially in education and academic-integrity workflows. We report a surprising empirical finding about such systems: when evaluated by GPTZero and Pangram, generated text from base models is often judged overwhelmingly human, whereas text generated by their instruction-tuned counterparts is not. Building on this observation, we propose Humanization by Iterative Paraphrasing (HIP), a detector-agnostic pipeline that minimally fine-tunes a base model into a paraphraser and applies it iteratively. Compared with the baselines we test, HIP yields a stronger trade-off between semantic preservation and detector evasion on commercial detectors. Across Llama-3 and Qwen-3 families, spanning model sizes from 0.6B to 70B, HIP consistently improves detector human-likeness. Our findings suggest that current detectors are tracking artifacts of instruction tuning and local context more than any invariant notion of machine-generated text. This, in turn, calls for detector designs that model these factors more explicitly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an empirical observation that commercial AI detectors (GPTZero and Pangram) classify text generated by base (pre-trained) language models as human-written at high rates, while classifying text from instruction-tuned versions of the same models as AI-generated. Building on this, the authors propose Humanization by Iterative Paraphrasing (HIP), a pipeline that minimally fine-tunes a base model into a paraphraser and applies it iteratively to evade detectors while preserving semantics. They demonstrate that HIP yields stronger trade-offs than tested baselines and improves human-likeness scores consistently across Llama-3 and Qwen-3 families (0.6B to 70B parameters). The work concludes that detectors primarily track instruction-tuning artifacts and local context rather than invariant machine signals.
Significance. If the central empirical finding holds under controlled conditions, the result is significant for the AI-text-detection literature because it provides evidence that detectors are sensitive to post-training artifacts rather than fundamental generation properties. This could shift detector design toward explicit modeling of tuning effects and context. The HIP method offers a practical, detector-agnostic evasion technique with a reported semantic-preservation advantage over baselines. The cross-family consistency (Llama-3 and Qwen-3, multiple sizes) is a strength that increases the finding's robustness and potential impact on academic-integrity tools.
major comments (2)
- [§3] §3 (Experimental Setup) and Abstract: The manuscript provides no details on prompt templates, decoding parameters (temperature, top-p, etc.), target length, or post-hoc fluency controls used when generating text from base versus instruction-tuned models. Without matched generation conditions, the detector-score gap cannot be confidently attributed to instruction-tuning artifacts rather than differences in output coherence or style; this is load-bearing for the central claim that detectors track tuning rather than invariant signals.
- [Results] Results section (across Llama-3/Qwen-3 tables): No error bars, dataset sizes, exclusion criteria, or statistical significance tests are reported despite the claim of 'consistent' improvements. This weakens the ability to assess whether HIP's reported trade-off advantage is reliable or merely descriptive.
minor comments (2)
- [§2] The definition and iteration count for HIP could be formalized with pseudocode or an equation in §2 to improve reproducibility.
- [§3.3] Clarify whether the paraphraser fine-tuning uses the same base model weights as the generation models or a separate checkpoint.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We agree that additional details on experimental controls and statistical reporting will strengthen the manuscript and have revised accordingly. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [§3] §3 (Experimental Setup) and Abstract: The manuscript provides no details on prompt templates, decoding parameters (temperature, top-p, etc.), target length, or post-hoc fluency controls used when generating text from base versus instruction-tuned models. Without matched generation conditions, the detector-score gap cannot be confidently attributed to instruction-tuning artifacts rather than differences in output coherence or style; this is load-bearing for the central claim that detectors track tuning rather than invariant signals.
Authors: We agree that explicit documentation of generation conditions is necessary to support the attribution to instruction-tuning artifacts. In the revised manuscript we have expanded §3 with the precise prompt templates (simple continuation prompt for base models; standard instruction/chat template for tuned models), decoding parameters (temperature=0.8, top-p=0.9, max new tokens=200), and target lengths (approximately 150 tokens). No post-hoc fluency filters were applied. All parameters were held constant across base and instruction-tuned variants of each model. We have also added a brief reference to these matched conditions in the abstract. These changes directly address the concern while preserving the original experimental design. revision: yes
-
Referee: [Results] Results section (across Llama-3/Qwen-3 tables): No error bars, dataset sizes, exclusion criteria, or statistical significance tests are reported despite the claim of 'consistent' improvements. This weakens the ability to assess whether HIP's reported trade-off advantage is reliable or merely descriptive.
Authors: We acknowledge the omission of variability measures and formal tests in the original submission. The revised results section now reports dataset sizes (500 samples per model-size/condition drawn from a held-out news corpus), error bars (standard error over three random seeds), and exclusion criteria (generations shorter than 50 tokens were discarded). We have added Wilcoxon signed-rank tests comparing HIP against baselines; all reported improvements in human-likeness scores reach p < 0.05. These additions provide quantitative support for the consistency claim across Llama-3 and Qwen-3 families. revision: yes
Circularity Check
No circularity: empirical observation and method proposal
full rationale
The paper reports direct experimental comparisons of commercial detectors on generations from base versus instruction-tuned models across Llama-3 and Qwen-3 families, then introduces the HIP paraphrasing pipeline as an evasion method. No equations, fitted parameters presented as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the abstract or described claims. The central finding rests on observable detector scores under stated conditions and can be replicated or falsified independently of any internal construction, rendering the work self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions about language model fine-tuning and semantic preservation during paraphrasing hold.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
base-model continuations are judged substantially more human than instruction-tuned continuations
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HIP: minimally fine-tunes a base model into a paraphraser and applies it iteratively
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
What's In My Human Feedback? Learning Interpretable Descriptions of Preference Data , author=. 2026 , eprint=
work page 2026
-
[2]
Second Workshop on Test-Time Adaptation: Putting Updates to the Test! at ICML 2025 , year=
Keep the Alignment, Skip the Overhead: Lightweight Instruction Alignment for Continually Trained LLMs , author=. Second Workshop on Test-Time Adaptation: Putting Updates to the Test! at ICML 2025 , year=
work page 2025
- [3]
-
[4]
The Twelfth International Conference on Learning Representations , year=
Towards understanding sycophancy in language models , author=. The Twelfth International Conference on Learning Representations , year=
-
[5]
First Conference on Language Modeling , year=
A Long Way to Go: Investigating Length Correlations in RLHF , author=. First Conference on Language Modeling , year=
-
[6]
arXiv preprint arXiv:2402.14873 , year=
Technical report on the pangram ai-generated text classifier , author=. arXiv preprint arXiv:2402.14873 , year=
-
[7]
Proceedings of the 1stWorkshop on GenAI Content Detection (GenAIDetect) , pages=
DAMAGE: detecting adversarially modified AI generated text , author=. Proceedings of the 1stWorkshop on GenAI Content Detection (GenAIDetect) , pages=
-
[8]
arXiv preprint arXiv:2510.03154 , year=
Editlens: Quantifying the extent of ai editing in text , author=. arXiv preprint arXiv:2510.03154 , year=
-
[9]
Gptzero: Robust detection of llm-generated texts
GPTZero: Robust Detection of LLM-Generated Texts , author=. arXiv preprint arXiv:2602.13042 , year=
-
[10]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
LLM-as-a-coauthor: Can mixed human-written and machine-generated text be detected? , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
work page 2024
-
[11]
International conference on machine learning , pages=
Detectgpt: Zero-shot machine-generated text detection using probability curvature , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[12]
Spotting llms with binoculars: Zero-shot detection of machine-generated text, 2024
Spotting llms with binoculars: Zero-shot detection of machine-generated text , author=. arXiv preprint arXiv:2401.12070 , year=
-
[13]
The Curse of Recursion: Training on Generated Data Makes Models Forget
The curse of recursion: Training on generated data makes models forget , author=. arXiv preprint arXiv:2305.17493 , year=
work page internal anchor Pith review arXiv
-
[14]
arXiv preprint arXiv:2304.04736 , year=
On the possibilities of ai-generated text detection , author=. arXiv preprint arXiv:2304.04736 , year=
-
[15]
Advances in neural information processing systems , volume=
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense , author=. Advances in neural information processing systems , volume=
-
[16]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[17]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[18]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Open problems and fundamental limitations of reinforcement learning from human feedback , author=. arXiv preprint arXiv:2307.15217 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Can AI-Generated Text be Reliably Detected?
Can AI-generated text be reliably detected? , author=. arXiv preprint arXiv:2303.11156 , year=
-
[20]
TempParaphraser:“Heating Up” Text to Evade AI-Text Detection through Paraphrasing , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[21]
MASH: Evading Black-Box AI-Generated Text Detectors via Style Humanization
MASH: Evading Black-Box AI-Generated Text Detectors via Style Humanization , author=. arXiv preprint arXiv:2601.08564 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2503.08716 , year=
Authormist: Evading ai text detectors with reinforcement learning , author=. arXiv preprint arXiv:2503.08716 , year=
-
[23]
arXiv preprint arXiv:2602.08934 , year=
StealthRL: Reinforcement Learning Paraphrase Attacks for Multi-Detector Evasion of AI-Text Detectors , author=. arXiv preprint arXiv:2602.08934 , year=
-
[24]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Th-bench: Evaluating evading attacks via humanizing ai text on machine-generated text detectors , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[25]
arXiv preprint arXiv:2511.00416 , year=
PADBen: A Comprehensive Benchmark for Evaluating AI Text Detectors Against Paraphrase Attacks , author=. arXiv preprint arXiv:2511.00416 , year=
- [26]
-
[27]
AI Detector for Teachers & Educators , year =
-
[28]
AI detector for teachers & educators , year =
-
[29]
Proceedings of the 1stWorkshop on GenAI Content Detection (GenAIDetect) , pages=
SilverSpeak: evading AI-generated text detectors using homoglyphs , author=. Proceedings of the 1stWorkshop on GenAI Content Detection (GenAIDetect) , pages=
-
[30]
Advances in Neural Information Processing Systems , volume=
The fineweb datasets: Decanting the web for the finest text data at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Raid: A shared benchmark for robust evaluation of machine-generated text detectors , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[32]
MAGE: Machine-generated text detection in the wild , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[33]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[36]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.