Spectral Dynamics in Deep Networks: Feature Learning, Outlier Escape, and Learning Rate Transfer
Pith reviewed 2026-05-22 10:22 UTC · model grok-4.3
The pith
MuP scaling produces width-consistent outlier spectral dynamics and learning rate transfer in deep linear networks, unlike NTK parameterization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
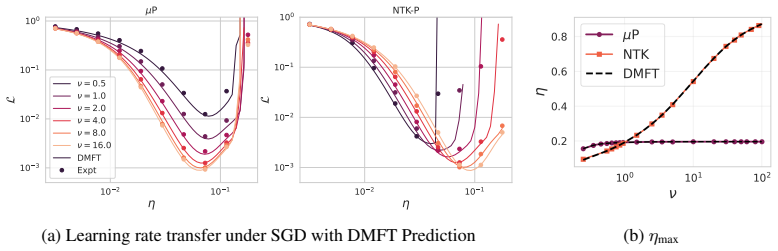
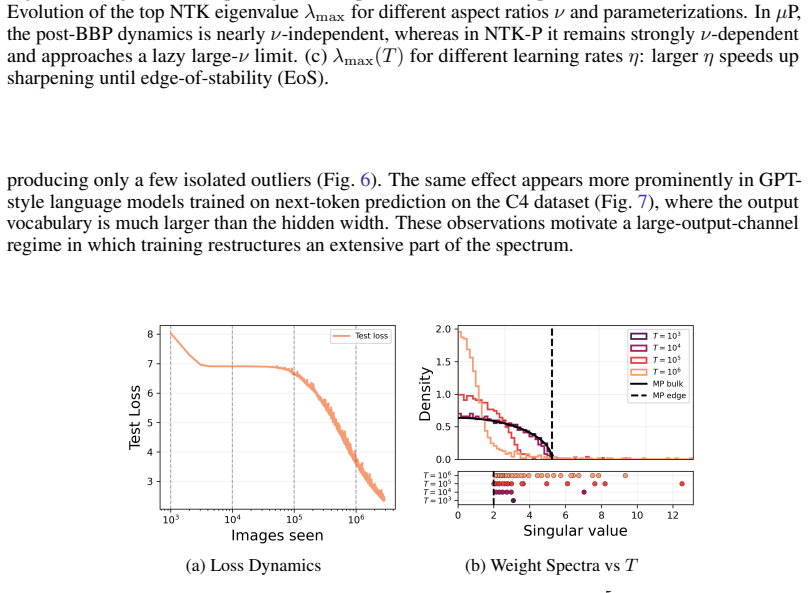
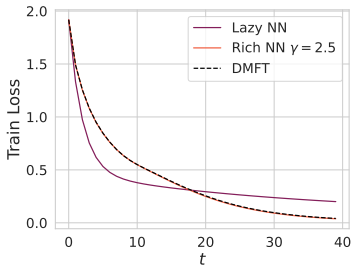
In the proportional high-dimensional limit for deep linear networks, muP yields width-consistent outlier dynamics and hyperparameter transfer, including width-stable growth of the leading NTK mode toward the edge of stability. In contrast, NTK parameterization exhibits strongly width-dependent outlier dynamics, despite converging to a stable large-width limit. The theory predicts outlier evolution with training time, width, output scale, and initialization variance, and shows that tasks with small output channels follow the bulk-plus-outlier description while large-output tasks like ImageNet or language modeling involve spectral bulk restructuring.
What carries the argument
A two-level dynamical mean-field theory that jointly tracks bulk and outlier spectral dynamics for spiked ensembles whose spike directions remain statistically dependent on the random bulk.
If this is right
- Outlier eigenvalues evolve in a manner that depends on training time, width, output scale, and initialization variance under the two-level description.
- Learning rate transfer across widths becomes possible because outlier motion and edge-of-stability approach remain stable in muP.
- Small-output-channel tasks are governed by outlier escape from the bulk, while large-output tasks require tracking bulk restructuring.
- The edge of the spectrum still converges for wide enough networks even when output channels are extensive.
Where Pith is reading between the lines
- Outlier escape may be the microscopic driver of feature learning that muP preserves across scales.
- The same bulk-plus-outlier tracking could guide initialization or scaling choices that improve training stability in nonlinear networks.
- Finite-width simulations that check whether spike directions stay coupled to the bulk would directly test the joint DMFT assumption.
Load-bearing premise
The spike directions remain statistically dependent on the random bulk so that a single two-level description can capture both infinite-width nonlinear networks and proportional deep linear networks.
What would settle it
Training deep linear networks of increasing width under muP and measuring whether the leading NTK outlier eigenvalue grows toward the edge of stability at a rate independent of width would confirm or refute the width-consistent dynamics claim.
Figures
















read the original abstract
We study the evolution of hidden-weight spectra in wide neural networks trained by (stochastic) gradient descent. We develop a two-level dynamical mean-field theory (DMFT) that jointly tracks bulk and outlier spectral dynamics for spiked ensembles whose spike directions remain statistically dependent on the random bulk. We apply this framework to two settings: (1) infinite-width nonlinear networks in mean-field/$\mu$P scaling and (2) deep linear networks in the proportional high-dimensional limit, where width, input dimension, and sample size diverge with fixed ratios. Our theory predicts how outliers evolve with training time, width, output scale, and initialization variance. In deep linear networks, $\mu$P yields width-consistent outlier dynamics and hyperparameter transfer, including width-stable growth of the leading NTK mode toward the edge of stability (EoS). In contrast, NTK parameterization exhibits strongly width-dependent outlier dynamics, despite converging to a stable large-width limit. We show that this bulk+outlier picture is descriptive of simple tasks with small output channels, but that tasks involving large numbers of outputs (ImageNet classification or GPT language modeling) are better described by a restructuring of the spectral bulk. We develop a toy model with extensive output channels that recapitulates this phenomenon and show that edge of the spectrum still converges for sufficiently wide networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a two-level dynamical mean-field theory (DMFT) that jointly tracks bulk and outlier spectral dynamics for spiked ensembles whose spike directions remain statistically dependent on the random bulk. It applies the framework to infinite-width nonlinear networks under mean-field/μP scaling and to deep linear networks in the proportional high-dimensional limit (width, input dimension, and sample size diverging at fixed ratios). The theory predicts outlier evolution with training time, width, output scale, and initialization variance. In deep linear networks, μP is shown to yield width-consistent outlier dynamics and hyperparameter transfer, including width-stable growth of the leading NTK mode toward the edge of stability, while NTK parameterization exhibits strongly width-dependent outlier dynamics despite a stable large-width limit. For tasks with large output channels, the paper argues that spectral bulk restructuring dominates and provides a toy model recapitulating this behavior.
Significance. If the DMFT closure and predictions hold, the work offers a valuable theoretical lens on feature learning via spectral evolution, the edge of stability, and the advantages of μP for learning-rate transfer across widths. The joint bulk-outlier treatment and the distinction between outlier escape and bulk restructuring for different output-channel regimes provide falsifiable predictions that could guide empirical studies. The application to both nonlinear infinite-width and proportional deep-linear settings is a strength.
major comments (2)
- [§3] §3 (two-level DMFT closure): The central claim of width-independent outlier dynamics under μP in the deep linear proportional regime rests on the assumption that spike directions remain statistically dependent on the random bulk while higher-order correlations induced by gradient descent remain negligible. The manuscript must supply either explicit bounds on the neglected terms or direct numerical checks of the closure against finite-width simulations in the proportional limit; without this, the predicted width-consistency may be an artifact of the mean-field truncation.
- [§5] §5 (deep linear networks, NTK-mode growth): The statement that the leading NTK mode grows toward the edge of stability in a width-stable manner under μP is load-bearing for the hyperparameter-transfer claim. The derivation should be accompanied by a quantitative finite-width scaling analysis (e.g., deviation from the infinite-width trajectory as a function of 1/width) rather than only the limiting prediction.
minor comments (2)
- [§2] The abstract and §2 should explicitly list the two free parameters (output scale and initialization variance) and state how they enter the spiked-ensemble construction.
- [Figures] Figure captions for the empirical validations should report the number of independent runs and any observed variance across random seeds.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. The points raised regarding the DMFT closure and finite-width validation are important for strengthening the theoretical claims. We address each major comment in detail below, and have made revisions to the manuscript to incorporate additional numerical evidence and analysis.
read point-by-point responses
-
Referee: [§3] §3 (two-level DMFT closure): The central claim of width-independent outlier dynamics under μP in the deep linear proportional regime rests on the assumption that spike directions remain statistically dependent on the random bulk while higher-order correlations induced by gradient descent remain negligible. The manuscript must supply either explicit bounds on the neglected terms or direct numerical checks of the closure against finite-width simulations in the proportional limit; without this, the predicted width-consistency may be an artifact of the mean-field truncation.
Authors: We agree that justifying the two-level DMFT closure is crucial, particularly the negligibility of higher-order correlations in the proportional limit. The manuscript derives the closure under the assumption that the spike directions maintain their statistical dependence on the bulk, which is preserved by the structure of the spiked ensemble and the gradient flow. To address the referee's concern, we have added direct numerical checks in the revised version, comparing the DMFT predictions for outlier evolution against finite-width simulations in the proportional regime (with fixed ratios for width, input dimension, and sample size). These simulations confirm that the closure holds with small errors that decrease as the system size increases, supporting the width-independent predictions under μP. revision: yes
-
Referee: [§5] §5 (deep linear networks, NTK-mode growth): The statement that the leading NTK mode grows toward the edge of stability in a width-stable manner under μP is load-bearing for the hyperparameter-transfer claim. The derivation should be accompanied by a quantitative finite-width scaling analysis (e.g., deviation from the infinite-width trajectory as a function of 1/width) rather than only the limiting prediction.
Authors: This is a valid point, as the width-stability of the NTK mode growth under μP is key to the hyperparameter transfer results. Our analysis focuses on the proportional high-dimensional limit where the theory becomes exact. However, to provide quantitative support, the revised manuscript now includes a finite-width scaling analysis. We present plots showing the deviation of the leading NTK eigenvalue from the infinite-width DMFT trajectory as a function of 1/width for various training times. The deviations are observed to be O(1/width) and consistent with the expected finite-width corrections, thereby reinforcing the claim of width-consistent dynamics and learning rate transfer. revision: yes
Circularity Check
DMFT framework derives predictions without reduction to inputs or self-citations
full rationale
The paper develops a two-level DMFT that jointly tracks bulk and outlier spectral dynamics for spiked ensembles with statistical dependence between spike directions and random bulk. This setup is applied to derive explicit predictions for outlier evolution under μP versus NTK scaling in both infinite-width nonlinear networks and proportional deep linear networks. The central results on width-consistent outlier growth to EoS under μP follow from the DMFT closure equations applied to the respective limits, without any quoted reduction of the target quantities to fitted parameters, self-definitions, or load-bearing self-citations. No steps exhibit the patterns of self-definitional equivalence, fitted-input predictions, or ansatz smuggling. The derivation remains self-contained against the stated mean-field assumptions.
Axiom & Free-Parameter Ledger
free parameters (2)
- output scale
- initialization variance
axioms (2)
- domain assumption Dynamical mean-field theory applies to wide neural networks in the infinite-width and proportional high-dimensional limits
- ad hoc to paper Spike directions in the ensembles remain statistically dependent on the random bulk
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-level dynamical mean-field theory (DMFT) that jointly tracks bulk and outlier spectral dynamics for spiked ensembles whose spike directions remain statistically dependent on the random bulk
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
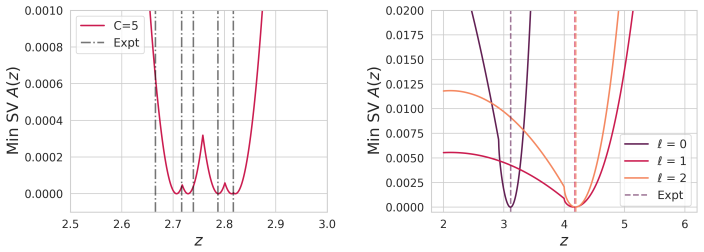
Result 1: Singular Values of Random Matrices with Statistically Coupled Spikes ... det A(z) = 0
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Spectral phase transitions and trainability in neural network learning dynamics
SGD on neural network weights induces a BBP phase transition that detaches signal eigenvalues from the random bulk, yielding an analytically solvable phase diagram for trainability in a linear teacher-student model.
-
The Spectral Dynamics and Noise Geometry of Muon
Muon induces a flat singular-value spectrum bias proven entropy-maximizing under alignment assumptions, with exact dynamics in regression favoring equal nonzero values and empirical gains in NanoGPT but reversal in ViT.
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing systems, 31, 2018
work page 2018
-
[5]
Jaehoon Lee, Lechao Xiao, Samuel Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl- Dickstein, and Jeffrey Pennington. Wide neural networks of any depth evolve as linear models under gradient descent.Advances in neural information processing systems, 32, 2019
work page 2019
-
[6]
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. Explaining neural scaling laws.arXiv preprint arXiv:2102.06701, 2021
-
[7]
Spectrum dependent learning curves in kernel regression and wide neural networks
Blake Bordelon, Abdulkadir Canatar, and Cengiz Pehlevan. Spectrum dependent learning curves in kernel regression and wide neural networks. InInternational Conference on Machine Learning, pages 1024–1034. PMLR, 2020
work page 2020
-
[8]
Bruno Loureiro, Cedric Gerbelot, Hugo Cui, Sebastian Goldt, Florent Krzakala, Marc Mezard, and Lenka Zdeborová. Learning curves of generic features maps for realistic datasets with a teacher-student model.Advances in Neural Information Processing Systems, 34:18137–18151, 2021
work page 2021
-
[9]
Mean-field theory of two-layers neural networks: dimension-free bounds and kernel limit
Song Mei, Theodor Misiakiewicz, and Andrea Montanari. Mean-field theory of two-layers neural networks: dimension-free bounds and kernel limit. InConference on Learning Theory, pages 2388–2464. PMLR, 2019
work page 2019
-
[10]
Mario Geiger, Stefano Spigler, Arthur Jacot, and Matthieu Wyart. Disentangling feature and lazy training in deep neural networks.Journal of Statistical Mechanics: Theory and Experiment, 2020(11):113301, 2020
work page 2020
-
[11]
Tensor programs iv: Feature learning in infinite-width neural networks
Greg Yang and Edward J Hu. Tensor programs iv: Feature learning in infinite-width neural networks. InInternational Conference on Machine Learning, pages 11727–11737. PMLR, 2021
work page 2021
-
[12]
Blake Bordelon and Cengiz Pehlevan. Self-consistent dynamical field theory of kernel evolution in wide neural networks.arXiv preprint arXiv:2205.09653, 2022
-
[13]
Behrooz Ghorbani, Song Mei, Theodor Misiakiewicz, and Andrea Montanari. When do neural networks outperform kernel methods?Advances in Neural Information Processing Systems, 33:14820–14830, 2020
work page 2020
-
[14]
arXiv preprint arXiv:2206.10012 , year=
Nikhil Vyas, Yamini Bansal, and Preetum Nakkiran. Limitations of the ntk for understanding generalization in deep learning.arXiv preprint arXiv:2206.10012, 2022
-
[15]
Andrea Montanari and Pierfrancesco Urbani. Dynamical decoupling of generalization and overfitting in large two-layer networks.arXiv preprint arXiv:2502.21269, 2025
-
[16]
Practice, theory, and theorems for random matrix theory in modern machine learning
Michael W Mahoney. Practice, theory, and theorems for random matrix theory in modern machine learning. 2022
work page 2022
-
[17]
Liam Hodgkinson, Zhichao Wang, and Michael W. Mahoney. Models of heavy-tailed mechanis- tic universality. InForty-second International Conference on Machine Learning, 2025. 11
work page 2025
-
[18]
Vladimir A Marˇcenko and Leonid Andreevich Pastur. Distribution of eigenvalues for some sets of random matrices.Mathematics of the USSR-Sbornik, 1(4):457–483, 1967
work page 1967
-
[19]
Cambridge University Press, 2020
Marc Potters and Jean-Philippe Bouchaud.A first course in random matrix theory: for physicists, engineers and data scientists. Cambridge University Press, 2020
work page 2020
-
[20]
Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices
Jinho Baik, Gérard Ben Arous, and Sandrine Péché. Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices. 2005
work page 2005
-
[21]
Greg Yang, Edward J Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tensor programs v: Tuning large neural networks via zero-shot hyperparameter transfer.arXiv preprint arXiv:2203.03466, 2022
-
[22]
C., Noci, L., Li, M., Bordelon, B., Bergsma, S., Pehlevan, C., Hanin, B., and Hestness, J
Nolan Dey, Bin Claire Zhang, Lorenzo Noci, Mufan Li, Blake Bordelon, Shane Bergsma, Cengiz Pehlevan, Boris Hanin, and Joel Hestness. Don’t be lazy: Completep enables compute-efficient deep transformers.arXiv preprint arXiv:2505.01618, 2025
-
[23]
Chen Xing, Devansh Arpit, Christos Tsirigotis, and Yoshua Bengio. A walk with sgd, 2018
work page 2018
-
[24]
The break-even point on optimization trajectories of deep neural networks
Stanislaw Jastrzebski, Maciej Szymczak, Stanislav Fort, Devansh Arpit, Jacek Tabor, Kyunghyun Cho*, and Krzysztof Geras*. The break-even point on optimization trajectories of deep neural networks. InInternational Conference on Learning Representations, 2020
work page 2020
-
[25]
Jeremy M Cohen, Simran Kaur, Yuanzhi Li, J Zico Kolter, and Ameet Talwalkar. Gra- dient descent on neural networks typically occurs at the edge of stability.arXiv preprint arXiv:2103.00065, 2021
-
[26]
Alex Damian, Eshaan Nichani, and Jason D Lee
Jeremy M. Cohen, B. Ghorbani, Shankar Krishnan, Naman Agarwal, Sourabh Medapati, Michal Badura, Daniel Suo, David E. Cardoze, Zachary Nado, George E. Dahl, and Justin Gilmer. Adaptive gradient methods at the edge of stability.ArXiv, abs/2207.14484, 2022
-
[27]
Edge of stochastic stability: Revisiting the edge of stability for sgd, 2025
Arseniy Andreyev and Pierfrancesco Beneventano. Edge of stochastic stability: Revisiting the edge of stability for sgd, 2025
work page 2025
-
[28]
Understanding the evolution of the neural tangent kernel at the edge of stability
Kaiqi Jiang, Jeremy Cohen, and Yuanzhi Li. Understanding the evolution of the neural tangent kernel at the edge of stability. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[29]
Understanding the mechanisms of fast hyperpa- rameter transfer.arXiv preprint arXiv:2512.22768, 2025
Nikhil Ghosh, Denny Wu, and Alberto Bietti. Understanding the mechanisms of fast hyperpa- rameter transfer.arXiv preprint arXiv:2512.22768, 2025
-
[30]
Florent Benaych-Georges and Raj Rao Nadakuditi. The singular values and vectors of low rank perturbations of large rectangular random matrices.Journal of Multivariate Analysis, 111:120–135, 2012
work page 2012
-
[31]
Amelia Perry, Alexander S Wein, Afonso S Bandeira, and Ankur Moitra. Optimality and sub- optimality of pca i: Spiked random matrix models.The Annals of Statistics, 46(5):2416–2451, 2018
work page 2018
-
[32]
Limiting eigenvectors of outliers for spiked information-plus-noise type matrices
Mireille Capitaine. Limiting eigenvectors of outliers for spiked information-plus-noise type matrices. InSéminaire de Probabilités XLIX, pages 119–164. Springer, 2018
work page 2018
-
[33]
Jean Barbier, Francesco Camilli, Marco Mondelli, and Manuel Sáenz. Fundamental limits in structured principal component analysis and how to reach them.Proceedings of the National Academy of Sciences, 120(30):e2302028120, 2023
work page 2023
-
[34]
Bbp phase transition for an extensive number of outliers.arXiv preprint arXiv:2511.18501, 2025
Niklas Forner, Alexander Maloney, and Bernd Rosenow. Bbp phase transition for an extensive number of outliers.arXiv preprint arXiv:2511.18501, 2025
work page internal anchor Pith review arXiv 2025
-
[35]
Lenaic Chizat, Edouard Oyallon, and Francis Bach. On lazy training in differentiable program- ming.Advances in neural information processing systems, 32, 2019
work page 2019
-
[36]
Kernel and rich regimes in overparametrized models
Blake Woodworth, Suriya Gunasekar, Jason D Lee, Edward Moroshko, Pedro Savarese, Itay Golan, Daniel Soudry, and Nathan Srebro. Kernel and rich regimes in overparametrized models. InConference on Learning Theory, pages 3635–3673. PMLR, 2020. 12
work page 2020
-
[37]
Feature-learning networks are consistent across widths at realistic scales
Nikhil Vyas, Alexander Atanasov, Blake Bordelon, Depen Morwani, Sabarish Sainathan, and Cengiz Pehlevan. Feature-learning networks are consistent across widths at realistic scales. arXiv preprint arXiv:2305.18411, 2023
-
[38]
Dynamic theory of the spin-glass phase.Physical Review Letters, 47(5):359, 1981
Haim Sompolinsky and Annette Zippelius. Dynamic theory of the spin-glass phase.Physical Review Letters, 47(5):359, 1981
work page 1981
-
[39]
C De Dominicis. Dynamics as a substitute for replicas in systems with quenched random impurities.Physical Review B, 18(9):4913, 1978
work page 1978
-
[40]
Blake Bordelon and Cengiz Pehlevan. Disordered dynamics in high dimensions: Connections to random matrices and machine learning.arXiv preprint arXiv:2601.01010, 2026
-
[41]
Path integral approach to random neural networks.Physical Review E, 98(6):062120, 2018
A Crisanti and H Sompolinsky. Path integral approach to random neural networks.Physical Review E, 98(6):062120, 2018
work page 2018
-
[42]
David G Clark, Blake Bordelon, Jacob A Zavatone-Veth, and Cengiz Pehlevan. Structure, disorder, and dynamics in task-trained recurrent neural circuits.bioRxiv, pages 2026–03, 2026
work page 2026
-
[43]
Francesca Mignacco, Florent Krzakala, Pierfrancesco Urbani, and Lenka Zdeborová. Dynamical mean-field theory for stochastic gradient descent in gaussian mixture classification.Advances in Neural Information Processing Systems, 33:9540–9550, 2020
work page 2020
-
[44]
Francesca Mignacco and Pierfrancesco Urbani. The effective noise of stochastic gradient descent.Journal of Statistical Mechanics: Theory and Experiment, 2022(8):083405, 2022
work page 2022
-
[45]
Cedric Gerbelot, Emanuele Troiani, Francesca Mignacco, Florent Krzakala, and Lenka Zde- borova. Rigorous dynamical mean field theory for stochastic gradient descent methods.arXiv preprint arXiv:2210.06591, 2022
-
[46]
(2024) A dynamical model of neural scaling laws.arXiv preprint arXiv:2402.01092
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. A dynamical model of neural scaling laws.arXiv preprint arXiv:2402.01092, 2024
-
[47]
Blake Bordelon and Cengiz Pehlevan. Dynamics of finite width kernel and prediction fluctua- tions in mean field neural networks.arXiv preprint arXiv:2304.03408, 2023
-
[48]
Infinite limits of multi-head transformer dynamics.arXiv preprint arXiv:2405.15712, 2024
Blake Bordelon, Hamza Tahir Chaudhry, and Cengiz Pehlevan. Infinite limits of multi-head transformer dynamics.arXiv preprint arXiv:2405.15712, 2024
-
[49]
Depthwise hyperparameter transfer in residual networks: Dynamics and scaling limit
Blake Bordelon, Lorenzo Noci, Mufan Bill Li, Boris Hanin, and Cengiz Pehlevan. Depthwise hyperparameter transfer in residual networks: Dynamics and scaling limit. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[50]
Hyperparameter Transfer with Mixture-of-Expert Layers
Tianze Jiang, Blake Bordelon, Cengiz Pehlevan, and Boris Hanin. Hyperparameter transfer with mixture-of-expert layers.arXiv preprint arXiv:2601.20205, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
doi:10.48550/arXiv.2603.18168 , urldate =
Louis-Pierre Chaintron, Lénaïc Chizat, and Javier Maas. Resnets of all shapes and sizes: Convergence of training dynamics in the large-scale limit.arXiv preprint arXiv:2603.18168, 2026
-
[52]
Jinho Baik and Jack W Silverstein. Eigenvalues of large sample covariance matrices of spiked population models.Journal of multivariate analysis, 97(6):1382–1408, 2006
work page 2006
-
[53]
Scaling Laws and Spectra of Shallow Neural Networks in the Feature Learning Regime
Leonardo Defilippis, Yizhou Xu, Julius Girardin, Emanuele Troiani, Vittorio Erba, Lenka Zdeborová, Bruno Loureiro, and Florent Krzakala. Scaling laws and spectra of shallow neural networks in the feature learning regime.arXiv preprint arXiv:2509.24882, 2025
work page internal anchor Pith review arXiv 2025
-
[54]
Vittorio Erba, Emanuele Troiani, Lenka Zdeborová, and Florent Krzakala. The nuclear route: Sharp asymptotics of erm in overparameterized quadratic networks.Advances in Neural Information Processing Systems, 38:88862–88901, 2026
work page 2026
-
[55]
Fabrizio Boncoraglio, Vittorio Erba, Emanuele Troiani, Yizhou Xu, Florent Krzakala, and Lenka Zdeborová. Single-head attention in high dimensions: A theory of generalization, weights spectra, and scaling laws. InWorkshop on Scientific Methods for Understanding Deep Learning, 2025. 13
work page 2025
-
[56]
Simon Martin, Giulio Biroli, and Francis Bach. High-dimensional analysis of gradient flow for extensive-width quadratic neural networks.arXiv preprint arXiv:2601.10483, 2026
-
[57]
Bayes-optimal learning of an extensive-width neural network from quadratically many samples
Antoine Maillard, Emanuele Troiani, Simon Martin, Lenka Zdeborová, and Florent Krzakala. Bayes-optimal learning of an extensive-width neural network from quadratically many samples. Advances in Neural Information Processing Systems, 37:82085–82132, 2024
work page 2024
-
[58]
Charles H Martin and Michael W Mahoney. Heavy-tailed universality predicts trends in test accuracies for very large pre-trained deep neural networks. InProceedings of the 2020 SIAM International Conference on Data Mining, pages 505–513. SIAM, 2020
work page 2020
-
[59]
Charles H Martin and Michael W Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(165):1–73, 2021
work page 2021
-
[60]
Random matrix analysis of deep neural network weight matrices.Physical Review E, 106(5):054124, 2022
Matthias Thamm, Max Staats, and Bernd Rosenow. Random matrix analysis of deep neural network weight matrices.Physical Review E, 106(5):054124, 2022
work page 2022
-
[61]
Zhichao Wang, Andrew Engel, Anand D Sarwate, Ioana Dumitriu, and Tony Chiang. Spectral evolution and invariance in linear-width neural networks.Advances in neural information processing systems, 36:20695–20728, 2023
work page 2023
-
[62]
How two-layer neural networks learn, one (giant) step at a time
Yatin Dandi, Florent Krzakala, Bruno Loureiro, Luca Pesce, and Ludovic Stephan. How two-layer neural networks learn, one (giant) step at a time. InNeurIPS 2023 Workshop on Mathematics of Modern Machine Learning, 2023
work page 2023
-
[63]
Behrad Moniri, Donghwan Lee, Hamed Hassani, and Edgar Dobriban. A theory of non- linear feature learning with one gradient step in two-layer neural networks.arXiv preprint arXiv:2310.07891, 2023
-
[64]
Yatin Dandi, Luca Pesce, Hugo Cui, Florent Krzakala, Yue M Lu, and Bruno Loureiro. A random matrix theory perspective on the spectrum of learned features and asymptotic generalization capabilities.arXiv preprint arXiv:2410.18938, 2024
-
[65]
Hugo Cui, Luca Pesce, Yatin Dandi, Florent Krzakala, Yue M Lu, Lenka Zdeborová, and Bruno Loureiro. Asymptotics of feature learning in two-layer networks after one gradient-step.arXiv preprint arXiv:2402.04980, 2024
-
[66]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks.arXiv preprint arXiv:1312.6120, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[67]
Daniel Kunin, Allan Raventós, Clémentine Dominé, Feng Chen, David Klindt, Andrew Saxe, and Surya Ganguli. Get rich quick: exact solutions reveal how unbalanced initializations promote rapid feature learning.arXiv preprint arXiv:2406.06158, 2024
-
[68]
Clémentine CJ Dominé, Nicolas Anguita, Alexandra M Proca, Lukas Braun, Daniel Kunin, Pedro AM Mediano, and Andrew M Saxe. From lazy to rich: Exact learning dynamics in deep linear networks.arXiv preprint arXiv:2409.14623, 2024
-
[69]
Blake Bordelon and Cengiz Pehlevan. Deep linear network training dynamics from random initialization: Data, width, depth, and hyperparameter transfer.arXiv preprint arXiv:2502.02531, 2025
-
[70]
Scaling and renormalization in high-dimensional regression
Alexander B Atanasov, Jacob A Zavatone-Veth, and Cengiz Pehlevan. Scaling and renormaliza- tion in high-dimensional regression.arXiv preprint arXiv:2405.00592, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Tuning large neural networks via zero-shot hyperparameter transfer
Greg Yang, Edward J Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tuning large neural networks via zero-shot hyperparameter transfer. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021
work page 2021
-
[72]
David G. Clark and L. F. Abbott. Theory of coupled neuronal-synaptic dynamics.Phys. Rev. X, 14:021001, Apr 2024. 14
work page 2024
-
[73]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, 2009
work page 2009
-
[74]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge.International Journal of Computer Vision (IJCV), 115(3):211–252, 2015
work page 2015
-
[75]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.The Journal of Machine Learning Research, 21(1):5485–5551, 2020
work page 2020
-
[76]
ψ1(τ)− X s c0(τ, s)g(s) # (69) +i Z dτ ˆψ0(τ)·
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Michal Guerquin, Hamish Ivison, Pang Wei Koh, Jiacheng Liu, Saumya Ma- lik, Willia...
work page 2024
-
[77]
Super-wide Scaling: The network width N→ ∞ with batch size B, number of update stepsT, and input-dimensionDare held fixed. Under these assumptions, one can show using DMFT [12] that the feature structural condition holds since we have
-
[78]
Concentration of Correlations and Errors: The quantities C ϕ and C g and ∆ concentrate due to a law of large numbers effect (they are averages over neurons in each layer)
-
[79]
Decoupling of Neurons: The neurons effectively decouple in their dynamics and become iid random processes throughout training. As a consequence, we can indeed view the single-site equations as defining the features ϕ and g elementwise in terms ofχandξ ϕℓ µ(t) =ϕ ℓ µ,t {χℓ,ξ ℓ} ,g ℓ+1 µ (t) =g ℓ+1 µ,t {χℓ+1,ξ ℓ+1} ,(112) which verifies that our structural ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.