LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling
Pith reviewed 2026-06-27 01:37 UTC · model grok-4.3
The pith
Two-loop parallel transformers outperform both non-looped and multi-loop versions on code benchmarks because refinement gains are overtaken by fixed positional mismatch costs beyond two loops.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
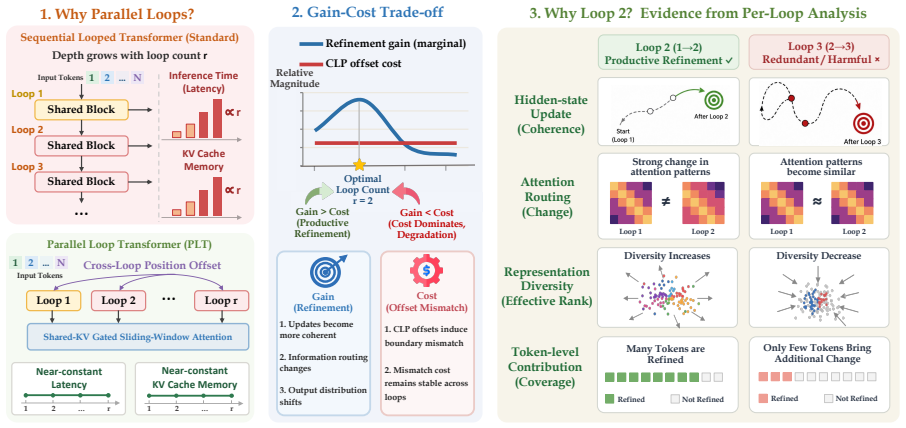
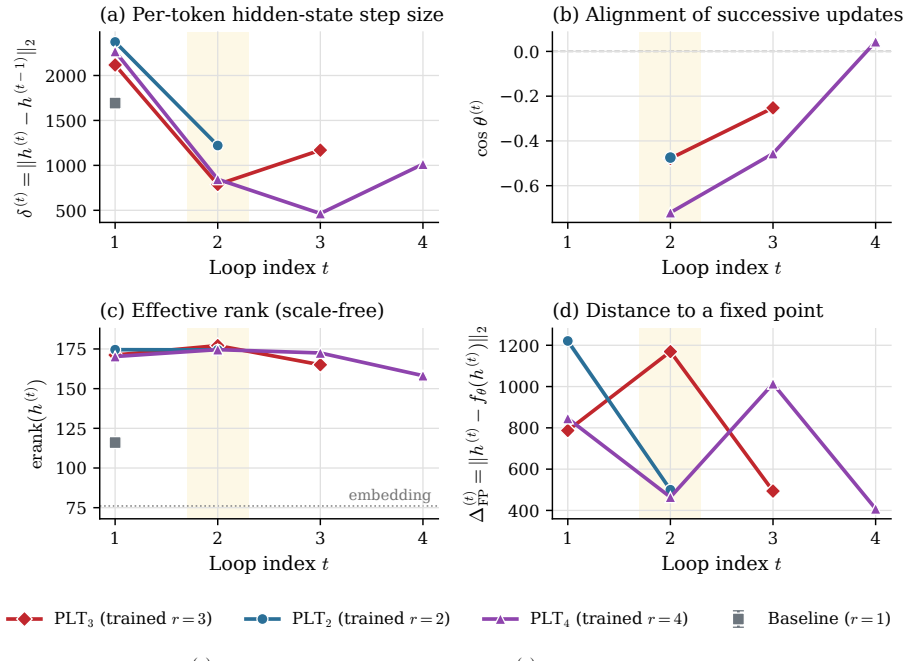
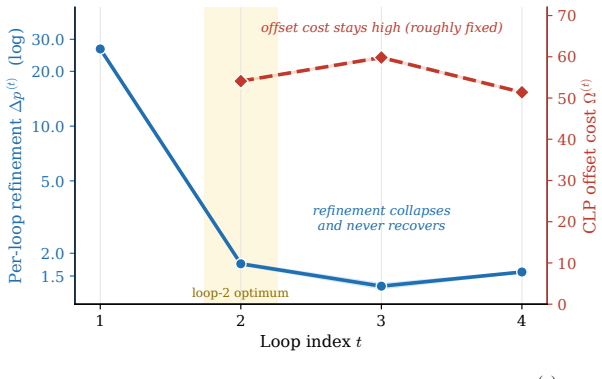
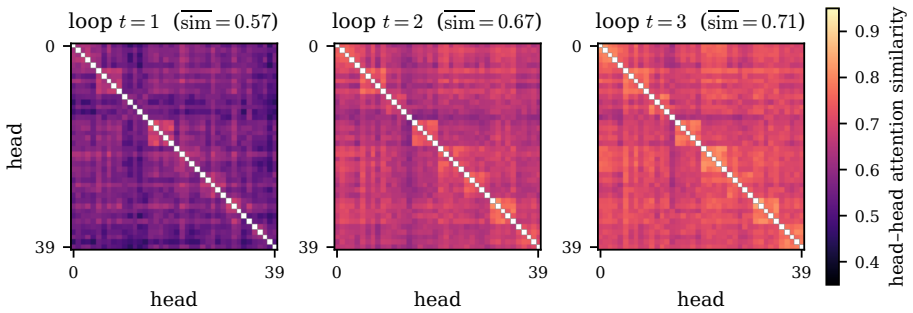
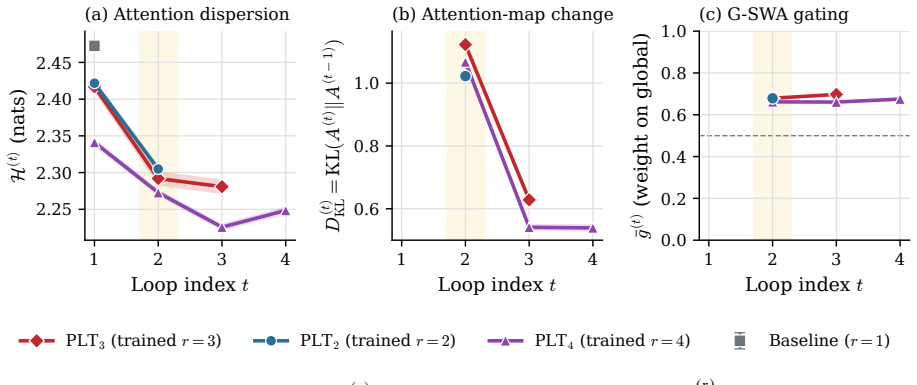
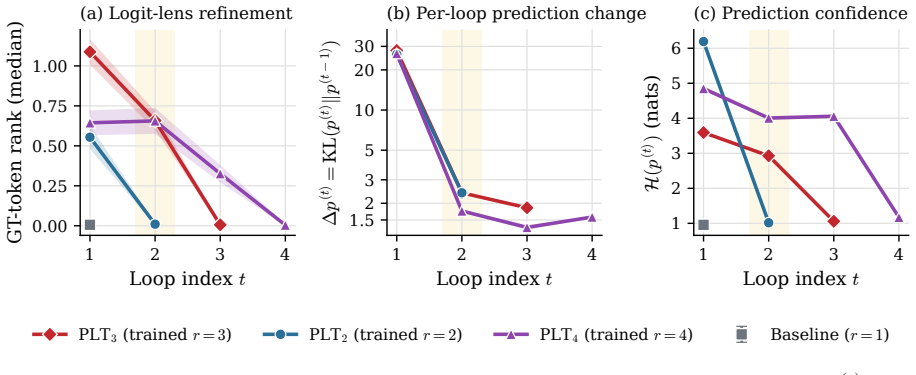
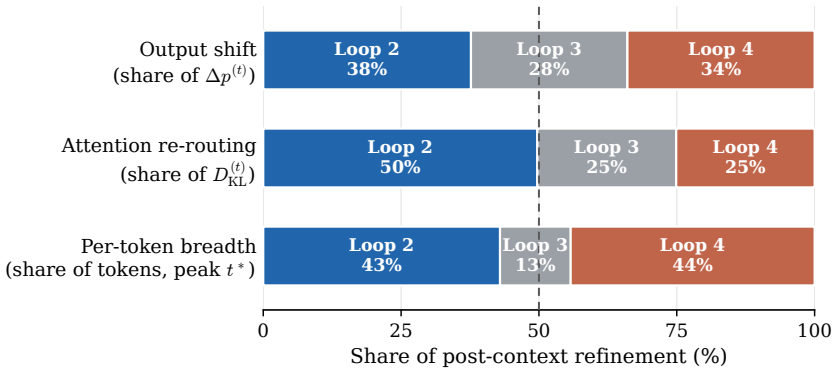
LoopCoder-v2 shows that for PLT coders the two-loop variant produces broad gains over the non-looped baseline on code generation, code reasoning, agentic software engineering and tool-use benchmarks, raising SWE-bench Verified from 43.0 to 64.4 points and Multi-SWE from 14.0 to 31.0 points, while variants with three or more loops regress. The main productive refinement occurs in the second loop; later loops yield diminishing, oscillatory updates and reduced representational diversity. Because the CLP-induced mismatch cost remains roughly fixed while refinement gains shrink, the offset cost increasingly dominates and explains why PLT saturates at two loops.
What carries the argument
Parallel Loop Transformers (PLT) with cross-loop position offsets (CLP) and shared-KV gated sliding-window attention, analyzed via a gain-cost view of loop-count selection
If this is right
- The two-loop configuration yields substantial gains on code generation, reasoning, agentic software engineering and tool-use benchmarks.
- Variants with three or more loops produce lower performance than the two-loop model.
- Loop two supplies the primary productive refinement while later loops add diminishing and oscillatory updates.
- The fixed CLP mismatch cost increasingly dominates once refinement gains shrink, producing saturation at two loops.
Where Pith is reading between the lines
- The same gain-cost pattern may appear in non-code domains if the positional mismatch mechanism behaves similarly.
- Redesigning the CLP offsets to reduce their fixed cost could allow useful performance from three or more loops.
- Running the same loop-count sweep on smaller models would test whether the two-loop optimum is size-dependent.
- The diagnostics suggest monitoring representational diversity as a cheap proxy for deciding when additional loops stop helping.
Load-bearing premise
The diagnostics correctly attribute the regression seen in three-or-more-loop models to diminishing refinement gains being overtaken by a fixed CLP-induced positional mismatch cost rather than to other training or evaluation artifacts.
What would settle it
Train otherwise identical PLT models with the cross-loop position offsets removed or neutralized and measure whether performance keeps rising or saturates differently as loop count increases past two.
Figures
read the original abstract
Looped Transformers scale latent computation by repeatedly applying shared blocks, but sequential looping increases latency and KV-cache memory with the loop count. Parallel loop Transformers (PLT) alleviate this cost through cross-loop position offsets (CLP) and shared-KV gated sliding-window attention, making loop count a practical design choice. We therefore study PLT loop-count selection through a gain--cost view: an extra loop may refine representations, but CLP also introduces a positional mismatch at each loop boundary. We instantiate this study by training LoopCoder-v2, a family of 7B PLT coders with different loop counts, from scratch on 18T tokens, followed by matched instruction tuning and evaluation. Empirically, the two-loop variant delivers broad gains over the non-looped baseline across code generation, code reasoning, agentic software engineering, and tool-use benchmarks, improving SWE-bench Verified from 43.0 to 64.4 points and Multi-SWE from 14.0 to 31.0 points. In contrast, variants with three or more loops regress, revealing a strongly non-monotonic loop-count effect. Our diagnostics show that loop 2 provides the main productive refinement, while later loops yield diminishing, oscillatory updates and reduced representational diversity. Because the CLP-induced mismatch remains roughly fixed as refinement gains shrink, the offset cost increasingly dominates. This gain--cost trade-off explains PLT's saturation at two loops and provides diagnostics for loop-count selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LoopCoder-v2, a family of 7B PLT-based code models trained from scratch on 18T tokens with varying loop counts (including a non-looped baseline), followed by matched instruction tuning. It reports that the two-loop variant yields broad gains over the baseline on code generation, reasoning, agentic software engineering, and tool-use benchmarks (e.g., SWE-bench Verified 43.0 o64.4; Multi-SWE 14.0 o31.0), while three-or-more-loop variants regress. The authors explain the strongly non-monotonic loop-count effect via a gain–cost tradeoff in which loop-2 provides the primary refinement benefit, later loops produce diminishing/oscillatory updates and lower diversity, and the roughly fixed CLP-induced positional mismatch cost increasingly dominates.
Significance. If the reported gains and non-monotonic pattern hold under further controls, the work supplies a concrete, large-scale empirical demonstration that loop count is a tunable design parameter in PLT architectures and that an optimum exists at two loops for code models. The 18T-token from-scratch training regime and the breadth of downstream benchmarks constitute a notable strength; the gain–cost framing offers a practical diagnostic lens for future loop-count selection.
major comments (1)
- [Abstract] Abstract (and the diagnostics paragraph): the causal claim that regression for ≥3 loops occurs because 'the CLP-induced mismatch remains roughly fixed as refinement gains shrink' is not isolated from alternatives. The reported patterns (diminishing updates, reduced representational diversity) are consistent with the hypothesis but could equally arise from training dynamics on the shared 18T-token run or from interactions between loop count and the shared-KV gated sliding-window attention; no ablation that directly measures or removes the mismatch term is described, leaving the fixed-cost premise untested.
minor comments (2)
- No error bars, statistical tests, or variance estimates are reported for the benchmark deltas; adding these would strengthen the claim of consistent gains.
- The precise definition of cross-loop position offsets (CLP) and the implementation details of the shared-KV gated sliding-window attention should be expanded in the methods section to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the causal framing in the abstract and diagnostics. We address the point directly below and agree that a revision is warranted to avoid overclaiming isolation of the mismatch effect.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the diagnostics paragraph): the causal claim that regression for ≥3 loops occurs because 'the CLP-induced mismatch remains roughly fixed as refinement gains shrink' is not isolated from alternatives. The reported patterns (diminishing updates, reduced representational diversity) are consistent with the hypothesis but could equally arise from training dynamics on the shared 18T-token run or from interactions between loop count and the shared-KV gated sliding-window attention; no ablation that directly measures or removes the mismatch term is described, leaving the fixed-cost premise untested.
Authors: We agree that the manuscript does not contain a direct ablation that isolates the CLP positional mismatch cost from alternative explanations such as training dynamics on the shared 18T-token corpus or interactions with the gated sliding-window attention. The reported diagnostics (diminishing/oscillatory updates and reduced diversity) are consistent with a gain-cost tradeoff but cannot by themselves rule out those alternatives. The non-monotonic pattern across loop counts provides indirect support for the interpretation, yet we acknowledge the limitation. We will revise the abstract and diagnostics paragraph to present the gain-cost account as a plausible explanation supported by the observed patterns, rather than a definitive causal claim, and will add an explicit note that no direct mismatch ablation was performed. This change will be incorporated in the next version. revision: yes
Circularity Check
No circularity: empirical model comparisons are independent of interpretive framework
full rationale
The paper reports results from training separate 7B PLT models with 0-3+ loop counts on 18T tokens, followed by instruction tuning and direct benchmark evaluation (SWE-bench, Multi-SWE, etc.). The gain-cost view is introduced as a post-hoc interpretive lens for the observed non-monotonic pattern, but the core claims rest on measured performance deltas between independently trained and evaluated models rather than any equation, fitted parameter, or self-citation that reduces the reported outcomes to the inputs by construction. No self-definitional steps, uniqueness theorems, or ansatzes appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2018 , journal =
Universal Transformers , author =. 2018 , journal =
2018
-
[2]
2023 , journal =
Looped Transformers as Programmable Computers , author =. 2023 , journal =
2023
-
[3]
arXiv preprint arXiv:2511.18538 , year=
From code foundation models to agents and applications: A comprehensive survey and practical guide to code intelligence , author=. arXiv preprint arXiv:2511.18538 , year=
-
[4]
2023 , journal =
Looped Transformers are Better at Learning Learning Algorithms , author =. 2023 , journal =
2023
-
[5]
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise
Sangmin Bae and Adam Fisch and Hrayr Harutyunyan and Ziwei Ji and Seungyeon Kim and Tal Schuster , year =. Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise. arXiv preprint , doi =
-
[6]
Manning , year =
Robert Csordas and Kazuki Irie and Jurgen Schmidhuber and Christopher Potts and Christopher D. Manning , year =
-
[7]
2024 , journal =
Recurrent Transformers with Dynamic Halt , author =. 2024 , journal =
2024
-
[8]
2025 , journal =
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach , author =. 2025 , journal =
2025
-
[9]
2025 , journal =
Efficient Parallel Samplers for Recurrent-Depth Models and Their Connection to Diffusion Language Models , author =. 2025 , journal =
2025
-
[10]
2025 , journal =
Parallel Loop Transformer for Efficient Test-Time Computation Scaling , author =. 2025 , journal =
2025
-
[11]
2025 , journal =
Two-Scale Latent Dynamics for Recurrent-Depth Transformers , author =. 2025 , journal =
2025
-
[12]
Wenquan Lu and Yuechuan Yang and Kyle Lee and Yanshu Li and Enqi Liu , year =. Latent. arXiv preprint , doi =
-
[13]
How Much Is One Recurrence Worth?
Kristian Schwethelm and Daniel Rueckert and Georgios Kaissis , year =. How Much Is One Recurrence Worth?. arXiv preprint , doi =
-
[14]
2026 , journal =
Hyperloop Transformers , author =. 2026 , journal =
2026
-
[15]
2026 , journal =
Hierarchical vs.\ Flat Iteration in Shared-Weight Transformers , author =. 2026 , journal =
2026
-
[16]
2026 , journal =
Solve the Loop: Attractor Models for Language and Reasoning , author =. 2026 , journal =
2026
-
[17]
2026 , journal =
Memory-Efficient Looped Transformer: Decoupling Compute from Memory in Looped Language Models , author =. 2026 , journal =
2026
-
[18]
arXiv preprint , doi =
Taekhyun Park and Yongjae Lee and Dohee Kim and Hyerim Bae , year =. arXiv preprint , doi =
-
[19]
2026 , journal =
Stabilizing Recurrent Dynamics for Test-Time Scalable Latent Reasoning in Looped Language Models , author =. 2026 , journal =
2026
-
[20]
2026 , journal =
Loop as a Bridge: Can Looped Transformers Truly Link Representation Space and Natural Language Outputs? , author =. 2026 , journal =
2026
-
[21]
Capps , year =
Chad A. Capps , year =. arXiv preprint , doi =
-
[22]
Chunyuan Deng and Yizhe Zhang and Rui-Jie Zhu and Yuanyuan Xu and Jiarui Liu and T. S. Eugene Ng and Hanjie Chen , year =. arXiv preprint , doi =
-
[23]
2026 , journal =
The Recurrent Transformer: Greater Effective Depth and Efficient Decoding , author =. 2026 , journal =
2026
-
[24]
2026 , journal =
Latent Recurrent Transformer: Architecture Exploration, Training Strategies, and Scaling Behavior , author =. 2026 , journal =
2026
-
[25]
2020 , journal =
Scaling Laws for Neural Language Models , author =. 2020 , journal =
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.