Benchmarking Federated Learning and Knowledge Distillation for Point Cloud Classification
Pith reviewed 2026-07-03 21:56 UTC · model grok-4.3
The pith
Hard-label terms in distillation allow high student accuracy from collapsed federated teachers by reusing proxy labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
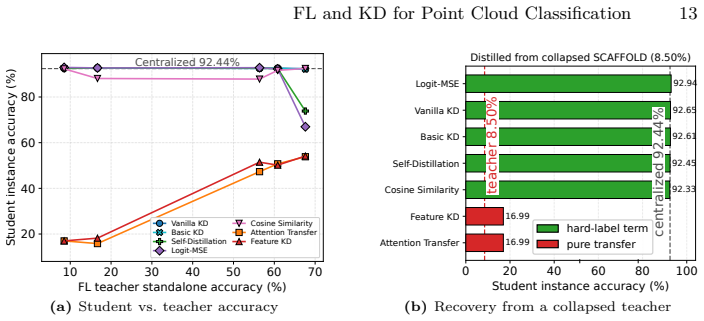
When distillation keeps a hard-label cross-entropy term on a labeled proxy split, a collapsed federated teacher (8.50 percent) paired with Logit-MSE still yields a 92.94 percent student. This 84.4-point gap reflects the proxy labels rather than the federated model, reusing the very labels whose privacy motivated federation. Objectives without hard labels instead track teacher quality (r approximately 0.99) and collapse when the teacher does.
What carries the argument
The evaluation pitfall created by retaining a hard-label cross-entropy term during distillation whenever a labeled proxy split is available.
If this is right
- Standalone federated learning under extreme non-IID label skew reaches only 76.32 percent on ModelNet40 against 92.26 percent centralized.
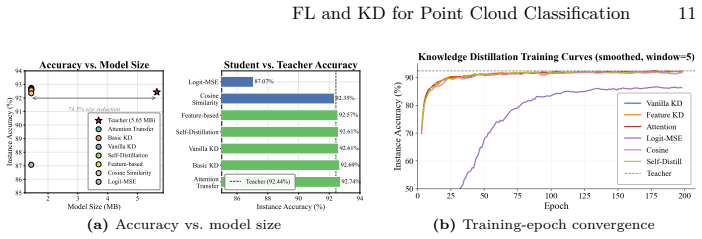
- Distillation compresses the teacher into a student 74.51 percent smaller and roughly twice as fast at inference, often matching or surpassing the teacher.
- Label-free distillation objectives track teacher quality with correlation r approximately 0.99 and collapse when the teacher does.
- On the clinical craniosynostosis dataset the best federated method reaches 75.83 percent against 100 percent centralized.
Where Pith is reading between the lines
- Evaluation protocols must avoid supervised losses on any data whose privacy the federation was meant to protect.
- The same masking effect may appear in other modalities whenever proxy labels are used to train or evaluate privacy-preserving pipelines.
- Strictly label-free distillation variants could be tested as a default for future federated model compression studies.
Load-bearing premise
The premise that student accuracy in these pipelines should measure the quality of the federated teacher rather than the availability of labeled proxy data.
What would settle it
Repeat the distillation experiment with a collapsed teacher but remove access to proxy labels for the hard-label cross-entropy term and check whether student accuracy then falls to match the teacher.
Figures
read the original abstract
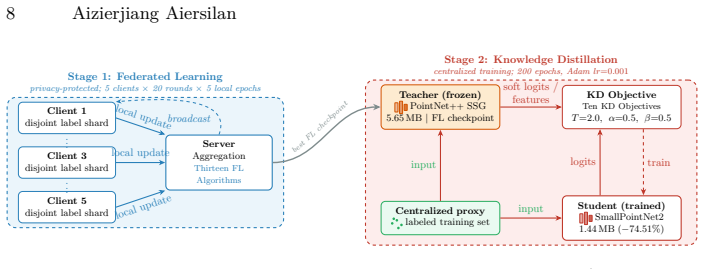
Deploying 3D point cloud analysis in privacy-sensitive, resource-constrained settings faces two barriers: data cannot be centralized, and models must run on limited edge hardware. We present a multi-seed benchmark jointly evaluating federated learning (FL) and knowledge distillation (KD) for 3D point cloud classification. It spans 13 FL algorithms and 10 KD objectives (a 130-pair cross-product) across 504 training runs, evaluated on ModelNet40 and a clinical craniosynostosis dataset. We report three findings. First, under extreme non-IID label skew, standalone FL degrades sharply: on ModelNet40, the strongest method reaches 76.32% against a 92.26% centralized reference; on clinical data, the best reaches 75.83% against 100%. Second, distillation successfully compresses the teacher into a student 74.51% smaller and roughly twice as fast at inference, often matching or surpassing the teacher. Third, the combined pipeline exposes an evaluation pitfall: when distillation keeps a hard-label cross-entropy term on a labeled proxy split, a collapsed federated teacher (8.50%) paired with Logit-MSE still yields a 92.94% student. This 84.4-point gap reflects the proxy labels rather than the federated model, reusing the very labels whose privacy motivated federation. Objectives without hard labels instead track teacher quality ($r \approx 0.99$) and collapse when the teacher does. We therefore recommend evaluating FL-KD pipelines with label-free distillation so reported accuracy reflects the federated teacher, not the proxy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a large-scale empirical benchmark jointly evaluating 13 federated learning algorithms and 10 knowledge distillation objectives (130 combinations) across 504 training runs for 3D point cloud classification. Experiments use ModelNet40 and a clinical craniosynostosis dataset under non-IID label skew. Reported findings are: (1) standalone FL degrades sharply (best 76.32% on ModelNet40 vs. 92.26% centralized; 75.83% vs. 100% on clinical data); (2) KD compresses the teacher into a student 74.51% smaller and ~2x faster at inference while often matching or exceeding teacher accuracy; (3) an evaluation pitfall exists when KD retains a hard-label cross-entropy term on labeled proxy data, as a collapsed federated teacher (8.50%) with Logit-MSE still produces a 92.94% student (84.4-point gap), whereas label-free objectives track teacher quality (r ≈ 0.99) and collapse with the teacher. The paper recommends label-free distillation so that reported student accuracy reflects the federated teacher rather than proxy labels.
Significance. The scale of the benchmark (504 runs, 130-pair cross-product) supplies a concrete empirical map of FL-KD interactions for point-cloud tasks that is rare in the literature. If the pitfall observation is accepted, the contrast between hard-label and label-free KD objectives supplies a practical diagnostic for future pipeline evaluations in privacy-sensitive domains. The work also supplies explicit compression ratios and inference-speed numbers that can serve as reference points for edge deployment.
major comments (2)
- [Abstract / pitfall discussion] Abstract and the section presenting the 84.4-point gap: the claim that this gap constitutes an 'evaluation pitfall' that 'reflects the proxy labels rather than the federated model' rests on the premise that the KD stage must not reuse hard labels from the proxy split. The manuscript does not supply an independent ablation or privacy analysis showing why such reuse is invalid once the federated teacher has already been trained; the justification is limited to a reference back to the original FL privacy motivation. This premise is load-bearing for the third finding and the final recommendation.
- [Results section on correlation] Results on label-free objectives: the reported r ≈ 0.99 correlation between teacher and student accuracy is presented as evidence that label-free KD tracks teacher quality, yet the manuscript does not state the exact number of points used for the correlation, whether it is Pearson or Spearman, or any p-value or confidence interval. Without these details the strength of the contrast with the hard-label case cannot be assessed.
minor comments (2)
- A table enumerating the 13 FL algorithms and 10 KD objectives (with their standard abbreviations) would improve readability of the 130-pair experimental design.
- The clinical craniosynostosis dataset is referenced but its size, class balance, and acquisition protocol are not summarized in the main text; a short paragraph or table entry would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / pitfall discussion] Abstract and the section presenting the 84.4-point gap: the claim that this gap constitutes an 'evaluation pitfall' that 'reflects the proxy labels rather than the federated model' rests on the premise that the KD stage must not reuse hard labels from the proxy split. The manuscript does not supply an independent ablation or privacy analysis showing why such reuse is invalid once the federated teacher has already been trained; the justification is limited to a reference back to the original FL privacy motivation. This premise is load-bearing for the third finding and the final recommendation.
Authors: The evaluation pitfall is demonstrated empirically by the 84.4-point discrepancy: a collapsed teacher (8.50%) yields a high-accuracy student (92.94%) only when a hard-label term is retained. This occurs because the student can learn directly from the proxy labels rather than from the federated teacher. The privacy motivation is central because those labels are the data whose centralization the FL setup was designed to avoid; reusing them for KD therefore defeats the purpose of evaluating the FL-KD pipeline as a whole. We agree the discussion can be strengthened and will revise the abstract and pitfall section to elaborate on this evaluation goal without relying solely on the original FL reference. A dedicated independent privacy analysis or large-scale ablation lies outside the scope of this benchmarking study. revision: partial
-
Referee: [Results section on correlation] Results on label-free objectives: the reported r ≈ 0.99 correlation between teacher and student accuracy is presented as evidence that label-free KD tracks teacher quality, yet the manuscript does not state the exact number of points used for the correlation, whether it is Pearson or Spearman, or any p-value or confidence interval. Without these details the strength of the contrast with the hard-label case cannot be assessed.
Authors: We thank the referee for noting this omission. The correlation is Pearson's r computed over the 13 FL algorithms (one point per algorithm per label-free objective), with associated p-values < 0.001. We will update the results section to report the exact number of points, confirm the correlation type, and include p-values together with 95% confidence intervals so that readers can fully assess the statistical contrast with the hard-label case. revision: yes
Circularity Check
No circularity: pure empirical benchmark with no derivations or reductions
full rationale
The paper reports experimental results across FL algorithms and KD objectives on point cloud datasets. No equations, fitted parameters, or derivation steps are present that could reduce claims to inputs by construction. The pitfall observation is an empirical contrast (high student accuracy despite collapsed teacher when using hard-label CE on proxy data) supported by direct runs and correlation measurements, not by self-definition, renaming, or self-citation chains. Central findings rest on the 504 training runs themselves rather than any load-bearing prior result from the authors.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Acar, D.A.E., Zhao, Y., Navarro, R.M., Mattina, M., Whatmough, P.N., Saligrama, V.: Federated learning based on dynamic regularization. arXiv preprint arXiv:2111.04263 (2021), https://arxiv.org/abs/2111.04263, accessed: 2026-06- 29 4, 9, 12, 28, 41, 43, 45, 47, 51, 53, 56
-
[2]
Ba, L.J., Caruana, R.: Do deep nets really need to be deep? Advances in neural infor- mation processing systems27(2014), https://proceedings.neurips.cc/paper/ 2014/hash/b0c355a9dedccb50e5537e8f2e3f0810-Abstract.html, accessed: 2026- 06-29 5, 6, 10, 12, 14, 29, 32, 44, 45, 47, 52, 56
2014
-
[3]
In: 2015 international conference on advanced robotics (ICAR)
Calli, B., Singh, A., Walsman, A., Srinivasa, S., Abbeel, P., Dollar, A.M.: The ycb object and model set: Towards common benchmarks for manipulation research. In: 2015 international conference on advanced robotics (ICAR). pp. 510–517. IEEE (2015), https://doi.org/10.1109/ICAR.2015.7251504 , accessed: 2026-06-29 5, 31
-
[4]
In: 2022 International Conference on Robotics and Automation (ICRA)
Downs, L., Francis, A., Koenig, N., Kinman, B., Hickman, R., Reymann, K., McHugh, T.B., Vanhoucke, V.: Google scanned objects: A high-quality dataset of 3d scanned household items. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 2553–2560. IEEE (2022),https://doi.org/10.1109/ ICRA46639.2022.9811809, accessed: 2026-06-29 5, 31
-
[5]
In: International conference on machine learning
Furlanello, T., Lipton, Z., Tschannen, M., Itti, L., Anandkumar, A.: Born again neural networks. In: International conference on machine learning. pp. 1607–1616. PMLR (2018), https://proceedings.mlr.press/v80/furlanello18a.html , ac- cessed: 2026-06-29 2, 4, 7, 10, 12, 14, 29, 32, 44, 45, 47, 52, 56
2018
-
[6]
Geiping,J.,Bauermeister,H.,Dröge,H.,Moeller,M.:Invertinggradients-howeasyis it to break privacy in federated learning? Advances in neural information processing systems33, 16937–16947 (2020),https://proceedings.neurips.cc/paper/2020/ hash/c4ede56bbd98819ae6112b20ac6bf145-Abstract.html, accessed: 2026-06-29 2
2020
-
[7]
Interna- tional journal of computer vision129(6), 1789–1819 (2021),https://doi.org/10
Gou, J., Yu, B., Maybank, S.J., Tao, D.: Knowledge distillation: A survey. Interna- tional journal of computer vision129(6), 1789–1819 (2021),https://doi.org/10. 1007/s11263-021-01453-z, accessed: 2026-06-29 5, 10, 12
2021
-
[8]
Guo, M.H., Cai, J.X., Liu, Z.N., Mu, T.J., Martin, R.R., Hu, S.M.: Pct: Point cloud transformer. Computational visual media7(2), 187–199 (2021),https://doi.org/ 10.1007/s41095-021-0229-5, accessed: 2026-06-29 4, 14
-
[9]
Hao, M., Li, H., Luo, X., Xu, G., Yang, H., Liu, S.: Efficient and privacy-enhanced federated learning for industrial artificial intelligence. IEEE Transactions on Indus- trial Informatics16(10), 6532–6542 (2019),https://doi.org/10.1109/TII.2019. 2945367, accessed: 2026-06-29 2
-
[10]
In: Proceedings of the IEEE/CVF international conference on computer vision
Heo, B., Kim, J., Yun, S., Park, H., Kwak, N., Choi, J.Y.: A comprehensive overhaul of feature distillation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1921–1930 (2019),https://openaccess.thecvf. com/content_ICCV_2019/html/Heo_A_Comprehensive_Overhaul_of_Feature_ Distillation_ICCV_2019_paper.html, accessed: 2026-06-29 5
1921
-
[11]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015), https://arxiv.org/abs/1503.02531 , accessed: 2026-06-29 2, 4, 6, 10, 12, 14, 29, 32, 44, 45, 47, 52, 56
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
Hsu, T.M.H., Qi, H., Brown, M.: Measuring the effects of non-identical data distribution for federated visual classification. arXiv preprint arXiv:1909.06335 (2019), https://arxiv.org/abs/1909.06335, accessed: 2026-06-29 2, 4, 9, 14, 28, 41, 43, 45, 47, 51, 54, 58 FL and KD for Point Cloud Classification 17
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Hu, Q., Yang, B., Xie, L., Rosa, S., Guo, Y., Wang, Z., Trigoni, N., Markham, A.: Randla-net: Efficient semantic segmentation of large-scale point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 11108–11117 (2020), https://openaccess.thecvf.com/content_ CVPR_2020/html/Hu_RandLA-Net_Efficient_Semantic_Se...
2020
-
[14]
arXiv preprint arXiv:2411.12377 (2024), https://arxiv.org/abs/2411.12377, accessed: 2026-06- 29 2, 4
Jimenez G., D.M., Solans, D., Heikkila, M., Vitaletti, A., Kourtellis, N., Anag- nostopoulos, A., Chatzigiannakis, I.: Non-iid data in federated learning: A survey with taxonomy, metrics, methods, frameworks and future directions. arXiv preprint arXiv:2411.12377 (2024), https://arxiv.org/abs/2411.12377, accessed: 2026-06- 29 2, 4
-
[15]
Kairouz, P., McMahan, H.B., et al.: Advances and open problems in federated learning. Foundations and trends in machine learning14(1-2), 1–210 (2021),https: //doi.org/10.1561/2200000083, accessed: 2026-06-29 2
-
[16]
In: International conference on machine learning
Karimireddy, S.P., Kale, S., Mohri, M., Reddi, S., Stich, S., Suresh, A.T.: Scaffold: Stochastic controlled averaging for federated learning. In: International conference on machine learning. pp. 5132–5143. PMLR (2020),https://proceedings.mlr. press/v119/karimireddy20a.html, accessed: 2026-06-29 4, 9, 12, 28, 41, 43, 45, 47, 51, 54, 57
2020
-
[17]
Khan, A.A., Ahmad, K.M., Shafiq, S., Amin, W., Kumar, R.: 3dffl: privacy- preserving federated few-shot learning for 3d point clouds in autonomous vehicles. Scientific Reports14(1), 19589 (2024), https://doi.org/10.1038/s41598-024- 70326-5, accessed: 2026-06-29 2
-
[18]
Medical image analysis95, 103156 (2024),https://doi.org/10
Kim, S., Park, H., Kang, M., Jin, K.H., Adeli, E., Pohl, K.M., Park, S.H.: Federated learning with knowledge distillation for multi-organ segmentation with partially labeled datasets. Medical image analysis95, 103156 (2024),https://doi.org/10. 1016/j.media.2024.103156, accessed: 2026-06-29 5
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, Q., He, B., Song, D.: Model-contrastive federated learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10713–10722 (2021),https://openaccess.thecvf.com/content/CVPR2021/html/ Li_Model-Contrastive_Federated_Learning_CVPR_2021_paper.html , accessed: 2026-06-29 4, 9, 28, 41, 43, 45, 47, 51, 52, 57
2021
-
[20]
In: International conference on machine learning
Li, T., Hu, S., Beirami, A., Smith, V.: Ditto: Fair and robust federated learning through personalization. In: International conference on machine learning. pp. 6357–6368. PMLR (2021),https://proceedings.mlr.press/v139/li21h.html , accessed: 2026-06-29 4, 9, 28, 41, 43, 45, 47, 51, 52, 57
2021
-
[21]
Li, T., Sahu, A.K., Talwalkar, A., Smith, V.: Federated learning: Challenges, methods, and future directions. IEEE signal processing magazine37(3), 50–60 (2020),https://doi.org/10.1109/MSP.2020.2975749, accessed: 2026-06-29 2
-
[22]
Li, T., Sahu, A.K., Zaheer, M., Sanjabi, M., Talwalkar, A., Smith, V.: Federated op- timization in heterogeneous networks. Proceedings of Machine learning and systems 2, 429–450 (2020),https://proceedings.mlsys.org/paper_files/paper/2020/ hash/1f5fe83998a09396ebe6477d9475ba0c-Abstract.html, accessed: 2026-06-29 4, 9, 12, 14, 28, 41, 43, 45, 47, 51, 52, 56
2020
-
[23]
Li, X., Jiang, M., Zhang, X., Kamp, M., Dou, Q.: Fedbn: Federated learning on non-iid features via local batch normalization. arXiv preprint arXiv:2102.07623 (2021), https://arxiv.org/abs/2102.07623, accessed: 2026-06-29 4, 9, 28, 41, 43, 45, 47, 51, 53, 57 18 Aizierjiang Aiersilan
-
[24]
Lin, T., Kong, L., Stich, S.U., Jaggi, M.: Ensemble distillation for robust model fu- sion in federated learning. Advances in neural information processing systems 33, 2351–2363 (2020),https://proceedings.neurips.cc/paper/2020/hash/ 18df51b97ccd68128e994804f3eccc87-Abstract.html, accessed: 2026-06-29 5, 12
2020
-
[25]
Frontiers in Communi- cations and Networks3, 907388 (2022),https://doi.org/10.3389/frcmn.2022
Liu, S., Yang, H.H., Tao, Y., Feng, Y., Hao, J., Liu, Z.: Privacy-preserved federated learning for 3d tooth segmentation in intra-oral mesh scans. Frontiers in Communi- cations and Networks3, 907388 (2022),https://doi.org/10.3389/frcmn.2022. 907388, accessed: 2026-06-29 2, 5
-
[26]
In: Federated learning: privacy and incentive, pp
Long, G., Tan, Y., Jiang, J., Zhang, C.: Federated learning for open banking. In: Federated learning: privacy and incentive, pp. 240–254. Springer (2020),https: //doi.org/10.1007/978-3-030-63076-8_17, accessed: 2026-06-29 2
-
[27]
IEEE Transactions on Industrial Informatics16(6), 4177–4186 (2019),https://doi.org/10.1109/TII
Lu, Y., Huang, X., Dai, Y., Maharjan, S., Zhang, Y.: Blockchain and federated learning for privacy-preserved data sharing in industrial iot. IEEE Transactions on Industrial Informatics16(6), 4177–4186 (2019),https://doi.org/10.1109/TII. 2019.2942190, accessed: 2026-06-29 2
work page doi:10.1109/tii 2019
-
[28]
Lu, Z., Pan, H., Dai, Y., Si, X., Zhang, Y.: Federated learning with non-iid data: A survey. IEEE Internet of Things Journal11(11), 19188–19209 (2024),https: //doi.org/10.1109/JIOT.2024.3376548, accessed: 2026-06-29 2, 4
-
[29]
In: International conference on artificial neural networks
Luo, C., Zhan, J., Xue, X., Wang, L., Ren, R., Yang, Q.: Cosine normalization: Using cosine similarity instead of dot product in neural networks. In: International conference on artificial neural networks. pp. 382–391. Springer (2018),https: //doi.org/10.1007/978-3-030-01418-6_38, accessed: 2026-06-29 5, 6, 10, 12, 14, 29, 32, 44, 45, 47, 52, 56
-
[30]
In: Artificial intelligence and statistics
McMahan, B., Moore, E., Ramage, D., Hampson, S., y Arcas, B.A.: Communication- efficient learning of deep networks from decentralized data. In: Artificial intelligence and statistics. pp. 1273–1282. Pmlr (2017),https://proceedings.mlr.press/v54/ mcmahan17a.html, accessed: 2026-06-29 2, 4, 9, 12, 28, 41, 43, 45, 47, 51, 52, 57
2017
-
[31]
Medical Image Analysis18(4), 635–646 (2014),https://doi.org/10.1016/j.media.2014
Mendoza, C.S., Safdar, N., Okada, K., Myers, E., Rogers, G.F., Linguraru, M.G.: Personalized assessment of craniosynostosis via statistical shape modeling. Medical Image Analysis18(4), 635–646 (2014),https://doi.org/10.1016/j.media.2014. 02.008, accessed: 2026-06-29 31
-
[32]
IEEE communications surveys & tutorials23(3), 1622–1658 (2021),https://doi.org/10.1109/COMST
Nguyen, D.C., Ding, M., Pathirana, P.N., Seneviratne, A., Li, J., Poor, H.V.: Feder- ated learning for internet of things: A comprehensive survey. IEEE communications surveys & tutorials23(3), 1622–1658 (2021),https://doi.org/10.1109/COMST. 2021.3075439, accessed: 2026-06-29 2
-
[33]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Park, W., Kim, D., Lu, Y., Cho, M.: Relational knowledge distillation. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 3967–3976 (2019),https://openaccess.thecvf.com/content_CVPR_ 2019/html/Park_Relational_Knowledge_Distillation_CVPR_2019_paper.html , accessed: 2026-06-29 4, 7, 14, 29, 32, 44, 45, 47, 52, 56
2019
-
[34]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 652–660 (2017),https://openaccess. thecvf.com/content_cvpr_2017/html/Qi_PointNet_Deep_Learning_CVPR_2017_ paper.html, accessed: 2026-06-29 2, 4
2017
-
[35]
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information pro- cessing systems30(2017), https://proceedings.neurips.cc/paper/2017/hash/ d8bf84be3800d12f74d8b05e9b89836f-Abstract.html, accessed: 2026-06-29 2, 4, 6, 10, 32, 44 FL and KD for Point Cloud Classification 19
2017
-
[36]
Qian, G., Li, Y., Peng, H., Mai, J., Hammoud, H., Elhoseiny, M., Ghanem, B.: Pointnext: Revisiting pointnet++ with improved training and scaling strategies. Advances in neural information processing systems35, 23192– 23204 (2022), https://proceedings.neurips.cc/paper_files/paper/2022/ hash / 9318763d049edf9a1f2779b2a59911d3 - Abstract - Conference . html,...
2022
-
[37]
Qin, L., Zhu, T., Zhou, W., Yu, P.S.: Knowledge distillation in federated learning: A survey on long lasting challenges and new solutions. International Journal of Intelligent Systems2025(1), 7406934 (2025), https://doi.org/10.1155/int/ 7406934, accessed: 2026-06-29 2, 5
-
[38]
Adaptive Federated Optimization
Reddi, S., Charles, Z., Zaheer, M., Garrett, Z., Rush, K., Konečn` y, J., Kumar, S., McMahan, H.B.: Adaptive federated optimization. arXiv preprint arXiv:2003.00295 (2020), https://arxiv.org/abs/2003.00295, accessed: 2026-06-29 4, 8, 9, 14, 28, 41, 43, 45, 47, 51, 54, 55, 58, 59
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[39]
Rieke, N., Hancox, J., Li, W., Milletari, F., Roth, H.R., Albarqouni, S., Bakas, S., Galtier, M.N., Landman, B.A., Maier-Hein, K., et al.: The future of digital health with federated learning. NPJ digital medicine3(1), 119 (2020), https: //doi.org/10.1038/s41746-020-00323-1, accessed: 2026-06-29 2, 5, 12
-
[40]
FitNets: Hints for Thin Deep Nets
Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550 (2014),https://arxiv. org/abs/1412.6550, accessed: 2026-06-29 2, 4, 7, 10, 12, 14, 29, 32, 44, 45, 47, 52, 56
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[41]
In: 2025 IEEE/CVF Winter Conference on Ap- plications of Computer Vision (WACV)
Sanjay, S., Akash, J., Dimple, A.S., et al.: Adversarial learning based knowledge distillation on 3d point clouds. In: 2025 IEEE/CVF Winter Conference on Ap- plications of Computer Vision (WACV). pp. 2932–2941. IEEE (2025),https: //openaccess.thecvf.com/content/WACV2025/html/J_Adversarial_Learning_ Based_Knowledge_Distillation_on_3D_Point_Clouds_WACV_2025...
2025
-
[42]
Sarker, S., Sarker, P., Stone, G., Gorman, R., Tavakkoli, A., Bebis, G., Sattarvand, J.: A comprehensive overview of deep learning techniques for 3d point cloud classification and semantic segmentation. Machine Vision and Applications35(4) (2024),https://doi.org/10.1007/s00138-024-01543-1, accessed: 2026-06-29 4
-
[43]
Schaufelberger, M., Kühle, R., Wachter, A., Weichel, F., Hagen, N., Ringwald, F., Eisenmann, U., Hoffmann, J., Engel, M., Freudlsperger, C., et al.: A statistical shape model of craniosynostosis patients and 100 model instances of each pathology. Zen- odo: Geneve, Switzerland (2021),https://doi.org/10.5281/zenodo.10167123 , accessed: 2026-06-29 2, 5, 31
-
[44]
Sheller, M.J., Edwards, B., Reina, G.A., et al.: Federated learning in medicine: facilitating multi-institutional collaborations without sharing patient data. Scientific Reports10, 12598 (Jul 2020), https://doi.org/10.1038/s41598-020-69250-1 , accessed: 2026-06-29 2, 5, 12
-
[45]
In: Proceedings of the IEEE/CVF international conference on computer vision
Thomas, H., Qi, C.R., Deschaud, J.E., Marcotegui, B., Goulette, F., Guibas, L.J.: Kpconv: Flexible and deformable convolution for point clouds. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 6411–6420 (2019), https://openaccess.thecvf.com/content_ICCV_2019/html/Thomas_KPConv_ Flexible_and_Deformable_Convolution_for_Point_...
2019
-
[46]
Contrastive representation distillation.arXiv preprint arXiv:1910.10699, 2019
Tian, Y., Krishnan, D., Isola, P.: Contrastive representation distillation. arXiv preprint arXiv:1910.10699 (2019),https://arxiv.org/abs/1910.10699, accessed: 2026-06-29 4, 7, 14, 29, 32, 44, 45, 47, 52, 56 20 Aizierjiang Aiersilan
-
[47]
In: Proceedings of the IEEE/CVF international conference on computer vision
Tung, F., Mori, G.: Similarity-preserving knowledge distillation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1365–1374 (2019), https://openaccess.thecvf.com/content_ICCV_2019/html/Tung_Similarity- Preserving_Knowledge_Distillation_ICCV_2019_paper.html, accessed: 2026-06- 29 4, 7, 14, 29, 32, 44, 45, 47, 52, 56
2019
-
[48]
Advances in neural infor- mation processing systems33, 7611–7623 (2020),https://proceedings.neurips
Wang, J., Liu, Q., Liang, H., Joshi, G., Poor, H.V.: Tackling the objective inconsis- tency problem in heterogeneous federated optimization. Advances in neural infor- mation processing systems33, 7611–7623 (2020),https://proceedings.neurips. cc/paper/2020/hash/564127c03caab942e503ee6f810f54fd- Abstract.html , ac- cessed: 2026-06-29 4, 9, 28, 41, 43, 45, 4...
2020
-
[49]
Wang, Y., Sun, Y., Liu, Z., Sarma, S.E., Bronstein, M.M., Solomon, J.M.: Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics (tog)38(5), 1–12 (2019),https://doi.org/10.1145/3326362, accessed: 2026-06-29 4
-
[50]
In: 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR)
Wu, T., Zhang, J., Fu, X., Wang, Y., Ren, J., Pan, L., Wu, W., Yang, L., Wang, J., Qian, C., et al.: Omniobject3d: Large-vocabulary 3d object dataset for realistic perception, reconstruction and generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 803–814 (2023),https: //doi.org/10.1109/CVPR52729.2023.0008...
-
[51]
Wu, X., Lao, Y., Jiang, L., Liu, X., Zhao, H.: Point transformer v2: Grouped vector attention and partition-based pooling. Advances in Neural Information Processing Systems35, 33330–33342 (2022),https://proceedings.neurips.cc/ paper_files/paper/2022/hash/d78ece6613953f46501b958b7bb4582f-Abstract- Conference.html, accessed: 2026-06-29 4, 14
2022
-
[52]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., Xiao, J.: 3d shapenets: A deep representation for volumetric shapes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1912–1920 (2015),https:// openaccess.thecvf.com/content_cvpr_2015/html/Wu_3D_ShapeNets_A_2015_ CVPR_paper.html, accessed: 2026-06-29 2, 3, 5, 31, 60
1912
-
[53]
Yang, Q., Liu, Y., Chen, T., Tong, Y.: Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST) 10(2), 1–19 (2019),https://doi.org/10.1145/3298981, accessed: 2026-06-29 2
-
[54]
In: International conference on machine learning
Yin, D., Chen, Y., Kannan, R., Bartlett, P.: Byzantine-robust distributed learning: Towards optimal statistical rates. In: International conference on machine learning. pp. 5650–5659. Pmlr (2018),https://proceedings.mlr.press/v80/yin18a.html, accessed: 2026-06-29 4, 9, 28, 41, 43, 45, 47, 51, 53, 58
2018
-
[55]
Electronics11(23), 4039 (2022),https://doi.org/10.3390/electronics11234039, accessed: 2026-06-29 5
Yu, L., Huang, J.: Cyclic federated learning method based on distribution informa- tion sharing and knowledge distillation for medical data. Electronics11(23), 4039 (2022),https://doi.org/10.3390/electronics11234039, accessed: 2026-06-29 5
-
[56]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yuan, L., Tay, F.E., Li, G., Wang, T., Feng, J.: Revisiting knowledge distil- lation via label smoothing regularization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3903–3911 (2020), https://openaccess.thecvf.com/content_CVPR_2020/html/Yuan_Revisiting_ Knowledge_Distillation_via_Label_Smoothing_Regularization...
2020
-
[57]
Zagoruyko, S., Komodakis, N.: Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv preprint arXiv:1612.03928 (2016),https://arxiv.org/abs/1612.03928, accessed: 2026-06-29 2, 4, 7, 10, 12, 14, 29, 32, 44, 45, 47, 52, 56 FL and KD for Point Cloud Classification 21
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[58]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, L., Dong, R., Tai, H.S., Ma, K.: Pointdistiller: Structured knowl- edge distillation towards efficient and compact 3d detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21791–21801 (2023),https://openaccess.thecvf.com/content/CVPR2023/ html/Zhang_PointDistiller_Structured_Knowledge_Distillation_Tow...
2023
-
[59]
In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition
Zhao, B., Cui, Q., Song, R., Qiu, Y., Liang, J.: Decoupled knowledge distil- lation. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. pp. 11953–11962 (2022),https://openaccess.thecvf.com/ content/CVPR2022/html/Zhao_Decoupled_Knowledge_Distillation_CVPR_2022_ paper.html, accessed: 2026-06-29 4, 6, 14, 29, 32, 44, 45, 4...
2022
-
[60]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhao, H., Jiang, L., Jia, J., Torr, P.H., Koltun, V.: Point transformer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 16259–16268 (2021), https://openaccess.thecvf.com/content/ICCV2021/html/Zhao_Point_ Transformer_ICCV_2021_paper.html, accessed: 2026-06-29 4
2021
-
[61]
Benchmarking Federated Learning & Knowledge Distillation for Point Cloud Classification
Zhu, L., Liu, Z., Han, S.: Deep leakage from gradients. Advances in neural infor- mation processing systems32(2019), https://proceedings.neurips.cc/paper/ 2019/hash/60a6c4002cc7b29142def8871531281a-Abstract.html, accessed: 2026- 06-29 2 Benchmarking Federated Learning & Knowledge Distillation for Point Cloud Classification Supplementary Material Aizierjia...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.