FunduSegmenter: Leveraging the RETFound Foundation Model for Joint Optic Disc and Optic Cup Segmentation in Retinal Fundus Images
Pith reviewed 2026-05-18 22:55 UTC · model grok-4.3
The pith
Adapting RETFound with new adapters and a decoder enables accurate joint optic disc and optic cup segmentation in fundus images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
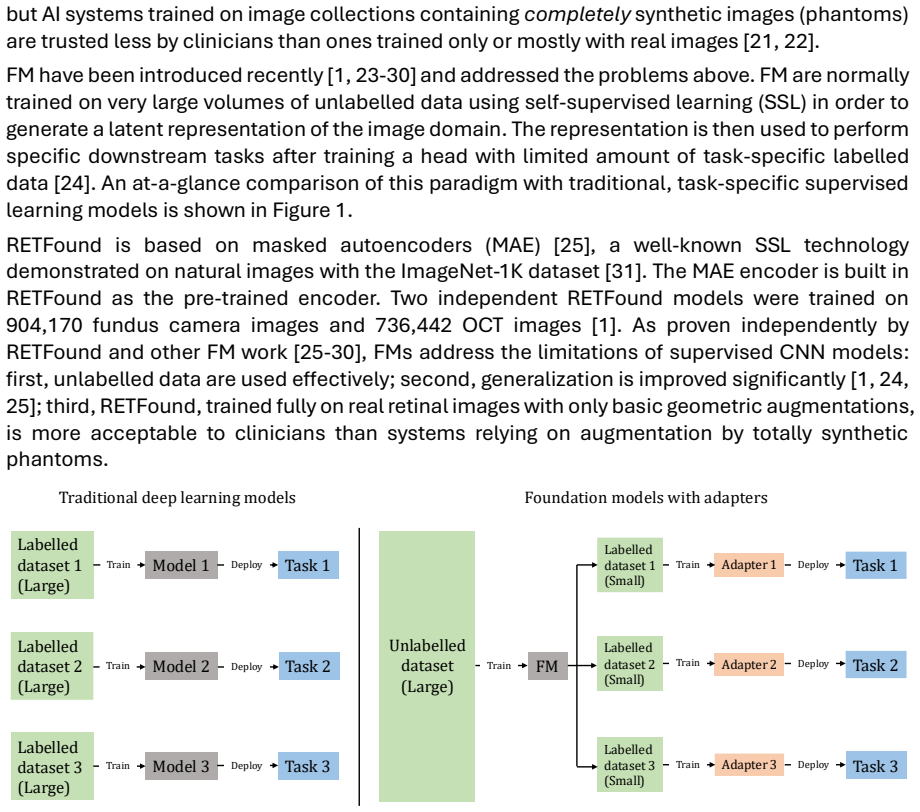
The study introduces FunduSegmenter as the first adaptation of RETFound for joint optic disc and optic cup segmentation. By combining RETFound with a Pre-adapter, Decoder, Post-adapter, CBAM skip connections, and ViT block adapter, the model achieves an average Dice similarity coefficient of 90.51 percent in internal verification, surpassing nnU-Net at 82.91 percent, DUNet at 89.17 percent, and TransUNet at 87.91 percent. External verification experiments produce results about three percent higher than the best baseline, and the model remains competitive in domain generalization tests across a proprietary dataset and four public ones.
What carries the argument
FunduSegmenter, a model that attaches a Pre-adapter, Decoder, Post-adapter, CBAM-equipped skip connections, and ViT block adapter to the RETFound vision transformer backbone to produce joint optic disc and optic cup segmentation masks.
If this is right
- The proposed modules can be reused to adapt other foundation models for medical image segmentation tasks.
- Stable optic disc and optic cup outlines support downstream steps such as setting retinal coordinates and discovering biomarkers.
- The approach maintains performance when the imaging source changes, reducing the need for retraining on every new dataset.
- Joint segmentation of both structures in one pass supplies the cup-to-disc ratio directly for glaucoma-related analysis.
Where Pith is reading between the lines
- The same adapter pattern may help transfer other large pre-trained models to additional retinal or ophthalmic segmentation problems.
- Because the model leverages general representations already learned by RETFound, it may require fewer labeled examples than training a segmentation network from scratch.
- If the performance edge holds on larger multi-center collections, the method could support automated screening pipelines that run across different hospitals without per-site retraining.
Load-bearing premise
The custom adapter and decoder modules developed for RETFound will continue to improve segmentation accuracy when applied to new clinical datasets or other foundation models.
What would settle it
A test on a new retinal fundus dataset from an unseen camera type or patient population where the average Dice score drops below the best baseline by more than two percentage points.
Figures

read the original abstract
Purpose: This study introduces the first adaptation of RETFound for joint optic disc (OD) and optic cup (OC) segmentation. RETFound is a well-known foundation model developed for fundus camera and optical coherence tomography images, which has shown promising performance in disease diagnosis. Methods: We propose FunduSegmenter, a model integrating a series of novel modules with RETFound, including a Pre-adapter, a Decoder, a Post-adapter, skip connections with Convolutional Block Attention Module and a Vision Transformer block adapter. The model is evaluated on a proprietary dataset, GoDARTS, and four public datasets, IDRiD, Drishti-GS, RIM-ONE-r3, and REFUGE, through internal verification, external verification and domain generalization experiments. Results: An average Dice similarity coefficient of 90.51% was achieved in internal verification, which outperformed all baselines, some substantially (nnU-Net: 82.91%; DUNet: 89.17%; TransUNet: 87.91%). In all external verification experiments, the average results were about 3% higher than those of the best baseline, and our model was also competitive in domain generalization. Conclusions: This study explored the potential of the latent general representations learned by RETFound for OD and OC segmentation in fundus camera images. Our FunduSegmenter generally outperformed state-of-the-art baseline methods. The proposed modules are general and can be extended to fine-tuning other foundation models. Translational Relevance: The model shows strong stability and generalization on both in-distribution and out-of-distribution data, providing stable OD and OC segmentation. This is an essential step for many automated tasks, from setting the accurate retinal coordinate to biomarker discovery. The code and trained weights are available at: https://github.com/JusticeZzy/FunduSegmenter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FunduSegmenter as the first adaptation of the RETFound foundation model for joint optic disc (OD) and optic cup (OC) segmentation in retinal fundus images. It integrates novel modules including a Pre-adapter, Decoder, Post-adapter, CBAM skip connections, and ViT block adapter. Evaluation occurs on the proprietary GoDARTS dataset plus public sets (IDRiD, Drishti-GS, RIM-ONE-r3, REFUGE) via internal verification, external verification, and domain generalization experiments. Key results include an average Dice of 90.51% internally (outperforming nnU-Net at 82.91%, DUNet at 89.17%, TransUNet at 87.91%), with external results ~3% above the best baseline and competitive domain generalization. Code and trained weights are released publicly.
Significance. If the reported empirical gains hold under fuller scrutiny, the work would be significant for showing how RETFound's latent representations can be adapted for precise OD/OC segmentation, a prerequisite for automated retinal coordinate setting and biomarker tasks. The ~3% external improvement and stability claims, if verified, would advance foundation-model use in ophthalmology. A clear strength is the public release of code and weights, which directly supports reproducibility and extension by others. The significance is currently limited by the absence of details needed to rule out artifacts in the performance claims.
major comments (3)
- [Methods] Methods section: the training protocol, hyperparameters (learning rate, batch size, epochs, loss weights), exact loss formulation, and any statistical tests for the significance of Dice improvements (e.g., paired t-tests or confidence intervals on the 90.51% vs. baseline figures) are not described, preventing verification that gains are free of post-hoc selection or implementation artifacts as noted in the soundness assessment.
- [Results] Results and Experiments sections: no ablation studies or module-specific contribution analysis are provided for the Pre-adapter, Decoder, Post-adapter, CBAM skips, and ViT adapter, making it impossible to confirm that these components drive the reported outperformance or that they transfer usefully to other foundation models as claimed in the Conclusions.
- [Experiments] Domain generalization experiments: the claim of competitive generalization and strong stability rests on the mix of GoDARTS plus IDRiD/Drishti-GS/RIM-ONE-r3/REFUGE being representative; without explicit analysis of camera models, resolutions, or demographic differences across these sets, the ~3% external gain may not extend to truly unseen clinical distributions (different vendors or acquisition protocols).
minor comments (2)
- [Abstract] Abstract: the statement that external results are 'about 3% higher' lacks per-dataset breakdowns or exact metric specification, reducing clarity for readers.
- [Conclusions] Conclusions: the assertion that the modules 'are general and can be extended to fine-tuning other foundation models' is stated without supporting cross-model experiments or discussion, though this is a presentation rather than load-bearing issue.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our manuscript. We have carefully considered each point and will revise the paper accordingly to improve its clarity, reproducibility, and robustness. Our detailed responses are provided below.
read point-by-point responses
-
Referee: [Methods] Methods section: the training protocol, hyperparameters (learning rate, batch size, epochs, loss weights), exact loss formulation, and any statistical tests for the significance of Dice improvements (e.g., paired t-tests or confidence intervals on the 90.51% vs. baseline figures) are not described, preventing verification that gains are free of post-hoc selection or implementation artifacts as noted in the soundness assessment.
Authors: We fully agree that these details are essential for reproducibility and to rule out potential artifacts. The manuscript's Methods section provided an overview but lacked the specific values. In the revised manuscript, we will add a comprehensive description of the training protocol, including the learning rate (set to 0.0001 with a step decay scheduler), batch size (16), number of epochs (150), loss function (Dice loss combined with binary cross-entropy, with equal weights), and statistical tests (we will report paired t-test p-values and 95% confidence intervals for the Dice score comparisons). These parameters were fixed before running the final experiments. We believe this addition will strengthen the soundness of our claims. revision: yes
-
Referee: [Results] Results and Experiments sections: no ablation studies or module-specific contribution analysis are provided for the Pre-adapter, Decoder, Post-adapter, CBAM skips, and ViT adapter, making it impossible to confirm that these components drive the reported outperformance or that they transfer usefully to other foundation models as claimed in the Conclusions.
Authors: We acknowledge this limitation in the current version. Although the overall performance gains suggest the effectiveness of the integrated modules, explicit ablations would better isolate their contributions. We will include an ablation study in the revised Experiments section, presenting results for the model with each module ablated one at a time, as well as cumulative additions. This will quantify the impact on the average Dice score. For the claim about extending to other foundation models, we will tone down the language to 'potentially generalizable' and note that the modular adapters are designed with this in mind, supported by the ablation evidence. revision: yes
-
Referee: [Experiments] Domain generalization experiments: the claim of competitive generalization and strong stability rests on the mix of GoDARTS plus IDRiD/Drishti-GS/RIM-ONE-r3/REFUGE being representative; without explicit analysis of camera models, resolutions, or demographic differences across these sets, the ~3% external gain may not extend to truly unseen clinical distributions (different vendors or acquisition protocols).
Authors: We agree that a more detailed characterization of the datasets would help contextualize the generalization results. In the revision, we will add an analysis of the domain differences, including a table listing the fundus camera types (e.g., Topcon, Zeiss), image resolutions, and any demographic data available in the datasets. We will discuss how these factors contribute to domain shift and why our results indicate competitive performance despite these variations. This will provide a more solid foundation for the stability claims. revision: yes
Circularity Check
No circularity: empirical results on held-out data
full rationale
The paper proposes FunduSegmenter as an adaptation of the external RETFound foundation model, adding modules such as Pre-adapter, Decoder, Post-adapter, CBAM skip connections and ViT block adapter. It reports Dice scores from training and testing on a mix of proprietary GoDARTS and public datasets (IDRiD, Drishti-GS, RIM-ONE-r3, REFUGE) using standard internal/external verification and domain generalization splits. All performance numbers are computed on held-out test images against independent baselines (nnU-Net, DUNet, TransUNet). No equations, uniqueness theorems, or predictions are defined in terms of the reported metrics themselves, and no self-citation chain is invoked to justify the core claims. The evaluation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- training hyperparameters (learning rate, batch size, epochs, loss weights)
axioms (1)
- domain assumption RETFound latent representations are transferable to the segmentation task when augmented with the proposed adapters
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adapt Segmenter's decoder to be used with RETFound... froze the weights of RETFound, and removed the MLP layer and the class token
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Loss functions: combination of Dice loss and Binary Cross Entropy loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
TAPE: A two-stage parameter-efficient adaptation framework for foundation models in OCT-OCTA analysis
TAPE decouples domain alignment from task fitting using parameter-efficient fine-tuning to adapt foundation models for superior OCT-OCTA segmentation with high efficiency.
Reference graph
Works this paper leans on
-
[1]
Zhou, Y ., Chia, M. A., Wagner, S. K., Ayhan, M. S., Williamson, D. J., Struyven, R. R., ... & Keane, P . A. (2023). A foundation model for generalizable disease detection from retinal images. Nature, 622(7981), 156-163
work page 2023
-
[2]
Mookiah, M. R. K., Hogg, S., MacGillivray, T., & Trucco, E. (2021). On the quantitative effects of compression of retinal fundus images on morphometric vascular measurements in VAMPIRE. Computer Methods and Programs in Biomedicine, 202, 105969
work page 2021
-
[3]
Wang, S., Yu, L., Li, K., Yang, X., Fu, C. W., & Heng, P . A. (2020). DOFE: Domain -oriented feature embedding for generalizable fundus image segmentation on unseen datasets. IEEE Transactions on Medical Imaging, 39(12), 4237-4248
work page 2020
-
[4]
Porwal, P ., Pachade, S., Kamble, R., Kokare, M., Deshmukh, G., Sahasrabuddhe, V ., & Meriaudeau, F . (2018). Indian diabetic retinopathy image dataset (IDRiD): a database for diabetic retinopathy screening research. Data, 3(3), 25
work page 2018
-
[5]
Sivaswamy, J., Krishnadas, S., Chakravarty, A., Joshi, G., & Tabish, A. S. (2015). A comprehensive retinal image dataset for the assessment of glaucoma from the optic nerve head analysis. JSM Biomedical Imaging Data Papers, 2(1), 1004
work page 2015
-
[6]
L., Sigut, J., & Gonzalez-Hernandez, M
Fumero, F ., Alayón, S., Sanchez, J. L., Sigut, J., & Gonzalez-Hernandez, M. (2011, June). RIM- ONE: An open retinal image database for optic nerve evaluation. In 2011 24th international symposium on computer-based medical systems (CBMS) (pp. 1-6). IEEE
work page 2011
-
[7]
Orlando, J. I., Fu, H., Breda, J. B., Van Keer, K., Bathula, D. R., Diaz-Pinto, A., ... & Bogunović, H. (2020). Refuge challenge: A unified framework for evaluating automated methods for glaucoma assessment from fundus photographs. Medical image analysis, 59, 101570
work page 2020
-
[8]
Perez-Rovira, A., MacGillivray, T., Trucco, E., Chin, K. S., Zutis, K., Lupascu, C., ... & Dhillon, B. (2011, August). VAMPIRE: Vessel assessment and measurement platform for images of the REtina. In 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society (pp. 3391-3394). IEEE
work page 2011
-
[9]
Xie Z, Ling T, Yang Y , Shu R, Liu BJ. Optic disc and cup image segmentation utilizing contour- based transformation and sequence labeling networks. Journal of Medical Systems. 2020 May;44:1-3. 14
work page 2020
-
[10]
Optic disc and optic cup segmentation based on anatomy guided cascade network
Bian X, Luo X, Wang C, Liu W, Lin X. Optic disc and optic cup segmentation based on anatomy guided cascade network. Computer Methods and Programs in Biomedicine. 2020 Dec 1;197:105717
work page 2020
-
[11]
Screening of glaucoma disease from retinal vessel images using semantic segmentation
Imtiaz R, Khan TM, Naqvi SS, Arsalan M, Nawaz SJ. Screening of glaucoma disease from retinal vessel images using semantic segmentation. Computers & Electrical Engineering. 2021 May 1;91:107036
work page 2021
-
[12]
NENet: Nested EfficientNet and adversarial learning for joint optic disc and cup segmentation
Pachade S, Porwal P , Kokare M, Giancardo L, Mériaudeau F . NENet: Nested EfficientNet and adversarial learning for joint optic disc and cup segmentation. Medical Image Analysis. 2021 Dec 1;74:102253
work page 2021
-
[13]
Deep level set learning for optic disc and cup segmentation
Yin P , Xu Y , Zhu J, Liu J, Huang H, Wu Q. Deep level set learning for optic disc and cup segmentation. Neurocomputing. 2021 Nov 13;464:330-41
work page 2021
-
[14]
Joshi A, Sharma KK. Graph deep network for optic disc and optic cup segmentation for glaucoma disease using retinal imaging. Physical and Engineering Sciences in Medicine. 2022 Sep;45(3):847-58
work page 2022
-
[15]
S., Rouco, J., Novo, J., & Ortega, M
Hervella, Á. S., Rouco, J., Novo, J., & Ortega, M. (2022). End -to-end multi-task learning for simultaneous optic disc and cup segmentation and glaucoma classification in eye fundus images. Applied Soft Computing, 116, 108347
work page 2022
- [16]
-
[17]
Tang, S., Song, C., Wang, D., Gao, Y ., Liu, Y ., & Lv, W. (2024). W -Net: A boundary -aware cascade network for robust and accurate optic disc segmentation. Iscience, 27(1)
work page 2024
-
[18]
Zhou, Z., Qi, L., & Shi, Y . (2022, October). Generalizable medical image segmentation via random amplitude mixup and domain -specific image restoration. In European Conference on Computer Vision (pp. 420-436). Cham: Springer Nature Switzerland
work page 2022
-
[19]
Chen, J., He, T., Zhuo, W., Ma, L., Ha, S., & Chan, S. H. G. (2022). Tvconv: Efficient translation variant convolution for layout -aware visual processing. In proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 12548-12558)
work page 2022
-
[20]
Hua, K., Fang, X., Tang, Z., Cheng, Y ., & Yu, Z. (2023). DCAM -NET: A novel domain generalization optic cup and optic disc segmentation pipeline with multi -region and multi- scale convolution attention mechanism. Computers in Biology and Medicine, 163, 107076
work page 2023
-
[21]
Chen, J. S., Coyner, A. S., Chan, R. P ., Hartnett, M. E., Moshfeghi, D. M., Owen, L. A., ... & Campbell, J. P . (2021). Deepfakes in ophthalmology: applications and realism of synthetic retinal images from generative adversarial networks. Ophthalmology Science, 1(4), 100079
work page 2021
-
[22]
A., Woof, W., Lazebnik, T., Moghul, I., Woodward -Court, P ., Wagner, S
Veturi, Y . A., Woof, W., Lazebnik, T., Moghul, I., Woodward -Court, P ., Wagner, S. K., ... & Pontikos, N. (2023). SynthEye: investigating the impact of synthetic data on artificial intelligence-assisted gene diagnosis of inherited retinal disease. Ophthalmo logy Science, 3(2), 100258
work page 2023
-
[23]
Moor, M., Banerjee, O., Abad, Z. S. H., Krumholz, H. M., Leskovec, J., Topol, E. J., & Rajpurkar, P . (2023). Foundation models for generalist medical artificial intelligence. Nature, 616(7956), 259-265
work page 2023
-
[24]
A., Antaki, F ., Zhou, Y ., Turner, A
Chia, M. A., Antaki, F ., Zhou, Y ., Turner, A. W., Lee, A. Y ., & Keane, P . A. (2024). Foundation models in ophthalmology. British Journal of Ophthalmology
work page 2024
-
[25]
He, K., Chen, X., Xie, S., Li, Y ., Dollár, P ., & Girshick, R. (2022). Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 16000-16009)
work page 2022
-
[26]
S., Gulati, A., Banerjee, O., Logé, C., Farhat, M., Saenz, A
Iyer, N. S., Gulati, A., Banerjee, O., Logé, C., Farhat, M., Saenz, A. D., & Rajpurkar, P . (2022). Self-supervised pretraining enables high -performance chest X -ray interpretation across clinical distributions. medRxiv, 2022-11. 15
work page 2022
-
[27]
Huang, Z., Bianchi, F ., Yuksekgonul, M., Montine, T . J., & Zou, J. (2023). A visual –language foundation model for pathology image analysis using medical twitter. Nature medicine, 29(9), 2307-2316
work page 2023
-
[28]
Lu, M. Y ., Chen, B., Williamson, D. F ., Chen, R. J., Liang, I., Ding, T., ... & Mahmood, F . (2024). A visual-language foundation model for computational pathology. Nature Medicine, 30(3), 863-874
work page 2024
-
[29]
Large-scale training of foundation models for wearable biosignals.arXiv preprint arXiv:2312.05409,
Abbaspourazad, S., Elachqar, O., Miller, A. C., Emrani, S., Nallasamy, U., & Shapiro, I. (2023). Large-scale training of foundation models for wearable biosignals. arXiv preprint arXiv:2312.05409
-
[30]
Pai, S., Bontempi, D., Hadzic, I., Prudente, V ., Sokač, M., Chaunzwa, T. L., ... & Aerts, H. J. (2024). Foundation model for cancer imaging biomarkers. Nature machine intelligence, 6(3), 354-367
work page 2024
-
[31]
Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., & Fei -Fei, L. (2009, June). Imagenet: A large - scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248-255). Ieee
work page 2009
-
[32]
Strudel, R., Garcia, R., Laptev, I., & Schmid, C. (2021). Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 7262-7272)
work page 2021
-
[33]
L., Shepherd, B., Milburn, K., Veluchamy, A., Meng, W., Carr, F .,
Hebert, H. L., Shepherd, B., Milburn, K., Veluchamy, A., Meng, W., Carr, F ., ... & Palmer, C. N. (2018). Cohort profile: genetics of diabetes audit and research in Tayside Scotland (GoDARTS). International journal of epidemiology, 47(2), 380-381j
work page 2018
-
[34]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[35]
Zhang, L., Wang, X., Yang, D., Sanford, T., Harmon, S., Turkbey, B., ... & Xu, Z. (2019). When unseen domain generalization is unnecessary? rethinking data augmentation. arXiv preprint arXiv:1906.03347
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[36]
Van der Maaten, L., & Hinton, G. (2008). Visualizing data using t -SNE. Journal of machine learning research, 9(11)
work page 2008
-
[37]
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large -scale image recognition. arXiv preprint arXiv:1409.1556
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[38]
Loshchilov, I., & Hutter, F . (2016). Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[39]
Liu, L., Zhang, Z., Li, S., Ma, K., & Zheng, Y . (2021). S -CUDA: self-cleansing unsupervised domain adaptation for medical image segmentation. Medical Image Analysis, 74, 102214
work page 2021
-
[40]
Lei, H., Liu, W., Xie, H., Zhao, B., Yue, G., & Lei, B. (2021). Unsupervised domain adaptation based image synthesis and feature alignment for joint optic disc and cup segmentation. IEEE Journal of Biomedical and Health Informatics, 26(1), 90-102
work page 2021
-
[41]
Liu, B., Pan, D., Shuai, Z., & Song, H. (2022). ECSD -Net: A joint optic disc and cup segmentation and glaucoma classification network based on unsupervised domain adaptation. Computer Methods and Programs in Biomedicine, 213, 106530
work page 2022
-
[42]
Chen, Z., Pan, Y ., & Xia, Y . (2023). Reconstruction -driven dynamic refinement based unsupervised domain adaptation for joint optic disc and cup segmentation. IEEE Journal of Biomedical and Health Informatics, 27(7), 3537-3548
work page 2023
-
[43]
Zhang, J., Lin, S., Cheng, T., Xu, Y ., Lu, L., He, J., ... & Ma, Y . (2024). RETFound -enhanced community-based fundus disease screening: real -world evidence and decision curve analysis. NPJ digital medicine, 7(1), 108
work page 2024
-
[44]
Power, A., Burda, Y ., Edwards, H., Babuschkin, I., & Misra, V . (2022). Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv preprint arXiv:2201.02177
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Zhang, P ., Li, Y ., Zhang, J., Jiang, W., Conze, P . H., Lamard, M., ... & Daho, M. E. H. (2024, May). Detection and Classification of Glaucoma in the Justraigs Challenge: Achievements in 16 Binary and Multilabel Classification. In 2024 IEEE International Symposium on Biomedical Imaging (ISBI) (pp. 1-4). IEEE
work page 2024
-
[46]
R., Shah, S., Gadari, A., Vupparaboina, S
Du, K., Nair, A. R., Shah, S., Gadari, A., Vupparaboina, S. C., Bollepalli, S. C., ... & Vupparaboina, K. K. (2024). Detection of Disease Features on Retinal OCT Scans Using RETFound. Bioengineering, 11(12), 1186
work page 2024
-
[47]
Villaplana-Velasco, A., Pigeyre, M., Engelmann, J., Rawlik, K., Canela-Xandri, O., Tochel, C., ... & Bernabeu, M. O. (2023). Fine-mapping of retinal vascular complexity loci identifies Notch regulation as a shared mechanism with myocardial infarction outco mes. Communications biology, 6(1), 523
work page 2023
-
[48]
K., Cortina-Borja, M., Silverstein, S
Wagner, S. K., Cortina-Borja, M., Silverstein, S. M., Zhou, Y ., Romero-Bascones, D., Struyven, R. R., ... & Keane, P . A. (2023). Association between retinal features from multimodal imaging and schizophrenia. JAMA psychiatry, 80(5), 478-487
work page 2023
-
[49]
Mordi, I. R., Trucco, E., Syed, M. G., MacGillivray, T., Nar, A., Huang, Y ., ... & Doney, A. S. (2022). Prediction of major adverse cardiovascular events from retinal, clinical, and genomic data in individuals with type 2 diabetes: a population cohort study. Diabetes Care, 45(3), 710-716
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.