Is VLA Reasoning Faithful? Probing Safety of Chain-of-Causation
Pith reviewed 2026-05-20 13:26 UTC · model grok-4.3
The pith
Vision-language-action driving models generate natural-language explanations that match scene reality less than half the time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
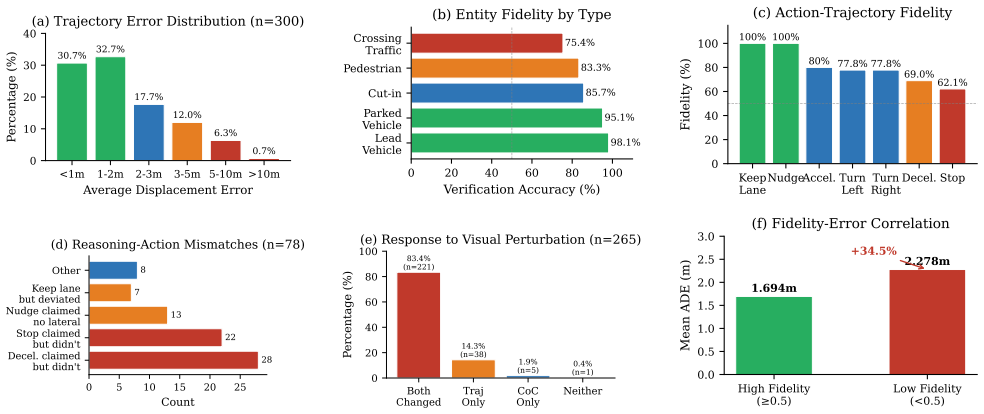
Output natural-language rationales with trajectories may be significantly unfaithful: overall reasoning fidelity is only 42.5 percent, Chain-of-Causation matches scene reality less than half the time, 94 pedestrians are missed in one-third of relevant scenes, trajectory outputs are 97.7 percent fragile under mild visual perturbations, and mean reasoning-action consistency is only 48.3 percent, with more than half of inferences showing low consistency including over a third of stop-claimed cases where the model continues instead.
What carries the argument
Chain-of-Causation reasoning, the natural-language trajectory explanations generated by VLA models in response to visual driving scenes.
If this is right
- Current VLA outputs cannot be treated as reliable explanations for safety audits or post-incident review.
- Small changes in camera input can produce entirely different rationales even when the scene content is essentially unchanged.
- A four-component safety architecture is needed to detect and mitigate unfaithful reasoning before deployment.
- Action decisions should be cross-checked against the model's own stated rationale in real time.
Where Pith is reading between the lines
- Similar faithfulness problems may appear in VLA systems used outside driving, such as robotic manipulation or navigation.
- New benchmarks that jointly score visual grounding, textual consistency, and action alignment would be required to track progress.
- Training objectives that explicitly penalize mismatches between rationale and scene or action could improve fidelity.
Load-bearing premise
The verification criteria for entity fidelity and action fidelity, together with the 100 PhysicalAI-AV scenarios, accurately and representatively capture when a VLA model's Chain-of-Causation reasoning is unfaithful to actual scene content.
What would settle it
Re-running the same 300 inferences with independent human verifiers who apply the identical entity and action fidelity rules and obtain an overall fidelity score above 70 percent would challenge the central claim.
Figures
read the original abstract
We present the first systematic study of faithfulness in Vision-Language-Action (VLA) driving models, analyzing 300 Alpamayo-R1-10B inferences across 100 diverse PhysicalAI-AV scenarios. Our main finding is that output natural-language rationales with trajectories may be significantly unfaithful: (i) overall reasoning fidelity is only 42.5%, with Chain-of-Causation matching scene reality less than half the time; (ii) 94 missed pedestrians in one-third of pedestrian-relevant scenes; (iii) 97.7% trajectory fragility under mild visual perturbations; and (iv) only 48.3% mean reasoning-action consistency, with 53.3% of inferences exhibiting low consistency, including 37.9% of stop-claimed cases where the model continues instead. We formalize faithfulness information-theoretically, define entity and action fidelity with verification criteria, and outline a four-component safety architecture aligned with these results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study of reasoning faithfulness in a Vision-Language-Action (VLA) model for autonomous driving. Using 300 inferences from the Alpamayo-R1-10B model on 100 PhysicalAI-AV scenarios, it finds that Chain-of-Causation rationales match scene reality only 42.5% of the time, with 94 missed pedestrians in relevant scenes, 97.7% trajectory fragility to mild perturbations, and 48.3% mean reasoning-action consistency. The authors provide an information-theoretic formalization of faithfulness, define entity and action fidelity verification criteria, and sketch a four-component safety architecture to mitigate the identified issues.
Significance. If the reported fidelity statistics are robust, this work identifies concrete safety risks in VLA driving models arising from unfaithful natural-language rationales and trajectories. The information-theoretic framing and the proposed safety architecture could guide future mitigation strategies. The scale of the evaluation (300 inferences) and the focus on specific failure modes such as missed pedestrians and action-reasoning inconsistency are strengths that could influence AV safety research.
major comments (2)
- [§3.2] §3.2 (Entity and Action Fidelity Criteria): The verification criteria for entity fidelity are not specified in sufficient detail regarding occlusion handling, spatial granularity, or causal attribution thresholds. This directly affects the reliability of the 94 missed pedestrians count and the overall 42.5% reasoning fidelity, as alternative reasonable criteria could change whether a given rationale is scored as faithful.
- [§4.1] §4.1 (Scenario Selection): The justification for the representativeness of the 100 PhysicalAI-AV scenarios is missing quantitative coverage metrics or sampling strategy details. This is load-bearing for the 97.7% trajectory fragility claim, because an under-sampling of rare safety-critical configurations could make the fragility statistic an artifact of the chosen set rather than a general property of the model.
minor comments (2)
- [Abstract] Abstract: The phrase 'formalize faithfulness information-theoretically' should include a forward reference to the section or equation number where the formalization appears.
- [Table 1] Table 1: The caption does not explain the exact definition of 'low consistency' used to arrive at the 53.3% figure; adding this would aid interpretation.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We have carefully considered each point and provide our responses below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Entity and Action Fidelity Criteria): The verification criteria for entity fidelity are not specified in sufficient detail regarding occlusion handling, spatial granularity, or causal attribution thresholds. This directly affects the reliability of the 94 missed pedestrians count and the overall 42.5% reasoning fidelity, as alternative reasonable criteria could change whether a given rationale is scored as faithful.
Authors: We thank the referee for highlighting the need for greater specificity in the entity fidelity verification criteria. Upon review, we agree that additional details on occlusion handling (e.g., how partially occluded entities are treated), spatial granularity (e.g., minimum overlap thresholds for entity detection), and causal attribution thresholds would strengthen the evaluation. In the revised manuscript, we will expand the description in §3.2 to include these explicit criteria and provide examples of how they were applied to the 300 inferences. This will make the 42.5% fidelity metric and the count of 94 missed pedestrians more reproducible and robust. revision: yes
-
Referee: [§4.1] §4.1 (Scenario Selection): The justification for the representativeness of the 100 PhysicalAI-AV scenarios is missing quantitative coverage metrics or sampling strategy details. This is load-bearing for the 97.7% trajectory fragility claim, because an under-sampling of rare safety-critical configurations could make the fragility statistic an artifact of the chosen set rather than a general property of the model.
Authors: The referee correctly notes that explicit quantitative coverage metrics and sampling strategy details for the 100 scenarios are not included in the current manuscript. The scenarios were selected from the PhysicalAI-AV benchmark to ensure diversity across different driving conditions, but we did not provide supporting statistics. In the revision, we will include a new subsection or appendix detailing the sampling strategy (e.g., stratified sampling across scenario categories) and quantitative metrics such as the distribution of pedestrian presence, weather conditions, and road types in the selected set. This will better support the claim that the 97.7% trajectory fragility is a general property rather than specific to the chosen scenarios. revision: yes
Circularity Check
Empirical measurement study with no derivation chain that reduces to fitted parameters or self-referential definitions
full rationale
The paper conducts an empirical analysis of 300 inferences across 100 scenarios, reporting measured statistics on reasoning fidelity, missed entities, trajectory fragility, and consistency. It defines verification criteria for entity and action fidelity and formalizes faithfulness information-theoretically, but these definitions serve as measurement instruments rather than inputs that are renamed or fitted to produce the reported outcomes. No equations, self-citations, or ansatzes are shown to force the central quantitative findings by construction. The study is self-contained against external benchmarks in the form of direct scenario evaluation, with no load-bearing reduction to prior author work or internal redefinitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 100 PhysicalAI-AV scenarios constitute a diverse and sufficient sample for generalizing faithfulness findings to VLA driving models.
invented entities (1)
-
Chain-of-Causation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize faithfulness information-theoretically, define entity and action fidelity with verification criteria... I(R;T|X)≈0
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Action fidelity... Stop: a(r)=stop ⇒ v_T(τ)<ε_v ...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai et al. Constitutional ai: Harmlessness from ai feedback.arXiv:2212.08073, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
EMMA: End-to-End Multimodal Model for Autonomous Driving
J. Hwang et al. Emma: End-to-end multimodal model for au- tonomous driving. arXiv preprint arXiv:2410.23262, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
ISO 26262:2018 road vehicles – functional safety
ISO. ISO 26262:2018 road vehicles – functional safety. In- ternational Organization for Standardization, 2018. 2
work page 2018
-
[4]
ISO 21448:2022 road vehicles – safety of the intended 4 functionality (sotif)
ISO. ISO 21448:2022 road vehicles – safety of the intended 4 functionality (sotif). International Organization for Stan- dardization, 2022. 2
work page 2022
-
[5]
A. Jacovi and Y . Goldberg. Towards faithfully interpretable NLP systems: A survey. InProceedings of the 58th An- nual Meeting of the Association for Computational Linguis- tics (ACL), 2020. 2
work page 2020
-
[6]
Measuring Faithfulness in Chain-of-Thought Reasoning
T. Lanham et al. Measuring faithfulness in chain-of-thought reasoning. arXiv preprint arXiv:2307.13702, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Alpamayo-r1: Bridging reasoning and action pre- diction for generalizable autonomous driving
NVIDIA. Alpamayo-r1: Bridging reasoning and action pre- diction for generalizable autonomous driving. Technical Re- port, 2025. 1, 2, 3
work page 2025
-
[8]
Physicalai-autonomous-vehicles dataset
NVIDIA. Physicalai-autonomous-vehicles dataset. Hugging Face, 2025. 3
work page 2025
-
[9]
Training language models to follow in- structions with human feedback
Long Ouyang et al. Training language models to follow in- structions with human feedback. InNeurIPS, 2022. 4
work page 2022
-
[10]
On a Formal Model of Safe and Scalable Self-driving Cars
S. Shalev-Shwartz, S. Shammah, and A. Shashua. On a formal model of safe and scalable self-driving cars. arXiv preprint arXiv:1708.06374, 2017. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
X. Tian et al. Drivevlm: The convergence of autonomous driving and large vision-language models. arXiv preprint arXiv:2402.12289, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
M. Turpin et al. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompt- ing. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 1, 2 5
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.