Gate AI: LLM Security Benchmark Evaluation Methodology and Results
Pith reviewed 2026-06-28 15:03 UTC · model grok-4.3
The pith
Evaluation harness for LLM detectors selects one global operating point and applies it uniformly across 16 benchmarks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
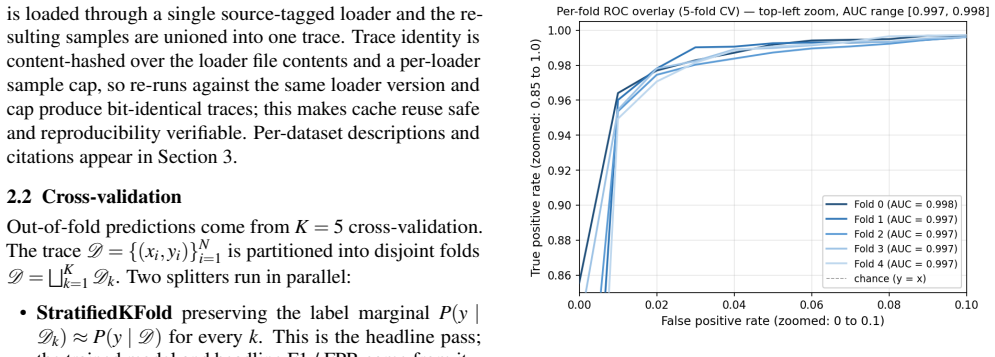
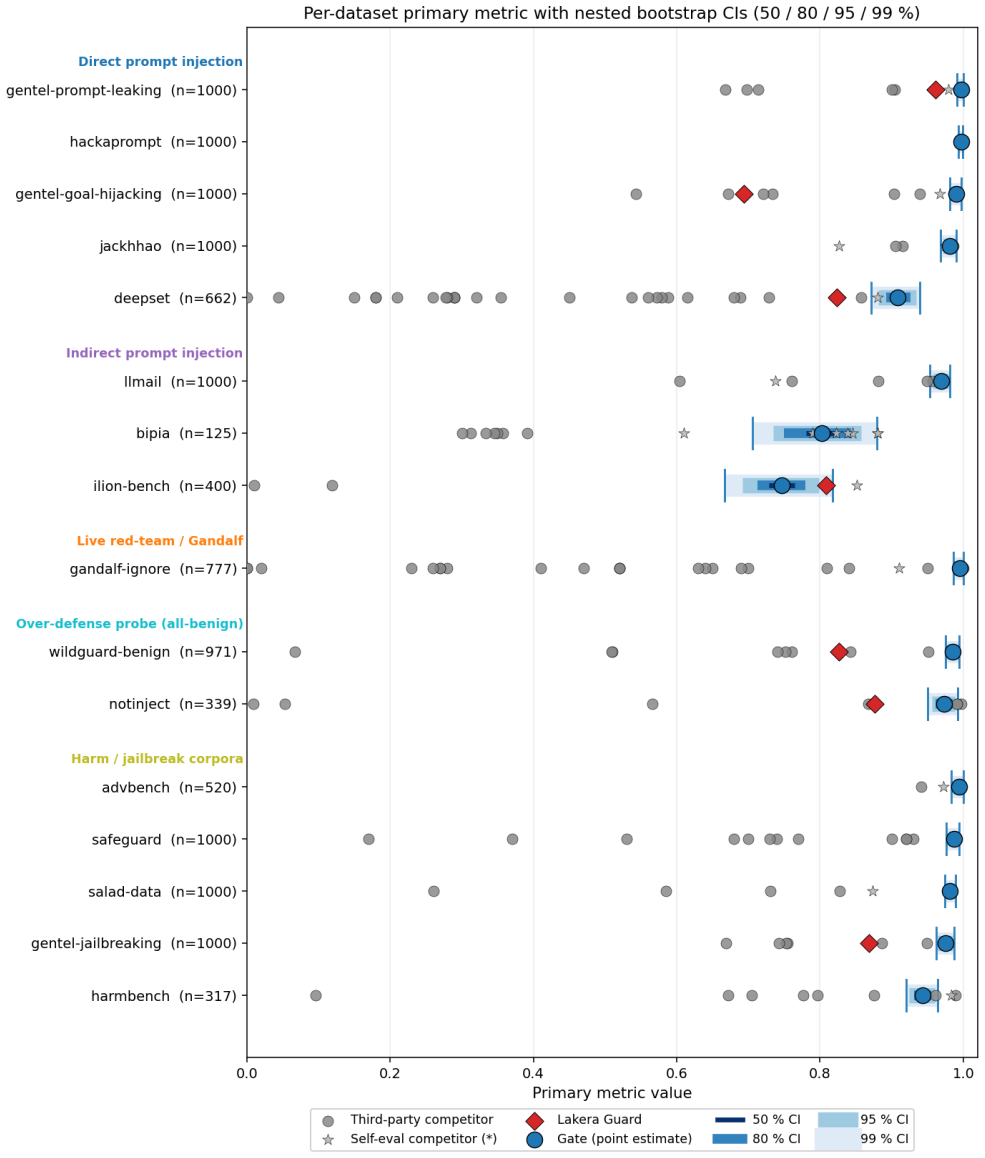
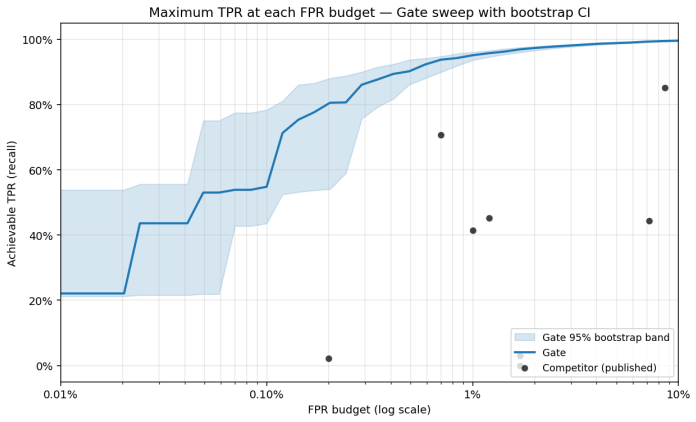
The harness scores any detector across the 16 benchmarks with 5-fold cross-validation, selects one global operating point on the held-out folds by maximizing F1 while constraining FPR to ≤1 percent, and applies that operating point uniformly so that per-dataset scores reflect a consistent threshold rather than per-benchmark optimization; a parallel group-fold pass over prompt-ID and MinHash clusters provides a leakage diagnostic.
What carries the argument
The 5-fold cross-validation procedure that selects a single global max-F1 operating point at FPR ≤1 percent on held-out folds and applies it uniformly, with a parallel StratifiedGroupKFold leakage diagnostic over composite near-duplicate keys.
If this is right
- Per-dataset results now reflect performance under one fixed operating point instead of benchmark-specific tuning.
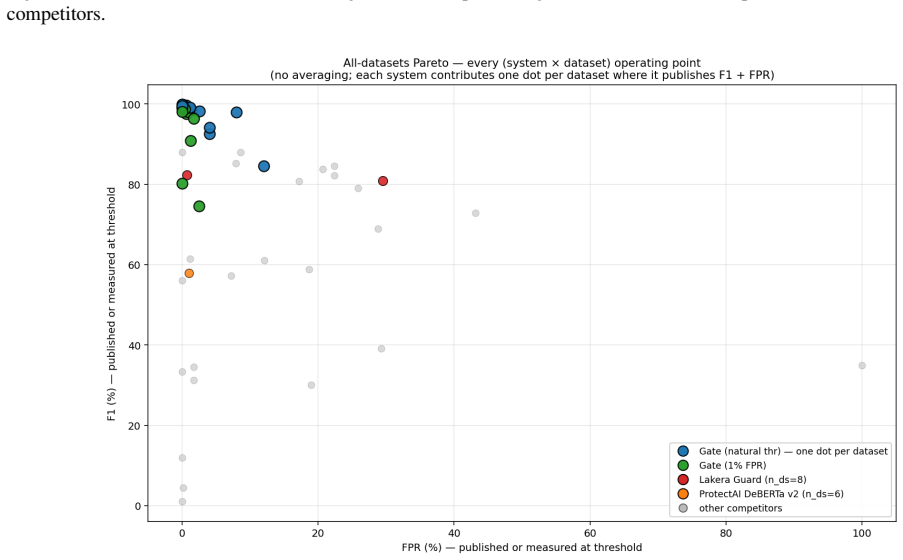
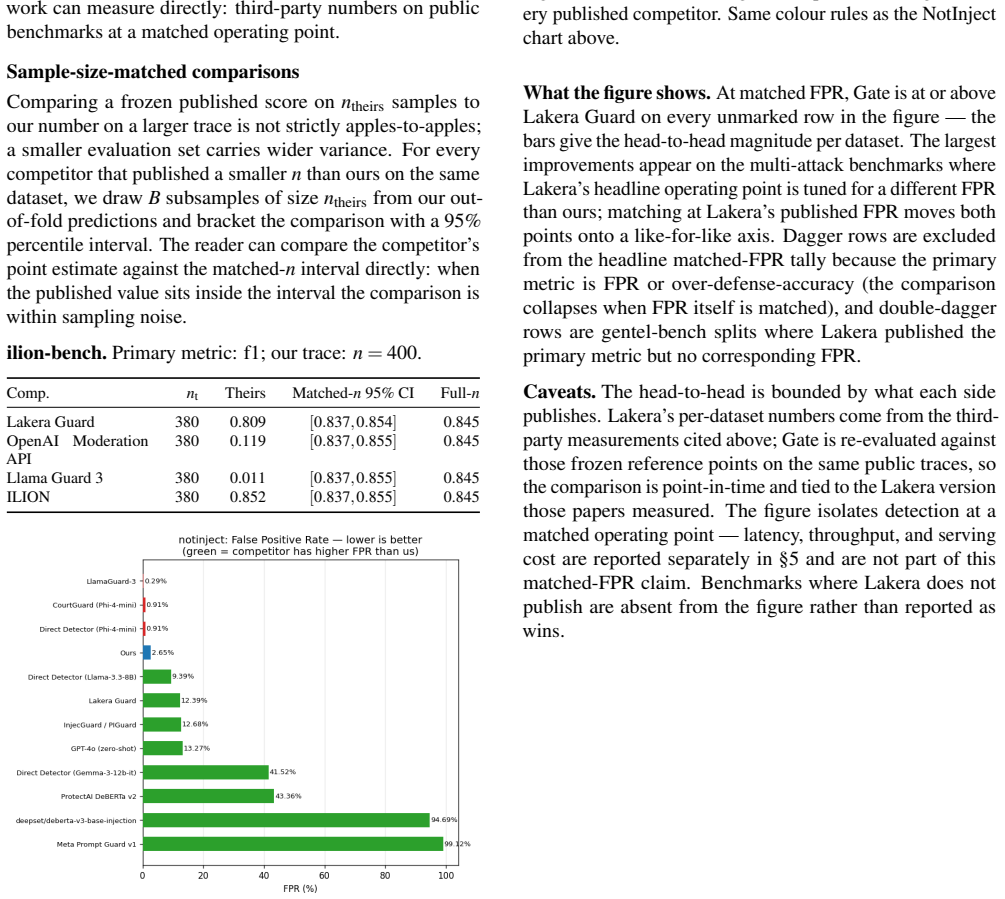
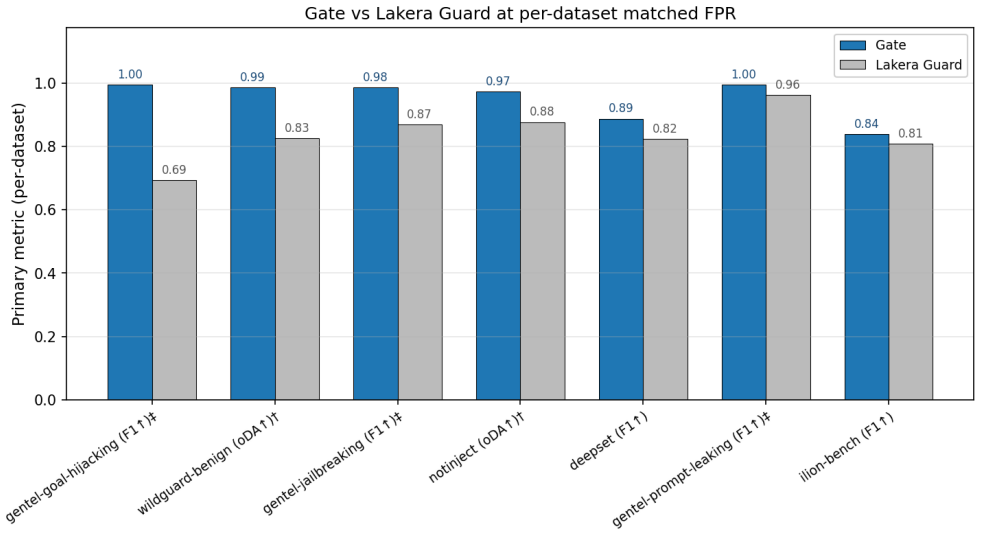
- Head-to-head comparisons with external detectors are performed after re-tuning the harness threshold to match each competitor's published false-positive rate.
- A battery of diagnostics (leave-one-dataset-out, random-label control, length-bias correlation, cross-source duplicate detection) quantifies generalization beyond the main cross-validation.
- The group-fold leakage diagnostic runs in parallel with the row-stratified pass to surface hidden prompt overlap.
Where Pith is reading between the lines
- Widespread use of the harness would make it harder for published detector papers to report inflated numbers obtained through hidden per-dataset tuning.
- The approach could be extended by adding private or adversarially generated benchmarks to test whether the global threshold still holds outside the current public set.
- If the near-duplicate clustering at Jaccard 0.8 misses semantically equivalent prompts that differ in wording, the leakage diagnostic may understate the risk of train-test contamination.
Load-bearing premise
The 16 public benchmarks together with the chosen near-duplicate clustering supply a representative and leakage-controlled distribution on which one global threshold remains meaningful.
What would settle it
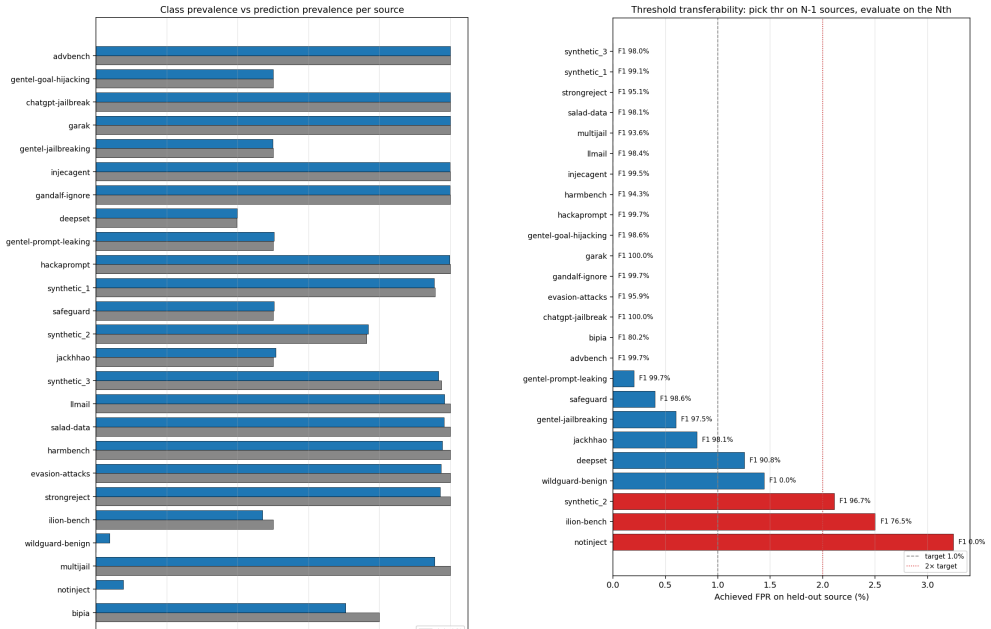
If the globally selected threshold produces markedly lower F1 on held-out data than the best per-dataset tuned thresholds, or if the generalization diagnostics (leave-one-dataset-out, paraphrase invariance, threshold transferability) consistently fail their quantitative thresholds, the claim that the harness yields more reliable comparisons would be falsified.
Figures



read the original abstract
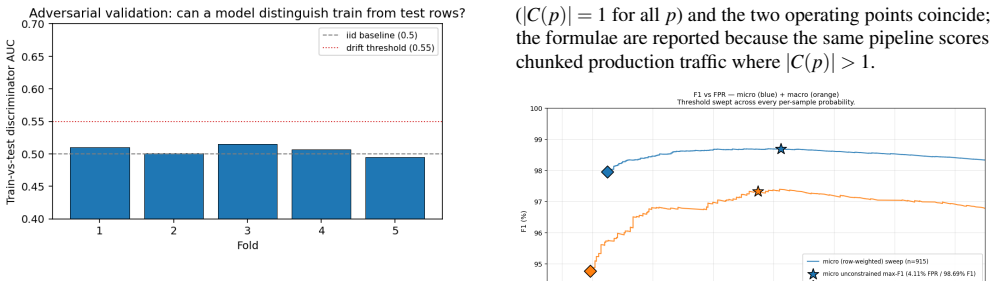
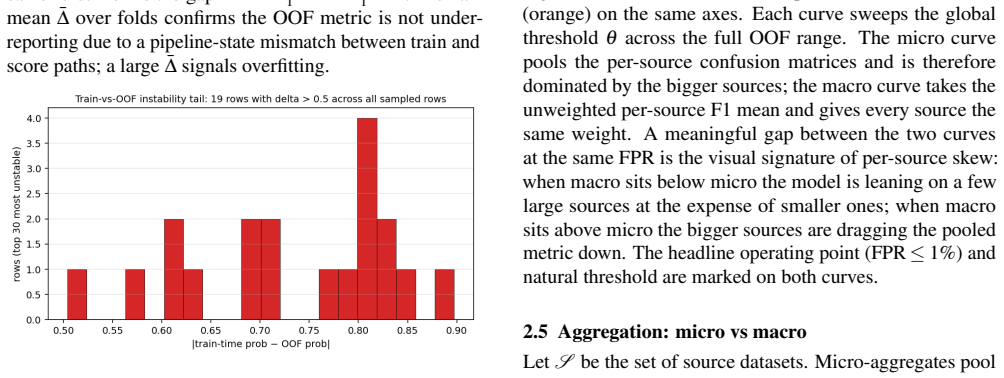
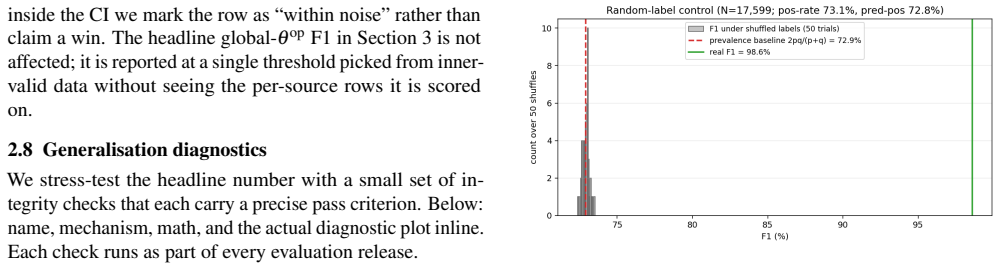
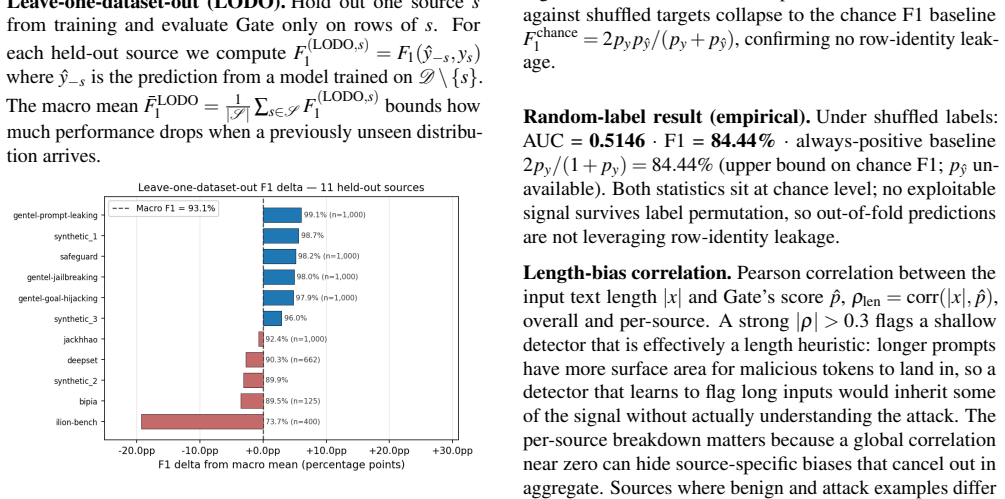
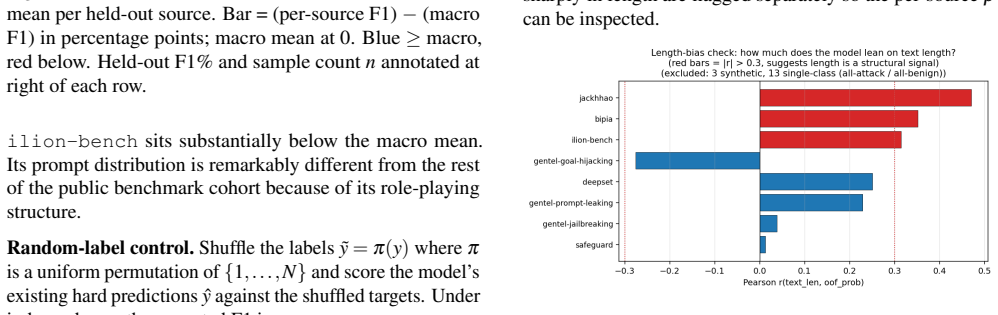
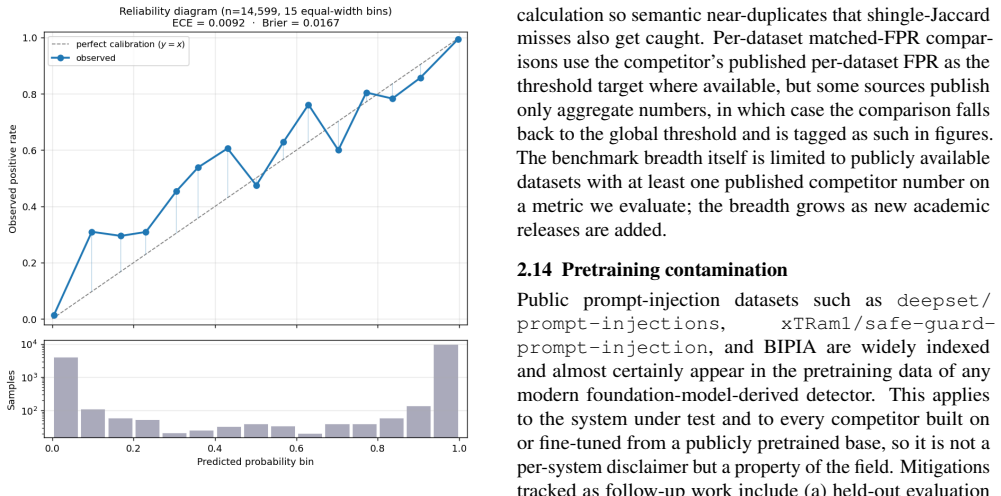
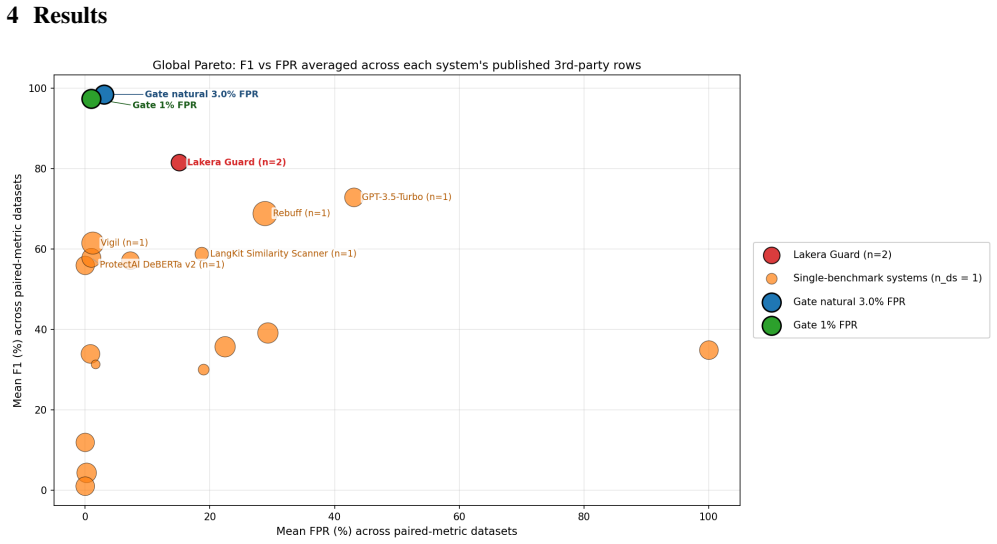
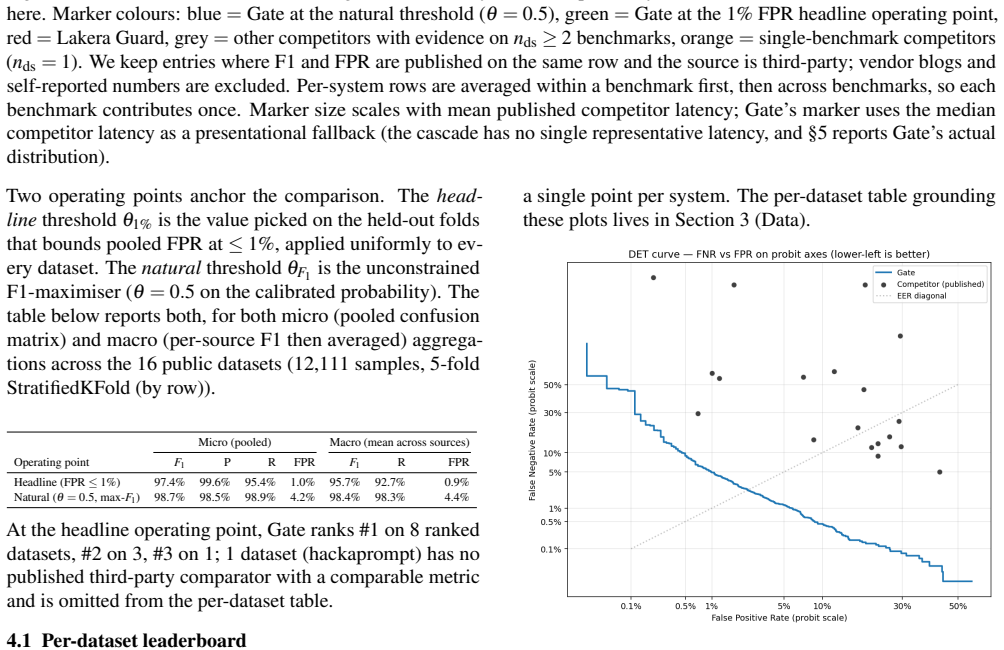
Published evaluations of prompt-injection and jailbreak detectors for Large Language Models often suffer from two systematic weaknesses: per-dataset threshold tuning and undisclosed operating points. We describe an evaluation harness that addresses both. The detector under evaluation is scored across 16 public benchmarks (12,111 samples) using 5-fold cross-validation. StratifiedKFold (by row) is the headline pass; a parallel StratifiedGroupKFold pass over a composite key (parent-prompt id plus MinHash + LSH near-duplicate clusters at Jaccard $\gtrsim 0.8$) runs alongside it as a leakage-premium diagnostic. A single global operating point is selected on the held-out folds (max F1 subject to FPR $\leq 1\%$) and applied uniformly to every dataset, so per-dataset results reflect one threshold rather than per-benchmark optimisation. Generalisation is examined through a battery of diagnostics (leave-one-dataset-out cross-validation, a random-label control, adversarial validation, permutation feature importance, length-bias correlation, classifier-head agreement, cross-source near-duplicate detection, threshold transferability, train-vs-OOF agreement, and a paraphrase-invariance probe), most with a quantitative pass threshold and the remainder with a stated failure mode. For every external comparison, the detector's threshold is re-tuned to the competitor's published false-positive rate so head-to-head values are evaluated at matched operating points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce an evaluation harness for prompt-injection and jailbreak detectors that mitigates per-dataset threshold tuning and undisclosed operating points. It scores detectors on 16 public benchmarks (12,111 samples) via 5-fold cross-validation, selects a single global operating point (max F1 subject to FPR ≤ 1%) on held-out folds, and applies it uniformly; StratifiedKFold by row is the headline protocol while StratifiedGroupKFold (parent-prompt + MinHash/LSH clusters at Jaccard ≳ 0.8) serves as a leakage diagnostic. A suite of generalization diagnostics (leave-one-dataset-out, random-label control, adversarial validation, etc.) is applied, most with quantitative pass thresholds, and external comparisons are performed at matched FPRs.
Significance. If the central claim holds, the work would provide a reproducible, standardized protocol for LLM security detector evaluation that reduces the common practice of per-benchmark optimization. The battery of diagnostics with stated quantitative thresholds and the explicit handling of operating-point matching are positive features that could improve comparability across papers.
major comments (1)
- [Evaluation Protocol (abstract and § on cross-validation)] The headline protocol uses StratifiedKFold by row for threshold selection and reporting, while the StratifiedGroupKFold (parent-prompt id plus MinHash/LSH near-duplicate clusters) is described only as a parallel diagnostic. Because near-duplicates can cross folds under the row-wise split, the selected global operating point may overfit to leaked examples; this directly undermines the claim that the harness produces a leakage-controlled uniform threshold applicable across the 16 benchmarks.
minor comments (1)
- [Abstract] Clarify whether the Jaccard ≳ 0.8 threshold for LSH clustering is fixed or tuned, and report the exact number of clusters formed.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying a key point about our evaluation protocol. We respond to the major comment below and outline the changes we will make.
read point-by-point responses
-
Referee: [Evaluation Protocol (abstract and § on cross-validation)] The headline protocol uses StratifiedKFold by row for threshold selection and reporting, while the StratifiedGroupKFold (parent-prompt id plus MinHash/LSH near-duplicate clusters) is described only as a parallel diagnostic. Because near-duplicates can cross folds under the row-wise split, the selected global operating point may overfit to leaked examples; this directly undermines the claim that the harness produces a leakage-controlled uniform threshold applicable across the 16 benchmarks.
Authors: We agree that the distinction between protocols requires clarification to support the leakage-control claim. The manuscript presents StratifiedKFold (by row) as the headline protocol because it follows conventional cross-validation practice and allows direct comparison with prior work, while the composite-key StratifiedGroupKFold serves as an explicit leakage diagnostic. However, the referee correctly notes that near-duplicates may still cross row-wise folds, potentially allowing the global threshold (max F1 at FPR ≤ 1%) to benefit from leakage. To strengthen the central claim, we will revise the abstract and the cross-validation section to designate the StratifiedGroupKFold results as the primary, leakage-controlled protocol for threshold selection and reporting. The row-wise results will be retained as a secondary comparison to quantify the leakage premium. This change directly addresses the risk of overfitting to leaked examples while preserving the uniform-threshold objective. revision: yes
Circularity Check
No significant circularity; methodology is self-contained
full rationale
The paper describes an evaluation harness using 5-fold cross-validation (StratifiedKFold headline, StratifiedGroupKFold diagnostic) to select a single global operating point (max F1 at FPR ≤1% on held-out folds) applied uniformly across 16 benchmarks. No equations, fitted parameters, or derivations are presented that reduce the claimed generalization or threshold selection to inputs by construction. No self-citations are load-bearing for uniqueness or ansatz, and the method is proposed independently without renaming known results or smuggling assumptions via citation. The central claim rests on the described procedure itself rather than reducing to its own outputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- FPR cap =
1%
- Jaccard threshold =
0.8
axioms (2)
- standard math StratifiedKFold yields unbiased performance estimates when applied to the composite benchmark collection
- domain assumption The 16 public benchmarks collectively represent the distribution of prompt-injection attacks
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
-
[4]
V . García. Which firewall best prevents prompt injection attacks? NeuralTrust blog. 2025.https://neuraltrust. ai/blog/prevent-prompt-injection-attacks-firewall-comparison
2025
-
[5]
deepset/prompt-injections (community-labelled prompt-injection dataset)
deepset. deepset/prompt-injections (community-labelled prompt-injection dataset). Hugging Face Datasets. 2023. https://huggingface.co/datasets/deepset/prompt-injections
2023
-
[6]
prompt-injection-jailbreak-sentinel-v2 (model card)
Rogue Security. prompt-injection-jailbreak-sentinel-v2 (model card). Hugging Face. 2025. https://huggingface. co/rogue-security/prompt-injection-jailbreak-sentinel-v2
2025
-
[7]
Schulhoff et al
S. Schulhoff et al. Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs Through a Global Prompt Hacking Competition. EMNLP 2023; project site. 2023.https://www.hackaprompt.com
2023
-
[8]
jackhhao/jailbreak-classification (binary jailbreak vs benign classification dataset)
jackhhao. jackhhao/jailbreak-classification (binary jailbreak vs benign classification dataset). Hugging Face Datasets. 2023.https://huggingface.co/datasets/jackhhao/jailbreak-classification
2023
-
[9]
S. Abdelnabi et al. LLMail-Inject: A Dataset from a Realistic Adaptive Prompt Injection Challenge. arXiv:2506.09956. 2025.https://arxiv.org/abs/2506.09956
- [10]
- [11]
-
[12]
L. E. Erdogan et al. safe-guard-prompt-injection (synthetic prompt-injection dataset, n=10,296). Hugging Face Datasets. 2024.https://huggingface.co/datasets/xTRam1/safe-guard-prompt-injection
2024
-
[13]
J. Kasundra et al. AprielGuard. arXiv:2512.20293. 2025.https://arxiv.org/abs/2512.20293
-
[14]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou et al. Universal and Transferable Adversarial Attacks on Aligned Language Models. arXiv:2307.15043. 2023. https://arxiv.org/abs/2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
A. Robey et al. SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks. arXiv:2310.03684. 2023. https://arxiv.org/abs/2310.03684
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Benchmarking and defending against indi- rect prompt injection attacks on large language models
J. Yi et al. Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models. arXiv:2312.14197. 2023.https://arxiv.org/abs/2312.14197
-
[17]
Lakera/gandalf_ignore_instructions (embedding-filtered Gandalf RCT subset)
Lakera AI. Lakera/gandalf_ignore_instructions (embedding-filtered Gandalf RCT subset). Hugging Face Datasets. 2023. https://huggingface.co/datasets/Lakera/gandalf_ignore_instructions
2023
- [18]
-
[19]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
M. Mazeika et al. HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal. arXiv:2402.04249. 2024.https://arxiv.org/abs/2402.04249
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
S. Han et al. WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs. arXiv:2406.18495. 2024.https://arxiv.org/abs/2406.18495
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
arXiv preprint arXiv:2402.05044 , year=
L. Li et al. SALAD-Bench: A Hierarchical and Comprehensive Safety Benchmark for Large Language Models. arXiv:2402.05044. 2024.https://arxiv.org/abs/2402.05044
-
[22]
G. C. Cawley, N. L. C. Talbot. On Over-fitting in Model Selection and Subsequent Selection Bias in Performance Evaluation. Journal of Machine Learning Research 11. 2010. https://jmlr.org/papers/v11/cawley10a. html 17
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.