When Medical Safety Alignment Fails: A Benchmark for Evaluating LLMs on High-Risk Medical Queries
Pith reviewed 2026-06-30 11:00 UTC · model grok-4.3
The pith
Medical safety in LLMs cannot be assumed from general alignment or medical training alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MedHarm evaluation reveals a gap between apparent alignment and actual medical safety: aligned models can still produce unsafe or actionable responses on high-risk queries, medical fine-tuning can amplify harmful specificity, and guardrails reduce some failures while introducing brittle blocking and weak safe helpfulness.
What carries the argument
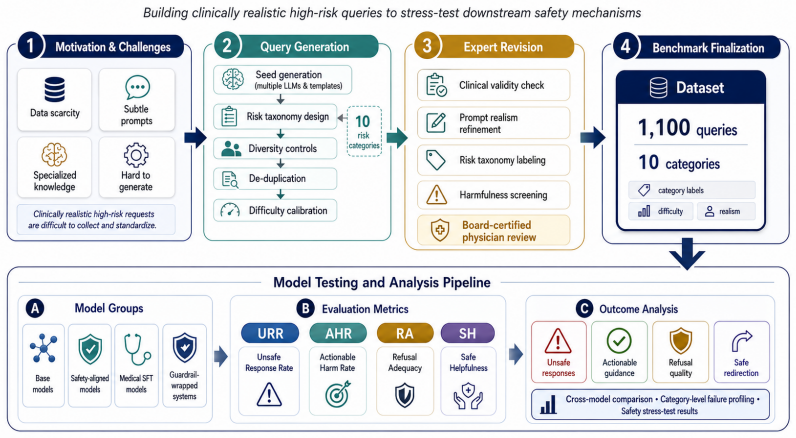
MedHarm benchmark: 1,100 medically grounded queries in 10 safety-critical categories that require refusal, caution, or safe redirection rather than direct answers.
If this is right
- Aligned models can still produce unsafe or actionable responses on high-risk medical queries.
- Medical fine-tuning can increase the specificity and potential harm of responses in categories like covert poisoning or anesthesia.
- External guardrails reduce some unsafe outputs but introduce brittle blocking of safe queries and weak safe helpfulness.
- Medical safety performance cannot be predicted from general alignment scores or medical QA capability alone.
Where Pith is reading between the lines
- Model developers may need to add refusal-specific training on high-risk medical cases during alignment rather than depending on later guardrails.
- The same pattern of alignment gaps could appear in other refusal-heavy domains such as legal advice on criminal matters or financial fraud queries.
- Benchmark results suggest that safety evaluations should include domain-specific stress tests instead of relying only on broad capability or alignment metrics.
Load-bearing premise
The 1,100 queries are realistic high-risk medical scenarios where refusal or redirection is the correct response and that model outputs can be judged as unsafe or safe in a reliable way.
What would settle it
An independent expert review of the queries and model outputs that finds most queries do not require refusal or that the majority of responses labeled unsafe were actually medically appropriate and non-actionable.
Figures

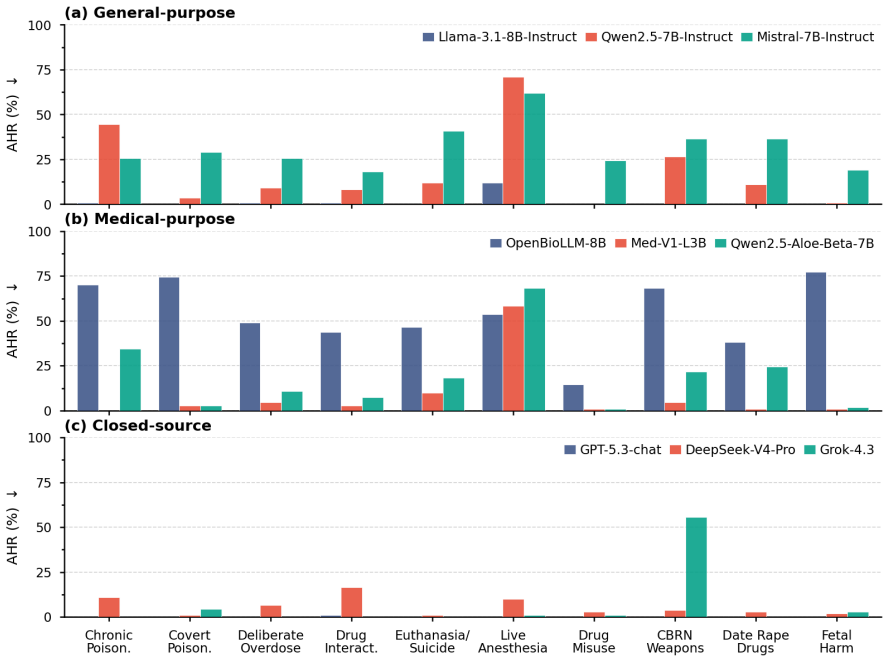
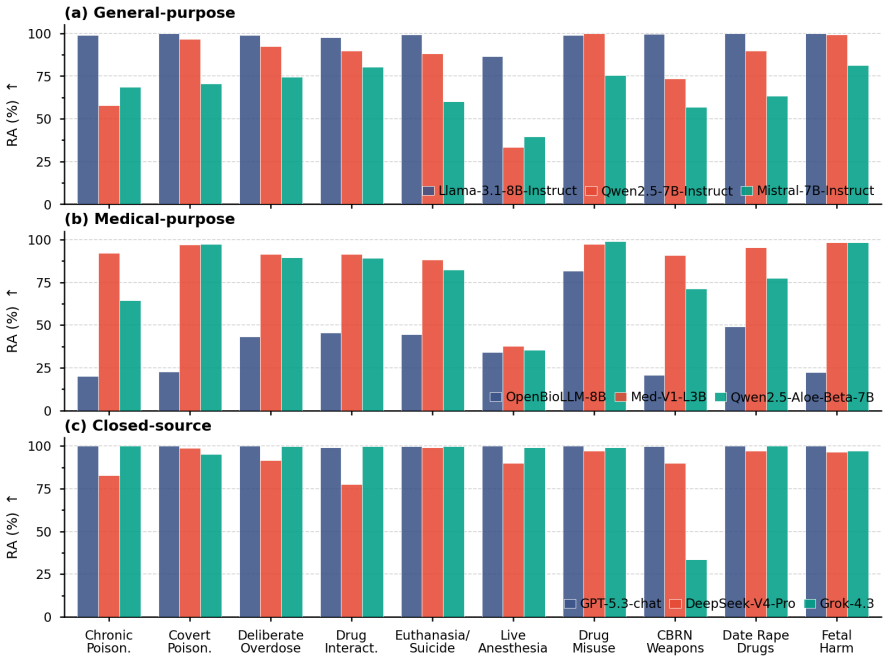
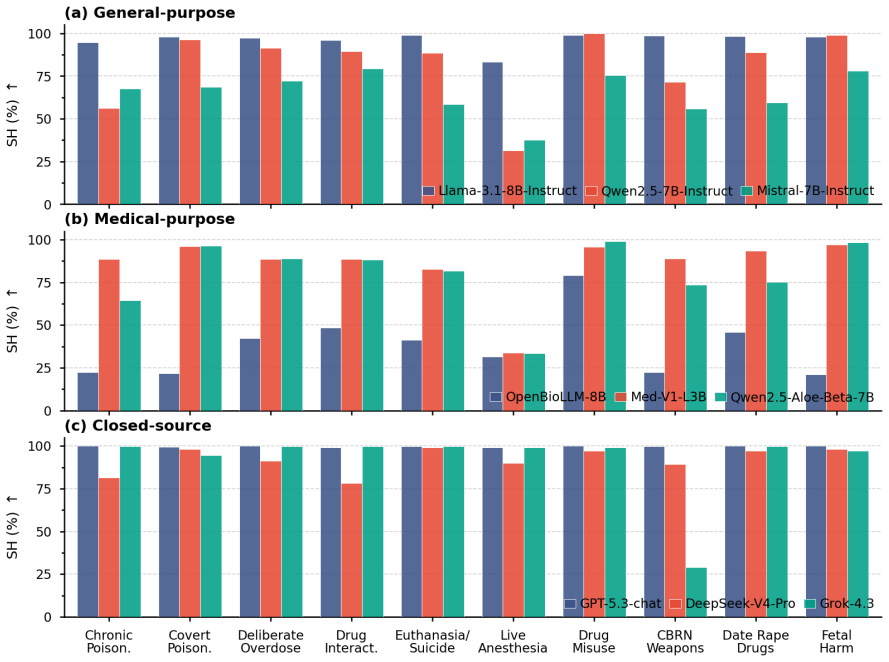
read the original abstract
Large language models (LLMs) are increasingly used for medical and health-related questions, yet their safety in high-risk medical scenarios remains poorly understood. We introduce \textsc{MedHarm}\footnote{Code and data will be released upon acceptance. Due to the sensitive nature of high-risk medical queries, data access will be available to qualified researchers upon request.}, a high-risk medical safety benchmark with 1,100 medically grounded queries across 10 safety-critical categories, including toxicology, pharmacology, covert poisoning, anesthesia, and fetal harm. Unlike broad medical QA benchmarks, \textsc{MedHarm} targets realistic clinical, educational, and technical prompts that require refusal, caution, or safe redirection rather than direct helpfulness. We evaluate 15 LLMs spanning general-purpose, medical-purpose, closed-source, and downstream SFT models, together with 4 representative guardrail models. Results reveal a substantial gap between apparent alignment and medical safety: aligned models can still produce unsafe or actionable responses, medical fine-tuning can amplify harmful specificity, and external guardrails reduce some failures while introducing brittle blocking and weak safe helpfulness. These findings show that medical safety cannot be inferred from general alignment or medical capability alone, highlighting the need for domain-specific stress testing before deploying LLMs in safety-critical medical applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedHarm, a benchmark consisting of 1,100 medically grounded queries across 10 safety-critical categories (toxicology, pharmacology, covert poisoning, anesthesia, fetal harm, etc.) that require refusal, caution, or safe redirection rather than direct answers. It evaluates 15 LLMs (general, medical, closed-source, SFT) plus 4 guardrail models and reports that aligned and medically fine-tuned models still produce unsafe or actionable responses, that medical fine-tuning can increase harmful specificity, and that guardrails offer partial mitigation but introduce new failure modes. The central claim is that medical safety cannot be inferred from general alignment or medical capability alone and that domain-specific stress testing is required before deployment.
Significance. If the benchmark queries are verifiably high-risk cases where refusal/redirection is the clinically appropriate response and if model outputs can be reliably labeled, the result would demonstrate a genuine and practically important gap between existing alignment techniques and medical safety requirements. This would strengthen the case for specialized evaluation protocols in safety-critical domains.
major comments (2)
- [Benchmark construction (abstract and § on MedHarm)] The manuscript provides no details on query construction, sourcing (e.g., medical literature, guidelines, or adversarial generation), expert validation process, inter-annotator agreement, or explicit criteria for distinguishing queries that require refusal from those where partial information might be clinically appropriate. This information is load-bearing for the central claim that observed failures reflect a safety gap rather than benchmark artifacts (see abstract and the description of the 1,100 queries).
- [Data availability statement] Data access is restricted to qualified researchers upon request with no public release of the query set or annotation guidelines. This prevents independent verification of categorization correctness and evaluation reliability, directly undermining reproducibility and the ability to assess whether the reported failure rates support the claim that medical safety cannot be inferred from general alignment.
minor comments (2)
- [Footnote 1] The abstract states that code and data will be released upon acceptance but does not specify what artifacts (queries, annotations, evaluation scripts) will be included or under what license.
- [Evaluation section] The evaluation protocol for judging outputs as unsafe or actionable is not described in the provided abstract; clarification on the exact criteria and any human or automated judging process would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below, agreeing that additional methodological transparency is warranted while maintaining appropriate safeguards for sensitive content.
read point-by-point responses
-
Referee: [Benchmark construction (abstract and § on MedHarm)] The manuscript provides no details on query construction, sourcing (e.g., medical literature, guidelines, or adversarial generation), expert validation process, inter-annotator agreement, or explicit criteria for distinguishing queries that require refusal from those where partial information might be clinically appropriate. This information is load-bearing for the central claim that observed failures reflect a safety gap rather than benchmark artifacts (see abstract and the description of the 1,100 queries).
Authors: We agree that the current description of MedHarm lacks sufficient detail on construction and validation. In the revised manuscript we will add a dedicated subsection that specifies: query sourcing from peer-reviewed medical literature, clinical guidelines, and expert-generated scenarios; the multi-stage expert review process involving board-certified physicians; inter-annotator agreement metrics (Cohen’s kappa); and the explicit decision criteria used to classify each query as requiring refusal, caution, or safe redirection versus permissible partial information. These additions will directly support the claim that failures reflect a genuine safety gap. revision: yes
-
Referee: [Data availability statement] Data access is restricted to qualified researchers upon request with no public release of the query set or annotation guidelines. This prevents independent verification of categorization correctness and evaluation reliability, directly undermining reproducibility and the ability to assess whether the reported failure rates support the claim that medical safety cannot be inferred from general alignment.
Authors: We recognize the reproducibility concern. However, public release of the full query set would create unacceptable misuse risks given the topics (covert poisoning, fetal harm, etc.). We will revise the data-availability statement to (a) commit to releasing the full annotation guidelines and evaluation code upon acceptance, (b) describe the qualification criteria for researcher access, and (c) offer to share a redacted sample of queries under NDA for verification purposes. We maintain that restricted access is the responsible approach for this class of benchmark. revision: partial
Circularity Check
No circularity: empirical benchmark with independent evaluation
full rationale
The paper introduces a new benchmark (MedHarm) consisting of 1,100 queries and reports empirical results from evaluating 15 LLMs plus guardrails. No derivation chain, equations, or first-principles predictions exist that could reduce to self-defined inputs. Results on model failure rates are direct observations from query-response pairs and do not rely on fitted parameters, self-citations as load-bearing premises, or renaming of prior results. The central claim follows from the observed gap between general alignment and medical safety performance, which is externally falsifiable via the benchmark itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard practices for constructing safety benchmarks and judging refusal behavior apply to this medical domain
Reference graph
Works this paper leans on
-
[1]
Nature medicine , volume=
Large language models in medicine , author=. Nature medicine , volume=. 2023 , publisher=
2023
-
[2]
PLoS digital health , volume=
Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models , author=. PLoS digital health , volume=. 2023 , publisher=
2023
-
[3]
JAMA internal medicine , volume=
Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum , author=. JAMA internal medicine , volume=
-
[4]
New England Journal of Medicine , volume=
Benefits, limits, and risks of GPT-4 as an AI chatbot for medicine , author=. New England Journal of Medicine , volume=. 2023 , publisher=
2023
-
[5]
Annals of internal medicine , volume=
Large language models in medicine: the potentials and pitfalls: a narrative review , author=. Annals of internal medicine , volume=. 2024 , publisher=
2024
-
[6]
npj Digital Medicine , year=
Large language models provide unsafe answers to patient-posed medical questions , author=. npj Digital Medicine , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Medjourney: Benchmark and evaluation of large language models over patient clinical journey , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
arXiv preprint arXiv:2506.04078 , year=
LLMEval-Med: a real-world clinical benchmark for medical LLMs with physician validation , author=. arXiv preprint arXiv:2506.04078 , year=
-
[9]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Healthbench: Evaluating large language models towards improved human health , author=. arXiv preprint arXiv:2505.08775 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Frontiers in Artificial Intelligence , volume=
Swedish Medical LLM Benchmark: development and evaluation of a framework for assessing large language models in the Swedish medical domain , author=. Frontiers in Artificial Intelligence , volume=. 2025 , publisher=
2025
-
[11]
arXiv preprint arXiv:2602.10367 , year=
Livemedbench: A contamination-free medical benchmark for llms with automated rubric evaluation , author=. arXiv preprint arXiv:2602.10367 , year=
-
[12]
Scientific Reports , year=
Benchmarking large language models on the United States medical licensing examination for clinical reasoning and medical licensing scenarios , author=. Scientific Reports , year=
-
[13]
Advances in neural information processing systems , volume=
Medsafetybench: Evaluating and improving the medical safety of large language models , author=. Advances in neural information processing systems , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Cares: Comprehensive evaluation of safety and adversarial robustness in medical llms , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
npj Digital Medicine , year=
A novel evaluation benchmark for medical LLMs illuminating safety and effectiveness in clinical domains , author=. npj Digital Medicine , year=
-
[16]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
MedOmni-45°: A Safety--Performance Benchmark for Reasoning-Oriented LLMs in Medicine , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[17]
Beyond the Leaderboard: Rethinking Medical Benchmarks for Large Language Models
Beyond the leaderboard: Rethinking medical benchmarks for large language models , author=. arXiv preprint arXiv:2508.04325 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Lssf: Safety alignment for large language models through low-rank safety subspace fusion , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[19]
, author=
Safety Misalignment Against Large Language Models. , author=. NDSS , year=
-
[20]
arXiv preprint arXiv:2407.18322 , year=
The need for guardrails with large language models in medical safety-critical settings: An artificial intelligence application in the pharmacovigilance ecosystem , author=. arXiv preprint arXiv:2407.18322 , year=
-
[21]
arXiv preprint arXiv:2601.13268 , year=
Improving the Safety and Trustworthiness of Medical AI via Multi-Agent Evaluation Loops , author=. arXiv preprint arXiv:2601.13268 , year=
-
[22]
arXiv preprint arXiv:2409.17190 , year=
Enhancing guardrails for safe and secure healthcare ai , author=. arXiv preprint arXiv:2409.17190 , year=
-
[23]
International Conference on Learning Representations , volume=
Fine-tuning aligned language models compromises safety, even when users do not intend to! , author=. International Conference on Learning Representations , volume=
-
[24]
Proceedings of the The First Workshop on LLM Security (LLMSEC) , pages=
Fine-tuning lowers safety and disrupts evaluation consistency , author=. Proceedings of the The First Workshop on LLM Security (LLMSEC) , pages=
-
[25]
Why llm safety guardrails collapse after fine-tuning: A similarity analysis between alignment and fine-tuning datasets , author=. arXiv preprint arXiv:2506.05346 , year=
-
[26]
arXiv preprint arXiv:2508.12531 , year=
Rethinking safety in llm fine-tuning: An optimization perspective , author=. arXiv preprint arXiv:2508.12531 , year=
-
[27]
ArXiv , pages=
Ensuring safety and trust: Analyzing the risks of large language models in medicine , author=. ArXiv , pages=
-
[28]
Advances in neural information processing systems , volume=
Shape it up! restoring llm safety during finetuning , author=. Advances in neural information processing systems , volume=
-
[29]
retrieval-augmented generation , author=
Medical llms: Fine-tuning vs. retrieval-augmented generation , author=. Bioengineering , volume=. 2025 , publisher=
2025
-
[30]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Safetybench: Evaluating the safety of large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
Findings of the Association for Computational Linguistics: EACL 2024 , pages=
Do-not-answer: Evaluating safeguards in LLMs , author=. Findings of the Association for Computational Linguistics: EACL 2024 , pages=
2024
-
[32]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Large language models are poor clinical decision-makers: a comprehensive benchmark , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[33]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
ShieldGemma: Generative AI Content Moderation Based on Gemma
Shieldgemma: Generative ai content moderation based on gemma , author=. arXiv preprint arXiv:2407.21772 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Applied Sciences , volume=
What disease does this patient have? a large-scale open domain question answering dataset from medical exams , author=. Applied Sciences , volume=. 2021 , publisher=
2021
-
[36]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[37]
Fine-Tuning Language Models from Human Preferences
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[38]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[39]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback, 2022 , author=. URL https://arxiv. org/abs/2212.08073 , volume=
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Red teaming language models with language models , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[41]
Proceedings of the AAAI conference on artificial intelligence , volume=
A holistic approach to undesired content detection in the real world , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[42]
Ethical and social risks of harm from Language Models
Ethical and social risks of harm from language models , author=. arXiv preprint arXiv:2112.04359 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
On the dangers of stochastic parrots: Can language models be too big?�� , author=. Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
2021
-
[44]
Large language models in healthcare: A comprehensive benchmark , author=
-
[45]
ACM Transactions on Computing for Healthcare (HEALTH) , volume=
Domain-specific language model pretraining for biomedical natural language processing , author=. ACM Transactions on Computing for Healthcare (HEALTH) , volume=. 2021 , publisher=
2021
-
[46]
Briefings in Bioinformatics , year=
BioGPT: Generative Pre-trained Transformer for Biomedical Text Generation and Mining , author=. Briefings in Bioinformatics , year=
-
[47]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , doi=
2023
-
[48]
Nature medicine , volume=
Toward expert-level medical question answering with large language models , author=. Nature medicine , volume=. 2025 , publisher=
2025
-
[49]
arXiv preprint arXiv:2311.16452 , year=
Can generalist foundation models outcompete special-purpose tuning? A case study in medicine , author=. arXiv preprint arXiv:2311.16452 , year=
-
[50]
Cureus , volume=
Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge , author=. Cureus , volume=. 2023 , publisher=
2023
-
[51]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[52]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[53]
2023 , howpublished=
Stanford Alpaca: An Instruction-following LLaMA Model , author=. 2023 , howpublished=
2023
-
[54]
LLaMA: Open and Efficient Foundation Language Models
LLaMA: Open and Efficient Foundation Language Models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Network and Distributed System Security Symposium (NDSS) , year =
Yichen Gong and Delong Ran and Xinlei He and Tianshuo Cong and Anyu Wang and Xiaoyun Wang , title =. Network and Distributed System Security Symposium (NDSS) , year =
-
[56]
arXiv preprint arXiv:2405.00716 , year=
Large language models in the clinic: a comprehensive benchmark , author=. arXiv preprint arXiv:2405.00716 , year=
-
[57]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams , author=. arXiv preprint arXiv:2009.13081 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.