HKVLM: Faithful Reasoning Grounding by Binding Language Queries to a Frozen Detector
Pith reviewed 2026-06-30 09:58 UTC · model grok-4.3
The pith
HKVLM trains only a lightweight hook to bind language queries to proposals from a frozen detector, fixing binding failures that cause VLMs to mislabel regions they correctly attend to.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
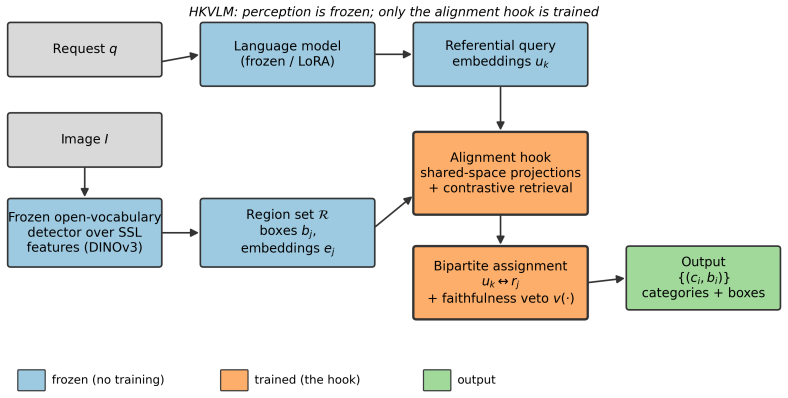
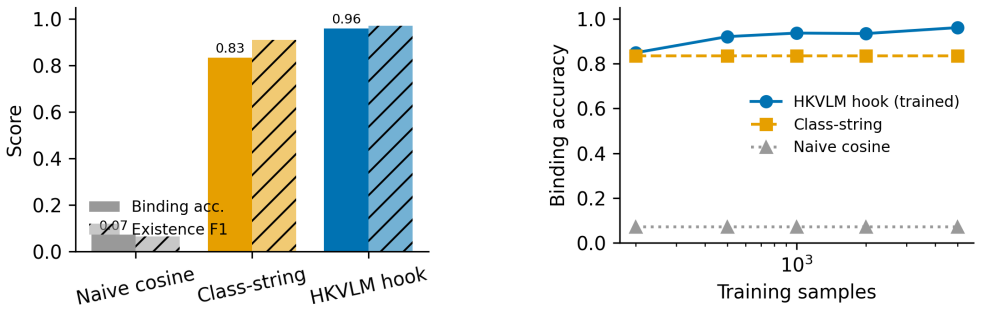
HKVLM removes localization from the language path: a frozen language-aligned detector emits class-agnostic region proposals; a frozen language model encodes reasoning instructions as referential query embeddings; a lightweight alignment hook binds queries to regions by contrastive retrieval and bipartite assignment in a shared embedding space; and a perception-grounded faithfulness veto forbids naming an object that no region supports. Only the hook is trained. With frozen Grounding DINO and Qwen2.5-VL this yields 50-90 times higher grounding accuracy than untrained cross-space matching on RefCOCO variants, raises POPE accuracy from 0.50 to 0.66-0.76, and reduces hallucination from ~0.99 to
What carries the argument
The alignment hook, which binds referential query embeddings from the frozen language model to class-agnostic region proposals from the frozen detector by contrastive retrieval and bipartite assignment in a shared embedding space.
If this is right
- Grounding accuracy on RefCOCO, RefCOCO+, and RefCOCOg rises 50-90 times over untrained cross-space matching when only the hook is trained.
- The faithfulness veto raises POPE accuracy from near-chance 0.50 to 0.66-0.76 and lowers hallucination rates from ~0.99 to 0.23-0.43.
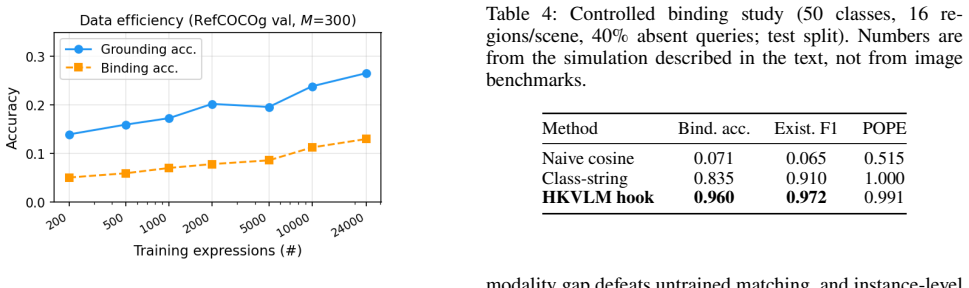
- Increasing detector proposals from 50 to 300 improves grounding accuracy 19-24 percent with no additional training, isolating error to perception.
- The approach works in small-data cold-start settings where full VLM tuning struggles because only a few hundred expressions are needed.
Where Pith is reading between the lines
- The same hook could be reused across different frozen detector-VLM pairs without retraining either base model.
- If perceptual error dominates once binding is solved, future gains would come mainly from stronger class-agnostic detectors rather than larger hooks.
- The say-versus-see split offers a diagnostic that could be applied to other grounding or referring-expression systems to locate where errors originate.
Load-bearing premise
The frozen detector produces class-agnostic region proposals that are sufficiently complete and language-aligned for the contrastive hook to bind queries reliably.
What would settle it
If training the hook on 200 expressions produces no large lift over the untrained cross-space matching baseline, or if raising the number of proposals from 300 to 1000 yields no further grounding gains, the claim that binding is the separable fix would be falsified.
Figures
read the original abstract
Many visual requests -- ``the object to open this bottle'', ``the person not wearing a helmet'' -- require reasoning, not just category matching. Pure open-vocabulary detectors need an explicit phrase; vision-language models (VLMs) can reason yet ``see but mis-speak'', attending to the right region but returning the wrong box or label. We argue this is a \emph{binding} failure: in coordinate-as-text VLMs localization passes through the autoregressive head, coupling it to language generation; in two-stage pipelines the model's intent is squeezed through a single class string. We present HKVLM, which removes localization from the language path. A frozen, language-aligned detector emits class-agnostic region proposals; a frozen language model encodes reasoning instructions as referential query embeddings; a lightweight \emph{alignment hook} binds queries to regions by contrastive retrieval and bipartite assignment in a shared embedding space. A perception-grounded faithfulness veto forbids naming an object that no region supports. Only the hook is trained, targeting small-data cold-start settings where monolithic VLM tuning struggles. We formalize a \emph{say-vs-see} decomposition separating localization error (SeeErr) from binding error (SayErr), and evaluate on RefCOCO/RefCOCO+/RefCOCOg and POPE. With frozen Grounding DINO and Qwen2.5-VL, training only the hook lifts grounding accuracy by $50$--$90\times$ over untrained cross-space matching; the faithfulness veto raises POPE accuracy from near-chance ($0.50$) to $0.66$--$0.76$ and reduces hallucination from ${\sim}0.99$ to $0.23$--$0.43$, with gains from $200$ expressions. Increasing proposals from $M{=}50$ to $M{=}300$ improves grounding by $19$--$24\%$ without retraining, confirming that residual error is perceptual (SeeErr) rather than binding (SayErr).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents HKVLM for faithful reasoning grounding: a frozen Grounding DINO emits class-agnostic region proposals, a frozen Qwen2.5-VL encodes referential queries, and only a lightweight contrastive alignment hook is trained to bind queries to regions via bipartite matching in embedding space; a perception-grounded faithfulness veto prevents unsupported naming. It formalizes a say-vs-see error decomposition and reports 50–90× grounding gains on RefCOCO/+/g over untrained matching, POPE accuracy rising from ~0.50 to 0.66–0.76 with hallucination dropping from ~0.99 to 0.23–0.43 using 200 expressions, plus 19–24% further grounding improvement when raising proposal count M from 50 to 300 without retraining (attributing residuals to SeeErr).
Significance. If the results and decomposition hold, the work shows that small-data hook training on frozen components can deliver large gains in binding accuracy and hallucination reduction for reasoning queries, providing an efficient cold-start alternative to monolithic VLM tuning while offering a diagnostic split between binding and perceptual error.
major comments (1)
- [Abstract (M ablation)] Abstract (M=50 to M=300 ablation paragraph): the claim that the 19–24% gain without retraining 'confirm[s] that residual error is perceptual (SeeErr) rather than binding (SayErr)' requires that the added proposals actually contain the target regions referenced by the queries. No proposal-recall figure (fraction of GT boxes covered at IoU>0.5 for each M) is reported, so the ablation cannot cleanly isolate binding success from coverage failure.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the M ablation. We address the concern point-by-point below.
read point-by-point responses
-
Referee: [Abstract (M ablation)] Abstract (M=50 to M=300 ablation paragraph): the claim that the 19–24% gain without retraining 'confirm[s] that residual error is perceptual (SeeErr) rather than binding (SayErr)' requires that the added proposals actually contain the target regions referenced by the queries. No proposal-recall figure (fraction of GT boxes covered at IoU>0.5 for each M) is reported, so the ablation cannot cleanly isolate binding success from coverage failure.
Authors: We agree that the current manuscript does not report proposal-recall (fraction of GT boxes covered at IoU>0.5), so the ablation cannot rigorously isolate coverage gains from binding gains. The interpretation in the abstract assumes that larger M primarily improves perceptual coverage given the class-agnostic frozen detector, but this assumption is unquantified. In revision we will add the requested proposal-recall numbers for M=50 and M=300; if they show substantial coverage improvement we will retain the SeeErr attribution, otherwise we will qualify or revise the claim. revision: yes
Circularity Check
No significant circularity; empirical results from hook training are independent of inputs
full rationale
The paper presents the HKVLM method as training only a lightweight alignment hook on held-out expressions while keeping Grounding DINO and Qwen2.5-VL frozen, then reports measured accuracy lifts (50-90x grounding, POPE from 0.50 to 0.66-0.76) and hallucination reductions on RefCOCO/POPE benchmarks. The say-vs-see decomposition and M=50-to-300 ablation are used to attribute residual error to SeeErr, but these are interpretive conclusions from empirical observations rather than any equation or self-citation that reduces the claimed gains to fitted parameters or prior results by construction. No load-bearing step matches the enumerated circularity patterns; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frozen Grounding DINO produces class-agnostic region proposals sufficient for binding arbitrary referential queries
- domain assumption The language model produces referential query embeddings that are directly comparable to detector region embeddings in a shared space
Reference graph
Works this paper leans on
-
[1]
ChatRex: Taming Multimodal LLM for Joint Perception and Understanding , author=. arXiv preprint arXiv:2411.18363 , year=
-
[2]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
DetGPT: Detect What You Need via Reasoning , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
LISA: Reasoning Segmentation via Large Language Model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[4]
International Conference on Learning Representations (ICLR) , year=
Kosmos-2: Grounding Multimodal Large Language Models to the World , author=. International Conference on Learning Representations (ICLR) , year=
-
[5]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic , author=. arXiv preprint arXiv:2306.15195 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
International Conference on Learning Representations (ICLR) , year=
Ferret: Refer and Ground Anything Anywhere at Any Granularity , author=. International Conference on Learning Representations (ICLR) , year=
-
[7]
European Conference on Computer Vision (ECCV) , year=
Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models , author=. European Conference on Computer Vision (ECCV) , year=
-
[8]
European Conference on Computer Vision (ECCV) , year=
Griffon: Spelling out All Object Locations at Any Granularity with Large Language Models , author=. European Conference on Computer Vision (ECCV) , year=
-
[9]
European Conference on Computer Vision (ECCV) , year=
LLaVA-Grounding: Grounded Visual Chat with Large Multimodal Models , author=. European Conference on Computer Vision (ECCV) , year=
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
GLaMM: Pixel Grounding Large Multimodal Model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[11]
European Conference on Computer Vision (ECCV) , year=
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection , author=. European Conference on Computer Vision (ECCV) , year=
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Grounded Language-Image Pre-training , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
YOLO-World: Real-Time Open-Vocabulary Object Detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[14]
European Conference on Computer Vision (ECCV) , year=
Simple Open-Vocabulary Object Detection with Vision Transformers , author=. European Conference on Computer Vision (ECCV) , year=
-
[15]
European Conference on Computer Vision (ECCV) , year=
End-to-End Object Detection with Transformers , author=. European Conference on Computer Vision (ECCV) , year=
-
[16]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Segment Anything , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[17]
Transactions on Machine Learning Research (TMLR) , year=
DINOv2: Learning Robust Visual Features without Supervision , author=. Transactions on Machine Learning Research (TMLR) , year=
-
[18]
DINOv3 , author=. arXiv preprint arXiv:2508.10104 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
International Conference on Machine Learning (ICML) , year=
Learning Transferable Visual Models from Natural Language Supervision , author=. International Conference on Machine Learning (ICML) , year=
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Improved Baselines with Visual Instruction Tuning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[21]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Qwen3-VL Technical Report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Evaluating Object Hallucination in Large Vision-Language Models , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
-
[26]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Object Hallucination in Image Captioning , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
-
[27]
Findings of the Association for Computational Linguistics: EMNLP , year=
Does Object Grounding Really Reduce Hallucination of Large Vision-Language Models? , author=. Findings of the Association for Computational Linguistics: EMNLP , year=
-
[28]
European Conference on Computer Vision (ECCV) , year=
Modeling Context in Referring Expressions , author=. European Conference on Computer Vision (ECCV) , year=
-
[29]
European Conference on Computer Vision (ECCV) , year=
Microsoft COCO: Common Objects in Context , author=. European Conference on Computer Vision (ECCV) , year=
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
LVIS: A Dataset for Large Vocabulary Instance Segmentation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
F-LMM: Grounding Frozen Large Multimodal Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Detect Anything via Next Point Prediction , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[33]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
RexSeek: Referring Any Person or Object via Natural Language , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[34]
arXiv preprint arXiv:2410.16163 , year=
Griffon-G: Bridging Vision-Language and Vision-Centric Tasks via Large Multimodal Models , author=. arXiv preprint arXiv:2410.16163 , year=
-
[35]
arXiv preprint arXiv:2508.19294 , year=
Object Detection with Multimodal Large Vision-Language Models: An In-depth Review , author=. arXiv preprint arXiv:2508.19294 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.