RADIANT-PET: Reasoning-Augmented PET/CT Lesion Segmentation with Large Language Models and Reinforcement Learning
Pith reviewed 2026-06-30 10:02 UTC · model grok-4.3
The pith
Coupling permissive voxel segmentation with LLM reasoning on textual uptake descriptions reduces false positives in PET/CT lesion detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
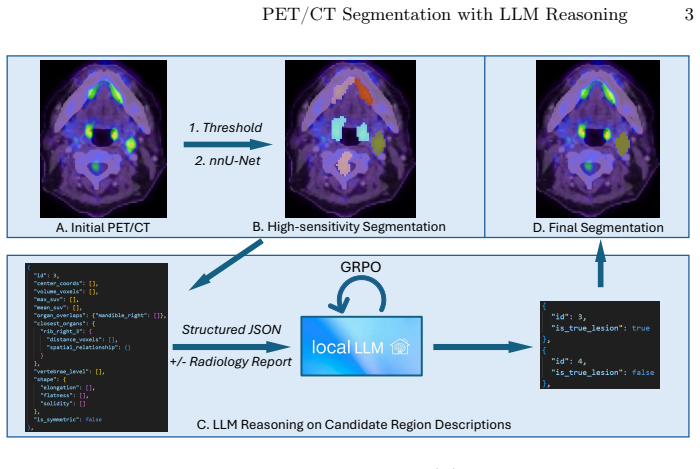
RADIANT-PET generates candidate uptake regions with a deliberately permissive voxel-level segmentation stage, converts each candidate into a structured textual description covering uptake intensity, morphology, and anatomical context, then uses an LLM to classify the candidate as a true lesion versus a physiologic or artifactual false positive, optionally incorporating the radiology report, and further optimizes the LLM with Group Relative Policy Optimization to reward correct lesion classification and site assignment; the resulting system outperforms image-only baselines on AutoPET and an OSU cohort, with largest gains when reports are supplied.
What carries the argument
The lesion-level LLM adjudication step that receives structured textual descriptions of candidate regions and outputs classifications as true lesions or false positives.
If this is right
- The largest accuracy gains appear when the radiology report is supplied as additional context to the LLM.
- Physiologic false positives that mimic malignant uptake are suppressed relative to image-only methods.
- Voxel-level predictions become more consistent with the clinical interpretation expressed in reports.
- Reinforcement learning improves both lesion classification accuracy and anatomically correct site assignment.
Where Pith is reading between the lines
- The same text-description-plus-LLM pattern could be tested on other imaging tasks where reports supply high-level context, such as CT or MRI lesion detection.
- If the method scales, it might lower the volume of cases needing manual radiologist review in high-throughput oncology workflows.
- Evaluating the approach on datasets with greater variation in scanner types or patient demographics would test whether the textual summaries capture all clinically relevant cues.
Load-bearing premise
Structured textual descriptions of uptake intensity, morphology, and anatomical context contain enough information for the LLM to correctly separate true lesions from physiologic or artifactual false positives.
What would settle it
A held-out test set where adding the LLM adjudication and reinforcement learning produces no measurable reduction in false positive rate or improvement in Dice score compared with the permissive segmentation model alone.
Figures

read the original abstract
Accurate lesion segmentation in PET/CT is critical for oncology, yet remains challenging because physiologic tracer uptake and artifacts can mimic malignant signal. We present RADIANT-PET, a reasoning-augmented framework that couples a high-sensitivity voxel-level segmentation model with lesion-level large language model (LLM) adjudication. Candidate uptake regions are generated with a deliberately permissive segmentation stage, then converted into structured textual descriptions that summarize uptake intensity, morphology, and regional and global anatomical context. An LLM classifies each candidate as true lesion vs. false positive, optionally leveraging the radiology report as additional clinical context. To strengthen lesion-level reasoning, we further optimize a local LLM via reinforcement learning using Group Relative Policy Optimization, rewarding correct lesion classification and anatomically concordant site assignment. Across AutoPET and an OSU test cohort, RADIANT-PET consistently outperforms strong image-only baselines, with the largest improvements observed when radiology reports are provided. Overall, these results demonstrate that LLM-based lesion-level reasoning adds a novel reasoning layer beyond conventional segmentation, suppressing physiologic false positives and aligning voxel-level predictions with clinical interpretation. The project repository is available at: https://github.com/jwang-580/RADIANT-PET.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RADIANT-PET, a hybrid framework for PET/CT lesion segmentation that first applies a deliberately permissive voxel-level segmenter to generate candidate regions, converts these into structured textual descriptions of uptake intensity, morphology, and anatomical context (optionally augmented by radiology reports), and then uses an LLM (fine-tuned via Group Relative Policy Optimization reinforcement learning) to classify candidates as true lesions versus physiologic or artifactual false positives. The central claim is that this lesion-level reasoning layer consistently outperforms strong image-only baselines on the AutoPET dataset and an OSU test cohort, with largest gains when reports are provided, by suppressing false positives and better aligning predictions with clinical interpretation.
Significance. If the empirical claims hold, the work would offer a meaningful advance by adding an explicit reasoning stage that addresses a persistent limitation of pure image-based methods in distinguishing malignant from physiologic uptake. The public release of the project repository (https://github.com/jwang-580/RADIANT-PET) is a clear strength supporting reproducibility. The combination of permissive segmentation, structured text conversion, optional report context, and GRPO-based LLM optimization is a coherent technical contribution. However, the absence of any quantitative results, baseline details, or error analysis in the provided manuscript prevents a full assessment of whether the claimed gains are real or merely artifacts of the first-stage segmenter.
major comments (2)
- [Abstract] Abstract: No quantitative performance numbers, baseline comparisons, statistical tests, or error analysis are supplied. Without these data it is impossible to evaluate whether the LLM adjudication step actually delivers the claimed suppression of physiologic false positives or merely inherits permissive behavior from the initial segmenter.
- [Abstract] Abstract: The central claim that 'structured textual descriptions ... contain sufficient information for an LLM to reliably classify candidates' is load-bearing yet unsupported; the manuscript provides no evidence that fine visual cues (heterogeneous uptake patterns, boundary texture, subtle gradients) survive the text conversion process or that the LLM adjudication is not simply benefiting from report leakage.
Simulated Author's Rebuttal
Thank you for the constructive review. We agree that the current abstract and manuscript lack the quantitative results, baseline details, and supporting analyses needed to substantiate the claims. We will revise accordingly to include these elements.
read point-by-point responses
-
Referee: [Abstract] Abstract: No quantitative performance numbers, baseline comparisons, statistical tests, or error analysis are supplied. Without these data it is impossible to evaluate whether the LLM adjudication step actually delivers the claimed suppression of physiologic false positives or merely inherits permissive behavior from the initial segmenter.
Authors: We agree that the abstract provides only a qualitative summary and that the manuscript as provided lacks the requested quantitative details. In the revision we will expand the abstract to report specific metrics (e.g., Dice, sensitivity, specificity) on AutoPET and the OSU cohort, include baseline comparisons, and note statistical significance. A new results section with error analysis will also be added to the main text. revision: yes
-
Referee: [Abstract] Abstract: The central claim that 'structured textual descriptions ... contain sufficient information for an LLM to reliably classify candidates' is load-bearing yet unsupported; the manuscript provides no evidence that fine visual cues (heterogeneous uptake patterns, boundary texture, subtle gradients) survive the text conversion process or that the LLM adjudication is not simply benefiting from report leakage.
Authors: We acknowledge that the current manuscript supplies no direct evidence or ablation addressing information preservation in the text conversion step or the possibility of report leakage. We will add a dedicated analysis section that includes (1) ablations isolating the contribution of the structured text descriptions versus report context and (2) a discussion of limitations regarding fine visual cues that may not be captured in text. These additions will be reflected in the revised abstract as well. revision: yes
Circularity Check
No significant circularity; empirical framework with external components
full rationale
The paper describes an applied framework that chains a permissive segmentation stage, text conversion of candidates, LLM classification, and optional RL fine-tuning. No equations, derivations, or fitted parameters are presented that reduce any output to an input by construction. Claims rest on experimental comparisons against image-only baselines on held-out cohorts (AutoPET, OSU), not on self-referential logic or self-citation chains. The method therefore remains self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can accurately classify lesion candidates when given structured textual descriptions of uptake intensity, morphology, regional context, and optional radiology reports.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Agarwal, S., et al.: gpt-oss-120b & gpt-oss-20b model card (2025). https://doi.org/10.48550/arXiv.2508.10925
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10925 2025
-
[2]
Journal of Clinical Oncology32(27), 3048–3058 (2014)
Barrington, S.F., et al.: Role of imaging in the staging and response assessment of lymphoma: consensus of the International Conference on Malignant Lymphomas Imaging Working Group. Journal of Clinical Oncology32(27), 3048–3058 (2014). https://doi.org/10.1200/JCO.2013.53.5229
-
[3]
Daniel Han, M.H., team, U.: Unsloth (2023), http://github.com/unslothai/unsloth
2023
-
[4]
doi: 10.1038/s41586-025-09422-z
Guo, D., Yang, D., Zhang, H., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. Nature645, 633–638 (2025). https://doi.org/10.1038/s41586-025-09422-z
-
[5]
European Journal of Nuclear Medicine and Molecular Imaging45(7), 1142–1154 (2018)
Ilyas, H., Mikhaeel, N.G., Dunn, J.T., Rahman, F., Møller, H., Smith, D., Barring- ton, S.F.: Defining the optimal method for measuring baseline metabolic tumour volume in diffuse large b cell lymphoma. European Journal of Nuclear Medicine and Molecular Imaging45(7), 1142–1154 (2018). https://doi.org/10.1007/s00259- 018-3953-z
-
[6]
Kalisch, H., Hörst, F., Herrmann, K., Kleesiek, J., Seibold, C.: AutoPET III chal- lenge: Incorporating anatomical knowledge into nnunet for lesion segmentation in PET/CT (2024). https://doi.org/10.48550/arXiv.2409.12155
-
[7]
PET Clinics14(3), 317–329 (Jul 2019)
Kostakoglu, L., Chauvie, S.: Pet-derived quantitative metrics for response and prognosis in lymphoma. PET Clinics14(3), 317–329 (Jul 2019). https://doi.org/10.1016/j.cpet.2019.03.002
-
[8]
Discovering Causal Signals in Images
Lopez-Paz, D., Bottou, L., Schölkopf, B., Vapnik, V.: Discovering causal signals in images (2016). https://doi.org/10.48550/arXiv.1605.08179
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1605.08179 2016
-
[9]
Rokuss, M., Kovacs, B., Kirchhoff, Y., Xiao, S., Ulrich, C., Maier- Hein, K.H., Isensee, F.: From FDG to PSMA: A hitchhiker’s guide to multitracer, multicenter lesion segmentation in PET/CT imaging (2024). https://doi.org/10.48550/arXiv.2409.09478
-
[10]
Salehi, S.S.M., Erdogmus, D., Gholipour, A.: Tversky loss function for image segmentation using 3d fully convolutional deep networks (2017), https://arxiv.org/abs/1706.05721
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [11]
-
[12]
Ra- diology: Artificial Intelligence5(5) (2023)
Wasserthal,J.,Meyer,M.,Hahn,F.,etal.:Totalsegmentator:Robustsegmentation of 104 anatomical structures in ct images. Radiology: Artificial Intelligence (2023). https://doi.org/10.1148/ryai.230024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.