When Agents Commit Too Soon: Diagnosing Premature Commitment in LLM Agents
Pith reviewed 2026-06-26 08:30 UTC · model grok-4.3
The pith
Cross-run hidden-state convergence at step 4 predicts whether LLM agents will maintain consistent trajectories on reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
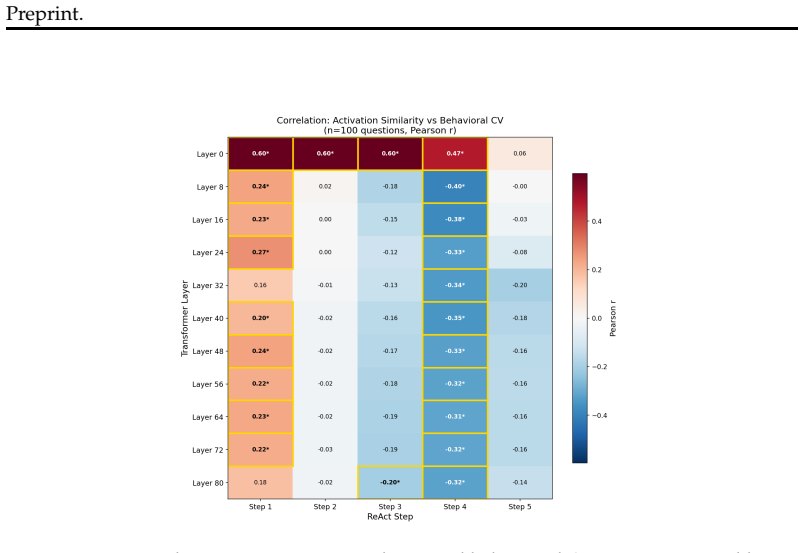
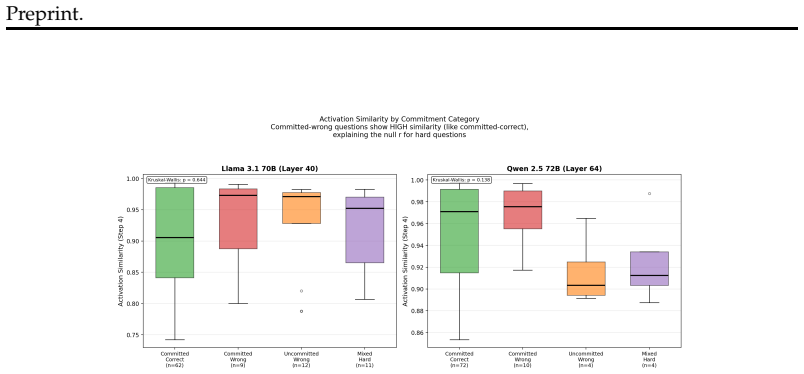
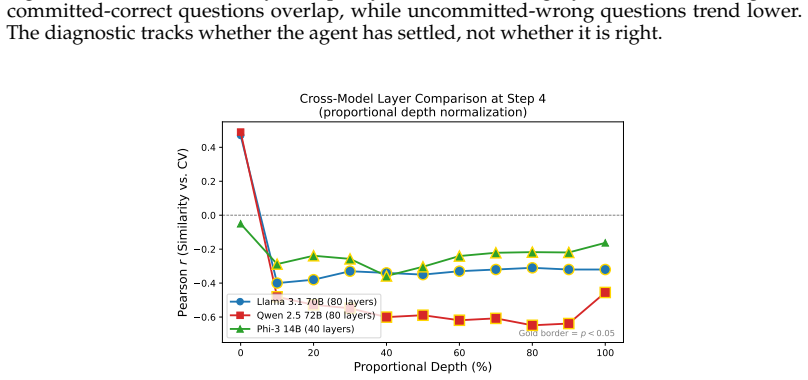
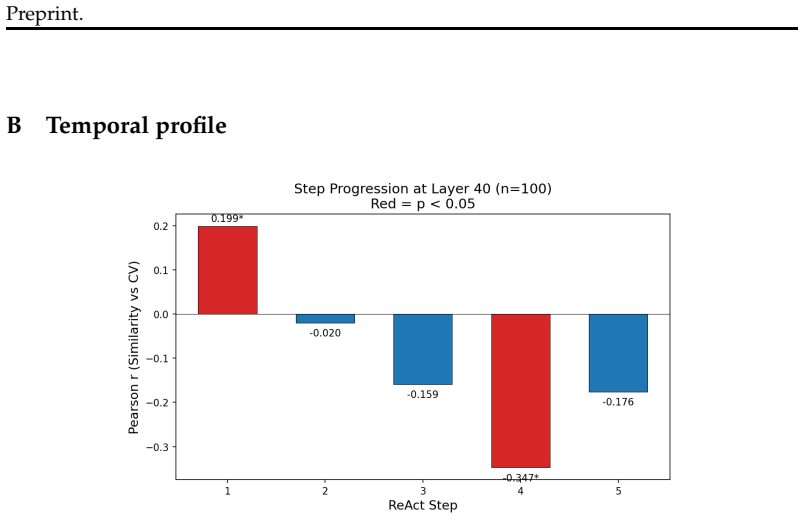
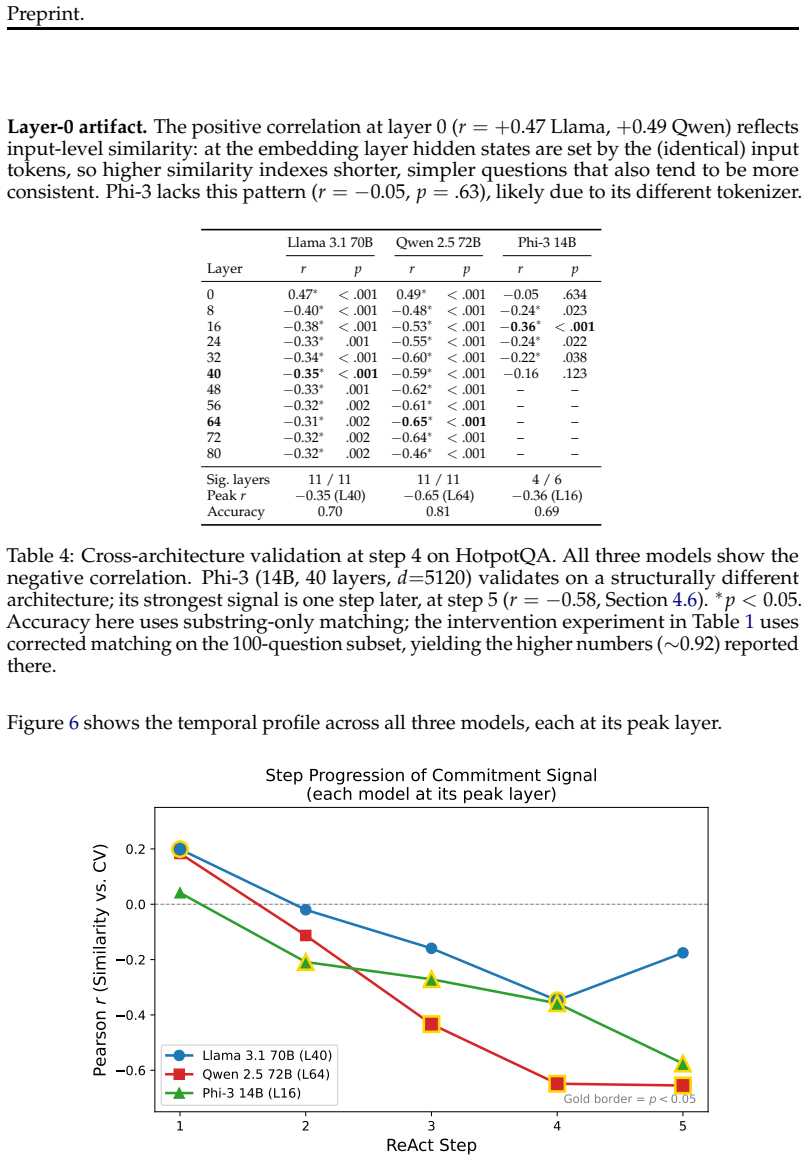
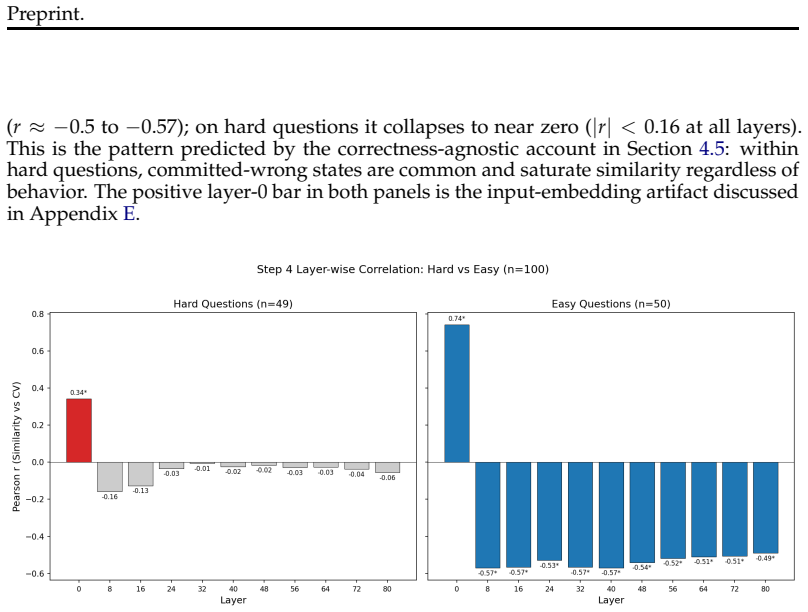
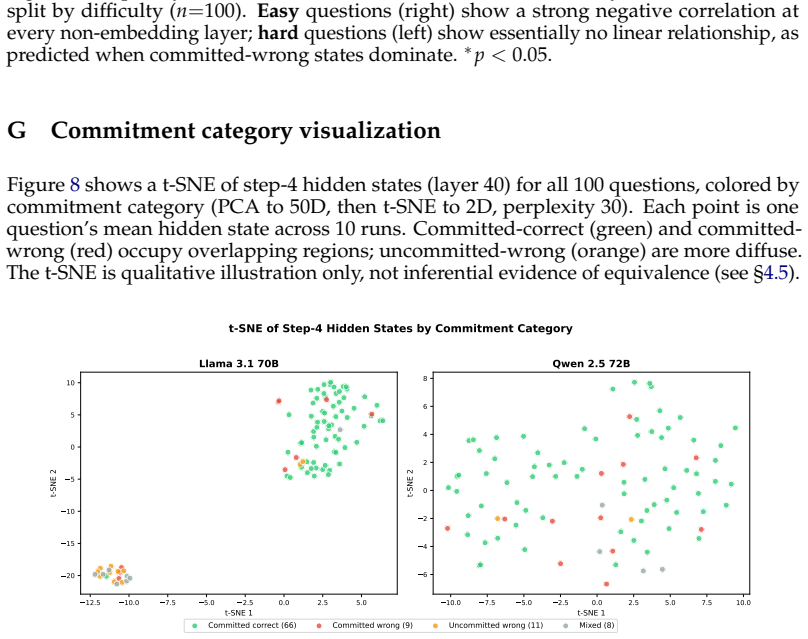
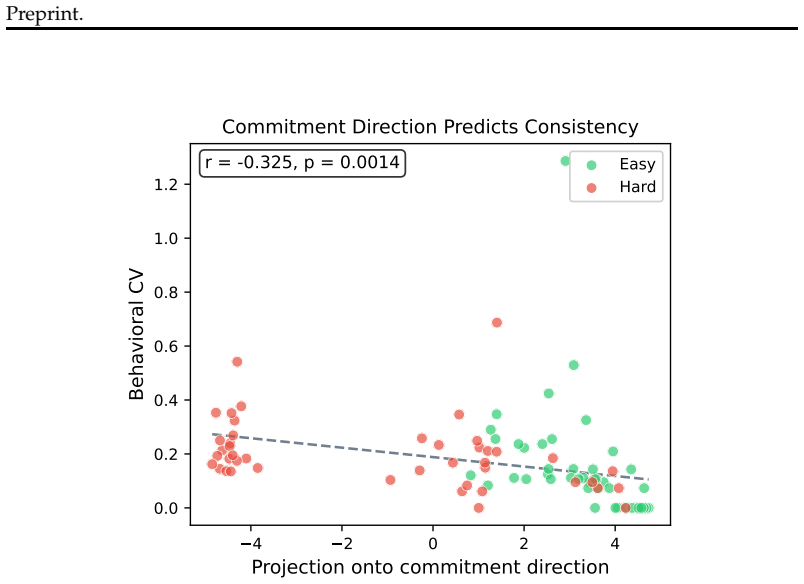
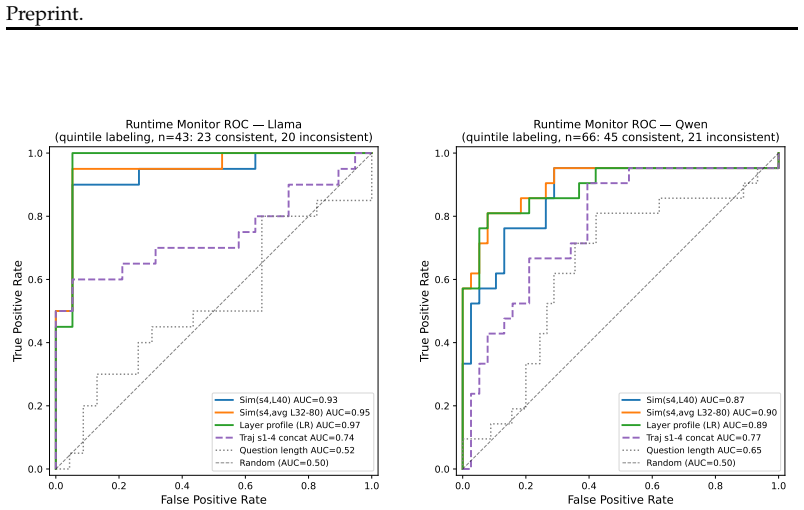
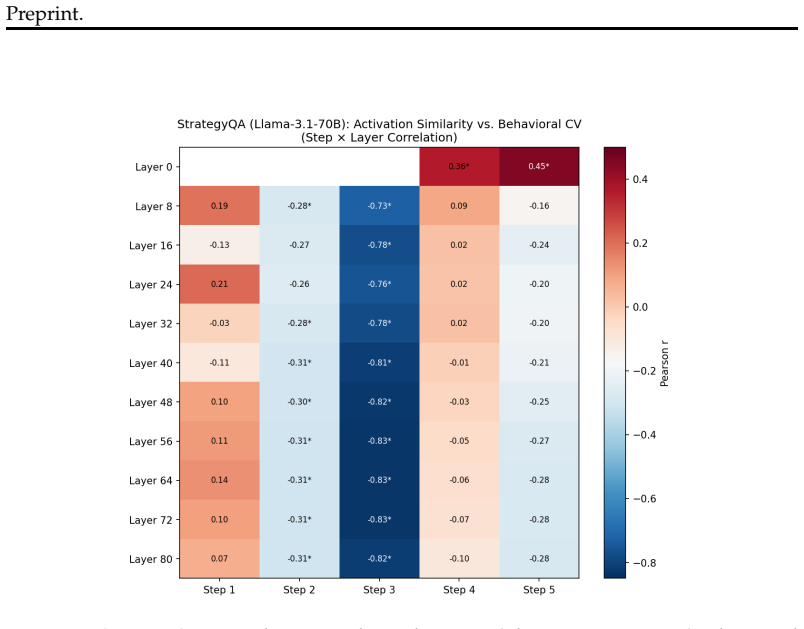
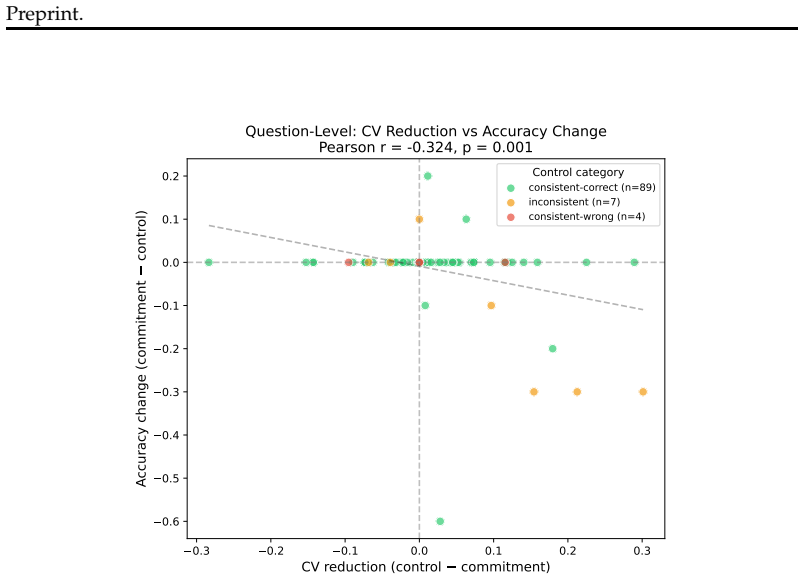
Representational commitment, measured as cross-run hidden-state convergence at a fixed reasoning step, diagnoses premature commitment in LLM agent trajectories. On Llama-3.1-70B running ReAct on HotpotQA, step-4 hidden-state similarity predicts downstream behavioral consistency with r = -0.35 and partial r = -0.45; the relation replicates on Qwen-2.5-72B, Phi-3-14B, and StrategyQA with r = -0.83. The signal does not separate committed-wrong from committed-correct cases and therefore tracks whether an agent has settled rather than whether it is right. A hidden-state monitor reaches AUROC 0.97 for detecting inconsistent trajectories, while a prompting intervention reduces behavioral variance b
What carries the argument
Representational commitment defined as cross-run hidden-state convergence at a fixed reasoning step, serving as an early indicator of trajectory consistency.
If this is right
- Early hidden-state monitoring can identify agents that will produce consistent but potentially narrow trajectories before the run ends.
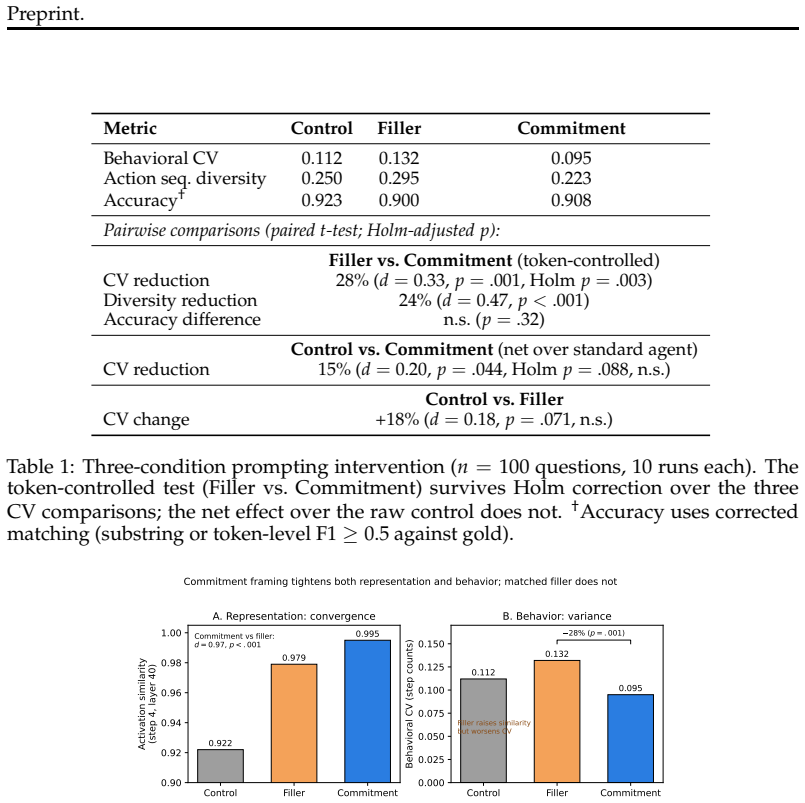
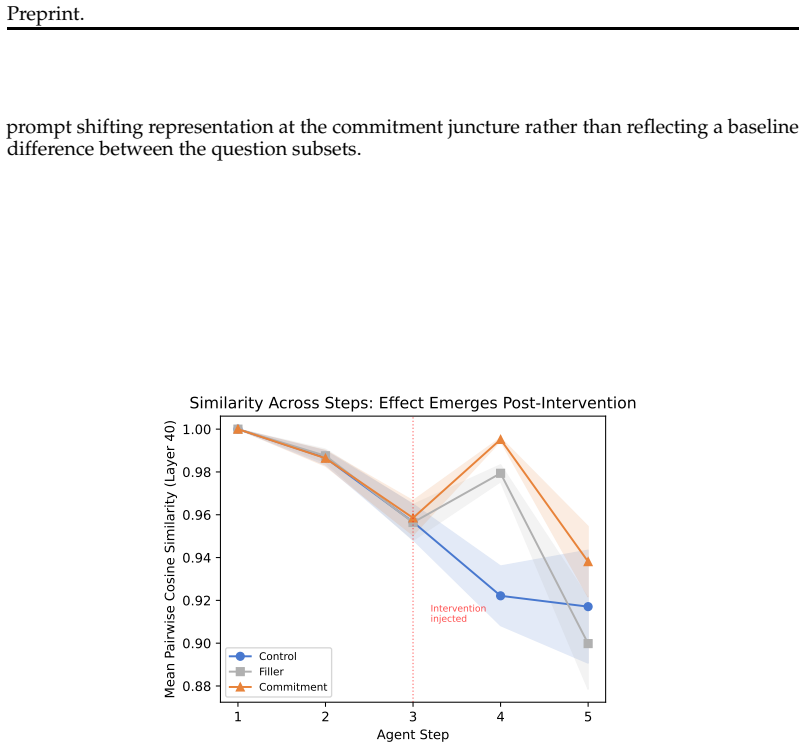
- A prompting intervention derived from the signal reduces output variance by 28 percent while leaving accuracy unchanged.
- The diagnostic transfers across model sizes and across HotpotQA and StrategyQA but provides only modest help for routing self-consistency compute on harder tasks.
- Because the signal is orthogonal to correctness, it can flag settled-wrong paths without conflating them with accuracy failures.
Where Pith is reading between the lines
- Agents could be modified to inject diversity at the specific step where convergence is first detected, potentially avoiding premature settling.
- The layer-wise and temporal signature of the signal suggests targeted monitoring or editing at particular layers rather than full-run checks.
- Combining the commitment monitor with separate correctness checks could produce agents that are both more consistent and more accurate than either method alone.
- The approach may generalize to other long-horizon sequential tasks where early stabilization of internal representations limits exploration.
Load-bearing premise
Cross-run hidden-state convergence at one fixed step measures a distinct process of representational commitment that is separate from correctness or output variance.
What would settle it
Observing no correlation between step-4 hidden-state similarity and later behavioral consistency on a held-out set of questions, or finding that committed-wrong and committed-correct cases become separable in the same activations.
Figures
read the original abstract
Long-horizon LLM agents can fail quietly: they settle on one reading of the evidence early, then spend the rest of the run defending it. We call this premature commitment. Final-answer scoring misses the failure mode because it sees only the answer, not whether the process has already collapsed to a stable path. We define representational commitment as cross-run hidden-state convergence at a fixed reasoning step, and use it as an early diagnostic of trajectory consistency. On Llama-3.1-70B running ReAct on HotpotQA, step-4 hidden-state similarity predicts downstream behavioral consistency (r = -0.35, partial r = -0.45), with a localized temporal and layer-wise signature. The signal replicates across Qwen-2.5-72B and Phi-3-14B, and on StrategyQA (r = -0.83). It does not track correctness: committed-wrong and committed-correct questions are not separable in activation similarity. That boundary is central to the claim. Commitment tells us whether an agent has settled, not whether it is right. A runtime monitor detects inconsistent trajectories from hidden states at AUROC up to 0.97 (0.85--0.88 under a stricter split), and a prompting intervention cuts behavioral variance by 28% against a token-matched control while leaving accuracy statistically unchanged. We also test whether the signal can route self-consistency compute; on a harder benchmark it helps only modestly and is matched by a simpler output-based baseline. The result is a diagnostic for a hidden process failure, with clear limits rather than a general accuracy lever.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines representational commitment as cross-run hidden-state convergence at a fixed early reasoning step in LLM agents and claims this measure predicts downstream behavioral consistency (r = -0.35, partial r = -0.45 on Llama-3.1-70B ReAct HotpotQA; r = -0.83 on StrategyQA), replicates across models, is independent of correctness, supports an AUROC-0.97 runtime monitor for inconsistent trajectories, and enables a prompting intervention that reduces behavioral variance by 28% without harming accuracy.
Significance. If the central correlation and its separation from correctness hold after clarification, the work supplies a process-level diagnostic for a failure mode missed by final-answer metrics, with demonstrated runtime utility and cross-model replication. The modest gains when routing self-consistency compute and the explicit limits noted in the abstract keep the practical impact focused rather than overstated.
major comments (2)
- [Abstract] Abstract: the reported negative correlation (r = -0.35) between hidden-state similarity (commitment) and behavioral consistency contradicts the directional prediction implied by the definition. Higher cross-run similarity at step 4 should correspond to higher (not lower) trajectory consistency if consistency is an agreement metric; the sign reversal affects interpretation of the partial correlation, the AUROC monitor, and the intervention result. The manuscript must define the exact behavioral-consistency metric (agreement rate, variance, or divergence) and justify the observed polarity.
- [Methods / Results] Methods and results sections: the abstract supplies AUROC values, partial correlations, and a 28% variance reduction but provides no details on the similarity metric, chosen layers, exact step selection, controls for output variance, or whether layer/step choices were pre-specified versus post-hoc. These choices are load-bearing for the claim that the signal is a distinct process failure mode.
minor comments (1)
- [Abstract] Abstract: state explicitly whether behavioral consistency is quantified as agreement (higher = more consistent) or as a divergence score.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address both major points by clarifying the behavioral-consistency metric and expanding methodological details in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported negative correlation (r = -0.35) between hidden-state similarity (commitment) and behavioral consistency contradicts the directional prediction implied by the definition. Higher cross-run similarity at step 4 should correspond to higher (not lower) trajectory consistency if consistency is an agreement metric; the sign reversal affects interpretation of the partial correlation, the AUROC monitor, and the intervention result. The manuscript must define the exact behavioral-consistency metric (agreement rate, variance, or divergence) and justify the observed polarity.
Authors: We agree the metric requires explicit definition. Behavioral consistency is operationalized as normalized cross-run answer variance (equivalently, disagreement rate), so higher values indicate greater inconsistency. Greater hidden-state convergence therefore predicts lower variance scores, producing the negative correlation. We will add this definition and polarity justification to the abstract and methods, and update related interpretations. revision: yes
-
Referee: [Methods / Results] Methods and results sections: the abstract supplies AUROC values, partial correlations, and a 28% variance reduction but provides no details on the similarity metric, chosen layers, exact step selection, controls for output variance, or whether layer/step choices were pre-specified versus post-hoc. These choices are load-bearing for the claim that the signal is a distinct process failure mode.
Authors: The methods section specifies cosine similarity on hidden states, but we acknowledge the need for greater transparency. We will expand it to report the exact metric, specific layers, step-4 rationale, output-length controls, and whether layer/step selection was pre-specified or exploratory. This will strengthen the claim that the signal is distinct from correctness. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines representational commitment explicitly as cross-run hidden-state convergence at a fixed step and reports its empirical correlation with separately measured behavioral consistency (r values, AUROC for trajectory detection). No equations, parameters, or self-citations reduce the diagnostic signal, the reported correlations, or the intervention results to a fitted input, self-definition, or renamed prior result. The negative sign of the correlation is a potential interpretive or correctness concern but does not create a circular reduction by construction. The central claim remains an independent empirical mapping between two distinct measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM hidden states at intermediate layers and steps capture aspects of the agent's current reasoning trajectory that are comparable across runs
invented entities (1)
-
representational commitment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Amin, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with LLMs
Pranjal Aggarwal, Aman Madaan, Yiming Yang, and Mausam. Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with LLMs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
2023
-
[3]
The Internal State of an LLM Knows When It's Lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying.arXiv preprint arXiv:2304.13734,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Discovering Latent Knowledge in Language Models Without Supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision.arXiv preprint arXiv:2212.03827,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. Persona vec- tors: Monitoring and controlling character traits in language models.arXiv preprint arXiv:2507.21509,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aieleen Letman, Akhil Mathur, Alan Schelten, Amy Yang, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Christina Lu, Jack Gallagher, Jonathan Michala, Kyle Fish, and Jack Lindsey. The assistant axis: Situating and stabilizing the default persona of language models.arXiv preprint arXiv:2601.10387,
-
[9]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Aman Mehta. When agents disagree with themselves: Measuring behavioral consistency in LLM-based agents.arXiv preprint arXiv:2602.11619, 2026a. Aman Mehta. Consistency amplifies: How behavioral variance shapes agent accuracy.arXiv preprint arXiv:2603.25764, 2026b. Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geo...
-
[11]
Steering Language Models With Activation Engineering
10 Preprint. Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Leela Castricato. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Wang, Bowen Zheng, Chengyuan Yu, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdi- nov, and Christopher D Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering.arXiv preprint arXiv:1809.09600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Reasoning models know when they’re right: Probing hidden states for self-verification. arXiv preprint arXiv:2504.05419,
-
[17]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
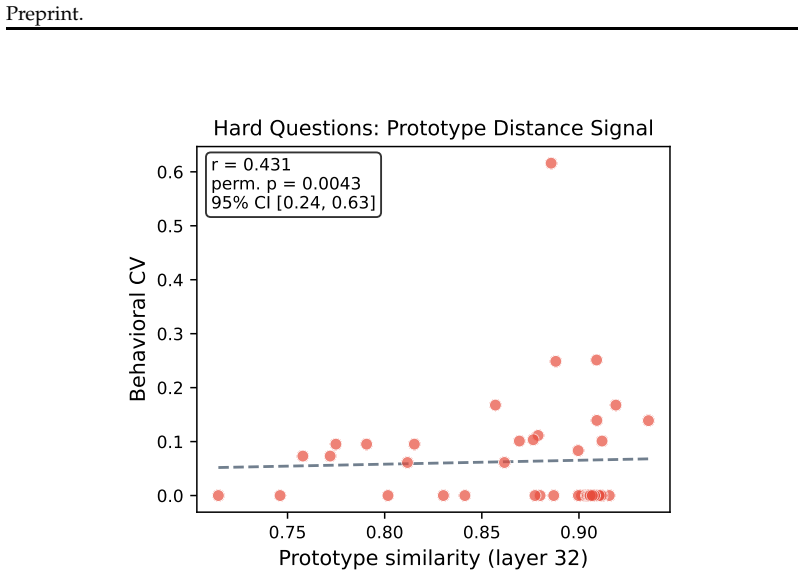
p = 0.0043 95% CI [0.24, 0.63] Hard Questions: Prototype Distance Signal Figure 9: Hard-question prototype signal: cosine similarity to hard-question centroid vs
0.0 0.1 0.2 0.3 0.4 0.5 0.6Behavioral CV r = 0.431 perm. p = 0.0043 95% CI [0.24, 0.63] Hard Questions: Prototype Distance Signal Figure 9: Hard-question prototype signal: cosine similarity to hard-question centroid vs. behavioral CV (step 4, layer 32). Questions further from the centroid are more consistent (r=0.43, perm.p=0.004). J Commitment as a linea...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.