On the Benefits of Free Exploration for Regret Minimization in Multi-Armed Bandits
Pith reviewed 2026-06-29 23:13 UTC · model grok-4.3
The pith
A logarithmic free exploration budget before regret starts lets UFE-KLUCB-H accumulate strictly less regret than policies without it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
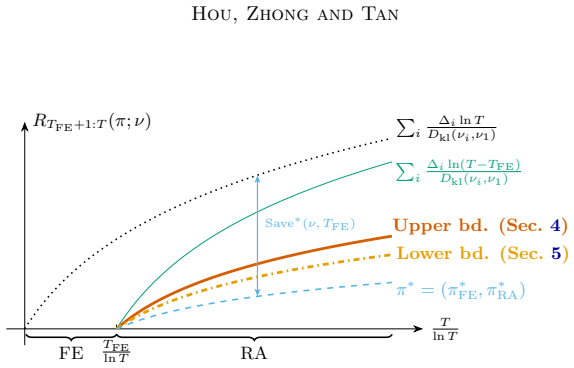
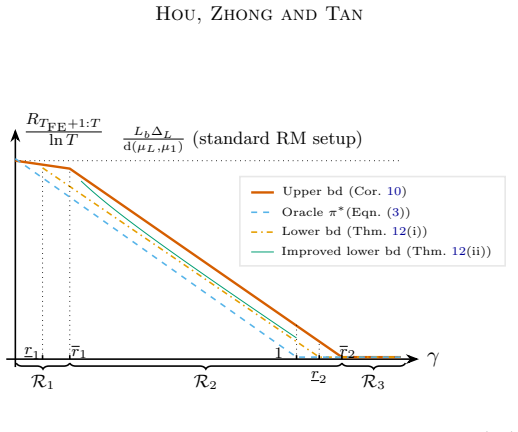
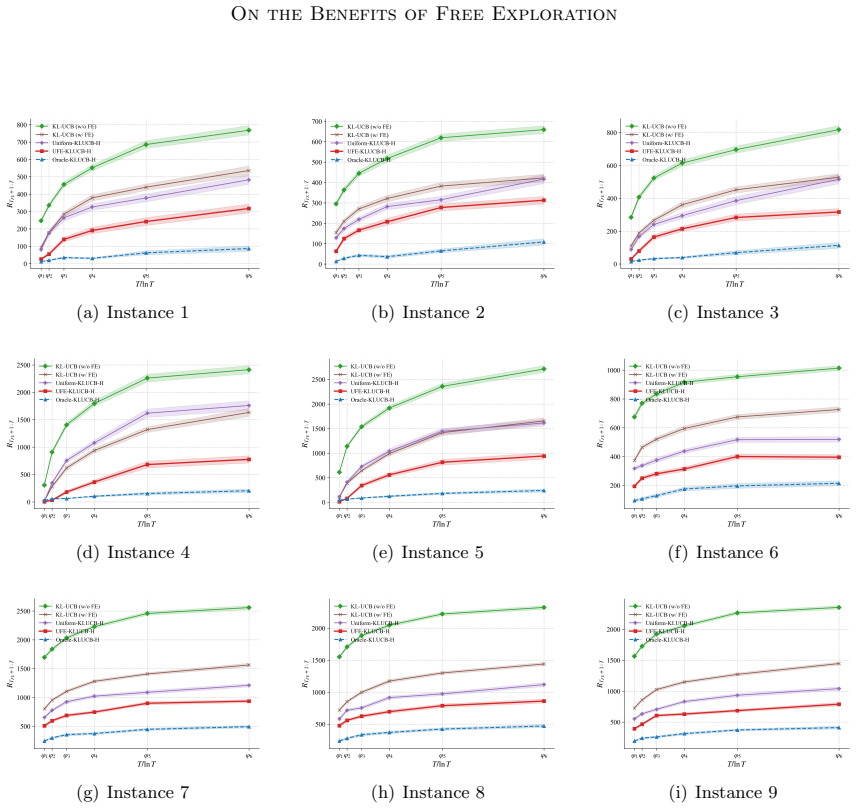
The central claim is that UFE-KLUCB-H, which pairs a principled free exploration policy UFE with the history-aware regret minimizer KLUCB-H, accumulates strictly less regret than policies lacking access to a free exploration phase. This is established through instance-dependent upper bounds on the regret, complemented by lower bounds derived via multi-instance perturbation arguments that establish near-optimality specifically for two-valued bandits. The bounds together reveal sharp phase transitions in accumulated regret that depend on the size of the available free exploration budget.
What carries the argument
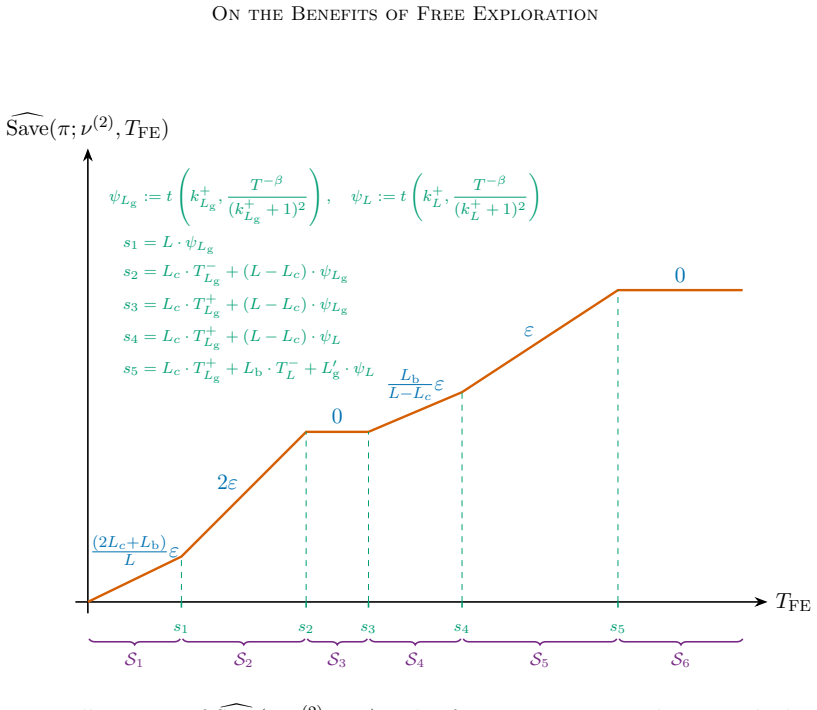
The two-phase UFE-KLUCB-H algorithm together with the definition of (α,β)-probably saving policies, which measure the high-probability regret saved due to the free exploration phase.
If this is right
- Regret exhibits sharp phase transitions as a function of the free exploration budget size.
- UFE-KLUCB-H is near-optimal for two-valued bandits according to the matching lower bounds.
- Forced exploration combined with adaptivity produces greater regret savings than non-adaptive approaches.
- The probably saving policies provide a formal way to certify regret reduction from any free exploration phase.
Where Pith is reading between the lines
- The multi-instance perturbation technique for lower bounds may extend to other settings where an initial free phase alters the information structure.
- The separation into free and paid phases could be tested in non-stationary or contextual bandit problems where early samples have lasting value.
- If the logarithmic scaling holds more broadly, it suggests a general principle that modest free data can produce permanent regret savings in sequential decision tasks.
Load-bearing premise
The free exploration budget scales logarithmically with the time horizon.
What would settle it
A two-valued bandit instance in which the realized cumulative regret of UFE-KLUCB-H is not strictly smaller than that of a standard policy without free exploration, or fails to approach the derived lower bound.
Figures
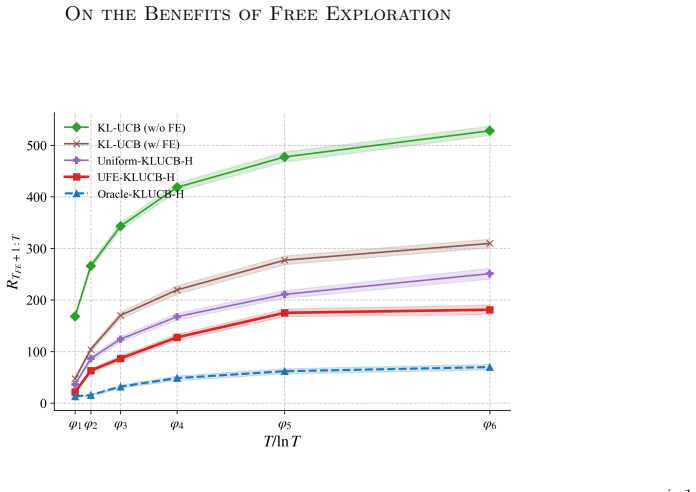
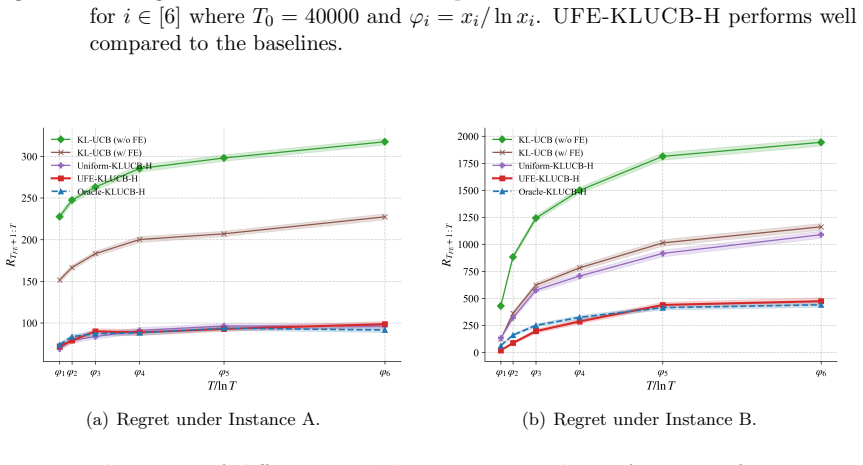
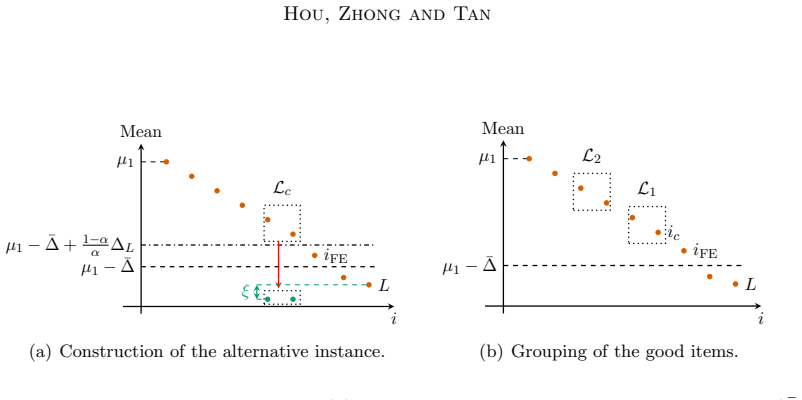
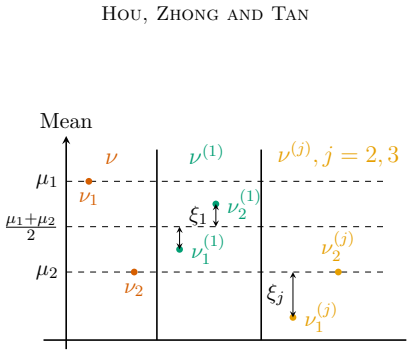
read the original abstract
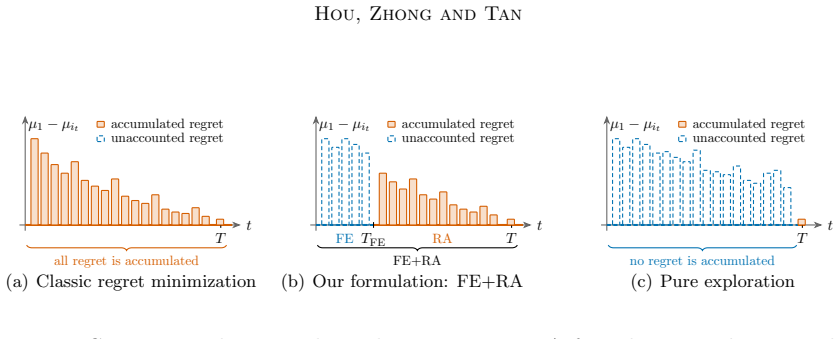
We study a stochastic multi-armed bandit problem where an agent is granted a free exploration budget before regret accumulates, a setting not captured by the classic regret minimization or pure exploration paradigms. The goal is to design an adaptive policy that strategically explores the bandit instance in the initial free exploration phase and minimizes the cumulative regret in the subsequent phase. We formalize this regret minimization with free exploration problem and identify an interesting regime where the free exploration budget scales logarithmically with the time horizon. To quantify the amount of regret saved with high probability as a result of the availability of the free exploration phase, we introduce a novel set of policies known as $(\alpha,\beta)$-probably saving policies. We propose a two-phase, probably saving algorithm, UFE-KLUCB-H, which consists of a principled free exploration policy, UFE, and a history-aware regret minimization policy KLUCB-H. Instance-dependent upper bounds on UFE-KLUCB-H are derived, showing that UFE-KLUCB-H accumulates strictly less regret than policies that do not have access to a free exploration phase. Complementarily, we derive instance-dependent lower bounds based on novel multi-instance perturbation arguments tailored to the free-exploration setting, demonstrating the near-optimality of UFE-KLUCB-H for two-valued bandits. Our upper and lower bounds reveal sharp phase transitions in the accumulated regret depending on the amount of available free exploration. Simulations are conducted to demonstrate that forced exploration and adaptivity in the algorithm lead to greater regret savings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes a stochastic multi-armed bandit setting with an initial free exploration budget (scaling logarithmically with the horizon) before regret accumulation begins. It introduces (α,β)-probably saving policies, proposes the two-phase UFE-KLUCB-H algorithm (UFE for free exploration followed by history-aware KLUCB-H), derives instance-dependent upper bounds showing strictly less regret than policies without free exploration, and provides complementary instance-dependent lower bounds via novel multi-instance perturbation arguments that establish near-optimality for two-valued bandits, along with sharp phase transitions in accumulated regret.
Significance. If the upper and lower bounds hold, the work bridges classic regret minimization and pure exploration by quantifying regret savings from free exploration and identifying phase-transition regimes. The probably-saving policy framework and tailored perturbation arguments could influence algorithm design in settings with cheap initial samples. The explicit upper-bound comparison to no-free-exploration baselines is a clear strength.
major comments (1)
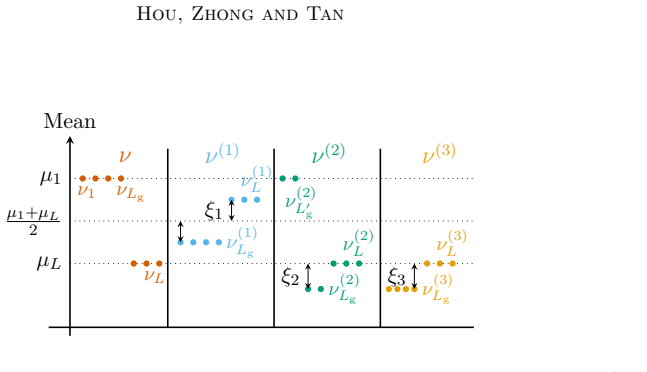
- [Lower bound section (multi-instance perturbation arguments)] The section deriving the instance-dependent lower bounds: the multi-instance perturbation arguments must explicitly adjust for the free exploration phase contributing information at zero regret cost. The manuscript should detail the perturbation construction (e.g., how the information-regret separation is maintained and why the arguments remain valid when the first phase incurs no cost) to confirm that the lower bound is not loose; any uniform treatment of pulls across phases would undermine the near-optimality claim for UFE-KLUCB-H on two-valued bandits.
minor comments (1)
- [Abstract] The abstract states that simulations demonstrate benefits of forced exploration and adaptivity but provides no details on the number of runs, random seeds, or error-bar construction; adding this information would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We appreciate the recognition of the work's significance in quantifying regret savings from free exploration. We address the single major comment below.
read point-by-point responses
-
Referee: [Lower bound section (multi-instance perturbation arguments)] The section deriving the instance-dependent lower bounds: the multi-instance perturbation arguments must explicitly adjust for the free exploration phase contributing information at zero regret cost. The manuscript should detail the perturbation construction (e.g., how the information-regret separation is maintained and why the arguments remain valid when the first phase incurs no cost) to confirm that the lower bound is not loose; any uniform treatment of pulls across phases would undermine the near-optimality claim for UFE-KLUCB-H on two-valued bandits.
Authors: We agree that greater explicitness in the perturbation construction will strengthen the presentation. Our multi-instance arguments are constructed by applying perturbations exclusively to the reward distributions governing the regret-accumulation phase (after the free budget is exhausted), while the free-exploration phase is modeled as supplying initial samples at zero regret cost. This separation is maintained by defining the perturbed instances such that any information obtained during free exploration does not resolve the uncertainty that forces additional pulls (and thus regret) in the second phase; the adversary's choice of perturbations is restricted to differences that remain hidden after the logarithmic free budget. We will revise the lower-bound section to spell out this phase-separated construction, the information-regret decoupling, and the avoidance of uniform pull counting across phases. These clarifications will directly support the near-optimality claim for two-valued bandits. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper introduces a new problem setting (regret minimization with free exploration budget), defines novel (α,β)-probably saving policies, proposes UFE-KLUCB-H with UFE free-exploration phase and KLUCB-H regret phase, and derives instance-dependent upper/lower bounds using multi-instance perturbation arguments. No quoted step reduces a claimed prediction or bound to a fitted parameter, self-defined quantity, or load-bearing self-citation by construction. The lower-bound perturbation arguments are presented as novel and tailored to separate the zero-regret free phase from the regret phase, with no evidence that they collapse to prior equations or author-only citations. Upper bounds are derived directly from the algorithm's analysis rather than renamed empirical patterns. This matches the default expectation of an independent derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Degenne, T
R. Degenne, T. Nedelec, C. Calauzenes, and V. Perchet. Bridging the gap between regret minimization and best arm identification, with application to A/B tests. InProceedings 52 On the Benefits of Free Exploration of the 22nd International Conference on Artificial Intelligence and Statistics, pages 1988– 1996,
1988
- [2]
- [3]
-
[4]
F. Sentenac, I. Lee, and C. Szepesvari. Balancing optimism and pessimism in offline-to- online learning.arXiv preprint arXiv:2502.08259,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.