VistaHop: Benchmarking Multi-hop Visual Reasoning for Visual DeepSearch
Pith reviewed 2026-06-28 10:33 UTC · model grok-4.3
The pith
A new benchmark shows the best multimodal reasoning models solve only 24% of multi-hop visual search tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
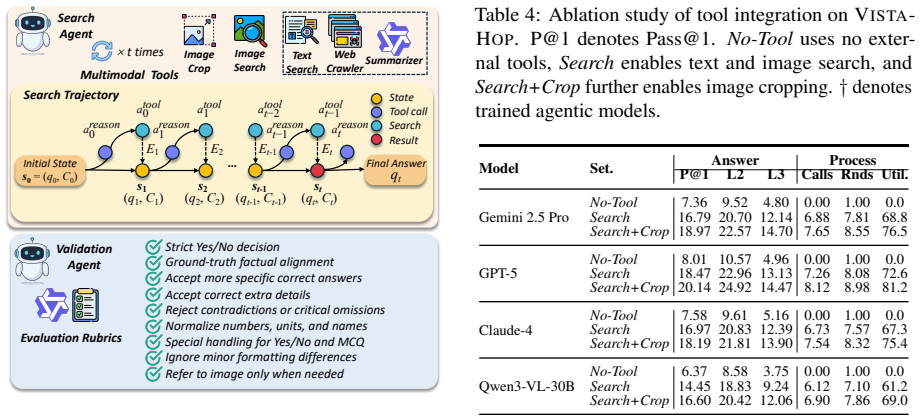
VistaHop consists of 300 high-resolution images organized into 25 visual search scenarios and 350 multi-hop QA tasks that force models to follow evidence chains starting from visual anchors or to fuse information across multiple image-grounded reasoning paths. Evaluation occurs inside VistaArena, a unified environment supporting tool-augmented reasoning through text search, image search, image cropping, and evidence-based answer validation. Across seven representative multimodal large reasoning models, the highest Pass@1 score is 24.31% from SenseNova-MARS-32B, exposing consistent weaknesses in visual grounding, evidence revisiting, long-chain reasoning, and multi-anchor information fusion.
What carries the argument
The VistaHop benchmark of 25 scenarios and 350 multi-hop QA tasks, evaluated inside the VistaArena tool-augmented environment that enables iterative image cropping and evidence chaining.
If this is right
- Stronger training methods are needed to improve visual grounding and evidence revisiting in multimodal models.
- Evaluation frameworks must incorporate iterative image inspection and long-chain reasoning rather than static questions.
- Multi-anchor information fusion remains an open requirement for solving visual deep search tasks.
- Tool support for cropping and searching within images is necessary to measure true agent capabilities.
- Current models remain far from solving the tasks posed by VistaHop.
Where Pith is reading between the lines
- Agent designs may benefit from explicit mechanisms that store and revisit specific image regions across steps.
- The performance gap suggests that simply increasing model size may not close the deficit without targeted multi-hop training data.
- VistaHop could be adapted to test visual agents in domains such as medical image review or document navigation.
- Repeated tool calls for cropping may expose context-length limits that static benchmarks miss.
Load-bearing premise
The 25 visual search scenarios and 350 multi-hop QA tasks are constructed to faithfully represent the core challenges of Visual DeepSearch without introducing selection biases or over-specific task designs that do not generalize.
What would settle it
A model achieving above 70% Pass@1 on VistaHop while retaining strong results on standard visual QA benchmarks would indicate that the reported limitations are not fundamental.
Figures




read the original abstract
Visual DeepSearch requires multimodal large reasoning model (MLRM) agents to answer complex visual queries by repeatedly inspecting image regions, grounding intermediate reasoning in visual evidence, and connecting fine-grained clues across long reasoning chains. However, existing benchmarks mainly focus on single-step visual understanding or static image-question answering, offering limited evaluation of iterative image inspection, visual-anchor grounding, and multi-hop evidence integration. In this work, we introduce VistaHop, a benchmark for evaluating vision-centric search and multi-hop visual reasoning in Visual DeepSearch. VistaHop contains 300 high-resolution images, 25 visual search scenarios, and 350 multi-hop QA tasks that require models to follow evidence chains from visual anchors or fuse information across multiple image-grounded reasoning paths. We further develop VistaArena, a unified evaluation environment that supports tool-augmented reasoning with text search, image search, image cropping, and evidence-based answer validation. Experiments on seven representative MLRMs show that current models remain far from solving VistaHop: the best model, SenseNova-MARS-32B, achieves only 24.31% Pass@1. These results reveal persistent limitations in visual grounding, evidence revisiting, long-chain reasoning, and multi-anchor information fusion, highlighting the need for stronger benchmarks and training methods for Visual DeepSearch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VistaHop, a benchmark with 300 high-resolution images, 25 visual search scenarios, and 350 multi-hop QA tasks for evaluating iterative visual inspection, visual-anchor grounding, and multi-hop evidence integration in multimodal large reasoning models (MLRMs) for Visual DeepSearch. It also presents VistaArena, a tool-augmented evaluation environment supporting text/image search, cropping, and evidence validation. Experiments across seven MLRMs report a best Pass@1 of 24.31% (SenseNova-MARS-32B), which the authors attribute to persistent limitations in visual grounding, evidence revisiting, long-chain reasoning, and multi-anchor fusion.
Significance. If the tasks are shown to require the targeted multi-hop operations, VistaHop would fill a gap left by single-step or static VQA benchmarks and provide concrete, falsifiable performance numbers to guide improvements in vision-centric agentic reasoning. The unified VistaArena environment and the scale of the evaluation (seven models) are positive contributions that could support reproducible follow-up work.
major comments (1)
- [§3] §3 (Benchmark Construction): The description of the 25 scenarios and 350 tasks provides no details on hop-count validation, shortcut detection (e.g., whether single-step or text-only solutions suffice), or inter-annotator reliability checks. This is load-bearing for the central claim in the abstract and §4 that the 24.31% score specifically reveals limitations in visual grounding, evidence revisiting, long-chain reasoning, and multi-anchor fusion; without such validation the performance gap cannot be confidently attributed to those failure modes rather than task artifacts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on VistaHop. We address the major comment regarding benchmark construction below and will incorporate the requested details in the revised manuscript to strengthen the attribution of results.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The description of the 25 scenarios and 350 tasks provides no details on hop-count validation, shortcut detection (e.g., whether single-step or text-only solutions suffice), or inter-annotator reliability checks. This is load-bearing for the central claim in the abstract and §4 that the 24.31% score specifically reveals limitations in visual grounding, evidence revisiting, long-chain reasoning, and multi-anchor fusion; without such validation the performance gap cannot be confidently attributed to those failure modes rather than task artifacts.
Authors: We acknowledge that §3 currently lacks explicit documentation of the validation procedures. The 25 scenarios were iteratively designed by experts to require multi-hop visual chaining (e.g., using one visual anchor to locate subsequent evidence), with tasks filtered to exclude single-step or text-only solutions. However, we agree that reporting hop-count validation, shortcut detection methods, and inter-annotator reliability is necessary to support the claims. In the revision, we will expand §3 with: (1) the process for assigning and verifying minimum hop counts per task, (2) the checks (manual review plus automated text/image-only baselines) confirming no shortcuts remain in the final 350 tasks, and (3) inter-annotator agreement metrics from multiple annotators. This will allow clearer attribution of the 24.31% Pass@1 to the targeted limitations. revision: yes
Circularity Check
No circularity: new benchmark tasks and metrics are independent of fitted parameters or self-referential definitions
full rationale
The paper constructs VistaHop as a new set of 350 multi-hop QA tasks across 25 scenarios on 300 images, evaluated in the new VistaArena environment. Model performance (e.g., 24.31% Pass@1) is measured directly on these tasks without any equations, fitted parameters, or predictions that reduce to prior inputs by construction. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify the core results. The interpretation of limitations follows from the observed scores rather than any definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-hop visual reasoning in Visual DeepSearch can be measured through curated QA tasks that require evidence chains from visual anchors or fusion across multiple image-grounded paths.
Reference graph
Works this paper leans on
-
[1]
Mahtab Bigverdi, Zelun Luo, Cheng-Yu Hsieh, Ethan Shen, Dongping Chen, Linda G
Qwen3-VL Technical Report.Preprint, arXiv:2511.21631. Mahtab Bigverdi, Zelun Luo, Cheng-Yu Hsieh, Ethan Shen, Dongping Chen, Linda G. Shapiro, and Ran- jay Krishna. 2025. Perception tokens enhance visual reasoning in multimodal language models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3836– 3845. ...
Pith/arXiv arXiv 2025
-
[2]
Rlfactory: A plug-and-play reinforcement learning post-training framework for llm multi-turn tool-use.Preprint, arXiv:2509.06980. Hao Chen, Zhexin Hu, Jiajun Chai, Haocheng Yang, Hang He, Xiaohan Wang, Wei Lin, Luhang Wang, Guojun Yin, and Zhuofeng zhao. 2025. Toolforge: A data synthesis pipeline for multi-hop search without real-world apis.Preprint, arXi...
arXiv 2025
-
[3]
see the world, dis- cover knowledge
ChineseSimpleVQA – “see the world, dis- cover knowledge”: A chinese factuality evaluation for large vision language models.arXiv preprint arXiv:2502.11718. Yunzhuo Hao, Jiawei Gu, Huichen Will Wang, Linjie Li, Zhengyuan Yang, Lijuan Wang, and Yu Cheng. 2025. Can MLLMs reason in multimodality? EMMA: An enhanced multimodal reasoning benchmark.arXiv preprint...
arXiv 2025
-
[4]
An Yang, Anfeng Li, Baosong Yang, and 1 others
ProMMSearchAgent: A generalizable mul- timodal search agent trained with process-oriented rewards.arXiv preprint arXiv:2604.20486. An Yang, Anfeng Li, Baosong Yang, and 1 others
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Junyan Ye, Dongzhi Jiang, Jun He, Baichuan Zhou, Zilong Huang, Zhiyuan Yan, Hongsheng Li, Conghui He, and Weijia Li. 2025. BLINK-Twice: You see, but do you observe? a reasoning benchmark on visual perception.arXiv preprint arXiv:2510.09361. Yu Zeng, Wenxuan Huang, Zhen Fang, Shuang Chen, Yufan Shen, ...
Pith/arXiv arXiv 2025
-
[6]
One-sentence description of what the entity is
-
[7]
Main type of entity (person/place/event/object/concept)
-
[8]
Key attributes of the entity (achievements, characteristics, etc.)
-
[9]
description
Most related entities to this entity Return JSON: { "description": "One-sentence description", "entity_type": "person/place/event/object/concept", "properties": { "key1": "value1", "key2": "value2" }, "related_entities": ["entity1", "entity2", "entity3"] } Return JSON only, no other content. B.3 Prompts for Evidence Chain Construction This stage construct...
2024
-
[10]
has_duplicates
If no duplicates, return "has_duplicates": false
-
[11]
The merged entity should be a more general or specific concept
-
[12]
Only consider duplicate relationships between directly connected nodes B.4 Prompts for Textual QA Construction and Anti-Leakage Verification This stage generates text questions from evidence chains and applies the multi-agent anti-leakage loop. The SOLVERattempts to answer each ques- tion using only the text, the JUDGEidentifies leak- age or question issu...
-
[13]
Reverse Entity Order: - The phrasing of the question should follow the entity order of the reasoning chain in reverse, from the final entity toward the seed entity
-
[14]
- Describe entities indirectly using attributes, categories, or general characteristics
Obfuscation & Vagueness: - Never directly mention the final answer entity or any intermediate entities by name. - Describe entities indirectly using attributes, categories, or general characteristics. - Avoid giving away the reasoning path; each step must be subtle
-
[15]
- Each reasoning step should provide a vague constraint or clue that requires external search or knowledge verification
Difficulty & Multi-Step Search: - The question should require exactly N reasoning steps (where N = number of nodes in the chain). - Each reasoning step should provide a vague constraint or clue that requires external search or knowledge verification
-
[16]
- Keep the entity order reversed but the reasoning chain intact
Clarity of Requirements for Generation: - Maintain coherence and fluency. - Keep the entity order reversed but the reasoning chain intact. - Ensure the question is solvable via logical reasoning over external information, without revealing shortcuts. IMPORTANT - Anti-Leakage Requirements:
-
[17]
NEVER directly mention the final answer entity in the question text
-
[18]
Make clues V AGUE and INDIRECT - use indirect descriptions rather than specific names
-
[19]
Use OBFUSCATED descriptions - describe entities by their attributes rather than names
-
[20]
Avoid giving away the reasoning path
-
[21]
The question should be like a puzzle that requires multi-step search and reasoning
-
[22]
Which company founded by Elon Musk
Use RELATIVE/COMPARATIVE descriptions instead of absolute direct references - BAD: "Which company founded by Elon Musk..." - GOOD: "Which aerospace company founded..." Please generate a natural question where the final answer is the last entity in the chain: ```json { "question": "Generated question", "constraints": ["constraint1", "constraint2", ...], "r...
-
[23]
Reverse Entity Order: The phrasing follows the entity order in reverse
-
[24]
Obfuscation & Vagueness: Never directly mention the final answer or intermediate entities
-
[25]
Difficulty & Multi-Step Search: Each reasoning step provides vague constraints
-
[26]
judge_feedback
Anti-Leakage Requirements: Vague and indirect descriptions, no direct names. Instructions: - Use the "judge_feedback" field to understand WHY the question leaks and HOW to fix it. - The visual entity in the root node should be replaced with a visual reference. - Do NOT reveal the identity of the visual entity through text descriptions. - Keep the reasonin...
-
[27]
Extract ONLY the ROOT ENTITY (seed entity) from each question
-
[28]
Transform questions to VQA format by replacing the root entity with a visual reference
-
[29]
Use the root_entity_type to determine the appropriate visual reference
-
[30]
root_visual_description
IMPORTANT: Use the "root_visual_description" field to add visual context to the question EXTRACTION RULES: - ONLY extract the root entity (the seed entity from the evidence chain) - The root entity is the starting point of the reasoning chain - Do NOT extract intermediate or leaf entities CRITICAL: USING ROOT_VISUAL_DESCRIPTION: Each question item include...
1990
-
[31]
first_letter_ascii: Use ASCII value of the first letter of the answer
-
[32]
first_letter_alphabet: Position of first letter in the English alphabet (A=1, B=2, ..., Z=26)
-
[33]
character_count: Number of characters, excluding spaces and punctuation
-
[34]
word_count: Number of words in the answer
-
[35]
vowel_count: Number of vowels (a, e, i, o, u, case-insensitive)
-
[36]
digit_sum: Sum of all digits present in the answer
-
[37]
founding_year: Extract a valid founding/establishment year (only if the year is NOT present in the question)
-
[38]
Hamburg",
founding_year_diff: 2026 minus the founding year (only if the year is NOT present in the question) IMPORTANT RULES: - If the answer contains a YEAR (like 1974, 1885, 1999), use founded_year or founded_year_diff - If the answer is a SHORT NAME (like "Hamburg", "Paris"), use first_letter_ascii_sum - If the answer is a SENTENCE/PHRASE, use character_count or...
2026
-
[39]
ADD: Sum all extracted values
-
[40]
SUBTRACT: Subtract second from first (for exactly 2 chains)
-
[41]
MULTIPLY: Multiply all values
-
[42]
DIVIDE: Divide first by second (for exactly 2 chains)
-
[43]
MAX: Return the maximum value
-
[44]
MIN: Return the minimum value
-
[45]
Operation: [ADD/SUBTRACT/MULTIPLY/DIVIDE/MAX/MIN/A VG] Reason: [brief explanation in English] Return your answer using the format above, no other text
A VG: Return the average of all values Choose the operation that produces the most meaningful and verifiable result. Operation: [ADD/SUBTRACT/MULTIPLY/DIVIDE/MAX/MIN/A VG] Reason: [brief explanation in English] Return your answer using the format above, no other text. Table 28: Prompt for Stage 6 fused question generation. Stage 6 — Fused question generat...
-
[46]
Naturally integrates content from ALL {n} original VQA questions about the image
-
[47]
Clearly asks the solver to compute the {operation_display} of numerical values derived from the corresponding answers
-
[48]
question
Does NOT reveal any entity names, answers, or intermediate numerical results Answer Extraction Guidance (for the reasoning process): {extraction_hints} - Final step: Apply the {fusion_operation} operation to obtain the final numerical answer. Output Format (JSON only): { "question": "A single continuous question ending with ’What is the result?’ in natura...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.