What LLMs explain is not what they believe: Evaluating explanation sufficiency under models' own input beliefs
Pith reviewed 2026-06-30 00:34 UTC · model grok-4.3
The pith
LLM explanations are generally insufficient when measured against the inputs the model itself believes would produce its output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
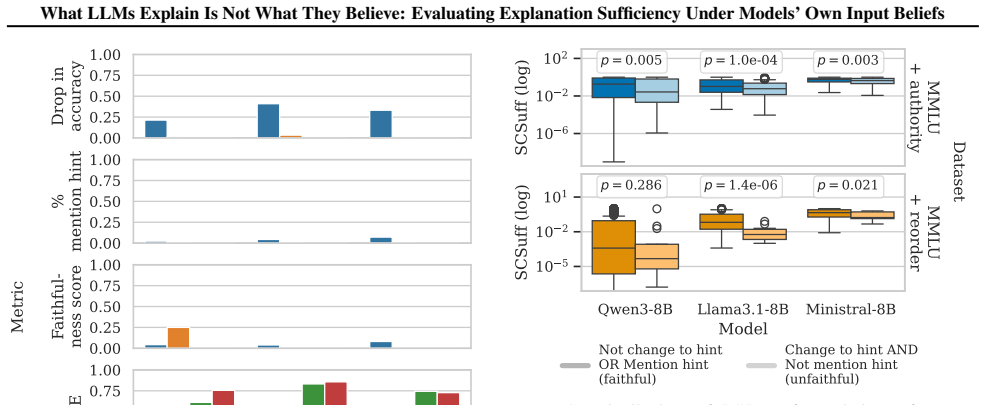
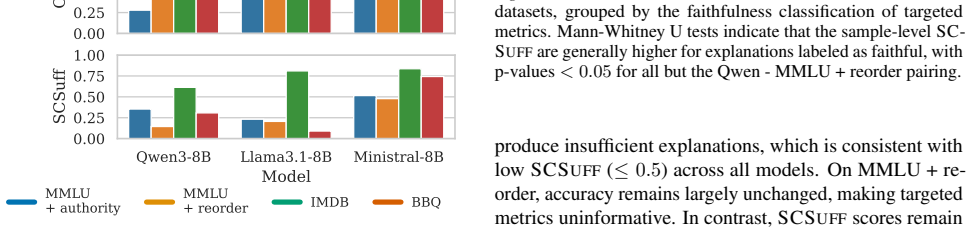
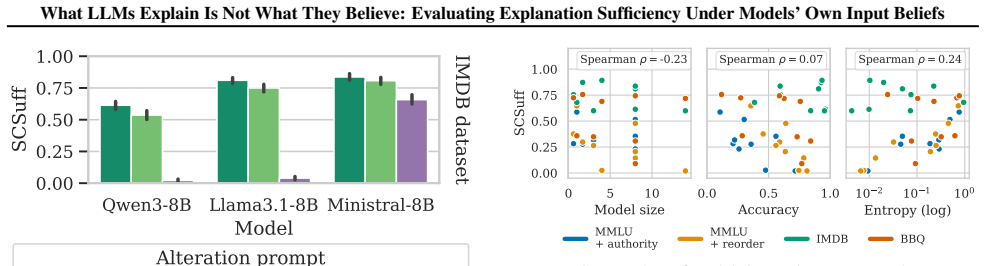
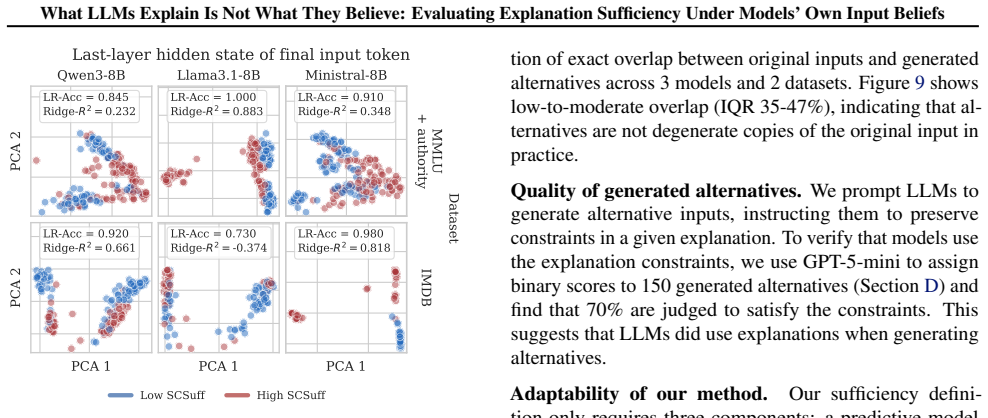
The paper establishes that free-text explanations from LLMs are generally insufficient under the input distribution implied by the model's own beliefs, as quantified by the new SCSuff metric; sufficiency varies with the chosen distribution, and internal representations predict top and bottom SCSuff scores.
What carries the argument
Self-consistent sufficiency (SCSuff), an information-theoretic metric that checks whether an explanation lets the LLM generate alternative inputs consistent with its beliefs about the original input-output pair.
If this is right
- Sufficiency of an explanation can increase or decrease when the input distribution changes.
- SCSuff scores show only weak correlation with model size, accuracy, or output entropy.
- Final-token hidden states contain enough signal to classify explanations as high or low SCSuff.
- SCSuff can serve as a guide for detecting insufficient explanations and for improving them.
Where Pith is reading between the lines
- If hidden states predict sufficiency, models could be trained to favor internal states that produce higher-SCSuff explanations.
- SCSuff might be computed on other sequence models to check whether their explanations remain consistent with their own generative beliefs.
- The dependence on input distribution implies that explanations sufficient under one task distribution may become insufficient under distribution shift.
Load-bearing premise
That the alternative inputs generated by the LLM conditioned on the explanation accurately capture the model's own beliefs about possible inputs that would produce the observed output.
What would settle it
A test in which the generated alternative inputs are fed back to the model and the original output is not recovered at rates predicted by SCSuff, or in which SCSuff fails to align with targeted perturbation tests on the same explanations.
Figures

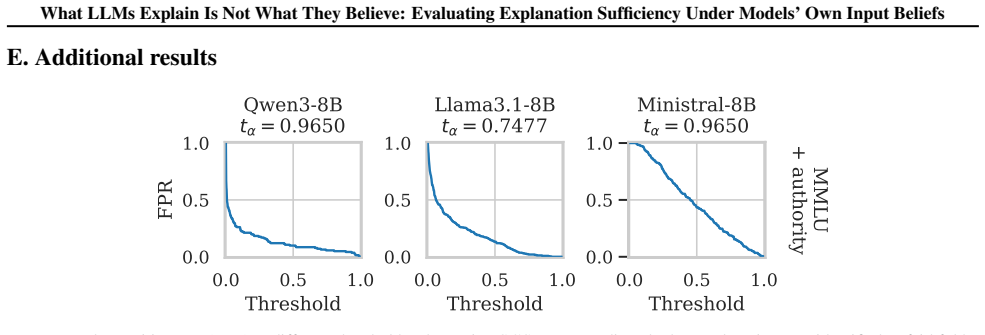
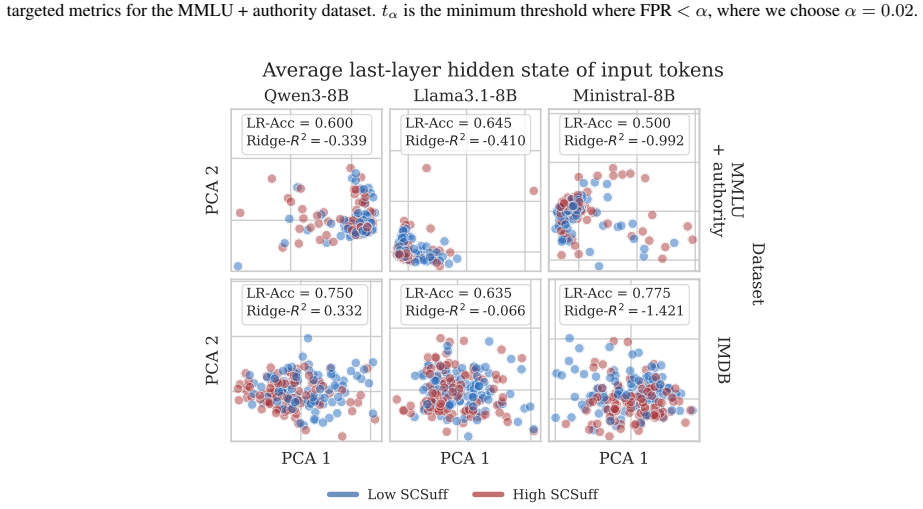
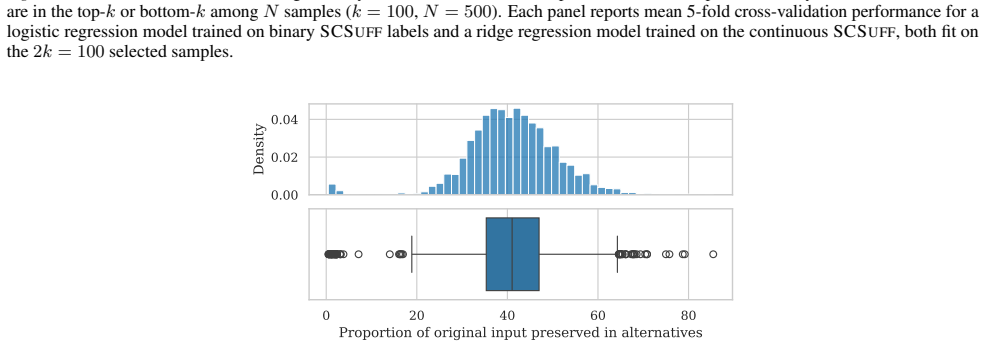
read the original abstract
Large language models (LLMs) are increasingly deployed in high-stakes domains, where free-text explanations such as chain-of-thought and post-hoc rationales are used to justify model outputs. Yet it remains unclear whether these explanations are sufficient, i.e., if they contain enough information to explain the model's output-generating process. We generalize classical sufficiency from feature attributions to arbitrary explanations and prove that explanation sufficiency can change depending on the input distribution, which must be explicitly defined for LLM explanations. We propose using the LLM itself to generate alternative inputs conditioned on an explanation, capturing its beliefs about possible inputs. We formalize self-consistent sufficiency as a goal for free-text explanations and introduce an information-theoretic metric, SCSuff, that enables evaluation of free-text explanations without relying on predefined biases or shortcuts. Our experiments show that SCSuff agrees with targeted perturbation tests where applicable and demonstrate that explanation sufficiency can vary with the input distribution. We find LLM explanations are generally insufficient and weakly correlated with model size, accuracy, or output entropy. Analysis of final-token hidden states shows that top and bottom SCSuff scores can be predicted from internal representations, suggesting that SCSuff can guide detection and improvement of sufficient LLM explanations. The code for this paper is available at https://github.com/rajesh-lab/self-consistent-sufficiency .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper generalizes classical feature-attribution sufficiency to free-text LLM explanations, proves that sufficiency is distribution-dependent and must be defined explicitly, introduces SCSuff as an information-theoretic metric that uses the LLM itself to generate alternative inputs conditioned on a given explanation (to capture the model's own beliefs), shows via experiments that SCSuff agrees with targeted perturbation tests, finds that LLM explanations are generally insufficient and only weakly correlated with model size/accuracy/output entropy, and demonstrates that top/bottom SCSuff scores are predictable from final-token hidden states. Code is released.
Significance. If the central results hold, the work supplies a principled, bias-avoiding framework for assessing whether free-text explanations (CoT, post-hoc rationales) actually reflect an LLM's input beliefs rather than post-hoc rationalization. The explicit proof that sufficiency varies with the input distribution, the reproducible code, and the link to internal representations are concrete strengths that could guide both evaluation and improvement of explanations.
major comments (2)
- [SCSuff definition and experimental setup] The definition of SCSuff (formalized after the proof that sufficiency depends on the input distribution) rests on the assumption that LLM-generated alternative inputs conditioned on the explanation faithfully sample the model's internal conditional distribution over inputs that would produce the observed output. No direct empirical validation of this assumption (e.g., comparing generated inputs against the model's own next-token or reconstruction behavior under identical conditioning) is described; this is load-bearing for the claim that SCSuff measures self-consistent rather than externally proxied sufficiency.
- [Experimental results and analysis of hidden states] The claim that explanations are 'generally insufficient' and only weakly correlated with model size, accuracy, or entropy is central, yet the abstract and high-level findings lack the detailed statistical reporting, data-exclusion rules, and per-model/per-task breakdowns needed to evaluate robustness; without these, it is difficult to assess whether the insufficiency result generalizes or is sensitive to generation hyperparameters.
minor comments (2)
- Clarify the exact prompting template and temperature settings used for generating the alternative inputs; small changes here could affect whether the generated distribution truly reflects the model's beliefs.
- The manuscript would benefit from an explicit limitations paragraph discussing prompt sensitivity and the computational cost of SCSuff evaluation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [SCSuff definition and experimental setup] The definition of SCSuff (formalized after the proof that sufficiency depends on the input distribution) rests on the assumption that LLM-generated alternative inputs conditioned on the explanation faithfully sample the model's internal conditional distribution over inputs that would produce the observed output. No direct empirical validation of this assumption (e.g., comparing generated inputs against the model's own next-token or reconstruction behavior under identical conditioning) is described; this is load-bearing for the claim that SCSuff measures self-consistent rather than externally proxied sufficiency.
Authors: We agree that the assumption regarding faithful sampling of the model's internal conditional distribution is central to interpreting SCSuff as self-consistent sufficiency, and that the manuscript does not include direct empirical validation (such as explicit comparisons to next-token or reconstruction behavior under the same conditioning). This is a valid observation. In the revision we will add a dedicated analysis subsection that provides supporting evidence for the assumption, including comparisons of generated alternative inputs against the model's conditional token probabilities and perplexity measures when the explanation is provided as context. We note that exhaustive validation remains challenging due to the intractability of the full input distribution, but the added experiments will strengthen the claim. revision: yes
-
Referee: [Experimental results and analysis of hidden states] The claim that explanations are 'generally insufficient' and only weakly correlated with model size, accuracy, or entropy is central, yet the abstract and high-level findings lack the detailed statistical reporting, data-exclusion rules, and per-model/per-task breakdowns needed to evaluate robustness; without these, it is difficult to assess whether the insufficiency result generalizes or is sensitive to generation hyperparameters.
Authors: We acknowledge that the current results section presents primarily aggregate findings without sufficient granular statistical details, explicit data-exclusion criteria, or per-model/per-task breakdowns, which limits assessment of robustness and sensitivity to hyperparameters. This point is correct. We will revise the experimental results and analysis sections to include expanded tables and figures with per-model and per-task means, standard deviations, confidence intervals, and explicit rules for data exclusion (e.g., filtering invalid or low-quality generations). These additions will allow clearer evaluation of whether the insufficiency and weak correlation results hold across settings. revision: yes
Circularity Check
No circularity: SCSuff is an explicit design choice to operationalize self-consistent sufficiency
full rationale
The paper defines SCSuff explicitly as an information-theoretic metric that uses LLM-generated alternative inputs (conditioned on the explanation) to represent the model's own beliefs about input distributions. This is presented as a deliberate methodological decision to capture 'self-consistent sufficiency' rather than any fitted parameter, self-referential definition, or reduction of a result to its inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes smuggled via citation are present in the provided text. The central empirical claims (explanations generally insufficient, weak correlations with size/accuracy/entropy, hidden-state predictability) follow from applying this defined metric to experiments and are not forced by the definition itself. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
, author=
Have we learned to explain?: How interpretability methods can learn to encode predictions in their interpretations. , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
2021
-
[2]
and Daly, Raymond E
Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher , title =. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , month =. 2011 , address =
2011
-
[3]
T ruthful QA : Measuring How Models Mimic Human Falsehoods
Lin, Stephanie and Hilton, Jacob and Evans, Owain. T ruthful QA : Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.229
-
[4]
Deployable Generative AI, ICML , year=
Chain-of-thought hub: A continuous effort to measure large language models' reasoning performance , author=. Deployable Generative AI, ICML , year=
-
[5]
CoRR , year=
Language Models (Mostly) Know What They Know , author=. CoRR , year=
-
[6]
arXiv preprint arXiv:2404.04475 , year=
Length-controlled alpacaeval: A simple way to debias automatic evaluators , author=. arXiv preprint arXiv:2404.04475 , year=
-
[7]
Weld and Luke Zettlemoyer , year = 2017, booktitle =
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[8]
Lin, Yen-Ting and Chen, Yun-Nung. LLM -Eval: Unified Multi-Dimensional Automatic Evaluation for Open-Domain Conversations with Large Language Models. Proceedings of the 5th Workshop on NLP for Conversational AI (NLP4ConvAI 2023). 2023. doi:10.18653/v1/2023.nlp4convai-1.5
-
[9]
Faithfulness Tests for Natural Language Explanations
Pepa Atanasova and Oana-Maria Camburu and Christina Lioma and Thomas Lukasiewicz and Jakob Grue Simonsen and Isabelle Augenstein. Faithfulness Tests for Natural Language Explanations. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics‚ ACL 2023‚ Toronto, Canada, July 9--14‚ 2023. 2023
2023
-
[10]
2020 , eprint=
WT5?! Training Text-to-Text Models to Explain their Predictions , author=. 2020 , eprint=
2020
-
[11]
Advances in Neural Information Processing Systems , volume=
e-snli: Natural language inference with natural language explanations , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Explain Yourself! Leveraging Language Models for Commonsense Reasoning
Rajani, Nazneen Fatema and McCann, Bryan and Xiong, Caiming and Socher, Richard. Explain Yourself! Leveraging Language Models for Commonsense Reasoning. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1487
-
[13]
S em E val-2020 Task 4: Commonsense Validation and Explanation
Wang, Cunxiang and Liang, Shuailong and Jin, Yili and Wang, Yilong and Zhu, Xiaodan and Zhang, Yue. S em E val-2020 Task 4: Commonsense Validation and Explanation. Proceedings of the Fourteenth Workshop on Semantic Evaluation. 2020. doi:10.18653/v1/2020.semeval-1.39
-
[14]
NILE : Natural Language Inference with Faithful Natural Language Explanations
Kumar, Sawan and Talukdar, Partha. NILE : Natural Language Inference with Faithful Natural Language Explanations. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.771
-
[15]
Neural Information Processing Systems , year=
Knowledge-Grounded Self-Rationalization via Extractive and Natural Language Explanations , author=. Neural Information Processing Systems , year=
-
[16]
Towards Explainable NLP : A Generative Explanation Framework for Text Classification
Liu, Hui and Yin, Qingyu and Wang, William Yang. Towards Explainable NLP : A Generative Explanation Framework for Text Classification. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1560
-
[17]
Proceedings of the 14th ACM international conference on web search and data mining , pages=
Explain and predict, and then predict again , author=. Proceedings of the 14th ACM international conference on web search and data mining , pages=
-
[18]
Nature Machine Intelligence , volume=
Explaining machine learning models with interactive natural language conversations using TalkToModel , author=. Nature Machine Intelligence , volume=. 2023 , publisher=
2023
-
[19]
arXiv preprint arXiv:2310.11207 , year=
Can large language models explain themselves? a study of llm-generated self-explanations , author=. arXiv preprint arXiv:2310.11207 , year=
-
[20]
Ferrando, Javier and G \'a llego, Gerard I. and Costa-juss \`a , Marta R. Measuring the Mixing of Contextual Information in the Transformer. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.595
-
[21]
International Conference on Artificial Intelligence and Statistics , pages=
Don’t be fooled: label leakage in explanation methods and the importance of their quantitative evaluation , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
2023
-
[22]
BMC Medical Informatics and Decision Making , volume=
From algorithms to action: improving patient care requires causality , author=. BMC Medical Informatics and Decision Making , volume=. 2024 , publisher=
2024
-
[23]
Journal of the American Medical Informatics Association , volume=
AI as an intervention: improving clinical outcomes relies on a causal approach to AI development and validation , author=. Journal of the American Medical Informatics Association , volume=. 2025 , publisher=
2025
-
[24]
International conference on learning representations , year=
Fastshap: Real-time shapley value estimation , author=. International conference on learning representations , year=
-
[25]
I ncorporating R esidual and N ormalization L ayers into A nalysis of M asked L anguage M odels
Kobayashi, Goro and Kuribayashi, Tatsuki and Yokoi, Sho and Inui, Kentaro. I ncorporating R esidual and N ormalization L ayers into A nalysis of M asked L anguage M odels. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.373
-
[26]
Proceedings of the AAAI conference on artificial intelligence , volume=
Hatexplain: A benchmark dataset for explainable hate speech detection , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[27]
D ecomp X : Explaining Transformers Decisions by Propagating Token Decomposition
Modarressi, Ali and Fayyaz, Mohsen and Aghazadeh, Ehsan and Yaghoobzadeh, Yadollah and Pilehvar, Mohammad Taher. D ecomp X : Explaining Transformers Decisions by Propagating Token Decomposition. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.149
-
[28]
Modarressi, Ali and Fayyaz, Mohsen and Yaghoobzadeh, Yadollah and Pilehvar, Mohammad Taher. G lob E nc: Quantifying Global Token Attribution by Incorporating the Whole Encoder Layer in Transformers. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.1...
-
[29]
SQ u AD : 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQ u AD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264
-
[30]
BLEURT : Learning Robust Metrics for Text Generation
Sellam, Thibault and Das, Dipanjan and Parikh, Ankur. BLEURT : Learning Robust Metrics for Text Generation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.704
-
[31]
and Ng, Andrew and Potts, Christopher
Socher, Richard and Perelygin, Alex and Wu, Jean and Chuang, Jason and Manning, Christopher D. and Ng, Andrew and Potts, Christopher. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013
2013
-
[32]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[33]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference
Williams, Adina and Nangia, Nikita and Bowman, Samuel. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1101
work page internal anchor Pith review doi:10.18653/v1/n18-1101 2018
-
[34]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
Gao, Tianyu and Yen, Howard and Yu, Jiatong and Chen, Danqi. Enabling Large Language Models to Generate Text with Citations. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.398
-
[35]
China Conference on Information Retrieval , pages=
On the Capacity of Citation Generation by Large Language Models , author=. China Conference on Information Retrieval , pages=. 2024 , organization=
2024
-
[36]
L earning to Faithfully Rationalize by Construction
Jain, Sarthak and Wiegreffe, Sarah and Pinter, Yuval and Wallace, Byron C. L earning to Faithfully Rationalize by Construction. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.409
-
[37]
Advances in Neural Information Processing Systems , volume=
Contextcite: Attributing model generation to context , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
2019 ,journal =
Natural Questions: a Benchmark for Question Answering Research ,author =. 2019 ,journal =
2019
-
[39]
Proceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining , pages=
WebGLM: towards an efficient web-enhanced question answering system with human preferences , author=. Proceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[40]
arXiv preprint arXiv:2409.02897 , year=
Longcite: Enabling llms to generate fine-grained citations in long-context qa , author=. arXiv preprint arXiv:2409.02897 , year=
-
[41]
arXiv preprint arXiv:2310.18512 , year=
Preventing language models from hiding their reasoning , author=. arXiv preprint arXiv:2310.18512 , year=
-
[42]
Advances in Neural Information Processing Systems , volume=
Explanations that reveal all through the definition of encoding , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
arXiv preprint arXiv:2402.02315 , year=
A survey of large language models in finance (finllms) , author=. arXiv preprint arXiv:2402.02315 , year=
-
[44]
plausibility: On the (un) reliability of explanations from large language models , author=
Faithfulness vs. plausibility: On the (un) reliability of explanations from large language models , author=. arXiv preprint arXiv:2402.04614 , year=
-
[45]
AI Open , volume=
Large language models in law: A survey , author=. AI Open , volume=. 2024 , publisher=
2024
-
[46]
ArXiv , pages=
Language models are capable of metacognitive monitoring and control of their internal activations , author=. ArXiv , pages=
-
[47]
Annual Review of Psychology , volume=
Metacognition and confidence: A review and synthesis , author=. Annual Review of Psychology , volume=. 2024 , publisher=
2024
-
[48]
npj Artificial Intelligence , volume=
Exploring the role of large language models in the scientific method: from hypothesis to discovery , author=. npj Artificial Intelligence , volume=. 2025 , publisher=
2025
-
[49]
Iscience , volume=
The application of large language models in medicine: A scoping review , author=. Iscience , volume=. 2024 , publisher=
2024
-
[50]
Advances in Neural Information Processing Systems , volume=
Simple and effective masked diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
arXiv preprint arXiv:2307.13702 , year=
Measuring faithfulness in chain-of-thought reasoning , author=. arXiv preprint arXiv:2307.13702 , year=
-
[52]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[53]
arXiv preprint arXiv:2410.14155 , year=
Towards Faithful Natural Language Explanations: A Study Using Activation Patching in Large Language Models , author=. arXiv preprint arXiv:2410.14155 , year=
-
[54]
ERASER : A Benchmark to Evaluate Rationalized NLP Models
DeYoung, Jay and Jain, Sarthak and Rajani, Nazneen Fatema and Lehman, Eric and Xiong, Caiming and Socher, Richard and Wallace, Byron C. ERASER : A Benchmark to Evaluate Rationalized NLP Models. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.408
-
[55]
arXiv preprint arXiv:2010.12762 , year=
Measuring association between labels and free-text rationales , author=. arXiv preprint arXiv:2010.12762 , year=
arXiv 2010
-
[56]
Faithfulness Tests for Natural Language Explanations
Atanasova, Pepa and Camburu, Oana-Maria and Lioma, Christina and Lukasiewicz, Thomas and Simonsen, Jakob Grue and Augenstein, Isabelle. Faithfulness Tests for Natural Language Explanations. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023. doi:10.18653/v1/2023.acl-short.25
-
[57]
On Measuring Faithfulness or Self-consistency of Natural Language Explanations
Parcalabescu, Letitia and Frank, Anette. On Measuring Faithfulness or Self-consistency of Natural Language Explanations. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.329
-
[58]
arXiv preprint arXiv:2308.14272 , year=
Goodhart's Law Applies to NLP's Explanation Benchmarks , author=. arXiv preprint arXiv:2308.14272 , year=
-
[59]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[60]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[61]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Graph of thoughts: Solving elaborate problems with large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[62]
arXiv preprint arXiv:2502.18600 , year=
Chain of draft: Thinking faster by writing less , author=. arXiv preprint arXiv:2502.18600 , year=
-
[63]
arXiv preprint arXiv:2412.16720 , year=
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
-
[64]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
Reasoning Models Don’t Always Say What They Think , author=
-
[66]
A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
Jacovi, Alon and Bitton, Yonatan and Bohnet, Bernd and Herzig, Jonathan and Honovich, Or and Tseng, Michael and Collins, Michael and Aharoni, Roee and Geva, Mor. A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume...
-
[67]
R e CE val: Evaluating Reasoning Chains via Correctness and Informativeness
Prasad, Archiki and Saha, Swarnadeep and Zhou, Xiang and Bansal, Mohit. R e CE val: Evaluating Reasoning Chains via Correctness and Informativeness. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.622
-
[68]
arXiv preprint arXiv:2503.03750 , year=
The MASK Benchmark: Disentangling Honesty From Accuracy in AI Systems , author=. arXiv preprint arXiv:2503.03750 , year=
-
[69]
arXiv preprint arXiv:2502.09992 , year=
Large language diffusion models , author=. arXiv preprint arXiv:2502.09992 , year=
-
[70]
NAACL , year =
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions , author =. NAACL , year =
-
[71]
Proceedings of North American Chapter of the Association for Computational Linguistics (NAACL) , year =
Daniel Khashabi and Snigdha Chaturvedi and Michael Roth and Shyam Upadhyay and Dan Roth , title =. Proceedings of North American Chapter of the Association for Computational Linguistics (NAACL) , year =
-
[72]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
-
[73]
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. arXiv:1803.05457v1 , year =
-
[74]
ACL , year=
Program induction by rationale generation: Learning to solve and explain algebraic word problems , author=. ACL , year=
-
[75]
PubMedQA: A Dataset for Biomedical Research Question Answering , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages=
2019
-
[76]
proceedings of the Conference on Fairness, Accountability, and Transparency , pages=
Bias in bios: A case study of semantic representation bias in a high-stakes setting , author=. proceedings of the Conference on Fairness, Accountability, and Transparency , pages=
-
[77]
CoRR , volume=
Guangsheng Bao and Hongbo Zhang and Linyi Yang and Cunxiang Wang and Yue Zhang , title=. CoRR , volume=. 2024 , cdate=
2024
-
[78]
International conference on learning representations , year=
INVASE: Instance-wise variable selection using neural networks , author=. International conference on learning representations , year=
-
[79]
Advances in Neural Information Processing Systems , volume=
Honestllm: Toward an honest and helpful large language model , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.