Distribution-based deep multiple instance learning for tumor proportion scoring in NSCLC
Pith reviewed 2026-06-29 01:31 UTC · model grok-4.3
The pith
A zero-inflated beta distribution model in multiple instance learning predicts tumor proportion scores more accurately than regression methods from slide-level labels alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training a distribution-based MIL architecture to predict the parameters of a zero-inflated beta distribution representing TPS, the model achieves higher accuracy than baseline regressions while providing explainability through the concentration of the estimated distribution, all without requiring patch-level annotations.
What carries the argument
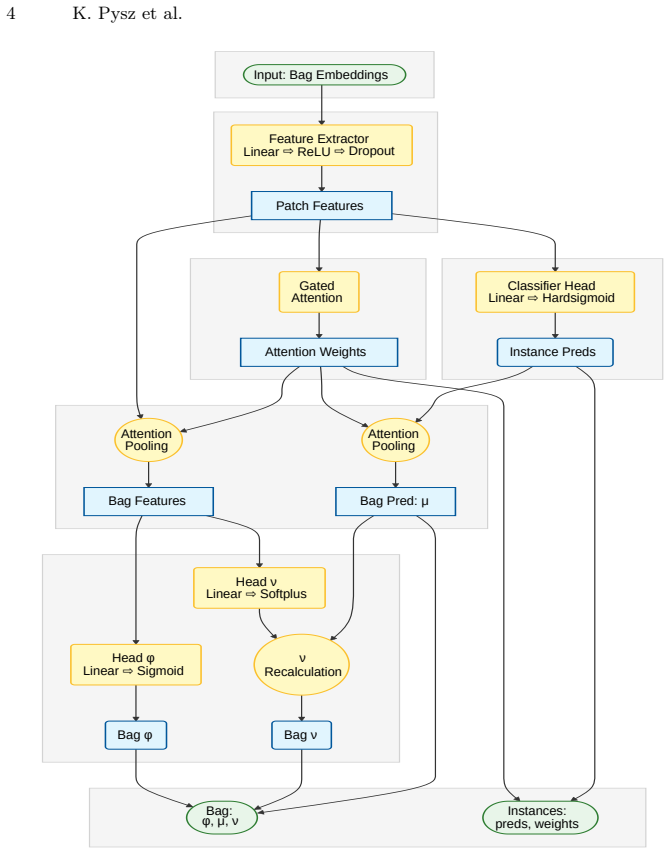
The MIL aggregation that outputs parameters of the zero-inflated beta distribution for TPS, which allows the model to represent the probability distribution over possible tumor proportions for a slide.
If this is right
- Outperforms linear and ridge regression in prediction accuracy for TPS.
- Handles non-expressive zero-class images better due to the zero-inflated component.
- Captures expected accuracy through the concentration of the predicted distribution.
- Provides improved explainability compared to point-estimate regression methods.
- Enables training with only slide-level labels in an end-to-end manner.
Where Pith is reading between the lines
- The distribution modeling could be applied to other quantitative scoring tasks in digital pathology where proportions are estimated.
- Uncertainty in TPS predictions could be derived from the variance of the ZIBeta distribution for clinical decision support.
- Reducing reliance on patch-level annotations might accelerate development of similar models for other cancer types.
- Integration with existing pathology workflows could decrease the time experts spend on manual scoring.
Load-bearing premise
That tumor proportion scores follow a zero-inflated beta distribution and that aggregating patch embeddings via MIL can reliably estimate the distribution parameters without patch-level supervision.
What would settle it
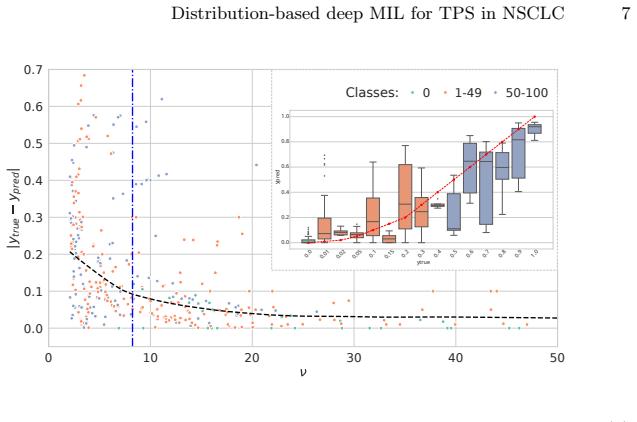
If on an independent test set the ZIBeta-based model does not show lower error metrics than the ridge regression baseline, or if the distribution concentration does not correlate with prediction accuracy as expected, the performance advantage would be falsified.
Figures
read the original abstract
Accurate assessment of tumor proportion score (TPS) in non-small cell lung cancer (NSCLC) is critical for treatment planning and prognosis. Key challenges include the tedious manual work required to annotate each slide, combined with the limited number of experts certified for this task. Multiple instance learning (MIL) has proven to be an effective approach for predicting TPS scores at the slide level; however, existing methods struggle with non-expressive (zero class) images. Our approach involves two models: (1) an embedding-extraction and multiclass-classification network that captures the histopathological features of individual patches, and (2) a MIL model that aggregates these embeddings to predict zero-inflated beta (ZIBeta) parameters representing the overall TPS probability distribution for the entire slide. Using only slide-level TPS scores as labels, we demonstrate how this end-to-end framework can leverage a novel distribution-based architecture to improve prediction accuracy and explainability. ZIBeta modeling significantly outperforms baseline linear and ridge regression while capturing expected accuracy through distribution concentration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an end-to-end distribution-based multiple instance learning (MIL) framework for tumor proportion score (TPS) prediction in NSCLC pathology slides. It consists of a patch embedding and multiclass classification network followed by a MIL aggregator that predicts the four parameters of a zero-inflated beta (ZIBeta) distribution to model slide-level TPS. Using only slide-level TPS labels, the authors claim that ZIBeta modeling significantly outperforms linear and ridge regression baselines in accuracy while improving explainability through distribution concentration.
Significance. If the central results hold, the work would demonstrate a practical way to move from point-estimate MIL to full distributional modeling in weakly supervised computational pathology, which is relevant for zero-inflated proportion data like TPS. The explicit use of a parametric distribution for aggregation is a clear methodological contribution that could aid interpretability.
major comments (2)
- [Method (ZIBeta MIL aggregator)] Method section describing the MIL aggregator and ZIBeta parameter prediction: the central claim that the four ZIBeta parameters can be recovered from patch embeddings using only a scalar slide-level TPS target (the mean of the distribution) lacks justification for identifiability. Multiple distinct (π, α, β) combinations can produce identical expected values, so the learned parameters may not correspond to the underlying patch distribution even when the mean matches the label.
- [Experiments] Experimental results section: the abstract states outperformance over linear and ridge regression baselines, but the manuscript must provide concrete details on datasets, cross-validation procedure, exact metrics (e.g., MAE, calibration of the full distribution), and statistical significance tests to support the claim that the distributional model improves accuracy beyond mean matching.
minor comments (2)
- [Abstract] The abstract should include at least one sentence on the datasets used and the primary evaluation metric to allow readers to assess the scope of the claimed improvement.
- [Method] Notation for the ZIBeta parameters (zero-inflation probability and shape parameters) should be defined explicitly when first introduced, and the loss function used to train the parameter predictor should be stated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point by point below. We will revise the manuscript to incorporate clarifications and additional details where appropriate.
read point-by-point responses
-
Referee: [Method (ZIBeta MIL aggregator)] Method section describing the MIL aggregator and ZIBeta parameter prediction: the central claim that the four ZIBeta parameters can be recovered from patch embeddings using only a scalar slide-level TPS target (the mean of the distribution) lacks justification for identifiability. Multiple distinct (π, α, β) combinations can produce identical expected values, so the learned parameters may not correspond to the underlying patch distribution even when the mean matches the label.
Authors: We agree that identifiability is a valid concern. The supervision signal is the slide-level mean TPS, so the loss primarily constrains the expected value of the predicted ZIBeta distribution; multiple parameter combinations can yield the same mean. The end-to-end architecture uses patch embeddings to inform the parameter predictions, but this does not guarantee unique recovery of all four parameters. We will revise the method section to explicitly acknowledge this limitation, clarify that the model is not claimed to recover the exact underlying patch distribution, and emphasize that the value lies in improved mean accuracy plus distributional outputs for explainability. We will also add a brief discussion of this point. revision: partial
-
Referee: [Experiments] Experimental results section: the abstract states outperformance over linear and ridge regression baselines, but the manuscript must provide concrete details on datasets, cross-validation procedure, exact metrics (e.g., MAE, calibration of the full distribution), and statistical significance tests to support the claim that the distributional model improves accuracy beyond mean matching.
Authors: We agree that the experimental section requires more concrete details to support the claims. In the revision we will expand the experiments section to specify the datasets (number of slides, sources, and preprocessing), the cross-validation procedure, the exact evaluation metrics (including MAE for the mean and any distribution calibration measures), and the statistical significance tests performed. These additions will allow readers to assess whether the ZIBeta model provides benefits beyond mean matching. revision: yes
Circularity Check
No significant circularity; derivation relies on standard MIL and external baselines
full rationale
The paper describes an end-to-end MIL architecture that aggregates patch embeddings to predict ZIBeta distribution parameters using only slide-level TPS labels, then compares performance against linear and ridge regression baselines. No quoted equations, self-citations, or steps reduce the central claim to a fitted input renamed as prediction, a self-definitional loop, or a load-bearing uniqueness theorem imported from the authors' prior work. The modeling assumptions (ZIBeta form and MIL aggregation) are stated explicitly as modeling choices rather than derived by construction from the target outputs, leaving the derivation self-contained against the provided external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scientific Reports14(1), 7136 (Mar 2024)
van Eekelen, L., Spronck, J., Looijen-Salamon, M., Vos, S., Munari, E., Giro- lami, I., Eccher, A., Acs, B., Boyaci, C., de Souza, G.S., Demirel-Andishmand, M., Meesters, L.D., Zegers, D., van der Woude, L., Theelen, W., van den Heuvel, M., Grünberg, K., van Ginneken, B., van der Laak, J., Ciompi, F.: Comparing deep learning and pathologist quantification...
-
[2]
Journal for ImmunoTherapy of Cancer10(5), e003956 (5 2022)
Govindan, R., Aggarwal, C., Antonia, S.J., Davies, M., Dubinett, S.M., Fer- ris, A., Forde, P.M., Garon, E.B., Goldberg, S.B., Hassan, R., Hellmann, M.D., Hirsch, F.R., Johnson, M.L., Malik, S., Morgensztern, D., Neal, J.W., Patel, J.D., Rimm, D.L., Sagorsky, S., Schwartz, L.H., Sepesi, B., Herbst, R.S.: Society for immunotherapy of cancer (sitc) clinical...
-
[3]
Histopathology80(4), 635–647 (Nov 2021)
Hondelink, L.M., Huyuk, M., Postmus, P.E., Smit, V.T.H.B.M., Blom, S., von der Thusen, J.H., Cohen, D.: Development and validation of a supervised deep learning algorithm for automated wholeslide programmed deathligand 1 tumour proportion score assessment in nonsmall cell lung cancer. Histopathology80(4), 635–647 (Nov 2021). https://doi.org/10.1111/his.14...
-
[4]
Howard, A., Sandler, M., Chu, G., Chen, L.C., Chen, B., Tan, M., Wang, W., Zhu, Y., Pang, R., Vasudevan, V., Le, Q.V., Adam, H.: Searching for MobileNetV3. arXiv (May 2019). https://doi.org/10.48550/arXiv.1905.02244
-
[5]
Attention-based Deep Multiple Instance Learning
Ilse, M., Tomczak, J.M., Welling, M.: Attention-based Deep Multiple Instance Learning. arXiv (Feb 2018). https://doi.org/10.48550/arXiv.1802.04712
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.04712 2018
-
[6]
JCO Precision Oncology (May 2024), https://ascopubs.org/doi/10.1200/PO.23.00556 10 K
Kim, H., Kim, S., Choi, S., Park, C., Park, S., Pereira, S., Ma, M., Yoo, D., Paeng, K., Jung, W., Park, S., Ock, C.Y., Lee, S.H., Choi, Y.L., Chung, J.H.: Clinical Validation of Artificial Intelligence–Powered PD-L1 Tumor Pro- portion Score Interpretation for Immune Checkpoint Inhibitor Response Pre- diction in Non–Small Cell Lung Cancer. JCO Precision O...
-
[7]
Scientific Reports11(1), 15907 (Aug 2021)
Liu, J., Zheng, Q., Mu, X., Zuo, Y., Xu, B., Jin, Y., Wang, Y., Tian, H., Yang, Y., Xue, Q., Huang, Z., Chen, L., Gu, B., Hou, X., Shen, L., Guo, Y., Li, Y.: Automated tumor proportion score analysis for PD-L1 (22C3) expres- sion in lung squamous cell carcinoma. Scientific Reports11(1), 15907 (Aug 2021). https://doi.org/10.1038/s41598-021-95372-1, publish...
- [8]
-
[9]
appendix b.6
MinistryofHealth,RepublicofPoland:Refundationnoticeno.81(1january2026). appendix b.6. treatment of patients with lung cancer (icd-10: C34) and pleural mesothelioma (icd-10:c45). https://www.gov.pl/attachment/af3ac669-45c2-4875- 9822-e89e9f6612ce (2025), accessed: 2026-01-08
2025
-
[10]
Journal of Translational Medicine19(1) (Jun 2021)
Pan, B., Kang, Y., Jin, Y., Yang, L., Zheng, Y., Cui, L., Sun, J., Feng, J., Li, Y., Guo, L., Liang, Z.: Automated tumor proportion scoring for PD-L1 expres- sion based on multistage ensemble strategy in non-small cell lung cancer. Journal of Translational Medicine19(1) (Jun 2021). https://doi.org/10.1186/s12967-021- 02898-z, publisher: Springer Science a...
-
[11]
Histopathology87(1), 90–100 (2025)
Plass, M., Olteanu, G.E., Dacic, S., Kern, I., Zacharias, M., Popper, H., Fukuoka, J., Ishijima, S., Kargl, M., Murauer, C., Kalson, L., Brcic, L.: Comparative perfor- mance of pd-l1 scoring by pathologists and ai algorithms. Histopathology87(1), 90–100 (2025). https://doi.org/10.1111/his.15432
-
[12]
Archives of Pathology & Laboratory Medicine148(7), 757–774 (Jul 2024)
Sholl, L.M., Awad, M., Roy, U.B., Beasley, M.B., Cartun, R.W., Hwang, D.M., Kalemkerian,G.,Lopez-Rios,F.,Mino-Kenudson,M.,Paintal,A.,Reid,K.,Ritter- house, L., Souter, L.A., Swanson, P.E., Ventura, C.B., Furtado, L.V.: Programmed death ligand-1 and tumor mutation burden testing of patients with lung cancer for selection of immune checkpoint inhibitor ther...
-
[13]
Wang, R., Qiu, Y., Wang, T., Wang, M., Jin, S., Cong, F., Zhang, Y., Xu, H.: MIHIC: a multiplex IHC histopathological image classification dataset for lung cancer immune microenvironment quantification. Frontiers in Immunology15(Feb 2024). https://doi.org/10.3389/fimmu.2024.1334348, publisher: Frontiers
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.