DIRECT: When and Where Should You Allocate Test-Time Compute in Embodied Planners?
Pith reviewed 2026-06-27 09:40 UTC · model grok-4.3
The pith
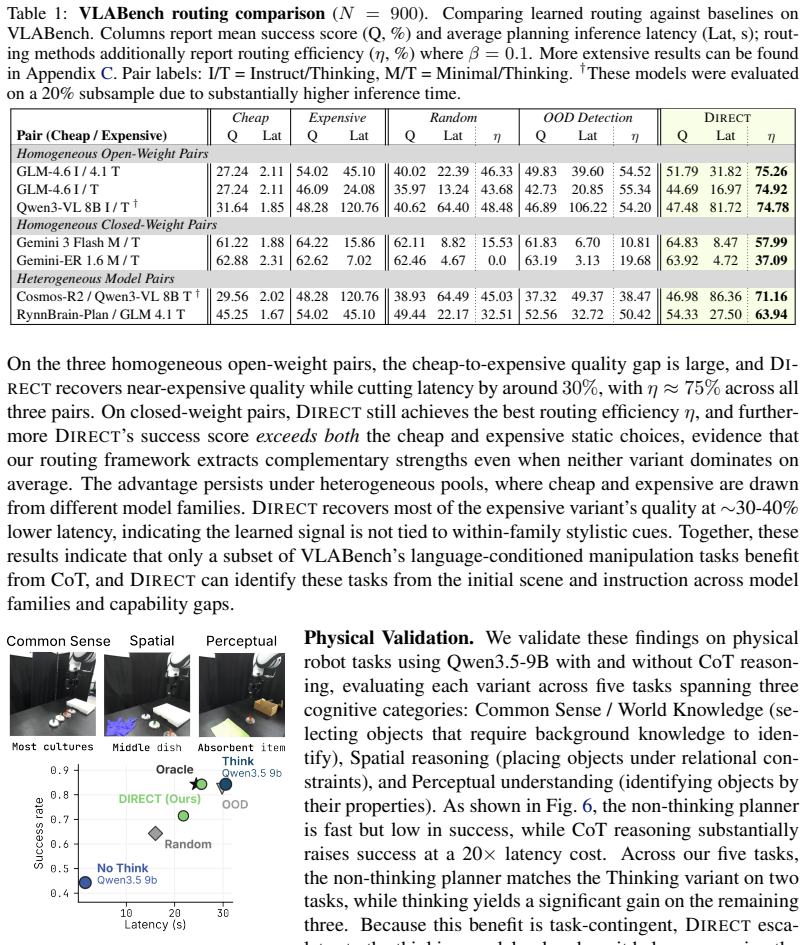
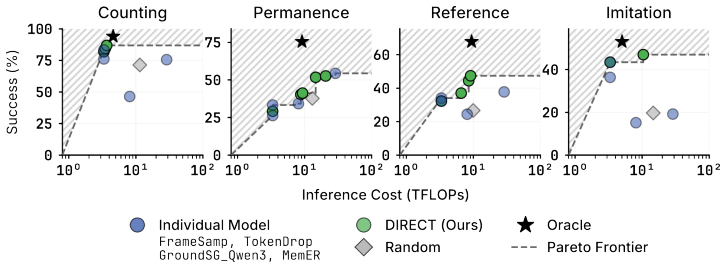
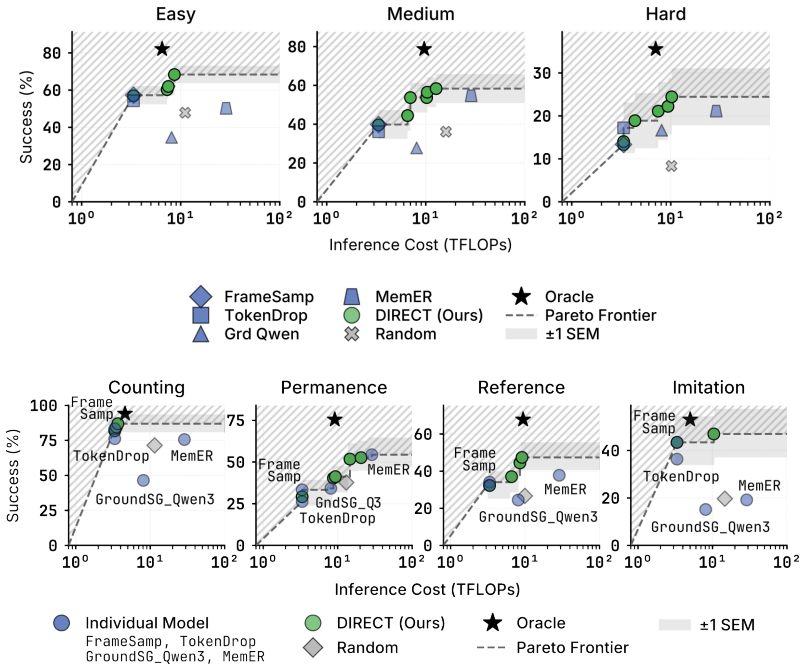
DIRECT routes VLM compute per prompt using scene context to match strong models at up to 65 percent lower latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
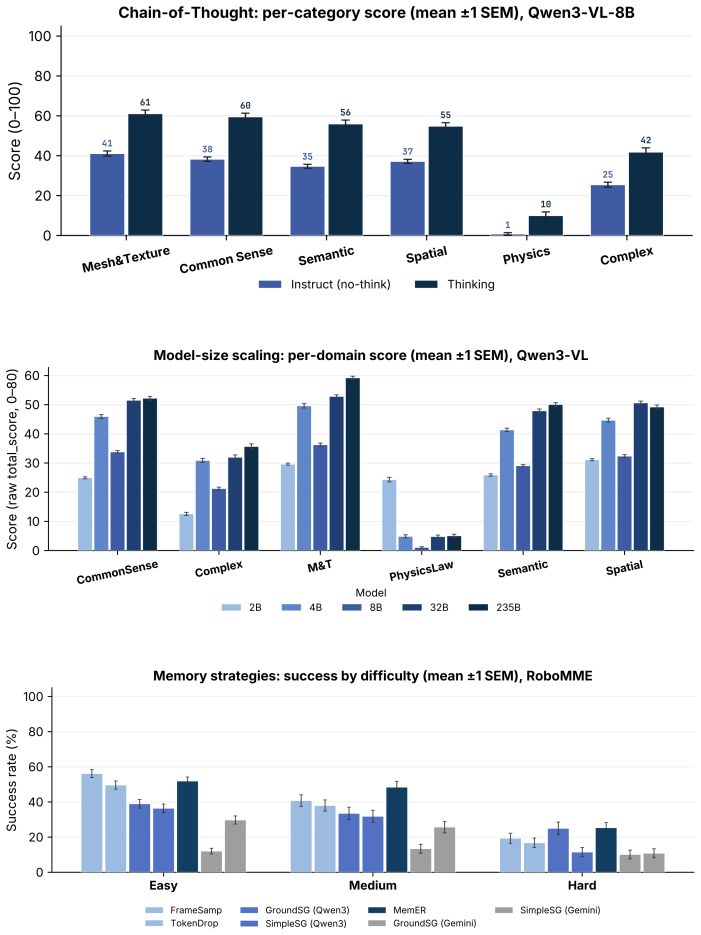
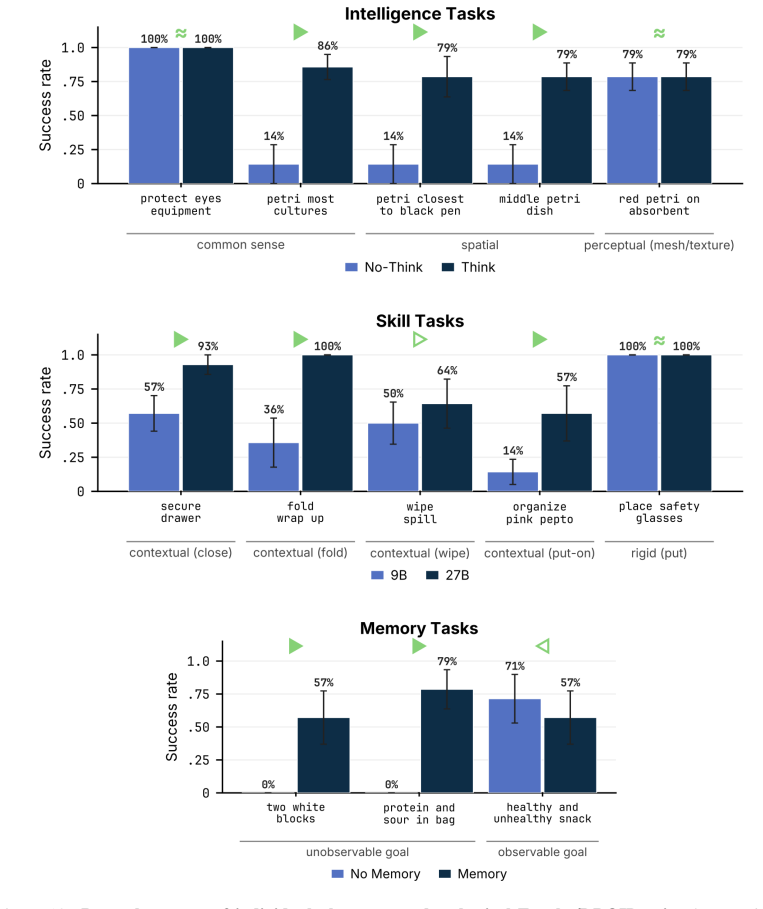
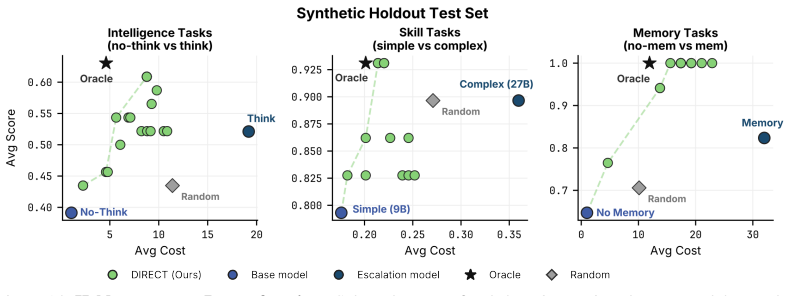
DIRECT uses multimodal scene context to allocate compute per prompt across the three axes of chain-of-thought depth, model size, and memory history, improving the success-cost Pareto frontier over any fixed model choice and delivering comparable or higher task success at up to 65 percent lower average latency on VLABench, RoboMME, and physical Franka arm experiments.
What carries the argument
The DIRECT router, which predicts the best compute allocation axis and quantity from multimodal scene context to select among scaling options for each prompt.
If this is right
- Uniform scaling of test-time compute wastes resources because gains differ qualitatively across axes.
- Scene-context routing can deliver frontier-level performance on physical robots without always running the largest model or deepest reasoning.
- Allocations must be decided per prompt rather than once for an entire task or agent.
- Zero-shot manipulation and long-horizon chaining both benefit when the router selects the right axis for each step.
- The same routing logic applies across simulation and real hardware without retraining the underlying VLMs.
Where Pith is reading between the lines
- Routers of this form could be applied to non-embodied VLM tasks where latency and cost also matter.
- Additional axes such as tool use or external search might be added to the router's decision space.
- The approach implies that energy use in deployed robots can be reduced by avoiding unnecessary compute on easy scenes.
- Scene features that predict task difficulty could be isolated and used to train lighter routing models.
Load-bearing premise
Multimodal scene context supplies enough information to choose the optimal allocation axis and amount without routing mistakes that erase the latency savings.
What would settle it
A held-out set of scenes where the router's chosen allocations produce both lower success rates and higher average latency than the single best fixed model.
Figures






read the original abstract
Vision-Language Models (VLMs) are increasingly deployed as high-level planners for embodied agents, with an emerging strategy of scaling test-time compute to improve capability. However, we observe that doing so increases latency, token usage, and FLOPs while yielding uneven, often diminishing gains in downstream success, limiting where embodied agents can be deployed. We argue that choosing when and where to spend test-time compute is central to bringing frontier performance to the real world. We introduce DIRECT, a routing framework that uses multimodal scene context to allocate compute per prompt, improving the success--cost Pareto frontier over fixed model selection. Across three dominant scaling axes, namely chain-of-thought depth, model size, and memory history, our experiments on VLABench and RoboMME show that test-time compute is not a uniform lever: different axes yield qualitatively distinct capability gains. We validate these insights on a physical Franka arm in a DROID setup spanning zero-shot manipulation and long-horizon chaining, where our router matches or exceeds a stronger model's success rate at up to 65% lower average latency. Ultimately, our results show that naively scaling test-time compute is wasteful, and that DIRECT can provide frontier-level embodied planning in robotic systems at a fraction of the cost. Project page can be found at jadee-dao.github.io/direct/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that naively scaling test-time compute for VLM-based embodied planners leads to uneven gains and higher costs, and introduces DIRECT, a routing framework that uses multimodal scene context to allocate compute per prompt across three axes (chain-of-thought depth, model size, memory history). Experiments on VLABench and RoboMME show qualitatively distinct gains from each axis, and physical validation on a Franka arm in DROID demonstrates the router matching or exceeding stronger fixed-model success rates at up to 65% lower average latency, thereby improving the success-cost Pareto frontier.
Significance. If substantiated with full experimental controls, the result would be significant for embodied AI by demonstrating practical efficiency gains in deploying frontier VLMs on robots without uniform scaling. Credit is due for the multi-benchmark evaluation and physical hardware validation on zero-shot manipulation and long-horizon tasks, which directly addresses deployment constraints.
major comments (2)
- [Abstract] Abstract: the central claim that the router 'matches or exceeds a stronger model's success rate at up to 65% lower average latency' is load-bearing for the Pareto-frontier improvement; the text provides no quantitative details on router training, error bars, baseline definitions, or data splits, preventing assessment of whether routing errors offset the reported gains.
- [Abstract] The assumption that multimodal scene context supplies sufficient signal to predict allocations without misallocations whose success penalty exceeds latency savings is invoked for the main result but lacks supporting analysis (e.g., routing accuracy or failure-case breakdowns), which is required to establish robustness over fixed selection.
minor comments (1)
- [Abstract] The abstract introduces the three axes but defers their explicit listing; consider naming them in the opening sentence for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting areas where additional clarity would strengthen the presentation. We address each major comment below and commit to revisions that directly respond to the concerns while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the router 'matches or exceeds a stronger model's success rate at up to 65% lower average latency' is load-bearing for the Pareto-frontier improvement; the text provides no quantitative details on router training, error bars, baseline definitions, or data splits, preventing assessment of whether routing errors offset the reported gains.
Authors: We agree the abstract is highly condensed and omits key methodological specifics that support the central claim. The full manuscript details router training (supervised classification on multimodal features, Section 3.2), reports error bars on all success and latency metrics (Tables 2–4 and Figure 3), defines baselines explicitly (fixed-model and oracle routers, Section 4.1), and specifies data splits (80/20 train/test per benchmark, Appendix A). To make these elements immediately visible, we will revise the abstract to include one concise sentence summarizing training procedure, evaluation protocol, and statistical reporting. This change will be made without altering the reported 65% latency figure or the overall claim. revision: yes
-
Referee: [Abstract] The assumption that multimodal scene context supplies sufficient signal to predict allocations without misallocations whose success penalty exceeds latency savings is invoked for the main result but lacks supporting analysis (e.g., routing accuracy or failure-case breakdowns), which is required to establish robustness over fixed selection.
Authors: The manuscript already contains a quantitative routing-accuracy evaluation on held-out prompts (Section 5.3, 87.4% top-1 accuracy) and a qualitative discussion of misallocation cases. However, we acknowledge that a dedicated breakdown quantifying the success penalty of misallocations versus latency savings is not present in the current version. We will add this analysis—comparing success rates on correctly versus incorrectly routed prompts and computing net Pareto improvement after routing errors—to the revised manuscript, thereby directly addressing the robustness concern. revision: yes
Circularity Check
Empirical routing framework evaluated on external benchmarks; no derivation reduces to fitted inputs or self-citations
full rationale
The paper introduces DIRECT as an empirical routing method that allocates test-time compute across axes like CoT depth, model size, and memory history using multimodal scene context. It reports experimental results on VLABench, RoboMME, and a physical Franka/DROID setup, claiming the router matches or exceeds stronger fixed models at up to 65% lower latency. No equations, derivations, or self-citations are invoked that reduce success rates, latency figures, or Pareto improvements to quantities defined by parameters fitted within the paper itself or to prior author work. The claims rest on direct benchmark comparisons rather than any self-definitional, fitted-prediction, or uniqueness-imported structure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as I can, not as I say: Grounding language in robotic affordances. InProceedings of the 6th Conference on Robot Learning (CoRL), 2022
2022
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[3]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. Palm-e: an embodied multimodal language model. InProceedings of the 40th International Confere...
2023
-
[4]
L. X. Shi, B. Ichter, M. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, et al. Hi robot: Open-ended instruction following with hierarchical vision-language- action models.arXiv preprint arXiv:2502.19417, 2025
Pith/arXiv arXiv 2025
-
[5]
G. R. Team, A. Abdolmaleki, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, A. Bal- akrishna, N. Batchelor, A. Bewley, J. Bingham, et al. Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer.arXiv preprint arXiv:2510.03342, 2025
Pith/arXiv arXiv 2025
-
[6]
Sridhar, J
A. Sridhar, J. Pan, S. Sharma, and C. Finn. Memer: Scaling up memory for robotic control via experience retrieval. InThe Fourteenth International Conference on Learning Representations, 2025
2025
-
[7]
C. Snell, J. Lee, K. Xu, and A. Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
Pith/arXiv arXiv 2024
-
[8]
L. Chen, M. Zaharia, and J. Zou. FrugalGPT: How to use large language models more effi- ciently while reducing cost and latency. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[9]
I. Ong, L. Chen, S. Huang, M. Zaharia, and J. Zou. RouteLLM: Learning to route LLMs with open models. InProceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS), 2024. 9
2024
-
[10]
Huang, P
W. Huang, P. Abbeel, D. Tamane, K. Hausman, K. Fang, D. Shah, I. Mordatch, A. Zaldivar, S. Guadarrama, and F. Lu. Inner monologue: Embodied reasoning through planning with language models. InProceedings of the 6th Conference on Robot Learning (CoRL), 2022
2022
-
[11]
Kahneman
D. Kahneman. Thinking, fast and slow.Farrar, Straus and Giroux, 2011
2011
-
[12]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, b. ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
2025
-
[13]
Y . Ji, H. Tan, J. Shi, X. Hao, Y . Zhang, H. Zhang, P. Wang, M. Zhao, Y . Mu, P. An, et al. Robobrain: A unified brain model for robotic manipulation from abstract to concrete. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1724–1734, 2025
2025
-
[14]
W. Mao, W. Zhong, Z. Jiang, D. Fang, Z. Zhang, Z. Lan, H. Li, F. Jia, T. Wang, H. Fan, et al. Robomatrix: A skill-centric hierarchical framework for scalable robot task planning and execution in open-world.arXiv preprint arXiv:2412.00171, 2024
arXiv 2024
-
[15]
Y . Yang, J. Sun, S. Kou, Y . Wang, and Z. Deng. Lohovla: A unified vision-language-action model for long-horizon embodied tasks.arXiv preprint arXiv:2506.00411, 2025
arXiv 2025
-
[16]
S. Han, B. Qiu, Y . Liao, S. Huang, C. Gao, S. Yan, and S. Liu. Robocerebra: A large-scale benchmark for long-horizon robotic manipulation evaluation, 2025. URLhttps://arxiv. org/abs/2506.06677
arXiv 2025
-
[17]
D. Ding, A. Mallick, C. Wang, R. Sim, S. Mukherjee, V . R ¨uhle, L. Lakshmanan, and A. H. Awadallah. Hybrid llm: Cost-efficient and quality-aware query routing. InInternational Con- ference on Learning Representations, volume 2024, pages 41348–41366, 2024
2024
-
[18]
P. Aggarwal, A. Madaan, A. Anand, S. P. Potharaju, S. Mishra, P. Zhou, A. Gupta, D. Ra- jagopal, K. Kappaganthu, Y . Yang, et al. Automix: Automatically mixing language models. arXiv preprint arXiv:2310.12963, 2023
arXiv 2023
-
[19]
Huang, B
Z. Huang, B. Lin, J. Zhang, J. Wang, Y . Liu, N. Lu, T. Li, and X. Huang. Vl-routerbench: A benchmark for vision-language model routing, 2025. URLhttps://arxiv.org/abs/2512. 23562
2025
-
[20]
H. Ma, G. Lai, and H.-J. Ye. Mmr-bench: A comprehensive benchmark for multimodal llm routing.arXiv preprint arXiv:2601.17814, 2026
arXiv 2026
-
[21]
X. Liu, B. He, X. Liu, A. Luo, H. Zhang, and H. Chen. Adaptive vision-language model routing for computer use agents.arXiv preprint arXiv:2603.12823, 2026
arXiv 2026
-
[22]
X. Tang, Y . Han, F. Gou, W. Zhao, X. Meng, Y . Yu, J. Zhang, Y . Shi, Y . Wang, and T. Zhang. Ecvl-router: Scenario-aware routing for vision-language models.arXiv preprint arXiv:2510.27256, 2025
arXiv 2025
-
[23]
Zhang, Z
S. Zhang, Z. Xu, P. Liu, X. Yu, Y . Li, Q. Gao, Z. Fei, Z. Yin, Z. Wu, Y .-G. Jiang, and X. Qiu. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11142–11152, October 2025. 10
2025
-
[24]
I. Chun, S. Lee, M. Albergo, S. Xie, and E. Vanden-Eijnden. Dynamic test-time compute scaling in control policy: Difficulty-aware stochastic interpolant policy.Advances in Neural Information Processing Systems, 38:51441–51462, 2026
2026
-
[25]
J. Wei, X. Wang, D. Schuurman, M. Bazarewski, B. Ichter, R. Liu, D. Zhou, and Q. V . Le. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[26]
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information pro- cessing systems, 36:11809–11822, 2023
2023
-
[27]
Z. Bi, K. Han, C. Liu, Y . Tang, and Y . Wang. Forest-of-thought: Scaling test-time compute for enhancing llm reasoning.arXiv preprint arXiv:2412.09078, 2024
arXiv 2024
-
[28]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
Pith/arXiv arXiv 2022
-
[29]
E. Zhao, P. Awasthi, and S. Gollapudi. Sample, scrutinize and scale: Effective inference-time search by scaling verification.arXiv preprint arXiv:2502.01839, 2025
arXiv 2025
-
[30]
W. Yang, S. Ma, Y . Lin, and F. Wei. Towards thinking-optimal scaling of test-time compute for llm reasoning.Advances in Neural Information Processing Systems, 38:43605–43631, 2026
2026
- [31]
-
[32]
X. Wang, J. McInerney, L. Wang, and N. Kallus. Entropy after</think>for reasoning model early exiting.arXiv preprint arXiv:2509.26522, 2025
Pith/arXiv arXiv 2025
-
[33]
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine. Robotic control via embodied chain-of-thought reasoning.arXiv preprint arXiv:2407.08693, 2024
Pith/arXiv arXiv 2024
-
[34]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, et al. Cot- vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[35]
M. Ganai, K. Luo, J. Frey, C. Barrett, and M. Pavone. Self-supervised bootstrapping of action- predictive embodied reasoning.arXiv preprint arXiv:2602.08167, 2026
Pith/arXiv arXiv 2026
-
[36]
W. Chen, S. Belkhale, S. Mirchandani, K. Pertsch, D. Driess, O. Mees, and S. Levine. Training strategies for efficient embodied reasoning. In J. Lim, S. Song, and H.-W. Park, editors,Pro- ceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 365–391. PMLR, 27–30 Sep 2025
2025
-
[37]
Z. Duan, Y . Zhang, S. Geng, G. Liu, J. Boedecker, and C. X. Lu. Fast ecot: Efficient embodied chain-of-thought via thoughts reuse.arXiv preprint arXiv:2506.07639, 2025
arXiv 2025
-
[38]
Z. Liu, J. Liu, H. Chen, J. Yu, Z. Guo, C. Hou, C. Gu, X. Mi, R. Zhang, K. Wu, et al. Last {0}: Latent spatio-temporal chain-of-thought for robotic vision-language-action model.arXiv preprint arXiv:2601.05248, 2026
arXiv 2026
-
[39]
S. Bai, J. Lyu, W. Zhou, Z. Li, D. Wang, L. Xing, X. Zhao, P. Wang, Z. Wang, C. Chi, et al. Latent reasoning vla: Latent thinking and prediction for vision-language-action models.arXiv preprint arXiv:2602.01166, 2026
Pith/arXiv arXiv 2026
-
[40]
W. Chen, S. Belkhale, S. Mirchandani, O. Mees, D. Driess, K. Pertsch, and S. Levine. Training strategies for efficient embodied reasoning.arXiv preprint arXiv:2505.08243, 2025. 11
arXiv 2025
-
[41]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
Pith/arXiv arXiv 2025
-
[42]
Y . Dai, H. Fu, J. Lee, Y . Liu, H. Zhang, J. Yang, C. Finn, N. Fazeli, and J. Chai. Robomme: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639, 2026
Pith/arXiv arXiv 2026
-
[43]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[44]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[45]
M.-L. M.-F. Multi-Granularity. M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216, 2024
Pith/arXiv arXiv 2024
-
[46]
Zheng, H
Y . Zheng, H. Zhu, R. Lu, Y . Guan, S. Zhang, F. Wang, J. Shao, and H. Li. Efficient and privacy-preserving aggregated reverse knn query over crowd-sensed data.IEEE Transactions on Information Forensics and Security, 18:4285–4299, 2023
2023
-
[47]
Rifkin and A
R. Rifkin and A. Klautau. In defense of one-vs-all classification.Journal of machine learning research, 5(Jan):101–141, 2004
2004
-
[48]
Y . Lu, R. Liu, J. Yuan, X. Cui, S. Zhang, H. Liu, and J. Xing. Routerarena: An open platform for comprehensive comparison of llm routers.arXiv preprint arXiv:2510.00202, 2025
arXiv 2025
-
[49]
R. Sinha, A. Elhafsi, C. Agia, M. Foutter, E. Schmerling, and M. Pavone. Real-Time Anomaly Detection and Reactive Planning with Large Language Models. InProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024. doi:10.15607/RSS.2024.XX.114
-
[50]
Kapfer, K
C. Kapfer, K. Stine, B. Narasimhan, C. Mentzel, and E. Candes. Marlowe: Stanford’s gpu- based computational instrument, 2025
2025
-
[51]
X. C. Song, P. Smith, R. Kalyanam, X. Zhu, E. Adams, K. Colby, P. Finnegan, E. Gough, E. Hillery, R. Irvine, A. Maji, and J. St. John. Anvil - system architecture and experiences from deployment and early user operations. InPractice and Experience in Advanced Research Computing 2022: Revolutionary: Computing, Connections, You, PEARC ’22, New York, NY , US...
-
[52]
Q. Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026. URLhttps://qwen.ai/blog?id=qwen3.5
2026
-
[53]
W. Hong, W. Yu, X. Gu, G. Wang, G. Gan, H. Tang, J. Cheng, J. Qi, J. Ji, L. Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
Pith/arXiv arXiv 2025
-
[54]
Cosmos-reason2.https://huggingface.co/nvidia/Cosmos-Reason2-8B,
NVIDIA. Cosmos-reason2.https://huggingface.co/nvidia/Cosmos-Reason2-8B,
-
[55]
R. Dang, J. Guo, B. Hou, S. Leng, K. Li, X. Li, J. Liu, Y . Mao, Z. Wang, Y . Yuan, et al. Rynnbrain: Open embodied foundation models.arXiv preprint arXiv:2602.14979, 2026
arXiv 2026
-
[56]
Gemini 3 flash.https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf, 2025
Google DeepMind. Gemini 3 flash.https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf, 2025. Model card
2025
-
[57]
Gemini robotics-er 1.6.https://deepmind.google/models/ model-cards/gemini-robotics-er-1-6/, 2025
Google DeepMind. Gemini robotics-er 1.6.https://deepmind.google/models/ model-cards/gemini-robotics-er-1-6/, 2025. Model card
2025
-
[58]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[59]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, et al. DINOv2: Learning robust visual features without supervi- sion.Transactions on Machine Learning Research (TMLR), 2024
2024
-
[60]
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu. M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. In L.-W. Ku, A. Martins, and V . Srikumar, editors,Findings of the Association for Computa- tional Linguistics: ACL 2024, pages 2318–2335, Bangkok, Thailand, Aug. 2024. Associa...
-
[61]
π: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, L. Smith, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A Vision-Language-Action Flow Model for General Robot Control. In Proceedings...
-
[62]
soft-label
Q. Gu, Y . Ju, S. Sun, I. Gilitschenski, H. Nishimura, M. Itkina, and F. Shkurti. Safe: Mul- titask failure detection for vision-language-action models.Advances in Neural Information Processing Systems, 38:40041–40076, 2026. 13 DIRECT: When and Where Should You Allocate Test-Time Compute in Embodied Planners? Appendix Contents A Notation and Model Referen...
2026
-
[63]
used for the pairwise routing comparisons in the main paper (a model may appear as both).Thinkmarks chain-of-thought planners. Color runs red to green :Overall(mean across categories) is higher=green, while the resource columnsSizeandLat.are inverted (smaller / faster=green, log-scaled); API planners have round-trip latencies (Appendix E) and a greySizece...
arXiv 1916
-
[64]
put"; reach for/pick up ->
VERB. Accept verbs in the canonical grammar and same-class synonyms (place/put/move/set/drop/slide -> "put"; reach for/pick up -> "pick up"; wipe/clean/mop -> "wipe"; close/shut -> "close"). A verb outside any class is INCORRECT only if it would change the VLA’s behavior
-
[65]
The referent must be correct and groundable
OBJECT. The referent must be correct and groundable. Color must match GT or be camera-confusable (clear/white/transparent; red/pink/orange; purple/violet); categorically different colors are INCORRECT. Noun synonyms are fine when only one such item is present (dish/petri dish; goggles/safety glasses; block/brick). Dropping a brand word is fine; dropping a...
-
[66]
put X in/on Y
DESTINATION. If GT requires placement ("put X in/on Y"), a prediction that only picks up drops the step -> INCORRECT. A bare pickup matched by "pick up X" is CORRECT. Destination color/type must match (or be camera-confusable)
-
[67]
If multiple candidates exist and the prediction drops the distinguishing attribute -> INCORRECT
DISAMBIGUATION. If multiple candidates exist and the prediction drops the distinguishing attribute -> INCORRECT. In singular scenes a missing color is fine
-
[68]
ABSTRACTION. If the instruction contains an abstraction the VLA cannot ground (color-by-analogy, density / world-knowledge, exclusion reasoning), the prediction must RESOLVE it to the concrete color/object in GROUND_TRUTH; parroting the abstraction -> INCORRECT. Simple spatial location (leftmost / rightmost / beside) is observable, not an abstraction
-
[69]
Off-distribution color words the VLA likely won’t bind ("lime") -> INCORRECT
-
[70]
llm_judge_match
Empty prediction -> INCORRECT. Reason about the scene first, then decide. Output ONLY this JSON: {"llm_judge_match": true|false, "reason": "<one concise sentence>"} Memory-need / routing judge.Decides whether the task needs cross-step memory or is observable step-by-step from the scene (gripper state and source-object disappearance). 40 You are routing a ...
-
[71]
name": "pick
pick: Used to grasp and pick up a target object. - Call format: { "name": "pick", "params": { "target_entity_name": Target Number } }
-
[72]
name": "place
place: Place an object in a specified location, suitable for vertical placement. - Call format: { "name": "place", "params": { "target_container_name": Target Number } }
-
[73]
name": "press
press: Press a specified location or button. - Call format: { "name": "press", "params": { "target_entity_name": Target Number } } 41
-
[74]
name": "open_door
open_door: Open a door. - Call format: { "name": "open_door", "params": { } }
-
[75]
name": "insert
insert: Insert an item into a target location. - Call format: { "name": "insert", "params": { "target_container_name": Target Number } }
-
[76]
name": "pull
pull: Pull the robotic arm horizontally. - Call format: { "name": "pull", "params": { } }
-
[77]
name": "pour
pour: Pour a liquid or granular substance. - Call format: { "name": "pour", "params": { "target_container_name": Target Number } }
-
[78]
name": "push
push: Push a target object horizontally. - Call format: { "name": "push", "params": { "target_container_name": Target Number } }
-
[79]
name": "lift
lift: Lift the robotic arm vertically. - Call format: { "name": "lift", "params": { } } These call formats ensure that each skill operation has clearly defined parameters, allowing the system to accurately execute the specified automated tasks. You will receive the following input:
-
[80]
- The second image contains the same four perspectives of objects, but each view is labeled with a number (representing each object’s identifier)
Image input: Two images - The first image shows four different perspectives of objects (without labels). - The second image contains the same four perspectives of objects, but each view is labeled with a number (representing each object’s identifier)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.