From Craft to Kernel: A Governance-First Execution Architecture and Semantic ISA for Agentic Computers
Pith reviewed 2026-05-21 01:10 UTC · model grok-4.3
The pith
Arbiter-K wraps probabilistic AI models in a deterministic kernel that uses a Semantic ISA for taint-based security enforcement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
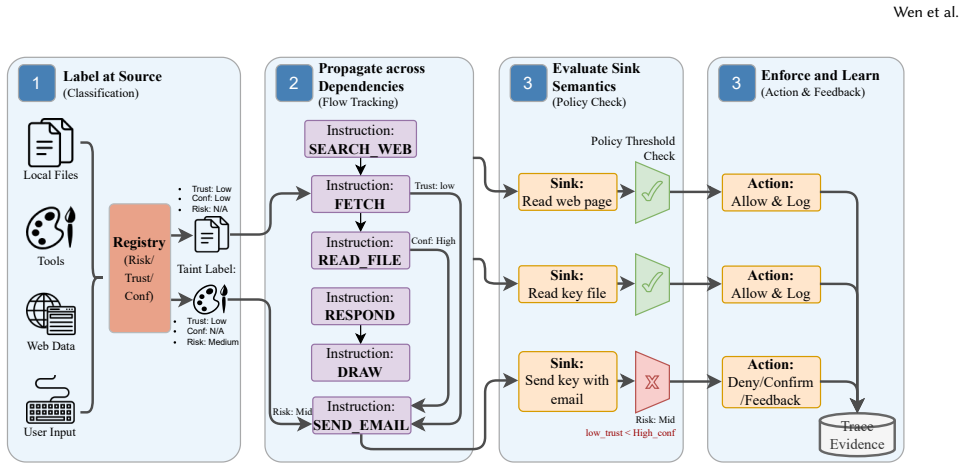
Arbiter-K reconceptualizes the underlying model as a Probabilistic Processing Unit encapsulated by a deterministic neuro-symbolic kernel. It implements a Semantic ISA to reify probabilistic messages into discrete instructions, maintains a Security Context Registry, and constructs an Instruction Dependency Graph at runtime. Active taint propagation based on data-flow pedigree then enables precise interdiction of unsafe trajectories at deterministic sinks along with autonomous execution correction and architectural rollback when security policies activate.
What carries the argument
Semantic ISA that converts probabilistic model outputs into discrete instructions to support runtime construction of an Instruction Dependency Graph and taint propagation inside the governance kernel.
If this is right
- Security enforcement shifts from heuristic patches to a built-in microarchitectural property of the execution environment.
- Unsafe trajectories are intercepted at rates from 76% to 95%, for a 92.79% absolute improvement over native policies on OpenClaw and NanoBot.
- Interdiction occurs at precise deterministic sinks such as high-risk tool calls or unauthorized network egress.
- The kernel triggers autonomous execution correction and architectural rollback when security policies activate.
Where Pith is reading between the lines
- The same kernel structure could be applied to other probabilistic control systems that must interact with external tools or networks.
- The discrete-instruction layer may eventually support formal verification of agent safety properties beyond runtime taint checks.
- Adoption could allow existing agent platforms to gain deterministic guards without retraining the underlying models for each new policy.
Load-bearing premise
A Semantic ISA can translate probabilistic model outputs into discrete instructions while retaining enough information for accurate taint propagation and dependency graph construction without introducing new failure modes or excessive false positives.
What would settle it
A test on additional agent tasks that measures whether taint propagation either misses novel unsafe patterns or blocks safe operations at rates higher than the reported native-policy baseline.
Figures







read the original abstract
The transition of agentic AI from brittle prototypes to production systems is stalled by a pervasive crisis of craft. We suggest that the prevailing orchestration paradigm-delegating the system control loop to large language models and merely patching with heuristic guardrails-is the root cause of this fragility. Instead, we propose Arbiter-K, a Governance-First execution architecture that reconceptualizes the underlying model as a Probabilistic Processing Unit encapsulated by a deterministic, neuro-symbolic kernel. Arbiter-K implements a Semantic Instruction Set Architecture (ISA) to reify probabilistic messages into discrete instructions. This allows the kernel to maintain a Security Context Registry and construct an Instruction Dependency Graph at runtime, enabling active taint propagation based on the data-flow pedigree of each reasoning node. By leveraging this mechanism, Arbiter-K precisely interdicts unsafe trajectories at deterministic sinks (e.g., high-risk tool calls or unauthorized network egress) and enables autonomous execution correction and architectural rollback when security policies are triggered. Evaluations on OpenClaw and NanoBot demonstrate that Arbiter-K enforces security as a microarchitectural property, achieving 76% to 95% unsafe interception for a 92.79% absolute gain over native policies. The code is publicly available at https://github.com/cure-lab/ArbiterOS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Arbiter-K, a governance-first execution architecture for agentic AI that treats the underlying LLM as a Probabilistic Processing Unit encapsulated by a deterministic neuro-symbolic kernel. It introduces a Semantic Instruction Set Architecture (ISA) to reify probabilistic outputs into discrete instructions, enabling runtime maintenance of a Security Context Registry and construction of an Instruction Dependency Graph for active taint propagation. This mechanism is claimed to interdict unsafe trajectories at deterministic sinks (e.g., high-risk tool calls) with autonomous correction and rollback. Evaluations on OpenClaw and NanoBot report 76%–95% unsafe interception rates and a 92.79% absolute gain over native policies; the code is released publicly.
Significance. If the central claims hold after proper validation, the work could meaningfully advance secure agentic systems by shifting from heuristic guardrails to microarchitectural enforcement of security properties via taint tracking and dependency graphs. Public code availability is a clear strength that enables reproducibility and community scrutiny.
major comments (2)
- [Evaluation] Evaluation section (results on OpenClaw and NanoBot): The abstract and results report concrete performance figures (76% to 95% interception, 92.79% absolute gain) yet supply no description of experimental setup, number of trials or trajectories tested, precise definition of “unsafe trajectories,” choice of baselines, or statistical analysis. This information is load-bearing for attributing the reported gains to the proposed architecture rather than test-specific conditions.
- [Architecture / Semantic ISA] Semantic ISA and Instruction Dependency Graph construction (core mechanism description): The central security claim requires that probabilistic LLM outputs are reliably discretized into instructions such that taint propagation and dependency-graph construction remain accurate. No concrete mapping rules, uncertainty-handling procedure, or analysis of information loss/false-positive rates during discretization are provided; without these, the microarchitectural security property does not demonstrably follow.
minor comments (1)
- [Abstract] Abstract: The term “native policies” is used for the baseline comparison but is not defined; a brief parenthetical clarification would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key areas where additional detail will strengthen the manuscript. We respond to each major comment below and will make the indicated revisions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (results on OpenClaw and NanoBot): The abstract and results report concrete performance figures (76% to 95% interception, 92.79% absolute gain) yet supply no description of experimental setup, number of trials or trajectories tested, precise definition of “unsafe trajectories,” choice of baselines, or statistical analysis. This information is load-bearing for attributing the reported gains to the proposed architecture rather than test-specific conditions.
Authors: We agree that the Evaluation section requires substantially more detail to support the reported figures. In the revised manuscript we will add a complete description of the experimental protocol, including the total number of trajectories and trials executed on OpenClaw and NanoBot, the precise definition of unsafe trajectories (those that violate any policy encoded in the Security Context Registry), the baseline configurations (native LLM policies without the Arbiter-K kernel), and the statistical analysis performed (including variance across runs and any confidence intervals). These additions will allow readers to evaluate whether the observed gains are attributable to the architecture. revision: yes
-
Referee: [Architecture / Semantic ISA] Semantic ISA and Instruction Dependency Graph construction (core mechanism description): The central security claim requires that probabilistic LLM outputs are reliably discretized into instructions such that taint propagation and dependency-graph construction remain accurate. No concrete mapping rules, uncertainty-handling procedure, or analysis of information loss/false-positive rates during discretization are provided; without these, the microarchitectural security property does not demonstrably follow.
Authors: We acknowledge that the current description of the Semantic ISA would benefit from greater concreteness. In the revision we will insert an explicit subsection that defines the mapping rules used to convert probabilistic LLM outputs into discrete instructions, describes the uncertainty-handling mechanisms (for example, confidence-threshold gating and fallback to conservative taint labels), and reports measured rates of information loss and false-positive discretization errors on the evaluation workloads. These additions will make the accuracy of subsequent taint propagation and Instruction Dependency Graph construction more transparent. revision: yes
Circularity Check
No significant circularity in the proposed architecture and evaluation
full rationale
The paper presents Arbiter-K as a new system design: a governance-first execution architecture that encapsulates a probabilistic model inside a deterministic neuro-symbolic kernel using a Semantic ISA. It describes runtime mechanisms for Security Context Registry, Instruction Dependency Graph, and taint propagation, then reports empirical interception rates (76-95%, 92.79% gain) from evaluations on OpenClaw and NanoBot. No equations, fitted parameters, or self-citation chains are shown that reduce the central security claims to inputs by construction. The results are positioned as outcomes of the architecture rather than self-referential derivations, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Probabilistic model outputs can be faithfully reified into discrete instructions via a Semantic ISA without critical loss of intent or safety-relevant information.
invented entities (4)
-
Probabilistic Processing Unit
no independent evidence
-
Semantic Instruction Set Architecture (ISA)
no independent evidence
-
Security Context Registry
no independent evidence
-
Instruction Dependency Graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amazon. 2025. Amazon Bedrock AgentCore Policy: Control Agent-to-Tool Interactions. https://docs.aws.amazon.com/bedrock- agentcore/latest/devguide/policy.html
work page 2025
-
[2]
Anthropic. 2025. Equipping agents for the real world with Agent Skills. https://www.anthropic.com/engineering/equipping-agents- for-the-real-world- with-agent-skills
work page 2025
-
[3]
Xiaohe Bo, Zeyu Zhang, Quanyu Dai, Xueyang Feng, Lei Wang, Rui Li, Xu Chen, and Ji-Rong Wen. 2024. Reflective Multi-Agent Collabo- ration based on Large Language Models. In Proceedings of NeurIPS
work page 2024
-
[4]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi’c, Luca Beurer- Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Evaluate Attacks and Defenses for LLM Agents. ArXiv abs/2406.13352 (2024). https://api.semanticscholar. org/CorpusID:270619628
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [5]
-
[6]
Invariant Labs. 2025. Invariant Guardrails. https://github.com/invariantlabs-ai/invariant
work page 2025
-
[7]
IronClaw Contributors. 2026. IronClaw: Your secure personal AI as- sistant, always on your side. https://github.com/nearai/ironclaw
work page 2026
-
[8]
Yang JingYi, Shuai Shao, Dongrui Liu, and Jing Shao. 2025. RiOS- World: Benchmarking the Risk of Multimodal Computer-Use Agents. In NeurIPS
work page 2025
- [9]
- [10]
-
[11]
Thomas Kuntz, Agatha Duzan, Hao Zhao, Francesco Croce, J Zico Kolter, Nicolas Flammarion, and Maksym Andriushchenko. 2025. OS- Harm: A Benchmark for Measuring Safety of Computer Use Agents. In NeurIPS
work page 2025
- [12]
-
[13]
Songyang Liu, Chaozhuo Li, Chenxu Wang, Jinyu Hou, Zejian Chen, Litian Zhang, Zheng Liu, Qiwei Ye, Yiming Hei, Xi Zhang, and Zhongyuan Wang. 2026. ClawKeeper: Comprehensive Safety Pro- tection for OpenClaw Agents Through Skills, Plugins, and Watchers. ArXiv abs/2603.24414 (2026)
-
[14]
Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, Chenlin Zhou, Jiayi Mao, Tianze Xia, Jiafeng Guo, and Shenghua Liu. 2025. A Survey of Context Engineering for Large Language Models. ArXiv abs/2507.13334 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
NanoBot Contributors. 2026. NanoBot: Ultra-Lightweight Personal AI Agent. https://github.com/HKUDS/nanobot
work page 2026
-
[16]
OpenClaw Contributors. 2026. OpenClaw: Open-Source AI Agent Runtime. https://github.com/openclaw/openclaw
work page 2026
-
[17]
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Sam- rat Sohel Mondal, and Aman Chadha. 2024. A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Ap- plications. ArXiv abs/2402.07927 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
Sander Schulhoff, Michael Ilie, Nishant Balepur, Konstantine Ka- hadze, Amanda Liu, Chenglei Si, Yinheng Li, Aayush Gupta, Hyo- Jung Han, Sevien Schulhoff, Pranav Sandeep Dulepet, Saurav Vidyad- hara, Dayeon Ki, Sweta Agrawal, Chau Minh Pham, Gerson C. Kroiz, Feileen Li, Hudson Tao, Ashay Srivastava, Hevander Da Costa, Sa- loni Gupta, Megan L. Rogers, Inn...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Ava Spataru, Eric Hambro, Elena Voita, and Nicola Cancedda. 2024. Know When To Stop: A Study of Semantic Drift in Text Generation. In Proceedings of NAACL. 3656–3671
work page 2024
-
[20]
Wang, Trisha Singhal, Ameya Kelkar, and Jason Tuo
Charles L. Wang, Trisha Singhal, Ameya Kelkar, and Jason Tuo. 2025. MI9: An Integrated Runtime Governance Framework for Agentic AI. ArXiv abs/2508.03858 (2025)
- [21]
- [22]
-
[23]
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. 2025. Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents. In ICLR
work page 2025
-
[24]
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. 2024. Agent-SafetyBench: Eval- uating the Safety of LLM Agents. ArXiv abs/2412.14470 (2024). https: //api.semanticscholar.org/CorpusID:274859514
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Wei Zhao, Zhe Li, Peixin Zhang, and Jun Sun. 2026. ClawGuard: A Runtime Security Framework for Tool-Augmented LLM Agents Against Indirect Prompt Injection. ArXiv abs/2604.11790v1 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.