MECoBench: A Systematic Study of Multimodal Agent Collaboration in Embodied Environments
Pith reviewed 2026-07-01 02:14 UTC · model grok-4.3
The pith
Multimodal agents complete embodied tasks more reliably through collaboration when communication balances the added coordination costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
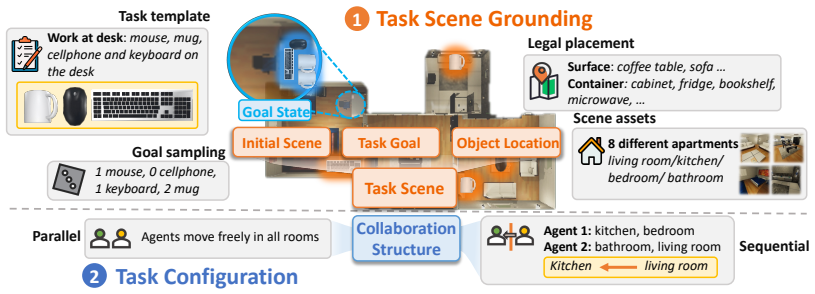
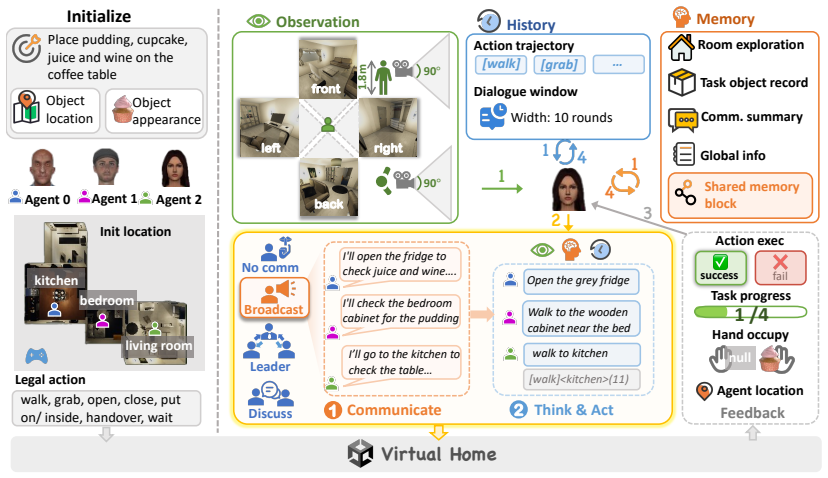
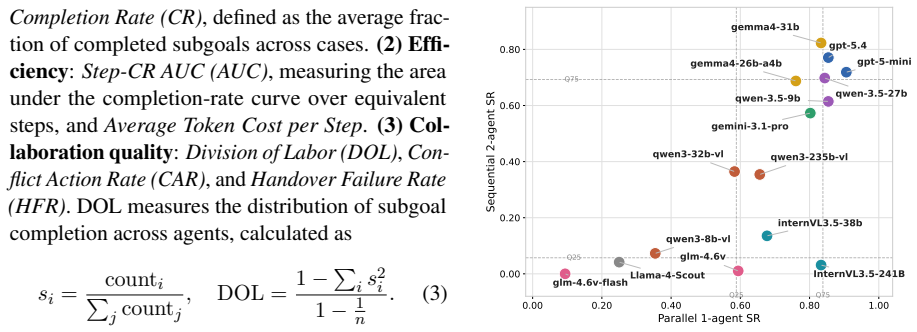
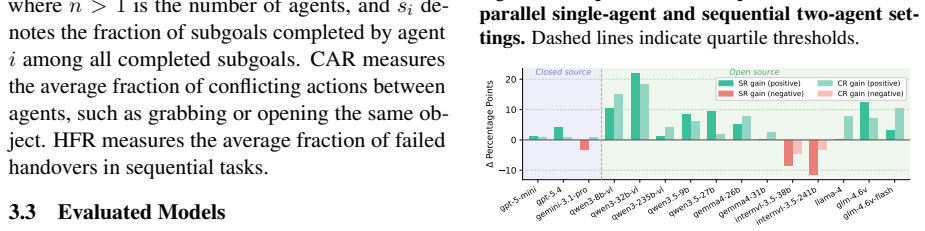
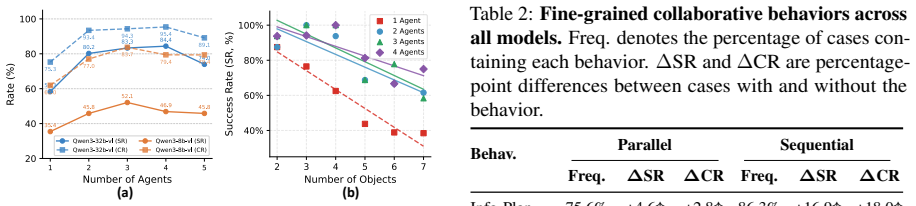
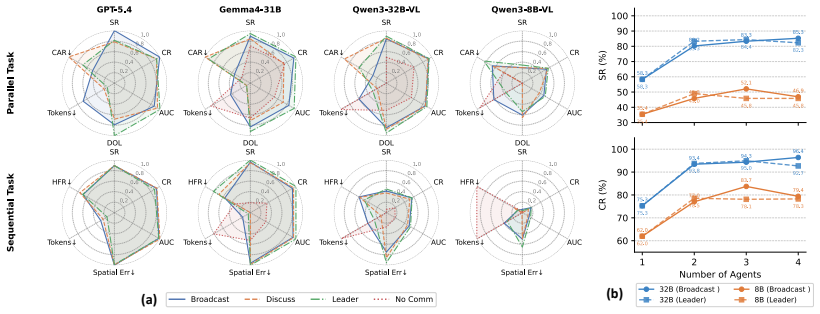
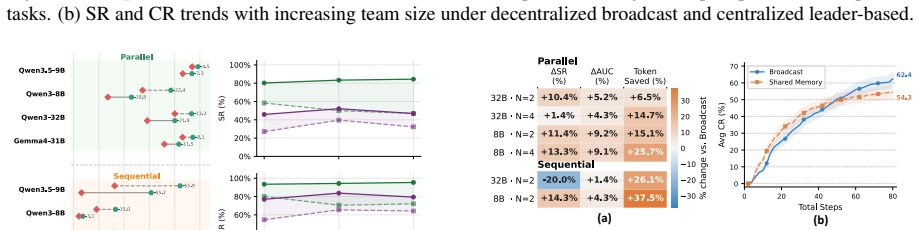
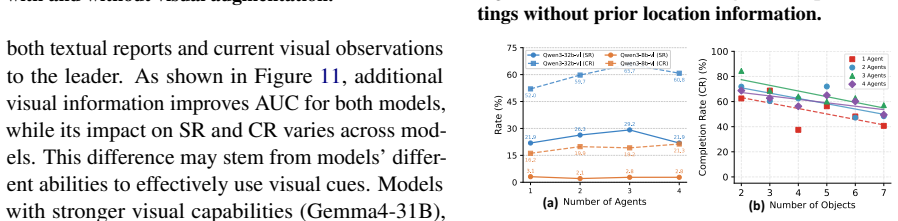
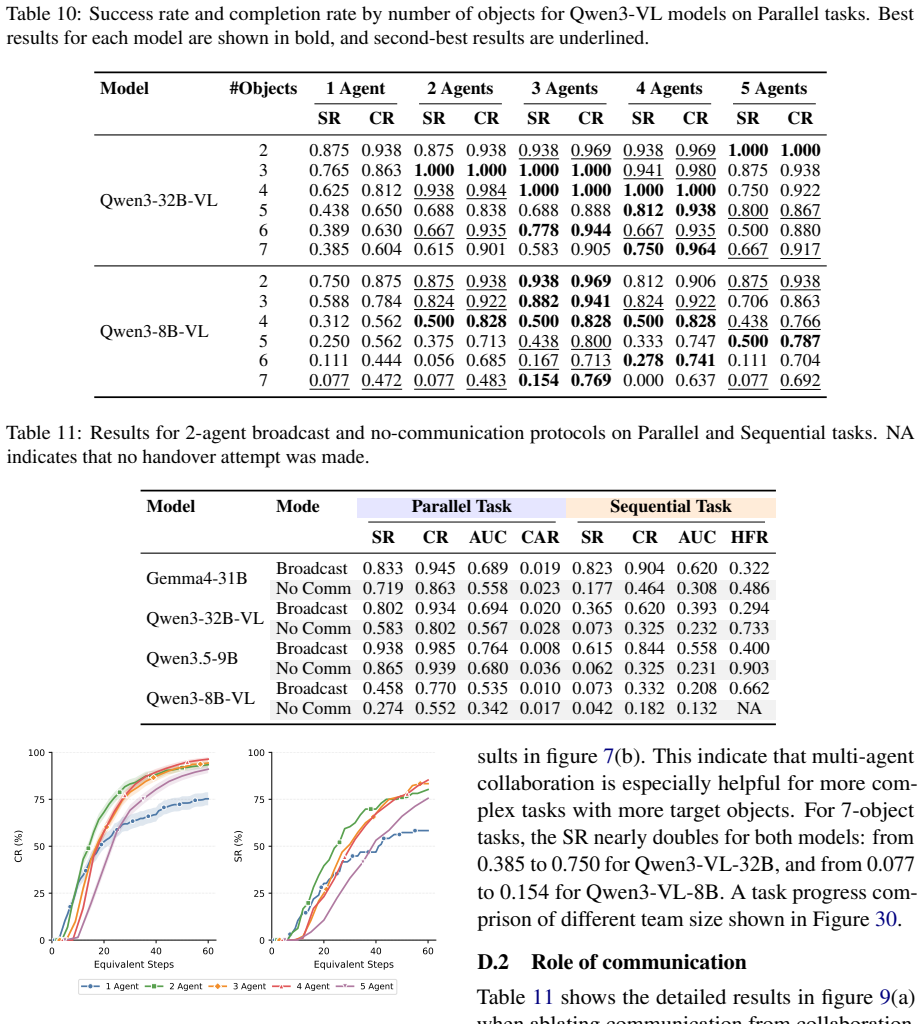
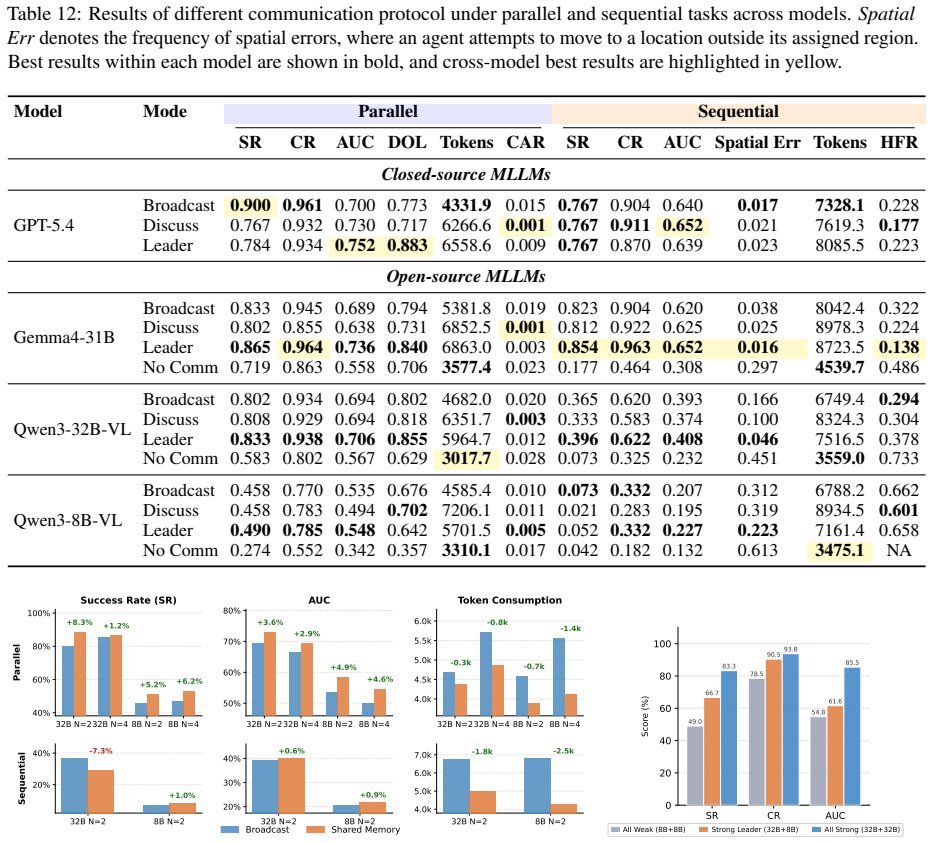
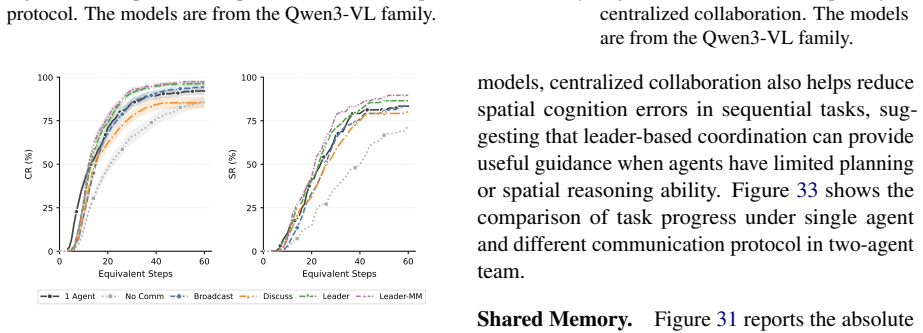
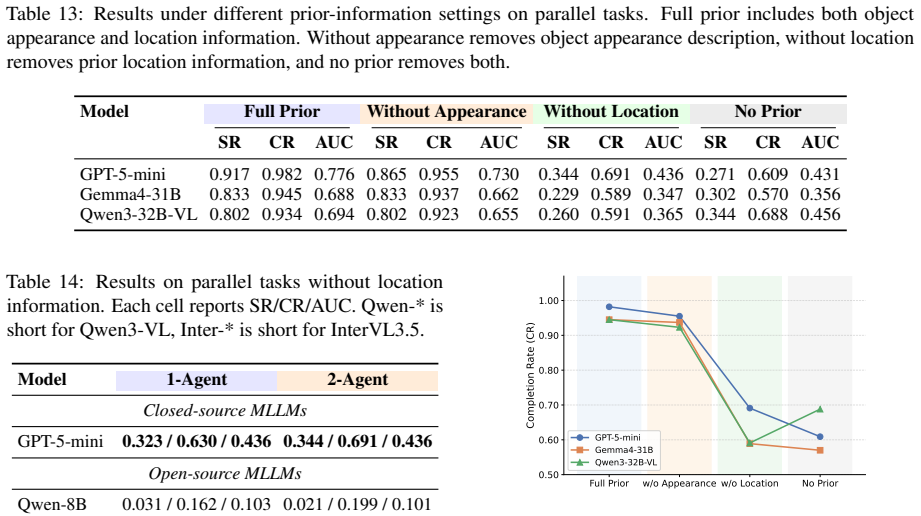
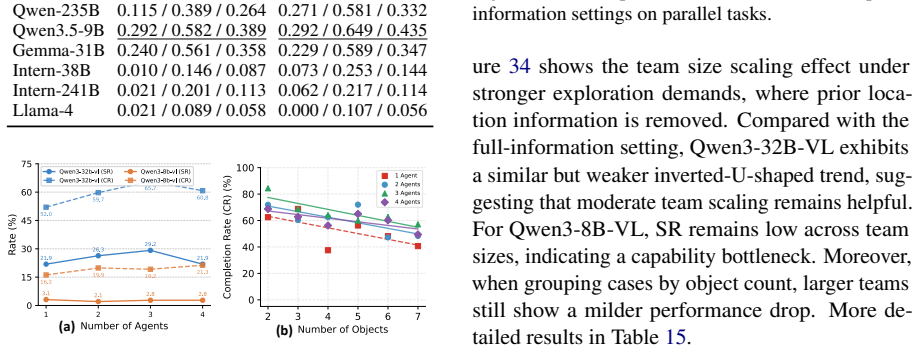
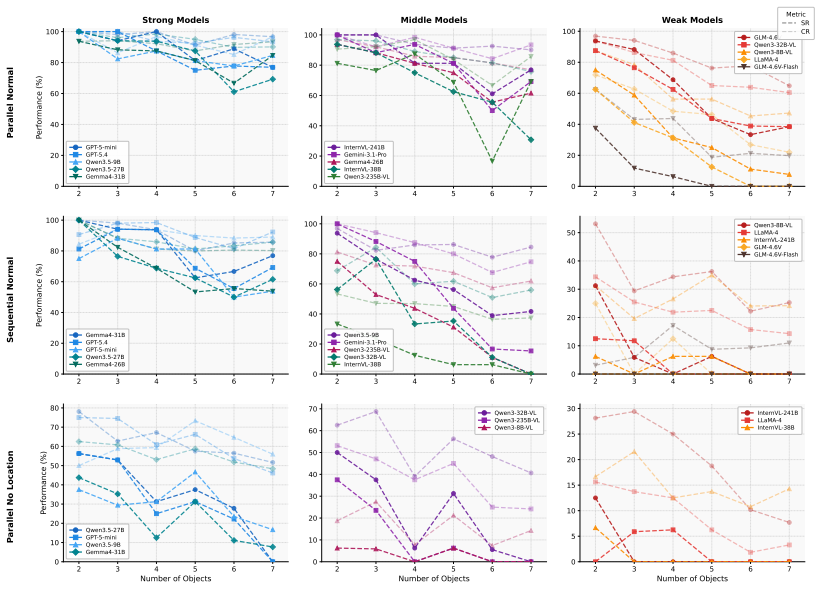
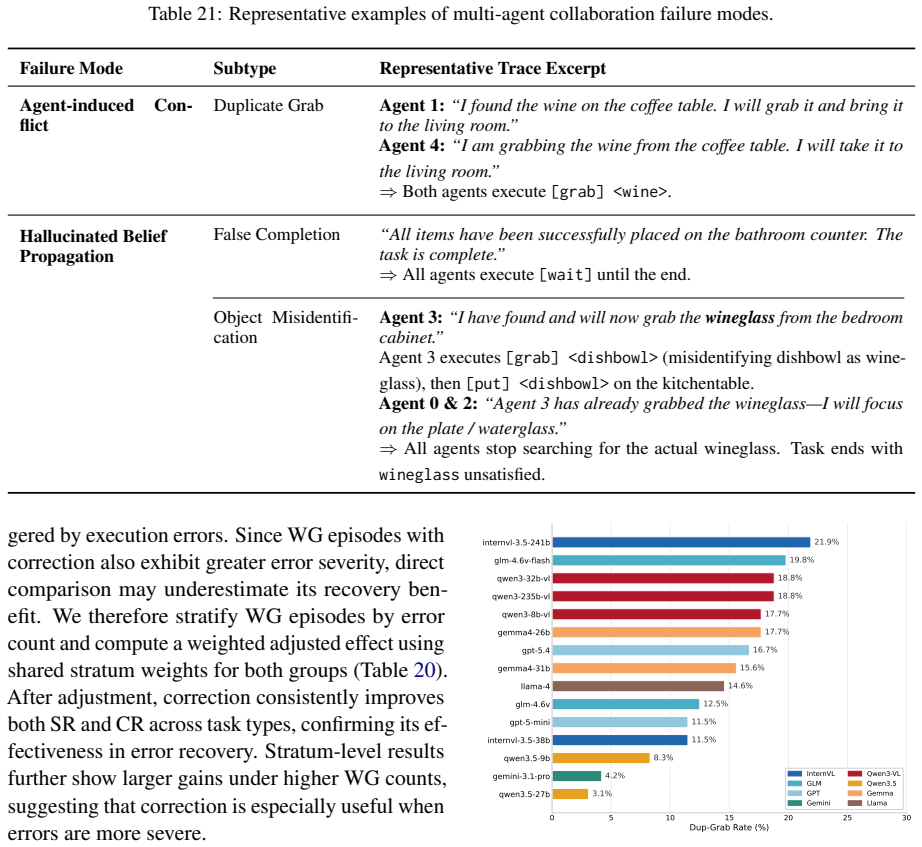
MECoBench supplies a platform with diverse real-world tasks, two cooperation structures, and three collaboration modes. Systematic tests across MLLMs establish that collaboration generally raises embodied task completion rates provided collaborative gains exceed coordination complexity. Communication is required to realize those gains, and the optimal collaboration mode depends on team size and model capability. Collaboration further increases robustness when priors are noisy or exploration is limited.
What carries the argument
MECoBench, the benchmark platform that systematically varies tasks, cooperation structures, and collaboration modes to isolate when and how multimodal agents benefit from joint work.
If this is right
- Communication protocols become a necessary design element for any multi-agent embodied system that hopes to exceed single-agent performance.
- Choice of collaboration mode must be tuned to both the number of agents and the capability level of the underlying models.
- Joint operation can be used to offset uncertainty in starting conditions or incomplete environmental knowledge.
- Performance gains scale with the ability to exchange information without incurring prohibitive coordination overhead.
- The same patterns hold across different MLLMs, suggesting the findings are not tied to one model family.
Where Pith is reading between the lines
- Designers of future robotic teams could prioritize lightweight communication channels over raw model scale.
- The observed dependence on team size points toward possible scaling rules for when adding agents stops helping.
- The benchmark could be extended to test whether the same trade-offs appear in longer-horizon or more open-ended tasks.
- Results imply that single-agent baselines may systematically underestimate what is achievable once coordination is solved.
Load-bearing premise
The tasks, structures, and modes selected for MECoBench are representative of the broader space of embodied multi-agent problems.
What would settle it
Re-running the full set of experiments on a fresh collection of embodied tasks outside the current benchmark and observing no consistent improvement from collaboration.
Figures










read the original abstract
Recent multimodal large language models (MLLMs) have strong potential as embodied agents, but their ability to collaborate in visually grounded environments remains underexplored. To address this gap, we introduce MECoBench, a multimodal embodied cooperation benchmark with an evaluation platform spanning diverse real-world tasks, two cooperation structures, and three collaboration modes. Through extensive experiments across various MLLMs, we summarize three key findings: (i) Collaboration generally improves embodied task completion, but its benefits depend on balancing collaborative gains against coordination complexity. (ii) Communication is essential to collaboration gains, while the best collaboration mode depends on team size and model capability. (iii) Moreover, collaboration improves robustness under noisy priors and exploration conditions. Generally, MECoBench provides a systematic testbed for understanding the mechanisms and limits of multimodal embodied collaboration. Code and dataset are available at https://github.com/q-i-n-g/MECoBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MECoBench, a multimodal embodied cooperation benchmark spanning diverse real-world tasks, two cooperation structures, and three collaboration modes. Experiments across multiple MLLMs yield three key findings: (i) collaboration generally improves task completion subject to coordination-complexity trade-offs, (ii) communication is essential while optimal mode depends on team size and model capability, and (iii) collaboration enhances robustness under noisy priors and exploration; the benchmark is positioned as a systematic testbed.
Significance. If the reported patterns prove robust to task selection and model families, MECoBench supplies a needed empirical platform for studying multimodal multi-agent collaboration in grounded settings, with potential to guide future agent design.
major comments (2)
- [Abstract] Abstract: the three key findings are phrased as general statements ("Collaboration generally improves", "Communication is essential", "the best collaboration mode depends on team size and model capability") without accompanying analysis or ablations that test invariance across task families, state-space characteristics, or MLLM architectures. This makes the claims load-bearing for the paper's central contribution yet unsupported by evidence of broader applicability.
- [Experiments / Results] The manuscript does not report any cross-task meta-analysis or sensitivity checks (e.g., correlation of performance deltas with task metrics such as state dimensionality or required coordination depth) that would substantiate the claimed mechanisms over benchmark-specific artifacts.
minor comments (2)
- [§3] Clarify the exact definition and implementation details of the three collaboration modes and two cooperation structures in the main text rather than relying solely on supplementary material.
- [§4] Ensure all reported metrics include error bars or statistical significance tests across random seeds and model runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important opportunities to strengthen the presentation of generality and mechanistic support in our work. We address each point below and commit to revisions that qualify claims appropriately while adding requested analyses where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the three key findings are phrased as general statements ("Collaboration generally improves", "Communication is essential", "the best collaboration mode depends on team size and model capability") without accompanying analysis or ablations that test invariance across task families, state-space characteristics, or MLLM architectures. This makes the claims load-bearing for the paper's central contribution yet unsupported by evidence of broader applicability.
Authors: We agree the abstract phrasing is too broad. While the benchmark already includes diverse real-world tasks, two cooperation structures, three collaboration modes, and multiple MLLM families (as detailed in Sections 3 and 4), we did not perform explicit invariance ablations. In revision we will (i) qualify all three findings in the abstract with phrases such as "within the evaluated tasks and models" and (ii) add a dedicated subsection reporting performance deltas stratified by task family and model scale to make the scope explicit. revision: yes
-
Referee: [Experiments / Results] The manuscript does not report any cross-task meta-analysis or sensitivity checks (e.g., correlation of performance deltas with task metrics such as state dimensionality or required coordination depth) that would substantiate the claimed mechanisms over benchmark-specific artifacts.
Authors: The referee is correct that no such meta-analysis appears in the current manuscript. To address this, we will add a new analysis subsection that computes Spearman correlations between observed collaboration gains and task-level metrics (state dimensionality, coordination depth, and exploration requirement) across the benchmark tasks. This will be included in the revised Experiments section. revision: yes
Circularity Check
Empirical benchmark study with no derivations or fitted parameters
full rationale
The paper introduces MECoBench as an evaluation platform, runs experiments across MLLMs on its tasks/structures/modes, and reports observed patterns as findings. No equations, parameter fitting, predictions, or derivation chains exist that could reduce to inputs by construction. All claims are direct empirical summaries from the benchmark runs, rendering the work self-contained with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected tasks and environments sufficiently capture real-world embodied cooperation challenges.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Tenenbaum and Sanja Fidler and Antonio Torralba , booktitle=
Xavier Puig and Tianmin Shu and Shuang Li and Zilin Wang and Yuan-Hong Liao and Joshua B. Tenenbaum and Sanja Fidler and Antonio Torralba , booktitle=. Watch-And-Help: A Challenge for Social Perception and Human-. 2021 , url=
2021
-
[9]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Puig, Xavier and Ra, Kevin and Boben, Marko and Li, Jiaman and Wang, Tingwu and Fidler, Sanja and Torralba, Antonio , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[10]
M ulti A gent B ench : Evaluating the Collaboration and Competition of LLM agents
Zhu, Kunlun and Du, Hongyi and Hong, Zhaochen and Yang, Xiaocheng and Guo, Shuyi and Wang, Zhe and Wang, Zhenhailong and Qian, Cheng and Tang, Xiangru and Ji, Heng and You, Jiaxuan. M ulti A gent B ench : Evaluating the Collaboration and Competition of LLM agents. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol...
-
[11]
Collab-Overcooked: Benchmarking and Evaluating Large Language Models as Collaborative Agents
Sun, Haochen and Zhang, Shuwen and Niu, Lujie and Ren, Lei and Xu, Hao and Fu, Hao and Zhao, Fangkun and Yuan, Caixia and Wang, Xiaojie. Collab-Overcooked: Benchmarking and Evaluating Large Language Models as Collaborative Agents. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.249
-
[12]
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors , url =
Chen, Weize and Su, Yusheng and Zuo, Jingwei and Yang, Cheng and Yuan, Chenfei and Chan, Chi-Min and Yu, Heyang and Lu, Yaxi and Hung, Yi-Hsin and Qian, Chen and Qin, Yujia and Cong, Xin and Xie, Ruobing and Liu, Zhiyuan and Sun, Maosong and Zhou, Jie , booktitle =. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors , url =
-
[13]
Multi-Agent Collaboration via Evolving Orchestration , url =
Dang, Yufan and Qian, Chen and Luo, Xueheng and Fan, Jingru and Xie, Zihao and Shi, Ruijie and Chen, Weize and Yang, Cheng and Che, Xiaoyin and Tian, Ye and Xiong, Xuantang and Han, Lei and Liu, Zhiyuan and Sun, Maosong , booktitle =. Multi-Agent Collaboration via Evolving Orchestration , url =
-
[14]
Forty-second International Conference on Machine Learning , year=
EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents , author=. Forty-second International Conference on Machine Learning , year=
-
[15]
The Thirteenth International Conference on Learning Representations , year=
VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents , author=. The Thirteenth International Conference on Learning Representations , year=
-
[16]
2026 , month = mar, howpublished =
GPT-5.4 Thinking System Card , author =. 2026 , month = mar, howpublished =
2026
-
[17]
2026 , month = feb, howpublished =
2026
-
[18]
2026 , month = apr, howpublished =
2026
-
[19]
AI magazine , volume=
Multiagent systems , author=. AI magazine , volume=
-
[20]
Stone, Peter and Veloso, Manuela , title =. Autonomous Robots , year =. doi:10.1023/A:1008942012299 , url =
-
[21]
Agent Laboratory: Using LLM Agents as Research Assistants
Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiaodong and Liu, Jiang and Moor, Michael and Liu, Zicheng and Barsoum, Emad. Agent Laboratory: Using LLM Agents as Research Assistants. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.320
-
[22]
Su, Haoyang and Chen, Renqi and Tang, Shixiang and Yin, Zhenfei and Zheng, Xinzhe and Li, Jinzhe and Qi, Biqing and Wu, Qi and Li, Hui and Ouyang, Wanli and Torr, Philip and Zhou, Bowen and Dong, Nanqing. Many Heads Are Better Than One: Improved Scientific Idea Generation by A LLM -Based Multi-Agent System. Proceedings of the 63rd Annual Meeting of the As...
-
[23]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework , url =
Hong, Sirui and Zhuge, Mingchen and Chen, Jonathan and Zheng, Xiawu and Cheng, Yuheng and Wang, Jinlin and Zhang, Ceyao and wang, zili and Yau, Steven and Lin, Zijuan and Zhou, Liyang and Ran, Chenyu and Xiao, Lingfeng and Wu, Chenglin and Schmidhuber, J\". MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework , url =. International Conferen...
-
[24]
Ashraful and Ali, Mohammed Eunus and Parvez, Md Rizwan
Islam, Md. Ashraful and Ali, Mohammed Eunus and Parvez, Md Rizwan. C ode S im: Multi-Agent Code Generation and Problem Solving through Simulation-Driven Planning and Debugging. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.285
-
[25]
AI Hospital: Benchmarking Large Language Models in a Multi-agent Medical Interaction Simulator
Fan, Zhihao and Wei, Lai and Tang, Jialong and Chen, Wei and Siyuan, Wang and Wei, Zhongyu and Huang, Fei. AI Hospital: Benchmarking Large Language Models in a Multi-agent Medical Interaction Simulator. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[26]
Chen, Xi and Yi, Huahui and You, Mingke and Liu, WeiZhi and Wang, Li and Li, Hairui and Zhang, Xue and Guo, Yingman and Fan, Lei and Chen, Gang and Lao, Qicheng and Fu, Weili and Li, Kang and Li, Jian , title =. npj Digital Medicine , year =. doi:10.1038/s41746-025-01550-0 , url =
-
[27]
2025 , howpublished =
AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society , author =. 2025 , howpublished =
2025
-
[28]
2024 , eprint=
MineLand: Simulating Large-Scale Multi-Agent Interactions with Limited Multimodal Senses and Physical Needs , author=. 2024 , eprint=
2024
-
[29]
Dong, Yubo and Zhu, Xukun and Pan, Zhengzhe and Zhu, Linchao and Yang, Yi. V illager A gent: A Graph-Based Multi-Agent Framework for Coordinating Complex Task Dependencies in M inecraft. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.964
-
[30]
Scaling Large Language Model-based Multi-Agent Collaboration , url =
Qian, Chen and Xie, Zihao and Wang, YiFei and Liu, Wei and Zhu, Kunlun and Xia, Hanchen and Dang, Yufan and Du, Zhuoyun and Chen, Weize and Yang, Cheng and Liu, Zhiyuan and Sun, Maosong , booktitle =. Scaling Large Language Model-based Multi-Agent Collaboration , url =
-
[31]
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making , url =
Li, Manling and Zhao, Shiyu and Wang, Qineng and Wang, Kangrui and Zhou, Yu and Srivastava, Sanjana and Gokmen, Cem and Lee, Tony and Li, Li and Zhang, Ruohan and Liu, Weiyu and Liang, Percy and Fei-Fei, Li and Mao, Jiayuan and Wu, Jiajun , booktitle =. Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making , url =. doi:10.52202/079017-3...
-
[32]
ProcTHOR: Large-Scale Embodied AI Using Procedural Generation , url =
Deitke, Matt and VanderBilt, Eli and Herrasti, Alvaro and Weihs, Luca and Ehsani, Kiana and Salvador, Jordi and Han, Winson and Kolve, Eric and Kembhavi, Aniruddha and Mottaghi, Roozbeh , booktitle =. ProcTHOR: Large-Scale Embodied AI Using Procedural Generation , url =
-
[33]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Savva, Manolis and Kadian, Abhishek and Maksymets, Oleksandr and Zhao, Yili and Wijmans, Erik and Jain, Bhavana and Straub, Julian and Liu, Jia and Koltun, Vladlen and Malik, Jitendra and Parikh, Devi and Batra, Dhruv , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
-
[34]
PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks , url =
Chang, Matthew and Chhablani, Gunjan and Clegg, Alexander and Dallaire Cote, Mikael and Desai, Ruta and Hlavac, Michal and Karashchuk, Vladimir and Krantz, Jacob and Mottaghi, Roozbeh and Parashar, Priyam and Patki, Siddharth and Prasad, Ishita and Puig, Xavier and Rai, Akshara and Ramrakhya, Ram and Tran, Daniel and Truong, Joanne and Turner, John and Un...
-
[35]
Robotics: Science and Systems , year=
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation , author=. Robotics: Science and Systems , year=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Yang, Yijun and Zhou, Tianyi and Li, Kanxue and Tao, Dapeng and Li, Lusong and Shen, Li and He, Xiaodong and Jiang, Jing and Shi, Yuhui , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[37]
Nature Machine Intelligence , volume =
Embodied large language models enable robots to complete complex tasks in unpredictable environments , author =. Nature Machine Intelligence , volume =. 2025 , doi =
2025
-
[38]
2025 , eprint=
EmbodiedEval: Evaluate Multimodal LLMs as Embodied Agents , author=. 2025 , eprint=
2025
-
[39]
The Twelfth International Conference on Learning Representations , year=
Large Language Models as Generalizable Policies for Embodied Tasks , author=. The Twelfth International Conference on Learning Representations , year=
-
[40]
COMBO: Compositional World Models for Embodied Multi-Agent Cooperation , url =
Zhang, Hongxin and Wang, Zeyuan and Lyu, Qiushi and Zhang, Zheyuan and Chen, Sunli and Shu, Tianmin and Dariush, Behzad and Lee, Kwonjoon and Du, Yilun and Gan, Chuang , booktitle =. COMBO: Compositional World Models for Embodied Multi-Agent Cooperation , url =
-
[41]
Heterogeneous Embodied Multi-Agent Collaboration , year=
Liu, Xinzhu and Guo, Di and Zhang, Xinyu and Liu, Huaping , journal=. Heterogeneous Embodied Multi-Agent Collaboration , year=
-
[42]
Building Cooperative Embodied Agents Modularly with Large Language Models , url =
Zhang, Hongxin and Du, Weihua and Shan, Jiaming and Zhou, Qinhong and Du, Yilun and Tenenbaum, Joshua B and Shu, Tianmin and Gan, Chuang , booktitle =. Building Cooperative Embodied Agents Modularly with Large Language Models , url =
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Shridhar, Mohit and Thomason, Jesse and Gordon, Daniel and Bisk, Yonatan and Han, Winson and Mottaghi, Roozbeh and Zettlemoyer, Luke and Fox, Dieter , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[44]
Science China Information Sciences , year =
Feng, Zhaohan and Xue, Ruiqi and Yuan, Lei and Yu, Yang and Ding, Ning and Liu, Meiqin and Gao, Bingzhao and Sun, Jian and Zheng, Xinhu and Wang, Gang , title =. Science China Information Sciences , year =. doi:10.1007/s11432-025-4820-4 , url =
-
[45]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[46]
2026 , howpublished =
Gemma 4 Model Card , author =. 2026 , howpublished =
2026
-
[47]
2025 , eprint=
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency , author=. 2025 , eprint=
2025
-
[48]
2025 , howpublished =
Llama 4: Model Cards and Prompt Formats , author =. 2025 , howpublished =
2025
-
[49]
2025 , eprint=
GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning , author=. 2025 , eprint=
2025
-
[50]
2025 , howpublished =
GPT-5 mini Model , author =. 2025 , howpublished =
2025
-
[51]
EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought , url =
Mu, Yao and Zhang, Qinglong and Hu, Mengkang and Wang, Wenhai and Ding, Mingyu and Jin, Jun and Wang, Bin and Dai, Jifeng and Qiao, Yu and Luo, Ping , booktitle =. EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought , url =
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Szot, Andrew and Mazoure, Bogdan and Attia, Omar and Timofeev, Aleksei and Agrawal, Harsh and Hjelm, Devon and Gan, Zhe and Kira, Zsolt and Toshev, Alexander , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[53]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[54]
A Cordial Sync: Going Beyond Marginal Policies for Multi-agent Embodied Tasks
Jain, Unnat and Weihs, Luca and Kolve, Eric and Farhadi, Ali and Lazebnik, Svetlana and Kembhavi, Aniruddha and Schwing, Alexander. A Cordial Sync: Going Beyond Marginal Policies for Multi-agent Embodied Tasks. Computer Vision -- ECCV 2020. 2020
2020
-
[55]
RoCo: Dialectic Multi-Robot Collaboration with Large Language Models , year=
Mandi, Zhao and Jain, Shreeya and Song, Shuran , booktitle=. RoCo: Dialectic Multi-Robot Collaboration with Large Language Models , year=
-
[56]
2025 , eprint=
Collaborating Action by Action: A Multi-agent LLM Framework for Embodied Reasoning , author=. 2025 , eprint=
2025
-
[57]
2024 , eprint=
TeamCraft: A Benchmark for Multi-Modal Multi-Agent Systems in Minecraft , author=. 2024 , eprint=
2024
-
[58]
2026 , eprint=
COOP ^2 : Defining, Observing, and Repairing Cooperation in LLM Multi-Agent Systems , author=. 2026 , eprint=
2026
-
[59]
VIKI‑R: Coordinating Embodied Multi-Agent Cooperation via Reinforcement Learning , url =
Kang, Li and Song, Xiufeng and Zhou, Heng and Qin, Yiran and Yang, Jie and Liu, Xiaohong and Torr, Philip and BAI, LEI and Yin, Zhenfei , booktitle =. VIKI‑R: Coordinating Embodied Multi-Agent Cooperation via Reinforcement Learning , url =
-
[60]
On the Utility of Learning about Humans for Human-AI Coordination , url =
Carroll, Micah and Shah, Rohin and Ho, Mark and Griffiths, Tom and Seshia, Sanjit and Abbeel, Pieter and Dragan, Anca , booktitle =. On the Utility of Learning about Humans for Human-AI Coordination , url =
-
[61]
Agashe, Saaket and Fan, Yue and Reyna, Anthony and Wang, Xin Eric. LLM -Coordination: Evaluating and Analyzing Multi-agent Coordination Abilities in Large Language Models. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.448
-
[62]
SoMi-ToM: Evaluating Multi-Perspective Theory of Mind in Embodied Social Interactions , url =
Fan, Xianzhe and Zhou, Xuhui and Jin, Chuanyang and Nottingham, Kolby and Zhu, Hao and Sap, Maarten , booktitle =. SoMi-ToM: Evaluating Multi-Perspective Theory of Mind in Embodied Social Interactions , url =
-
[63]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
AirCopBench: A Benchmark for Multi-drone Collaborative Embodied Perception and Reasoning , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2026 , doi =
2026
-
[64]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Zhang, Shiduo and Xu, Zhe and Liu, Peiju and Yu, Xiaopeng and Li, Yuan and Gao, Qinghui and Fei, Zhaoye and Yin, Zhangyue and Wu, Zuxuan and Jiang, Yu-Gang and Qiu, Xipeng , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.