VLAMotor: Test-Guided Enhancement of Vision-Language-Action Models via Agent-BasedData Synthesis
Pith reviewed 2026-06-30 19:16 UTC · model grok-4.3
The pith
VLAMotor turns exposed VLA test failures into agent-synthesized repair trajectories that raise success rates by 49 percent in simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
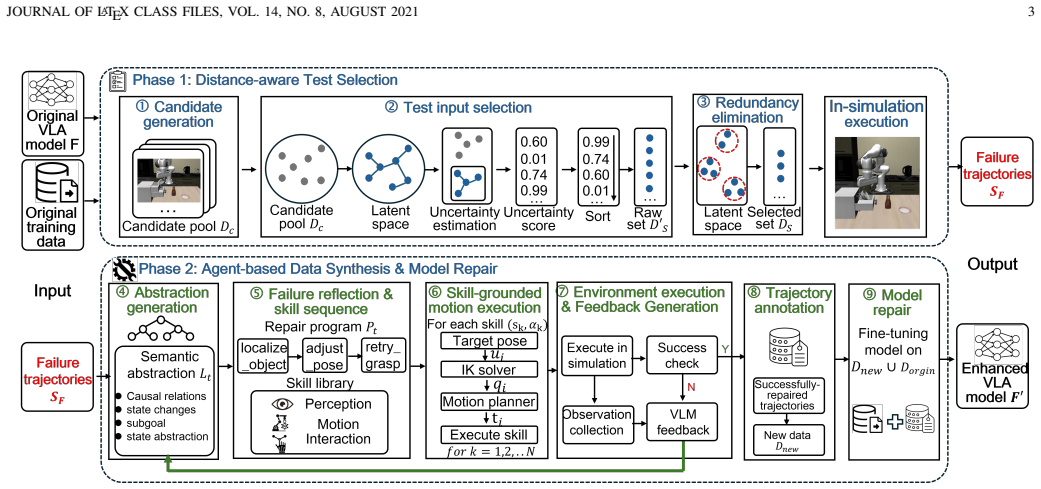
VLAMotor integrates distance-aware model testing for failure exposure with agent-based data synthesis for model fine-tuning. Failure trajectories are abstracted into structured semantic representations; an agent then plans parameterized repair-skill sequences that are realized as executable trajectories through inverse kinematics and motion execution. The successful trajectories are automatically labeled and supplied as new training data, yielding an enhanced VLA model that records higher success rates on robotic manipulation tasks.
What carries the argument
Agent-planned repair-skill sequences derived from distance-ranked failure trajectories and realized through inverse kinematics and motion execution.
If this is right
- Fine-tuning with the generated trajectories raises overall task success by 49.25 percent inside simulation.
- The same models improve success by 57.50 percent when transferred to real robot hardware.
- 92.33 percent of the generated test cases trigger failures in the original VLA models.
- Test coverage exceeds the prior state-of-the-art tool by 18.93 percent across four representative manipulation tasks.
Where Pith is reading between the lines
- The method could be extended to run continuously during deployment so that newly encountered failures immediately generate repair data.
- Similar agent-driven synthesis from simulation failures might apply to other data-driven controllers where real-world data collection is expensive.
- If the repair planning step generalizes across tasks, the approach could reduce reliance on large human-curated demonstration sets for training embodied models.
Load-bearing premise
Trajectories created in simulation from planned repairs will transfer to improve the VLA model's behavior on physical robots.
What would settle it
Deploying the fine-tuned models on the same real hardware tasks and measuring success rates that show no gain or a decline compared with the original models.
Figures
read the original abstract
Vision-Language-Action (VLA) models follow a data-driven paradigm and are constrained by the coverage of training data, making them prone to failure on edge-case configurations after deployment. To mitigate such risks, it is essential to expose high-quality failure modes and convert the resulting failures into supervisory data for model enhancement. Existing studies largely stop at failure detection and lack a mechanism for leveraging discovered failures for model repair. We propose VLAMotor, the first analysis framework for VLA enhancement, which integrates distance-aware model testing for failure exposure and agent-based data synthesis for model finetunning. First, VLAMotor estimates input uncertainty based on the distance to training samples, and combines uncertainty ranking with redundancy elimination to build compact test sets that expose diverse failures. Then, VLAMotor abstracts failure trajectories into structured semantic representations, and plans parameterized repair-skill sequences, which are then realized as executable trajectories through inverse kinematics and motion execution. The resulting successful trajectories are automatically labeled and used to fine-tune the original VLA model, yielding an enhanced VLA model. Evaluation on four representative robotic manipulation tasks shows that 92.33% of the in-simulation test cases generated by VLAMotor trigger VLA failures, and VLAMotor improves test coverage over the state-of-the-art tool by 18.93%. By fine-tuning VLA models with synthetic data derived from failed test cases, VLAMotor further enhances the overall success rate of VLA models by 49.25%. When deployed on real hardware, the simulation-enhanced models improve the success rate over the original VLA models by 57.50%, demonstrating an effective and low-cost direction for VLA enhancement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VLAMotor as the first framework to enhance Vision-Language-Action (VLA) models through distance-aware testing that exposes failures via uncertainty ranking and redundancy elimination, followed by agent-based synthesis that abstracts failures into semantic representations, plans parameterized repair-skill sequences, and realizes them as trajectories via inverse kinematics and motion execution for automatic labeling and fine-tuning. On four robotic manipulation tasks, it reports that 92.33% of generated in-simulation test cases trigger VLA failures, achieves 18.93% better test coverage than prior tools, improves overall success rate by 49.25% via fine-tuning on the synthetic data, and yields 57.50% success gains when the enhanced models are deployed on real hardware.
Significance. If the reported simulation-to-real gains hold under rigorous controls, the work would demonstrate a practical, low-cost pipeline for converting discovered VLA failures into supervisory data that meaningfully improves robustness on physical robots, addressing a core limitation of data-driven VLA models in edge-case manipulation scenarios.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: the central claims of 49.25% simulation and 57.50% real-hardware success-rate improvements are presented without any reported trial counts, variance, baseline models, or ablation isolating the contribution of the synthesized repair trajectories versus simply adding more data volume.
- [Method (data synthesis)] Synthesis pipeline (agent-based repair planning and IK realization): the manuscript provides no evidence that the generated trajectories address real-world contact dynamics, perception noise, or sim-to-real gaps; the 57.50% hardware gain therefore rests on an unverified assumption that IK-executed semantic repairs transfer without domain randomization or real-world trajectory validation.
- [Method (testing)] Failure exposure component: while distance-aware uncertainty ranking is described, the paper does not specify the distance metric, training-sample embedding method, or how redundancy elimination is performed, leaving the 92.33% failure-trigger and 18.93% coverage claims difficult to reproduce or compare.
minor comments (2)
- [Method] Notation for uncertainty estimation and skill parameterization could be formalized with equations or pseudocode for clarity.
- [Evaluation] Figure captions and experimental tables should explicitly list the number of runs and statistical measures supporting each reported percentage.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commit to revisions that strengthen the presentation of results and methods without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the central claims of 49.25% simulation and 57.50% real-hardware success-rate improvements are presented without any reported trial counts, variance, baseline models, or ablation isolating the contribution of the synthesized repair trajectories versus simply adding more data volume.
Authors: We agree that the abstract and evaluation sections would be strengthened by including these statistical and comparative details. In the revised manuscript we will report the number of trials per task, include variance measures (standard deviation across runs), explicitly name the baseline VLA models, and add an ablation that compares fine-tuning on the synthesized repair trajectories versus equivalent volumes of randomly sampled data. These additions will be placed in the Evaluation section and referenced from the abstract. revision: yes
-
Referee: [Method (data synthesis)] Synthesis pipeline (agent-based repair planning and IK realization): the manuscript provides no evidence that the generated trajectories address real-world contact dynamics, perception noise, or sim-to-real gaps; the 57.50% hardware gain therefore rests on an unverified assumption that IK-executed semantic repairs transfer without domain randomization or real-world trajectory validation.
Authors: The synthesis pipeline realizes trajectories via IK and motion execution, and the reported hardware results reflect direct deployment of the resulting models. We acknowledge that the manuscript currently provides limited discussion of contact dynamics, perception noise, and explicit sim-to-real mitigation strategies. In revision we will add a subsection in the Method section that (a) describes any domain randomization used during trajectory generation, (b) reports the hardware validation protocol, and (c) discusses observed transfer limitations. If additional controlled experiments are feasible before resubmission we will include them; otherwise we will clearly state the assumption and its scope. revision: partial
-
Referee: [Method (testing)] Failure exposure component: while distance-aware uncertainty ranking is described, the paper does not specify the distance metric, training-sample embedding method, or how redundancy elimination is performed, leaving the 92.33% failure-trigger and 18.93% coverage claims difficult to reproduce or compare.
Authors: We agree that the implementation details of the distance-aware testing component are insufficiently specified. In the revised manuscript we will add precise definitions: the distance metric (including its mathematical form), the embedding procedure for training samples, and the redundancy-elimination algorithm with its hyperparameters. These details will be placed in the Method section under the failure-exposure subsection and will enable direct reproduction and comparison with prior coverage tools. revision: yes
Circularity Check
No circularity: empirical pipeline with externally measured outcomes
full rationale
The paper describes an empirical method (distance-aware testing + agent-planned repair trajectories realized via IK) whose success is quantified by direct experimental metrics (failure exposure rate, coverage improvement, success-rate deltas on sim and real hardware). These quantities are not defined in terms of the method's own parameters, nor obtained by fitting then relabeling the same data. No equations, uniqueness theorems, or self-citation chains appear in the provided text that would reduce any claimed result to its inputs by construction. The reported gains are presented as measured outcomes of the pipeline rather than analytic predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Survey on Vision-Language-Action Models for Embodied AI
Y . Ma, Z. Song, Y . Zhuang, J. Hao, and I. King, “A survey on vision-language-action models for embodied ai,”arXiv preprint arXiv:2405.14093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Efficient Vision-Language-Action Models for Embodied Manipulation: A Systematic Survey
W. Guan, Q. Hu, A. Li, and J. Cheng, “Efficient vision-language-action models for embodied manipulation: A systematic survey,”arXiv preprint arXiv:2510.17111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Vlatest: Testing and evaluating vision-language-action models for robotic manipulation,
Z. Wang, Z. Zhou, J. Song, Y . Huang, Z. Shu, and L. Ma, “Vlatest: Testing and evaluating vision-language-action models for robotic manipulation,” Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 1615–1638, 2025
2025
-
[4]
In-simulation testing of deep learning vision models in autonomous robotic manipula- tors,
D. Humeniuk, H. Ben Braiek, T. Reid, and F. Khomh, “In-simulation testing of deep learning vision models in autonomous robotic manipula- tors,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, pp. 2187–2198, 2024
2024
-
[5]
Eva-vla: Evaluating vision-language-action models’ robustness under real-world physical variations,
H. Liu, J. Long, J. Wu, J. Hou, H. Tang, T. Jiang, W. Zhou, and W. Yao, “Eva-vla: Evaluating vision-language-action models’ robustness under real-world physical variations,”arXiv preprint arXiv:2509.18953, 2025
-
[6]
Robustvla: Robustness-aware reinforcement post-training for vision-language-action models,
H. Zhang, S. Zhang, J. Jin, Q. Zeng, R. Li, and D. Wang, “Robustvla: Robustness-aware reinforcement post-training for vision-language-action models,”arXiv preprint arXiv:2511.01331, 2025
-
[7]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei,et al., “Libero-plus: In-depth robustness analysis of vision- language-action models,”arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Evaluating uncertainty and quality of visual language action-enabled robots,
P. Valle, C. Lu, S. Ali, and A. Arrieta, “Evaluating uncertainty and quality of visual language action-enabled robots,”arXiv preprint arXiv:2507.17049, 2025
-
[9]
Diagnose, correct, and learn from manipulation failures via visual symbols,
X. Zeng, X. Zhou, Y . Li, J. Shi, T. Li, L. Chen, L. Ren, and Y .-L. Li, “Diagnose, correct, and learn from manipulation failures via visual symbols,”arXiv preprint arXiv:2512.02787, 2025
-
[10]
VLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models
B. Zhang, J. Li, J. Shen, Y . Cai, Y . Zhang, Y . Chen, J. Dai, J. Ji, and Y . Yang, “Vla-arena: An open-source framework for benchmarking vision-language-action models,”arXiv preprint arXiv:2512.22539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
A survey on robotics with foundation models: toward embodied ai,
Z. Xu, K. Wu, J. Wen, J. Li, N. Liu, Z. Che, and J. Tang, “A survey on robotics with foundation models: toward embodied ai,”arXiv preprint arXiv:2402.02385, 2024
-
[12]
Aligning cyber space with physical world: A comprehensive survey on embodied ai,
Y . Liu, W. Chen, Y . Bai, X. Liang, G. Li, W. Gao, and L. Lin, “Aligning cyber space with physical world: A comprehensive survey on embodied ai,”IEEE/ASME Transactions on Mechatronics, 2025
2025
-
[13]
From Human Memory to AI Memory: A Survey on Memory Mechanisms in the Era of LLMs
Y . Wu, S. Liang, C. Zhang, Y . Wang, Y . Zhang, H. Guo, R. Tang, and Y . Liu, “From human memory to ai memory: A survey on memory mechanisms in the era of llms,”arXiv preprint arXiv:2504.15965, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Advanced applications of industrial robotics: New trends and possibilities,
A. Dzedzickis, J. Suba ˇci¯ut˙e- ˇZemaitien˙e, E. ˇSutinys, U. Samukait ˙e- Bubnien˙e, and V . Buˇcinskas, “Advanced applications of industrial robotics: New trends and possibilities,”Applied Sciences, vol. 12, no. 1, p. 135, 2021
2021
-
[15]
Robotics and industry 4.0,
R. Goel and P. Gupta, “Robotics and industry 4.0,” inA roadmap to industry 4.0: Smart production, sharp business and sustainable development, pp. 157–169, Springer, 2019
2019
-
[16]
Service robots in the healthcare sector,
J. Holland, L. Kingston, C. McCarthy, E. Armstrong, P. O’Dwyer, F. Merz, and M. McConnell, “Service robots in the healthcare sector,”Robotics, vol. 10, no. 1, p. 47, 2021
2021
-
[17]
The rise of automation and robotics in warehouse management,
A. Dhaliwal, “The rise of automation and robotics in warehouse management,” inTransforming management using artificial intelligence techniques, pp. 63–72, CRC Press, 2020
2020
-
[18]
Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
R. Shao, W. Li, L. Zhang, R. Zhang, Z. Liu, R. Chen, and L. Nie, “Large vlm-based vision-language-action models for robotic manipulation: A survey,”arXiv preprint arXiv:2508.13073, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Generative artificial intelligence in robotic manipulation: A survey,
K. Zhang, P. Yun, J. Cen, J. Cai, D. Zhu, H. Yuan, C. Zhao, T. Feng, M. Y . Wang, Q. Chen,et al., “Generative artificial intelligence in robotic manipulation: A survey,”arXiv preprint arXiv:2503.03464, 2025
-
[20]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi,et al., “Openvla: An open- source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0,
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain,et al., “Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0,” in2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 6892–6903, IEEE, 2024
2024
-
[22]
GR00T N1: An open foundation model for generalist humanoid robots,
NVIDIA, J. Bjorck, N. C. Fernando Casta ˜neda, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu, ...
2025
-
[23]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai,et al., “A vision-language-action model with open-world generalization,”arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Black-box safety analysis and retraining of dnns based on feature extraction and clustering,
M. Attaoui, H. Fahmy, F. Pastore, and L. Briand, “Black-box safety analysis and retraining of dnns based on feature extraction and clustering,” ACM Transactions on Software Engineering and Methodology, vol. 32, no. 3, pp. 1–40, 2023
2023
-
[25]
Distance- aware test input selection for deep neural networks,
Z. Li, Z. Xu, R. Ji, M. Pan, T. Zhang, L. Wang, and X. Li, “Distance- aware test input selection for deep neural networks,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, pp. 248–260, 2024
2024
-
[26]
Search-based dnn testing and retraining with gan-enhanced simulations,
M. O. Attaoui, F. Pastore, and L. C. Briand, “Search-based dnn testing and retraining with gan-enhanced simulations,”IEEE Transactions on Software Engineering, 2025
2025
-
[27]
Hybridrepair: towards annotation-efficient repair for deep learning models,
Y . Li, M. Chen, and Q. Xu, “Hybridrepair: towards annotation-efficient repair for deep learning models,” inProceedings of the 31st ACM JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 SIGSOFT International Symposium on Software Testing and Analysis, pp. 227–238, 2022
2021
-
[28]
Detecting adversarial samples using influence functions and nearest neighbors,
G. Cohen, G. Sapiro, and R. Giryes, “Detecting adversarial samples using influence functions and nearest neighbors,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 14453–14462, 2020
2020
-
[29]
Element- based automated dnn repair with fine-tuned masked language model,
X. Wang, M. Zhang, X. Meng, J. Zhang, Y . Liu, and C. Hu, “Element- based automated dnn repair with fine-tuned masked language model,” Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 106–129, 2025
2025
-
[30]
Vlm agents generate their own memories: Distilling experience into embodied programs of thought,
G. Sarch, L. Jang, M. Tarr, W. W. Cohen, K. Marino, and K. Fragkiadaki, “Vlm agents generate their own memories: Distilling experience into embodied programs of thought,”Advances in Neural Information Processing Systems, vol. 37, pp. 75942–75985, 2024
2024
-
[31]
Analyzing and improving representations with the soft nearest neighbor loss,
N. Frosst, N. Papernot, and G. Hinton, “Analyzing and improving representations with the soft nearest neighbor loss,” inInternational conference on machine learning, pp. 2012–2020, PMLR, 2019
2012
-
[32]
To trust or not to trust a classifier,
H. Jiang, B. Kim, M. Guan, and M. Gupta, “To trust or not to trust a classifier,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[33]
Deep k-Nearest Neighbors: Towards Confident, Interpretable and Robust Deep Learning
N. Papernot and P. McDaniel, “Deep k-nearest neighbors: Towards confident, interpretable and robust deep learning,”arXiv preprint arXiv:1803.04765, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
Exploring methods for evaluating group differences on the nsse and other surveys: Are the t-test and cohen’sd indices the most appropriate choices,
J. Romano, J. D. Kromrey, J. Coraggio, J. Skowronek, and L. Devine, “Exploring methods for evaluating group differences on the nsse and other surveys: Are the t-test and cohen’sd indices the most appropriate choices,” inannual meeting of the Southern Association for Institutional Research, vol. 14, Citeseer, 2006
2006
-
[35]
Calibrated neighborhood aware confidence measure for deep metric learning,
M. Karpusha, S. Yun, and I. Fehervari, “Calibrated neighborhood aware confidence measure for deep metric learning,”arXiv preprint arXiv:2006.04935, 2020
-
[36]
Deepatash: Focused test generation for deep learning systems,
T. Zohdinasab, V . Riccio, and P. Tonella, “Deepatash: Focused test generation for deep learning systems,” inProceedings of the 32nd ACM SIGSOFT international symposium on software testing and analysis, pp. 954–966, 2023
2023
-
[37]
Robot: Robustness-oriented testing for deep learning systems,
J. Wang, J. Chen, Y . Sun, X. Ma, D. Wang, J. Sun, and P. Cheng, “Robot: Robustness-oriented testing for deep learning systems,” in2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), pp. 300–311, IEEE, 2021
2021
-
[38]
There is limited correlation between coverage and robustness for deep neural networks,
Y . Dong, P. Zhang, J. Wang, S. Liu, J. Sun, J. Hao, X. Wang, L. Wang, J. S. Dong, and D. Ting, “There is limited correlation between coverage and robustness for deep neural networks,”arXiv preprint arXiv:1911.05904, 2019
-
[39]
Is neuron coverage a meaningful measure for testing deep neural networks?,
F. Harel-Canada, L. Wang, M. A. Gulzar, Q. Gu, and M. Kim, “Is neuron coverage a meaningful measure for testing deep neural networks?,” in Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pp. 851–862, 2020
2020
-
[40]
Deepstellar: Model-based quantitative analysis of stateful deep learning systems,
X. Du, X. Xie, Y . Li, L. Ma, Y . Liu, and J. Zhao, “Deepstellar: Model-based quantitative analysis of stateful deep learning systems,” in Proceedings of the 2019 27th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering, pp. 477–487, 2019
2019
-
[41]
Testing dnn-based autonomous driving systems under critical environmental conditions,
Z. Li, M. Pan, T. Zhang, and X. Li, “Testing dnn-based autonomous driving systems under critical environmental conditions,” inInternational conference on machine learning, pp. 6471–6482, PMLR, 2021
2021
-
[42]
Deeprepair: Style-guided repairing for deep neural networks in the real-world operational environment,
B. Yu, H. Qi, Q. Guo, F. Juefei-Xu, X. Xie, L. Ma, and J. Zhao, “Deeprepair: Style-guided repairing for deep neural networks in the real-world operational environment,”IEEE Transactions on Reliability, vol. 71, no. 4, pp. 1401–1416, 2021
2021
-
[43]
Fuzz testing based data augmentation to improve robustness of deep neural networks,
X. Gao, R. K. Saha, M. R. Prasad, and A. Roychoudhury, “Fuzz testing based data augmentation to improve robustness of deep neural networks,” inProceedings of the acm/ieee 42nd international conference on software engineering, pp. 1147–1158, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.