Structure-Preserving Document Translation via Multi-Stage LLM Pipeline: A Case Study in Marathi
Pith reviewed 2026-06-30 09:56 UTC · model grok-4.3
The pith
A multi-stage pipeline translates Marathi government PDFs to English while keeping layout and hierarchy intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
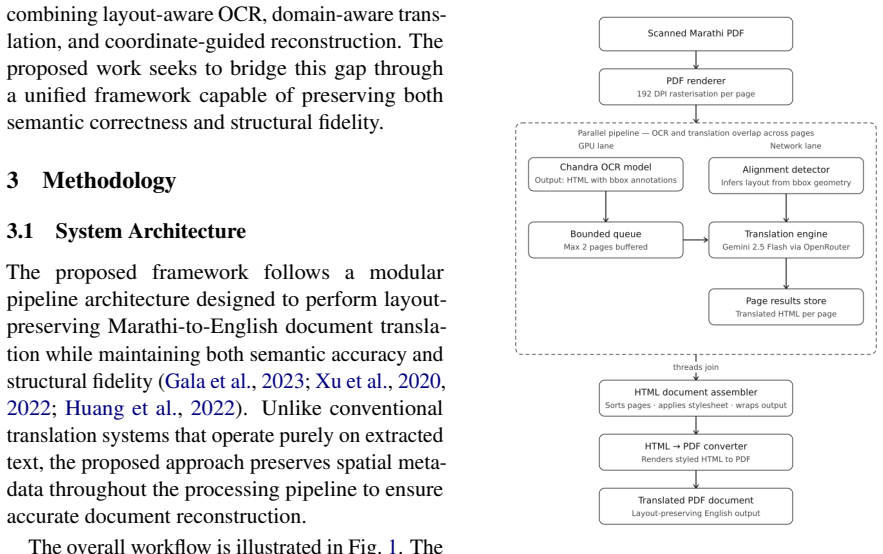
The framework performs end-to-end Marathi-to-English transformation of government documents by integrating layout-aware optical character recognition, coordinate-based text extraction, large language model translation, and HTML-based structured reconstruction, thereby maintaining structural consistency and layout fidelity between source and output.
What carries the argument
The multi-stage pipeline that combines layout-aware OCR with coordinate extraction and HTML reconstruction to enforce spatial alignment and hierarchical element preservation.
If this is right
- Translated outputs retain headings, tables, and spatial order that text-only methods lose.
- Terminology stays consistent across the document rather than varying sentence by sentence.
- The approach scales to other official document sets beyond the tested Marathi PDFs.
Where Pith is reading between the lines
- The same staged approach could apply to translation between other Indian regional languages and English.
- Output HTML files could feed directly into existing document management systems used by administrative offices.
- Error rates from OCR or translation might be reduced by feeding layout coordinates back into later pipeline stages.
Load-bearing premise
That adding spatial alignment rules and HTML hierarchy steps will keep layout fidelity and term consistency on real Marathi PDFs without large new errors from the OCR or language model stages.
What would settle it
Side-by-side measurement showing that the reconstructed HTML of a translated page deviates in element positions or ordering from the source PDF coordinates on a held-out set of government documents.
Figures


read the original abstract
Government documents in India are predominantly issued in regional languages such as Marathi, creating substantial accessibility barriers for non-native readers, interstate administrative bodies, and policy analysts. Although recent advances in neural machine translation have improved sentence-level translation quality, existing systems largely neglect document structure, formatting integrity, and domain-specific terminology, thereby limiting their applicability to official documentation. This paper presents a structure-preserving Marathi-to-English government document translation framework capable of performing end-to-end document transformation while maintaining layout fidelity. The proposed system integrates layout-aware optical character recognition, coordinate-based text extraction, large language model based translation, and structured document reconstruction through HTML representations. By enforcing spatial alignment constraints and preserving hierarchical document elements, the framework ensures structural consistency between the source and translated documents. Experimental evaluation on real-world Marathi government PDFs demonstrates improved structural preservation, translation coherence, and terminological consistency compared to conventional text-only translation pipelines. The proposed framework contributes toward scalable multilingual accessibility solutions for e-governance and administrative document processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-stage pipeline for Marathi-to-English translation of government documents that aims to preserve layout and structure. The system combines layout-aware OCR, coordinate-based text extraction, LLM-based translation, and HTML-based document reconstruction to enforce spatial alignment and hierarchical element preservation. The authors assert that experimental evaluation on real-world Marathi government PDFs shows improved structural preservation, translation coherence, and terminological consistency relative to text-only baselines.
Significance. If the quantitative claims hold under rigorous evaluation, the work addresses a practically important gap in document-level machine translation for low-resource official languages, with direct relevance to e-governance accessibility in India. The HTML reconstruction approach is a pragmatic engineering choice that could generalize beyond the Marathi case study.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation section: The abstract states that the pipeline 'demonstrates improved structural preservation' yet supplies no quantitative metrics (e.g., element-position IoU, table-structure F1, or layout deviation scores), no baselines, no ablation isolating the reconstruction stage, and no error analysis of OCR/LLM propagation. This absence directly undermines the central claim that coordinate-based extraction plus HTML reconstruction reliably maintains fidelity on real PDFs.
- [Method] Method description (pipeline stages): The claim that 'enforcing spatial alignment constraints' ensures consistency is load-bearing, but the manuscript provides no concrete bound on acceptable OCR coordinate error or LLM term-substitution rates, nor any metric that directly quantifies post-reconstruction layout deviation. Without these, the assumption that the pipeline keeps errors below the threshold that breaks alignment cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address each major comment below and commit to revisions that will strengthen the quantitative support for our claims.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation section: The abstract states that the pipeline 'demonstrates improved structural preservation' yet supplies no quantitative metrics (e.g., element-position IoU, table-structure F1, or layout deviation scores), no baselines, no ablation isolating the reconstruction stage, and no error analysis of OCR/LLM propagation. This absence directly undermines the central claim that coordinate-based extraction plus HTML reconstruction reliably maintains fidelity on real PDFs.
Authors: We agree that the manuscript would be strengthened by including quantitative metrics for structural preservation. In the revised version, we will incorporate metrics such as element-position IoU, table-structure F1, and layout deviation scores. We will also include comparisons to text-only baselines, an ablation study isolating the HTML reconstruction stage, and an error analysis detailing OCR and LLM error propagation. These additions will provide rigorous evidence for the pipeline's performance on real PDFs. revision: yes
-
Referee: [Method] Method description (pipeline stages): The claim that 'enforcing spatial alignment constraints' ensures consistency is load-bearing, but the manuscript provides no concrete bound on acceptable OCR coordinate error or LLM term-substitution rates, nor any metric that directly quantifies post-reconstruction layout deviation. Without these, the assumption that the pipeline keeps errors below the threshold that breaks alignment cannot be assessed.
Authors: We recognize the importance of providing concrete bounds and metrics to support the method's claims. The revised manuscript will specify acceptable bounds on OCR coordinate errors derived from our layout-aware OCR implementation, report LLM term-substitution rates observed in our experiments, and introduce a metric to quantify post-reconstruction layout deviation. This will allow readers to evaluate whether errors remain below thresholds that affect alignment. revision: yes
Circularity Check
No significant circularity; claims rest on system description and external experimental evaluation
full rationale
The paper describes a multi-stage pipeline (layout-aware OCR, coordinate extraction, LLM translation, HTML reconstruction) and asserts structural consistency via spatial alignment and hierarchical preservation. These are engineering choices evaluated experimentally on real PDFs, with no equations, fitted parameters, self-definitional loops, or load-bearing self-citations visible. The central claims do not reduce to inputs by construction; they are presented as outcomes of the described process and comparative tests. This is the normal case of a non-circular system paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [6]
-
[7]
Raviraj Joshi. 2022 a . L3cube-mahacorpus and mahabert: Marathi monolingual corpus, marathi bert language models, and resources. In Proceedings of the WILDRE-6 workshop within the 13th language resources and evaluation conference, pages 97--101
2022
-
[10]
R. Smith. 2007. https://doi.org/10.1109/ICDAR.2007.4376991 An overview of the tesseract ocr engine . volume 2, pages 629 -- 633
-
[21]
Gala, Jay and Chitale, Pranjal A. and AK, Raghavan and Gumma, Varun and Doddapaneni, Sumanth and Kumar, Aswanth and Nawale, Janki and Sujatha, Anupama and Puduppully, Ratish and Raghavan, Vivek and Kumar, Pratyush and Khapra, Mitesh M. and Dabre, Raj and Kunchukuttan, Anoop , month = dec, year =. doi:10.48550/arXiv.2305.16307 , abstract =
-
[22]
, year =
Smith, R. , year =. An Overview of the Tesseract OCR Engine , volume =. Ninth International Conference on Document Analysis and Recognition (ICDAR 2007) , doi =
2007
-
[23]
Team, NLLB and Costa-jussà, Marta R. and Cross, James and Çelebi, Onur and Elbayad, Maha and Heafield, Kenneth and Heffernan, Kevin and Kalbassi, Elahe and Lam, Janice and Licht, Daniel and Maillard, Jean and Sun, Anna and Wang, Skyler and Wenzek, Guillaume and Youngblood, Al and Akula, Bapi and Barrault, Loic and Gonzalez, Gabriel Mejia and Hansanti, Pra...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.04672
-
[24]
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , month = aug, year =. Attention. doi:10.48550/arXiv.1706.03762 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762
-
[25]
Fan, Angela and Bhosale, Shruti and Schwenk, Holger and Ma, Zhiyi and El-Kishky, Ahmed and Goyal, Siddharth and Baines, Mandeep and Celebi, Onur and Wenzek, Guillaume and Chaudhary, Vishrav and Goyal, Naman and Birch, Tom and Liptchinsky, Vitaliy and Edunov, Sergey and Grave, Edouard and Auli, Michael and Joulin, Armand , year =. Beyond. doi:10.48550/ARXI...
-
[26]
LLaMA: Open and Efficient Foundation Language Models
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timothée and Rozière, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and Rodriguez, Aurelien and Joulin, Armand and Grave, Edouard and Lample, Guillaume , month = feb, year =. doi:10.48550/arXiv.2302.13971 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971
-
[27]
Zhao, Wayne Xin and Zhou, Kun and Li, Junyi and Tang, Tianyi and Wang, Xiaolei and Hou, Yupeng and Min, Yingqian and Zhang, Beichen and Zhang, Junjie and Dong, Zican and Du, Yifan and Yang, Chen and Chen, Yushuo and Chen, Zhipeng and Jiang, Jinhao and Ren, Ruiyang and Li, Yifan and Tang, Xinyu and Liu, Zikang and Liu, Peiyu and Nie, Jian-Yun and Wen, Ji-R...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.18223
-
[28]
doi:10.48550/arXiv.1912.13318 , abstract =
Xu, Yiheng and Li, Minghao and Cui, Lei and Huang, Shaohan and Wei, Furu and Zhou, Ming , month = jun, year =. doi:10.48550/arXiv.1912.13318 , abstract =
-
[29]
Layoutlmv3: Pre-training for document ai with unified text and image masking,
Huang, Yupan and Lv, Tengchao and Cui, Lei and Lu, Yutong and Wei, Furu , month = jul, year =. doi:10.48550/arXiv.2204.08387 , abstract =
-
[30]
Appalaraju, Srikar and Jasani, Bhavan and Kota, Bhargava Urala and Xie, Yusheng and Manmatha, R. , month = sep, year =. doi:10.48550/arXiv.2106.11539 , abstract =
-
[31]
doi:10.48550/arXiv.2104.08836 , abstract =
Xu, Yiheng and Lv, Tengchao and Cui, Lei and Wang, Guoxin and Lu, Yijuan and Florencio, Dinei and Zhang, Cha and Wei, Furu , month = sep, year =. doi:10.48550/arXiv.2104.08836 , abstract =
-
[32]
Can you see the mark on the document? This means it is important, enhance the content inside
Zhong, Xu and Tang, Jianbin and Yepes, Antonio Jimeno , month = aug, year =. doi:10.48550/arXiv.1908.07836 , abstract =
-
[33]
Wang, Xinlong and Wang, Wen and Cao, Yue and Shen, Chunhua and Huang, Tiejun , month = mar, year =. Images. doi:10.48550/arXiv.2212.02499 , abstract =
-
[34]
doi:10.48550/arXiv.2012.14740 , abstract =
Xu, Yang and Xu, Yiheng and Lv, Tengchao and Cui, Lei and Wei, Furu and Wang, Guoxin and Lu, Yijuan and Florencio, Dinei and Zhang, Cha and Che, Wanxiang and Zhang, Min and Zhou, Lidong , month = jan, year =. doi:10.48550/arXiv.2012.14740 , abstract =
-
[35]
Li, Tao and Srikumar, Vivek , month = aug, year =. Augmenting. doi:10.48550/arXiv.1906.06298 , abstract =
-
[36]
Xiao, Tete and Singh, Mannat and Mintun, Eric and Darrell, Trevor and Dollár, Piotr and Girshick, Ross , month = oct, year =. Early. doi:10.48550/arXiv.2106.14881 , abstract =
-
[37]
Baek, Jeonghun and Kim, Geewook and Lee, Junyeop and Park, Sungrae and Han, Dongyoon and Yun, Sangdoo and Oh, Seong Joon and Lee, Hwalsuk , month = dec, year =. What. doi:10.48550/arXiv.1904.01906 , abstract =
-
[38]
arXiv.org , author=
On limitations of LLM as Annotator for Low Resource Languages , url=. arXiv.org , author=. 2025 , month=
2025
-
[39]
arXiv preprint arXiv:2205.14728 , year=
L3cube-mahanlp: Marathi natural language processing datasets, models, and library , author=. arXiv preprint arXiv:2205.14728 , year=
-
[40]
Proceedings of the WILDRE-6 workshop within the 13th language resources and evaluation conference , pages=
L3cube-mahacorpus and mahabert: Marathi monolingual corpus, marathi bert language models, and resources , author=. Proceedings of the WILDRE-6 workshop within the 13th language resources and evaluation conference , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.