A Stereo Visual SLAM System Using Object-Level Motion Estimation and Geometric Filtering Based on Cross Disparity
Pith reviewed 2026-07-03 11:56 UTC · model grok-4.3
The pith
OCD SLAM detects dynamic features via cross disparity discrepancy and pairs it with object tracking to raise trajectory accuracy in moving scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
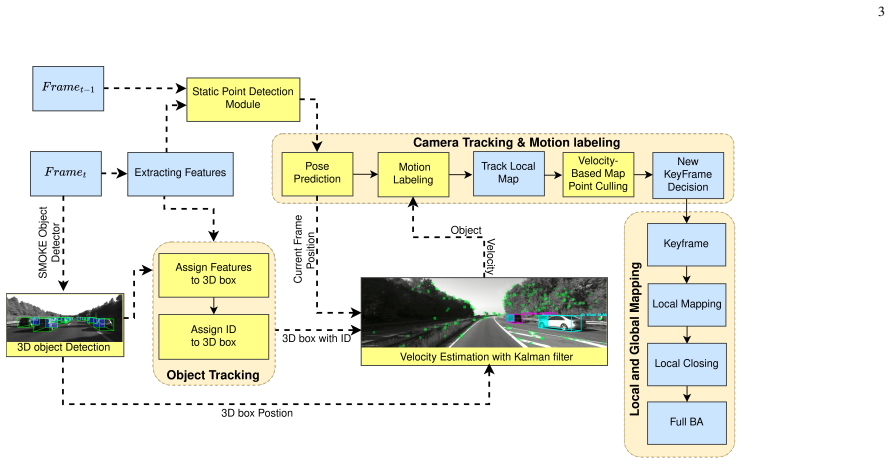
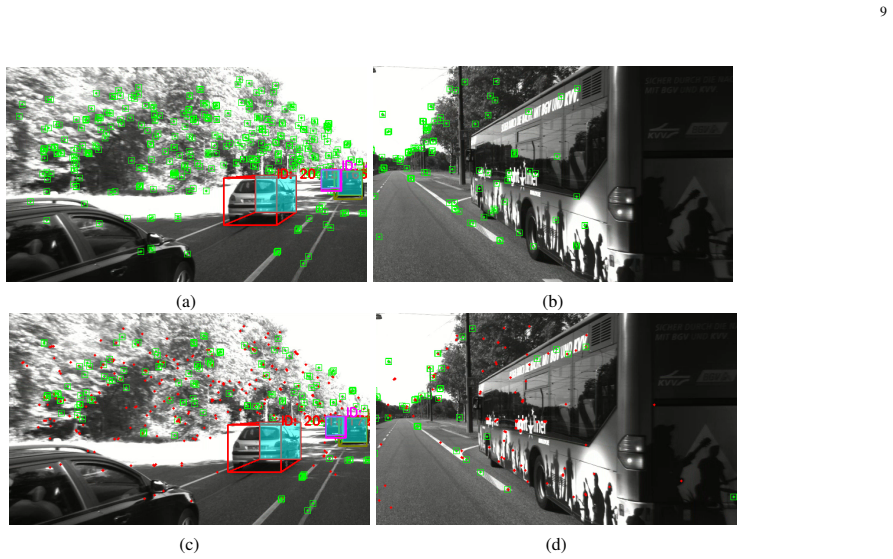
The central claim is that the discrepancy between standard disparity and cross disparity reliably isolates dynamic feature points, and that this geometric signal combined with object-level classification from SMOKE detection and Kalman tracking produces a clean static map for accurate pose estimation in dynamic environments.
What carries the argument
Cross disparity, the quantity that exploits simultaneous temporal and stereo inconsistency to identify dynamic feature points, operating alongside object-level motion classification.
If this is right
- Pose estimation remains stable when vehicles or pedestrians cross the camera view.
- Feature points missed by the object detector can still be removed by the geometric filter.
- Trajectory accuracy improves on both odometry and raw KITTI sequences that contain traffic.
- Ablation results isolate the cross disparity module as the component that recovers dynamic points the detector overlooks.
Where Pith is reading between the lines
- The same cross disparity test could be adapted to other stereo or RGB-D SLAM pipelines that already compute disparity.
- In scenes dominated by small or distant movers the object detector may need higher resolution input for the two layers to stay complementary.
- Replacing the Kalman tracker with a learned motion model might further reduce latency in real-time operation.
Load-bearing premise
The difference between disparity and cross disparity correctly marks only dynamic points without creating false positives that would degrade the pose solver, and the object detector plus tracker labels entire objects without missing or misclassifying relevant movers.
What would settle it
On KITTI sequences containing moving vehicles, if the absolute trajectory error of OCD SLAM exceeds that of ORB-SLAM2, the claimed accuracy gain would be refuted.
Figures




read the original abstract
This paper presents OCD SLAM, a dynamic stereo visual SLAM framework that extends ORB-SLAM2 by jointly addressing dynamic objects and dynamic features in the scene. Usual visual SLAM systems operating in dynamic environments often fail in the presence of moving objects, due to the static-world assumption used in pose estimation and mapping. To address this predicament, we introduce a novel geometric approach based on the discrepancy between disparity and a newly proposed notion called ``cross disparity'', which exploits both temporal and stereo inconsistency to identify dynamic feature points. Complementary to this feature-level motion analysis, OCD SLAM integrates a 3D object detection module (SMOKE) with Kalman filter-based object tracking to perform object-level motion classification, enabling robust separation of static and dynamic scene elements for accurate pose estimation. The proposed approach has been evaluated on various sequences from the KITTI Odometry and KITTI Raw datasets. Results demonstrate that OCD SLAM achieves significant improvement in trajectory accuracy compared to ORB-SLAM2 and several state-of-the-art dynamic SLAM methods. Ablation studies further demonstrate the effectiveness of the cross disparity module in the KITTI Raw dataset and show that this method is able to detect dynamic features that are missed by the 3D object detection scheme alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OCD SLAM, a stereo visual SLAM system extending ORB-SLAM2 for dynamic environments. It introduces a geometric filter based on the discrepancy between standard disparity and a proposed 'cross disparity' to detect dynamic feature points via temporal-stereo inconsistency, complemented by SMOKE 3D object detection and Kalman-filter object tracking for object-level static/dynamic classification. The central claim is that this yields significant trajectory accuracy improvements over ORB-SLAM2 and other dynamic SLAM methods on KITTI Odometry and KITTI Raw sequences, with ablations confirming the cross-disparity module's value in detecting features missed by object detection alone.
Significance. If the cross-disparity filter reliably separates dynamic features without excessive false positives on static geometry, the method offers a lightweight, geometry-driven complement to learning-based object detection in stereo SLAM. The joint feature-level and object-level motion handling is a constructive integration. However, the absence of reported quantitative trajectory errors, inlier statistics, or false-positive rates against ground truth leaves the practical significance difficult to gauge from the abstract alone.
major comments (2)
- [Abstract] Abstract: The claim of 'significant improvement in trajectory accuracy' is stated without any numerical values, error bars, sequence-specific ATE/RPE figures, or comparison tables. This omission makes the central empirical claim impossible to evaluate for magnitude or statistical reliability.
- [Experiments / Ablation studies] Experiments / Ablation studies (KITTI Raw): No per-sequence false-positive rates for the cross-disparity test against ground-truth dynamic labels, nor before/after inlier counts or pose-estimation error deltas, are reported. Without these, it is impossible to confirm that the discrepancy test isolates dynamic points without discarding usable static features under ego-motion parallax, directly undermining the load-bearing assumption for the reported accuracy gains.
minor comments (1)
- [Abstract] The abstract mentions evaluation on 'various sequences' but does not list which ones or exclusion criteria; adding this would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify how to better present our empirical claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of 'significant improvement in trajectory accuracy' is stated without any numerical values, error bars, sequence-specific ATE/RPE figures, or comparison tables. This omission makes the central empirical claim impossible to evaluate for magnitude or statistical reliability.
Authors: We agree that the abstract should include concrete quantitative support for the central claim. The full manuscript already contains per-sequence ATE/RPE tables (Tables I and II) comparing OCD SLAM against ORB-SLAM2 and other dynamic SLAM methods on KITTI Odometry. We will revise the abstract to cite the key aggregate improvements, for example the average ATE reduction on dynamic sequences. revision: yes
-
Referee: [Experiments / Ablation studies] Experiments / Ablation studies (KITTI Raw): No per-sequence false-positive rates for the cross-disparity test against ground-truth dynamic labels, nor before/after inlier counts or pose-estimation error deltas, are reported. Without these, it is impossible to confirm that the discrepancy test isolates dynamic points without discarding usable static features under ego-motion parallax, directly undermining the load-bearing assumption for the reported accuracy gains.
Authors: KITTI Raw sequences do not provide ground-truth dynamic object labels, so per-sequence false-positive rates against GT cannot be computed. We therefore rely on trajectory-level ablations (with/without the cross-disparity module) and qualitative results to demonstrate that the filter improves accuracy without harming static geometry. We can add before/after inlier counts from our existing experiments to the ablation section if they are not already tabulated. revision: partial
Circularity Check
No circularity: new cross-disparity definition and object integration are independent of inputs
full rationale
The paper defines a new geometric quantity called cross disparity to detect dynamic points via temporal-stereo inconsistency and combines it with an off-the-shelf 3D detector (SMOKE) plus Kalman tracking for object-level classification. No equations, fitted parameters, or self-citations are shown that would make the reported accuracy gains equivalent to the input data by construction. The KITTI evaluations constitute external benchmarks, and the method is presented as an extension rather than a renaming or self-referential loop. The derivation chain remains self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,
R. Mur-Artal and J. D. Tard ´os, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,”IEEE Transactions on Robotics, vol. 33, no. 5, pp. 1255–1262, 2017
2017
-
[2]
Direct sparse odometry,
J. J. Engel, V . Koltun, and D. Cremers, “Direct sparse odometry,”
-
[3]
[Online]. Available: http://arxiv.org/abs/1607.02565
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Lsd-slam: Large-scale direct monocular slam,
J. Engel, T. Sch ¨ops, and D. Cremers, “Lsd-slam: Large-scale direct monocular slam,” inComputer Vision – ECCV 2014, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds. Cham: Springer International Publishing, 2014, pp. 834–849
2014
-
[5]
An evaluation of the rgb-d slam system,
F. Endres, J. Hess, N. Engelhard, J. Sturm, D. Cremers, and W. Burgard, “An evaluation of the rgb-d slam system,” in2012 IEEE International Conference on Robotics and Automation, 2012, pp. 1691–1696
2012
-
[6]
Smoke: Single-stage monocular 3d object detection via keypoint estimation,
Z. Liu, Z. Wu, and R. T ´oth, “Smoke: Single-stage monocular 3d object detection via keypoint estimation,” 2020. [Online]. Available: https://arxiv.org/abs/2002.10111
-
[7]
Are we ready for autonomous driving? the kitti vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” inConference on Computer Vision and Pattern Recognition (CVPR), 2012
2012
-
[8]
Vision meets robotics: The kitti dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,”International Journal of Robotics Research (IJRR), 2013
2013
-
[9]
Rgb-d slam in dynamic environments using static point weighting,
S. Li and D. Lee, “Rgb-d slam in dynamic environments using static point weighting,”IEEE Robotics and Automation Letters, vol. 2, no. 4, pp. 2263–2270, 2017
2017
-
[10]
Fast visual odometry using intensity-assisted iterative closest point,
L. Shile and L. Dongheui, “Fast visual odometry using intensity-assisted iterative closest point,”IEEE Robotics and Automation Letters, vol. 1, no. 2, pp. 992–999, 2016
2016
-
[11]
Mvs- slam: Enhanced multiview geometry for improved semantic rgbd slam in dynamic environment,
Q. U. Islam, H. Ibrahim, P. K. Chin, K. Lim, and M. Z. Abdullah, “Mvs- slam: Enhanced multiview geometry for improved semantic rgbd slam in dynamic environment,”Journal of Field Robotics, vol. 41, no. 1, pp. 109–130, 2024
2024
-
[12]
Robust monocular slam in dynamic environments,
W. Tan, H. Liu, Z. Dong, G. Zhang, and H. Bao, “Robust monocular slam in dynamic environments,” in2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), 2013, pp. 209–218
2013
-
[13]
Rgb-d slam in dynamic environments using point correlations,
W. Dai, Y . Zhang, P. Li, Z. Fang, and S. Scherer, “Rgb-d slam in dynamic environments using point correlations,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 1, pp. 373–389, 2022
2022
-
[14]
Improving rgb-d slam in dynamic environments: A motion removal approach,
Y . Sun, M. Liu, and M. Q.-H. Meng, “Improving rgb-d slam in dynamic environments: A motion removal approach,”Robotics and Autonomous Systems, vol. 89, pp. 110–122, 2017
2017
-
[15]
Stat- icfusion: Background reconstruction for dense rgb-d slam in dynamic environments,
R. Scona, M. Jaimez, Y . R. Petillot, M. Fallon, and D. Cremers, “Stat- icfusion: Background reconstruction for dense rgb-d slam in dynamic environments,” in2018 IEEE International Conference on Robotics and Automation (ICRA), 2018, pp. 3849–3856
2018
-
[16]
Mask- slam: Robust feature-based monocular slam by masking using semantic segmentation,
M. Kaneko, K. Iwami, T. Ogawa, T. Yamasaki, and K. Aizawa, “Mask- slam: Robust feature-based monocular slam by masking using semantic segmentation,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Los Alamitos, CA, USA: IEEE Computer Society, Jun. 2018, pp. 371–3718
2018
-
[17]
Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,
L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 4, pp. 834–848, 2018
2018
-
[18]
A mobile robot visual slam system with enhanced semantics segmentation,
F. Li, W. Chen, W. Xu, L. Huang, D. Li, S. Cai, M. Yang, X. Xiong, Y . Liu, and W. Li, “A mobile robot visual slam system with enhanced semantics segmentation,”IEEE Access, vol. 8, pp. 25 442–25 458, 2020
2020
-
[19]
Detect-slam: Making object detection and slam mutually beneficial,
F. Zhong, S. Wang, Z. Zhang, C. Chen, and Y . Wang, “Detect-slam: Making object detection and slam mutually beneficial,” in2018 IEEE Winter Conference on Applications of Computer Vision (WACV), 2018, pp. 1001–1010
2018
-
[20]
Rds-slam: Real-time dynamic slam using semantic segmentation methods,
Y . Liu and J. Miura, “Rds-slam: Real-time dynamic slam using semantic segmentation methods,”IEEE Access, vol. 9, pp. 23 772–23 785, 2021
2021
-
[21]
Dp-slam: A visual slam with moving probability towards dynamic environments,
A. Li, J. Wang, M. Xu, and Z. Chen, “Dp-slam: A visual slam with moving probability towards dynamic environments,”Information Sciences, vol. 556, pp. 128–142, 2021
2021
-
[22]
Network uncertainty informed semantic feature selection for visual slam,
P. Ganti and S. L. Waslander, “Network uncertainty informed semantic feature selection for visual slam,” in2019 16th Conference on Computer and Robot Vision (CRV), 2019, pp. 121–128
2019
-
[23]
Ds- slam: A semantic visual slam towards dynamic environments,
C. Yu, Z. Liu, X.-J. Liu, F. Xie, Y . Yang, Q. Wei, and Q. Fei, “Ds- slam: A semantic visual slam towards dynamic environments,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018, pp. 1168–1174
2018
-
[24]
Segnet: A deep con- volutional encoder-decoder architecture for image segmentation,
V . Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep con- volutional encoder-decoder architecture for image segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, pp. 2481–2495, 2015
2015
-
[25]
Dynamic slam: A visual slam in outdoor dynamic scenes,
S. Wen, X. Li, X. Liu, J. Li, S. Tao, Y . Long, and T. Qiu, “Dynamic slam: A visual slam in outdoor dynamic scenes,”IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1–11, 2023
2023
-
[26]
Dynaslam: Tracking, mapping, and inpainting in dynamic scenes,
B. Bescos, J. M. F ´acil, J. Civera, and J. Neira, “Dynaslam: Tracking, mapping, and inpainting in dynamic scenes,”IEEE Robotics and Au- tomation Letters, vol. 3, no. 4, pp. 4076–4083, 2018
2018
-
[27]
Mask R-CNN,
K. He, G. Gkioxari, P. Doll ´ar, and R. B. Girshick, “Mask R-CNN,”
-
[28]
[Online]. Available: http://arxiv.org/abs/1703.06870
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Trifocal slam: A dynamic slam based on three frame views,
S. K. Dhali and B. Dasgupta, “Trifocal slam: A dynamic slam based on three frame views,”Neurocomputing, vol. 652, p. 130993, 2025
2025
-
[30]
M. Yaseen, “What is yolov8: An in-depth exploration of the internal features of the next-generation object detector,” 2024. [Online]. Available: https://arxiv.org/abs/2408.15857
-
[31]
Airdos: Dynamic slam benefits from articulated objects,
Y . Qiu, C. Wang, W. Wang, M. Henein, and S. A. Scherer, “Airdos: Dynamic slam benefits from articulated objects,”2022 International Conference on Robotics and Automation (ICRA), pp. 8047–8053, 2021
2022
-
[32]
Dgs-slam: A fast and robust rgbd slam in dynamic environments combined by geometric and semantic information,
L. Yan, X. Hu, L. Zhao, Y . Chen, P. Wei, and H. Xie, “Dgs-slam: A fast and robust rgbd slam in dynamic environments combined by geometric and semantic information,”Remote Sensing, vol. 14, no. 3, 2022
2022
-
[33]
Yolact++ better real- time instance segmentation,
D. Bolya, C. Zhou, F. Xiao, and Y . J. Lee, “Yolact++ better real- time instance segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 2, pp. 1108–1121, 2022
2022
-
[34]
Rso-slam: A robust semantic visual slam with optical flow in complex dynamic en- vironments,
L. Qin, C. Wu, Z. Chen, X. Kong, Z. Lv, and Z. Zhao, “Rso-slam: A robust semantic visual slam with optical flow in complex dynamic en- vironments,”IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 10, pp. 14 669–14 684, 2024
2024
-
[35]
What is yolov5: A deep look into the internal features of the popular object detector,
R. Khanam and M. Hussain, “What is yolov5: A deep look into the internal features of the popular object detector,” 2024. [Online]. Available: https://arxiv.org/abs/2407.20892
-
[36]
A semantic slam-based dense mapping approach for large-scale dynamic outdoor environment,
L. Yang and L. Wang, “A semantic slam-based dense mapping approach for large-scale dynamic outdoor environment,”Measurement, vol. 204, p. 112001, 2022
2022
-
[37]
Rethinking Atrous Convolution for Semantic Image Segmentation
L. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking atrous convolution for semantic image segmentation,” 2017. [Online]. Available: http://arxiv.org/abs/1706.05587
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
S2r-depthnet: Learning a generalizable depth-specific structural representation,
X. Chen, Y . Wang, X. Chen, and W. Zeng, “S2r-depthnet: Learning a generalizable depth-specific structural representation,” 2021. [Online]. Available: https://arxiv.org/abs/2104.00877
-
[39]
Drv-slam: An adaptive real-time semantic visual slam based on instance segmentation toward dynamic environments,
Q. Ji, Z. Zhang, Y . Chen, and E. Zheng, “Drv-slam: An adaptive real-time semantic visual slam based on instance segmentation toward dynamic environments,”IEEE Access, vol. 12, pp. 43 827–43 837, 2024
2024
-
[41]
Available: https://arxiv.org/abs/2005.11052
[Online]. Available: https://arxiv.org/abs/2005.11052
-
[42]
Dgm- vins: Visual–inertial slam for complex dynamic environments with joint geometry feature extraction and multiple object tracking,
B. Song, X. Yuan, Z. Ying, B. Yang, Y . Song, and F. Zhou, “Dgm- vins: Visual–inertial slam for complex dynamic environments with joint geometry feature extraction and multiple object tracking,”IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1–11, 2023
2023
-
[43]
X. Zhou, D. Wang, and P. Kr ¨ahenb¨uhl, “Objects as points,”CoRR, vol. abs/1904.07850, 2019. [Online]. Available: http://arxiv.org/abs/1904. 07850
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[44]
Deep layer aggregation,
F. Yu, D. Wang, E. Shelhamer, and T. Darrell, “Deep layer aggregation,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
2018
-
[45]
Dynaslam ii: Tightly- coupled multi-object tracking and slam,
B. Besc ´os, C. Campos, J. D. Tard´os, and J. Neira, “Dynaslam ii: Tightly- coupled multi-object tracking and slam,”IEEE Robotics and Automation Letters, vol. 6, pp. 5191–5198, 2020
2020
-
[46]
Stereo vision-based semantic 3d object and ego-motion tracking for autonomous driving,
P. Li, T. Qin, Shen, and Shaojie, “Stereo vision-based semantic 3d object and ego-motion tracking for autonomous driving,” inProceedings of the European Conference on Computer Vision (ECCV), September 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.