Just how sure are you? Improving Verbalized Uncertainty Calibration in Medical VQA
Pith reviewed 2026-06-26 05:33 UTC · model grok-4.3
The pith
A composite loss with contrastive alignment from 2x2 image-text perturbations calibrates verbalized uncertainty in medical VQA models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
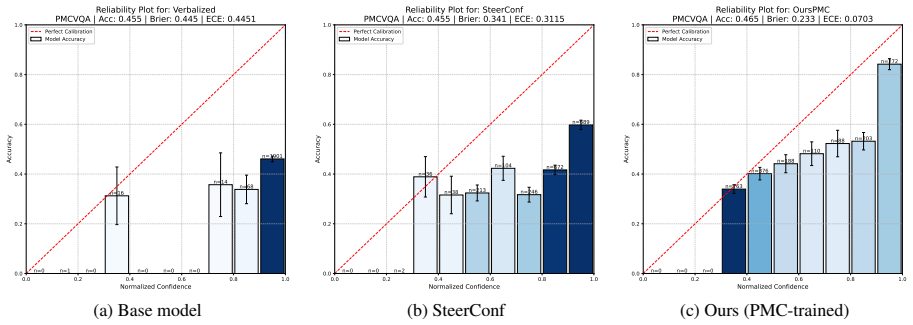
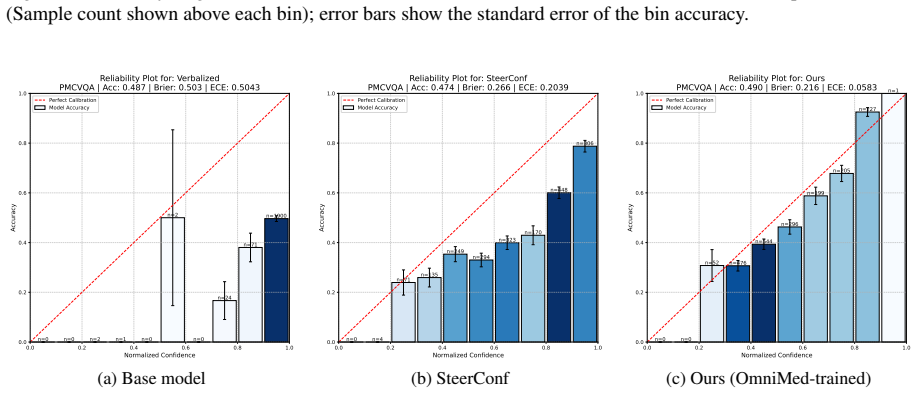
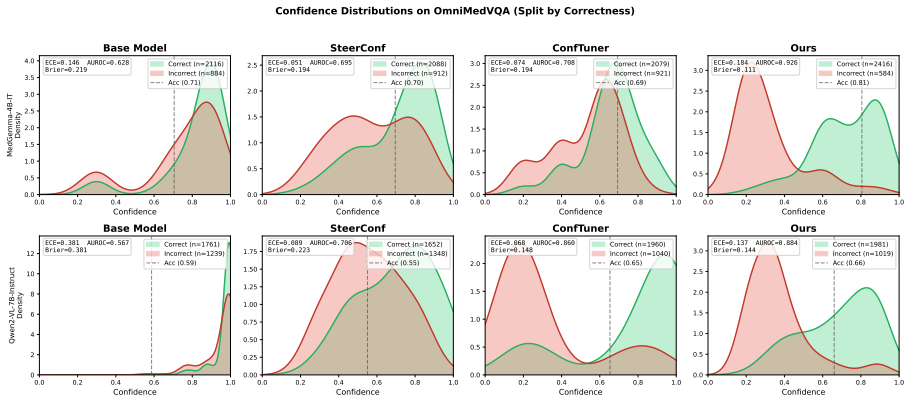
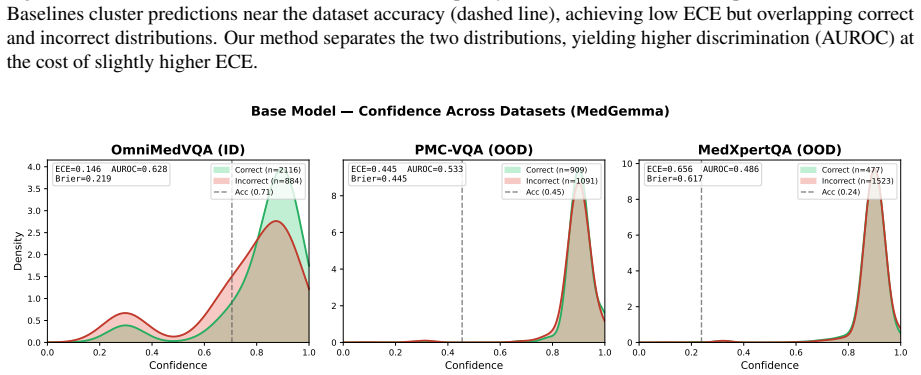
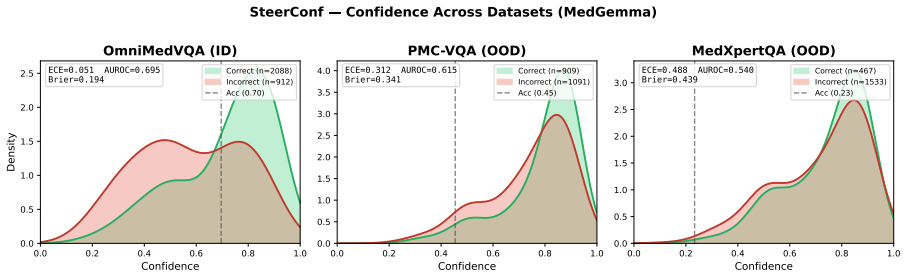
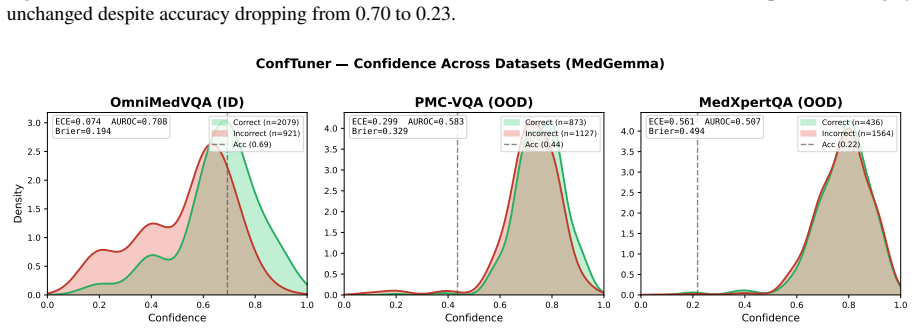
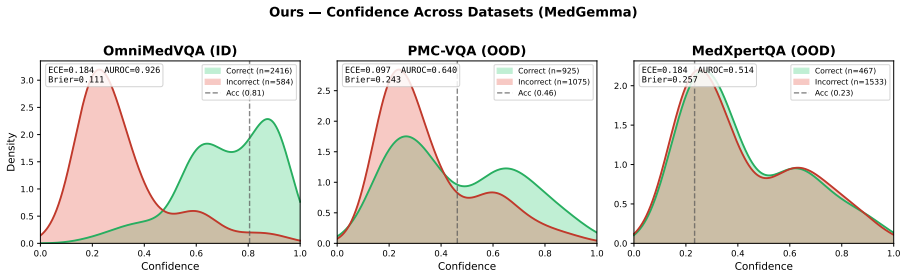
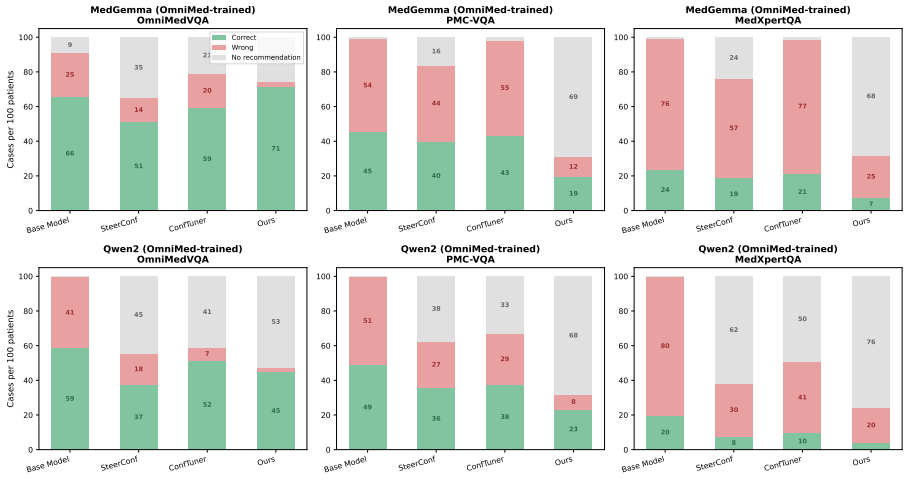
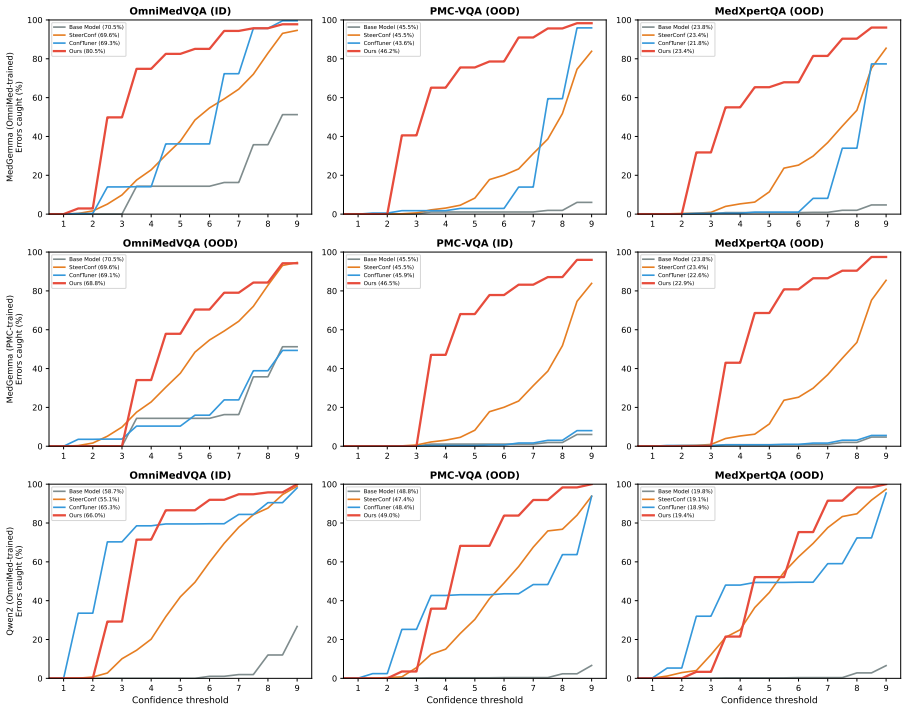
Finetuning MLLMs with a composite loss function that includes a Brier-style calibration term, an anchor regularizer, a contrastive image-text alignment term derived from a 2x2 factorial perturbation design crossing image presence with text integrity, and a KL-based stabilization term reduces calibration error by 60 percent or more and improves discrimination by 26 percent or more on three Medical VQA benchmarks for both MedGemma 4B IT and Qwen2 VL 7B Instruct, while preserving predictive accuracy and outperforming prompting-based, sampling-based, and other training-based methods.
What carries the argument
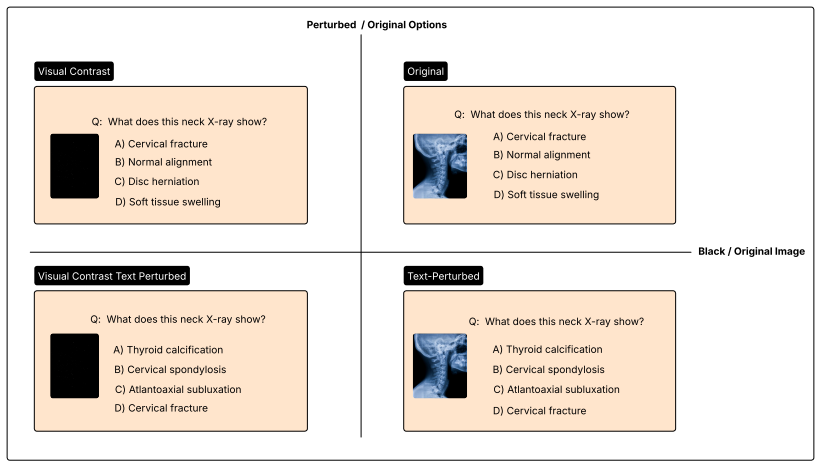
The 2x2 factorial perturbation design crossing image presence with text integrity, used to derive the contrastive image-text alignment signal in the loss.
If this is right
- Each component of the composite loss is necessary, as confirmed by ablation experiments.
- The method outperforms existing prompting, sampling, and training approaches on average across the benchmarks.
- Predictive accuracy on the medical VQA tasks remains unchanged after finetuning.
- The gains hold for two different model architectures on three separate benchmarks.
Where Pith is reading between the lines
- The perturbation-based alignment signal could be adapted to probe modality reliance in other multimodal medical tasks such as report generation.
- Better calibrated verbalized uncertainty might allow downstream systems to defer to human experts more reliably when model confidence is low.
- The anchor regularizer preventing confidence collapse may prove useful in calibration efforts for non-medical multimodal models as well.
Load-bearing premise
The 2x2 factorial perturbation design isolates the model's reliance on visual input versus language priors so the contrastive alignment term can be derived effectively.
What would settle it
Re-running the finetuning on the same benchmarks after removing the contrastive alignment term from the loss and checking whether the reported 60 percent calibration error reduction disappears.
Figures

read the original abstract
Multimodal large language models (MLLMs) applied to Medical Visual Question Answering (VQA) tend to produce overconfident outputs regardless of actual correctness, and existing verbalized confidence calibration methods, developed primarily for text only LLMs, do not account for the multimodal nature of medical image understanding. This work proposes a training based framework that finetunes MLLMs to improve their calibration using a composite loss function combining a Brier style calibration term, an anchor regularizer that prevents confidence collapse toward extreme values, a contrastive image text alignment term, and a KL based model stabilization term. The alignment signal is derived from a $2 \times 2$ factorial perturbation design that crosses image presence with text integrity, probing the reliance of the model on visual modality input versus language priors. Finally, a top K KL divergence regularizer is used to protect the answering ability of the model during finetuning. Across three Medical VQA benchmarks and two architectures (MedGemma 4B IT and Qwen2 VL 7B Instruct), our method reduces calibration error by 60% or more, and improves discrimination by 26% or more, while preserving predictive accuracy. On average across benchmarks, the technique outperforms prompting based, sampling based, and training based approaches, and ablation experiments confirm that each component of the loss function is indeed necessary for improving the calibration. All code for the experiments is publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a finetuning framework for calibrating verbalized uncertainty in MLLMs for medical VQA. It employs a composite loss with a Brier-style calibration term, an anchor regularizer to avoid collapse, a contrastive image-text alignment term derived from a 2×2 factorial perturbation (image presence crossed with text integrity), a KL stabilization term, and a top-K KL regularizer to preserve accuracy. On three Medical VQA benchmarks with MedGemma 4B IT and Qwen2 VL 7B Instruct, the method reports ≥60% reduction in calibration error and ≥26% gain in discrimination while maintaining predictive accuracy, outperforming prompting, sampling, and other training baselines; ablations indicate each loss component is necessary. Code is released publicly.
Significance. If the quantitative gains are robust, the work would meaningfully improve reliability of MLLMs in safety-critical medical settings by addressing overconfidence. The public code is a clear strength for reproducibility. The central empirical claim depends on the contrastive term providing a clean training signal, which in turn rests on the 2×2 design successfully isolating visual-modality reliance.
major comments (3)
- [Method (contrastive term derivation)] Method section (contrastive alignment term): the 2×2 perturbation design is presented as isolating visual vs. language-prior reliance to derive the contrastive term, yet no quantitative validation is supplied (e.g., correlation with independent visual-attention metrics, statistical test that the four cells differ only on the intended axis, or ablation of prompt/token-length confounds). Without this check the term reduces to a standard regularizer and the reported 60%+ calibration gains cannot be confidently attributed to modality-specific alignment.
- [Results (benchmark tables)] Results section and tables: the abstract and main claims state ≥60% calibration-error reduction and ≥26% discrimination improvement across benchmarks, but no error bars, dataset sizes, exact metric definitions (e.g., which calibration error variant), or statistical tests are reported. This directly limits the strength of evidence for the headline quantitative improvements.
- [Ablation studies] Ablation experiments: while the text states that ablations confirm necessity of each loss component, the same absence of error bars or variance estimates makes it impossible to judge whether observed differences exceed experimental noise, weakening the claim that every term is required.
minor comments (2)
- [Method] Clarify the precise mathematical form of the 'top K KL divergence regularizer' and the anchor regularizer with equations, as the current prose description leaves implementation details ambiguous.
- [Evaluation metrics] Ensure all metric names (calibration error, discrimination) receive explicit definitions and references to prior literature in the evaluation section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, agreeing where the critique identifies gaps in validation or reporting and outlining revisions accordingly. Our responses focus on strengthening the evidence for the 2×2 design, statistical rigor in results, and ablation analysis while preserving the core contributions.
read point-by-point responses
-
Referee: [Method (contrastive term derivation)] Method section (contrastive alignment term): the 2×2 perturbation design is presented as isolating visual vs. language-prior reliance to derive the contrastive term, yet no quantitative validation is supplied (e.g., correlation with independent visual-attention metrics, statistical test that the four cells differ only on the intended axis, or ablation of prompt/token-length confounds). Without this check the term reduces to a standard regularizer and the reported 60%+ calibration gains cannot be confidently attributed to modality-specific alignment.
Authors: We acknowledge that the manuscript lacks explicit quantitative validation (such as correlations with attention metrics or tests isolating prompt-length confounds) for the 2×2 factorial design. The design is motivated by crossing image presence with text integrity to probe visual-modality reliance versus language priors, and its contribution is evidenced indirectly through ablations demonstrating degraded calibration when the term is ablated. However, we agree this does not fully rule out alternative interpretations. In revision we will expand the method section with additional rationale, a qualitative example of the four cells, and an explicit limitations paragraph noting the absence of direct modality-isolation metrics. We cannot retroactively add new attention-correlation experiments without further work. revision: partial
-
Referee: [Results (benchmark tables)] Results section and tables: the abstract and main claims state ≥60% calibration-error reduction and ≥26% discrimination improvement across benchmarks, but no error bars, dataset sizes, exact metric definitions (e.g., which calibration error variant), or statistical tests are reported. This directly limits the strength of evidence for the headline quantitative improvements.
Authors: The referee correctly identifies missing statistical details. The current manuscript reports point estimates without variance, omits explicit dataset sizes in tables, and does not define the precise calibration metric variant or include significance tests. We will revise the results section and tables to include: (i) error bars from multiple random seeds, (ii) dataset sizes, (iii) clarification that calibration error refers to a Brier-style score as defined in the method, and (iv) paired statistical tests (e.g., Wilcoxon) comparing our method to baselines. These additions will be incorporated in the next version. revision: yes
-
Referee: [Ablation studies] Ablation experiments: while the text states that ablations confirm necessity of each loss component, the same absence of error bars or variance estimates makes it impossible to judge whether observed differences exceed experimental noise, weakening the claim that every term is required.
Authors: We agree that the ablation results, as presented, lack variance estimates, preventing assessment of whether component removals produce statistically meaningful drops. In the revised manuscript we will augment all ablation tables and figures with error bars across runs and, where feasible, report p-values for key comparisons. This will allow readers to evaluate whether each term's contribution exceeds noise. revision: yes
- Direct quantitative validation of the 2×2 design via correlations with independent visual-attention metrics or formal tests for prompt-length confounds would require new experiments and analysis beyond the scope of the original study.
Circularity Check
No circularity; empirical training framework evaluated on held-out benchmarks
full rationale
The paper introduces a composite loss (Brier calibration + anchor regularizer + contrastive alignment from 2x2 image/text perturbations + KL stabilization) and reports calibration/discrimination gains on three external Medical VQA benchmarks across two architectures. No equations, fitted parameters, or self-citations reduce the claimed improvements to quantities defined by construction inside the method itself. The 2x2 design supplies an empirical training signal rather than a self-referential prediction, and ablations test necessity without tautological closure. The derivation chain is self-contained against external data.
Axiom & Free-Parameter Ledger
free parameters (1)
- composite loss weights
axioms (2)
- domain assumption Finetuning with the top-K KL regularizer prevents degradation of answering accuracy.
- domain assumption The 2x2 perturbation design produces an alignment signal that improves visual reliance without introducing new biases.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2507.05201 , year=
MedGemma Technical Report , author=. arXiv preprint arXiv:2507.05201 , year=
-
[2]
Multimodal Large Language Models Challenge
Sheng, Chuyang and Shen, Shuo and Wang, Li and others , journal=. Multimodal Large Language Models Challenge. 2026 , doi=
2026
-
[3]
arXiv preprint arXiv:2506.22405 , year=
Sequential Diagnosis with Language Models , author=. arXiv preprint arXiv:2506.22405 , year=
-
[4]
arXiv preprint arXiv:2305.14975 , year =
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback , author =. arXiv preprint arXiv:2305.14975 , year =
-
[5]
arXiv preprint arXiv:2508.18847 , year =
Li, Yibo and Xiong, Miao and Wu, Jiaying and Hooi, Bryan , title =. arXiv preprint arXiv:2508.18847 , year =. doi:10.48550/arXiv.2508.18847 , url =
-
[6]
Xu, Tianyang and Wu, Shujin and Diao, Shizhe and Liu, Xiaoze and Wang, Xingyao and Chen, Yangyi and Gao, Jing , journal =
-
[7]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =
Seeing is Believing, but How Much? A Comprehensive Analysis of Verbalized Calibration in Vision-Language Models , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =. 2025 , address =
2025
-
[8]
Kriz, Anita and Janes, Elizabeth Laura and Shen, Xing and Arbel, Tal , journal =
-
[9]
arXiv preprint arXiv:2503.02863 , year =
Zhou, Ziang and Jin, Tianyuan and Shi, Jieming and Li, Qing , title =. arXiv preprint arXiv:2503.02863 , year =
-
[10]
Xiong, Miao and Hu, Zhiyuan and Lu, Xinyang and Li, Yifei and Fu, Jie and He, Junxian and Hooi, Bryan , booktitle =. Can
-
[11]
ICLR , year =
LoRA: Low-Rank Adaptation of Large Language Models , author =. ICLR , year =
-
[12]
Bakman, Yavuz Faruk and Yaldiz, Duygu Nur and Buyukates, Baturalp and Tao, Chenyang and Dimitriadis, Dimitrios and Avestimehr, Salman , booktitle =
-
[13]
International Conference on Learning Representations (ICLR) , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[14]
Enhancing Uncertainty Estimation in
Xiao, Zeguan and Dou, Diyang and Xiong, Boya and Chen, Yun and Chen, Guanhua , journal =. Enhancing Uncertainty Estimation in
-
[15]
Do Not Design, Learn: A Trainable Scoring Function for Uncertainty Estimation in Generative
Yaldiz, Duygu Nur and Bakman, Yavuz Faruk and Buyukates, Baturalp and Tao, Chenyang and Ramakrishna, Anil and Dimitriadis, Dimitrios and Zhao, Jieyu and Avestimehr, Salman , journal =. Do Not Design, Learn: A Trainable Scoring Function for Uncertainty Estimation in Generative
-
[16]
arXiv preprint arXiv:2503.02623 , year =
Rewarding Doubt: A Reinforcement Learning Approach to Calibrated Confidence Expression of Large Language Models , author =. arXiv preprint arXiv:2503.02623 , year =
-
[17]
arXiv preprint arXiv:2505.23912 , year =
Reinforcement Learning for Better Verbalized Confidence in Long-Form Generation , author =. arXiv preprint arXiv:2505.23912 , year =
-
[18]
arXiv preprint arXiv:2207.05221 , year =
Language Models (Mostly) Know What They Know , author =. arXiv preprint arXiv:2207.05221 , year =
-
[19]
arXiv preprint arXiv:2409.12180 , year =
Finetuning Language Models to Emit Linguistic Expressions of Uncertainty , author =. arXiv preprint arXiv:2409.12180 , year =
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
OmniMedVQA: A New Large-Scale Comprehensive Evaluation Benchmark for Medical LVLM , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =. 2402.09181 , archivePrefix =
-
[21]
Communications Medicine , volume =
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering , author =. Communications Medicine , volume =. 2024 , publisher =
2024
-
[22]
ICML , year =
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding , author =. ICML , year =
-
[23]
TMLR , year =
Teaching Models to Express Their Uncertainty in Words , author =. TMLR , year =
-
[24]
arXiv preprint arXiv:2404.10315 , year =
Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience , author =. arXiv preprint arXiv:2404.10315 , year =
-
[25]
arXiv preprint arXiv:2409.12191 , year=
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. arXiv preprint arXiv:2409.12191 , year=
-
[26]
Damani, Mehul and Puri, Isha and Slocum, Stewart and Shenfeld, Idan and Andreas, Jacob , year =
-
[27]
Zhang, Ruiyang and Zhang, Hu and Zheng, Zhedong , journal =
-
[28]
International Conference on Learning Representations , year =
Uncertainty Estimation in Autoregressive Structured Prediction , author =. International Conference on Learning Representations , year =
-
[29]
Padhi, Indu and Chen, Pin-Yu and Baldini, Ioana and Ramamurthy, Karthikeyan Natesan , journal =
-
[30]
arXiv preprint arXiv:2412.02778 , year =
Enhancing Language Model Factuality via Activation-Based Confidence Calibration and Guided Decoding , author =. arXiv preprint arXiv:2412.02778 , year =
-
[31]
ICLR 2025 Workshop on QUESTION , year =
Detecting Unreliable Responses in Vision-Language Models via Visual Uncertainty , author =. ICLR 2025 Workshop on QUESTION , year =
2025
-
[32]
International Conference on Learning Representations (ICLR) , year =
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author =. International Conference on Learning Representations (ICLR) , year =
-
[33]
arXiv preprint arXiv:2504.08750 , year =
Object-Level Verbalized Confidence Calibration in Vision-Language Models via Semantic Perturbation , author =. arXiv preprint arXiv:2504.08750 , year =
-
[34]
Proceedings of Medical Image Computing and Computer Assisted Intervention -- MICCAI 2025 , year =
Liao, Zehui and Hu, Shishuai and Zou, Ke and Fu, Huazhu and Zhen, Liangli and Xia, Yong , title =. Proceedings of Medical Image Computing and Computer Assisted Intervention -- MICCAI 2025 , year =
2025
-
[35]
Radiology , volume=
The meaning and use of the area under a receiver operating characteristic (ROC) curve , author=. Radiology , volume=. 1982 , publisher=
1982
-
[36]
ICML , year =
On Calibration of Modern Neural Networks , author =. ICML , year =
-
[37]
Monthly Weather Review , volume =
Verification of Forecasts Expressed in Terms of Probability , author =. Monthly Weather Review , volume =
-
[38]
arXiv preprint arXiv:2405.02917 , year =
Overconfidence is Key: Verbalized Uncertainty Evaluation in Large Language and Vision-Language Models , author =. arXiv preprint arXiv:2405.02917 , year =
-
[39]
Taming Overconfidence in
Leng, Jixuan and Huang, Chengsong and Zhu, Banghua and Huang, Jiaxin , booktitle =. Taming Overconfidence in
-
[40]
ICML , year =
Restoring Calibration for Aligned Large Language Models: A Calibration-Aware Fine-Tuning Approach , author =. ICML , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.