From Knowing to Acting: Benchmarking Self-Awareness Capability of LLM Agents
Pith reviewed 2026-06-27 13:13 UTC · model grok-4.3
The pith
LLM agents succeed more when they accurately judge whether a problem needs external tools or can be solved from internal knowledge alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
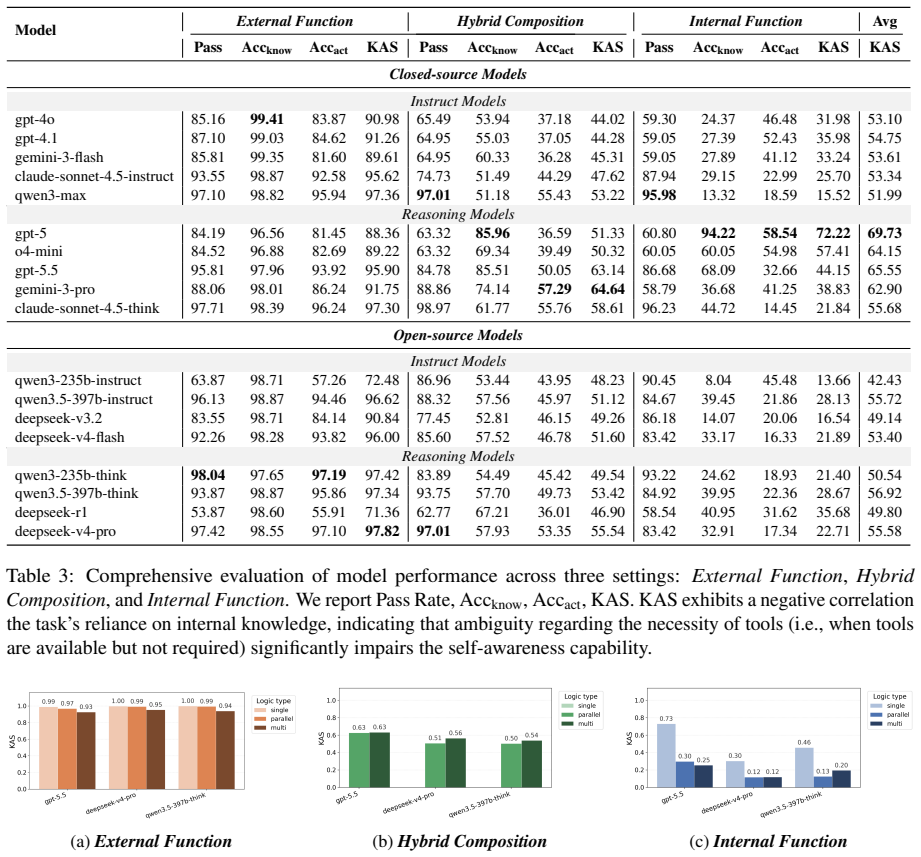
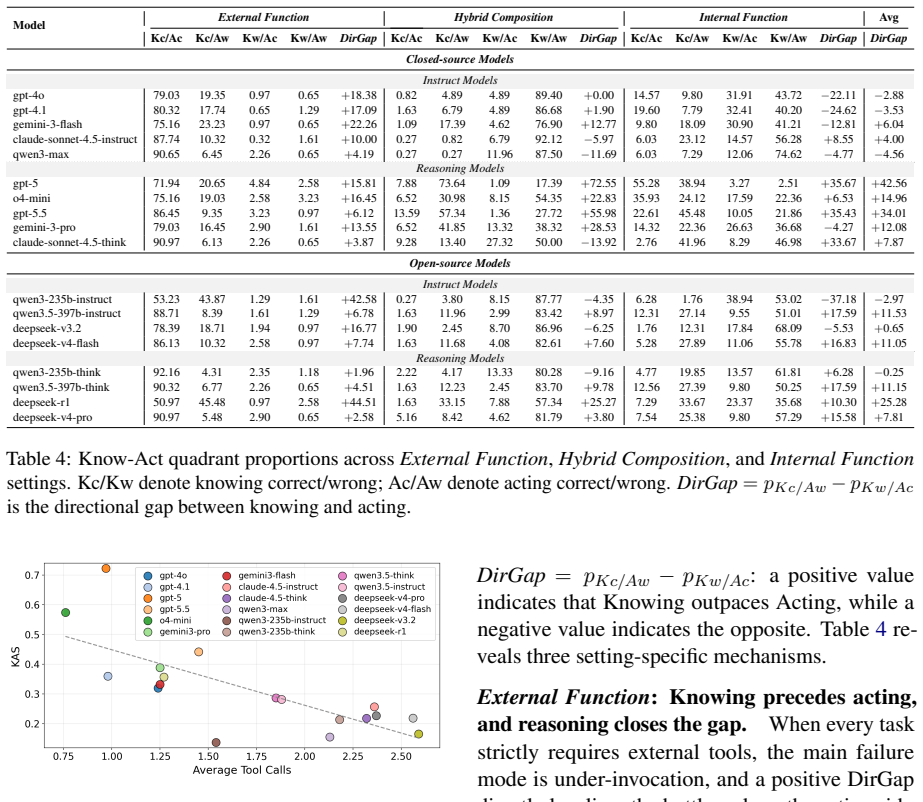
Self-awareness capability, the ability to discern whether a problem requires necessary external resources or can be solved via internal parametric knowledge, is strongly correlated with task success but degrades sharply in internal-capability settings, with open-source and instruction-following models showing stronger tool overuse due to shallow pattern matching and proprietary and reasoning-oriented models demonstrating more reliable cognitive gating.
What carries the argument
KAPRO (Knowing-Acting Quadrant PRObe), a framework that evaluates cognitive-behavioral alignment by decoupling an agent's metacognitive judgment from its spontaneous execution.
If this is right
- Self-awareness capability correlates positively with task success across agent architectures.
- Self-awareness drops sharply when tasks fall inside the agent's internal parametric knowledge.
- Open-source and instruction-following models overuse tools through shallow pattern matching.
- Proprietary and reasoning-oriented models exhibit more reliable decisions about when to invoke tools.
Where Pith is reading between the lines
- Training loops that reward accurate self-judgment before execution could reduce wasted tool calls in long-horizon tasks.
- The same decoupling of judgment from action might be applied to other agent decisions such as when to ask a human for clarification.
- Hybrid subspaces in the dataset may reveal whether agents can correctly combine internal and external steps rather than defaulting to one mode.
Load-bearing premise
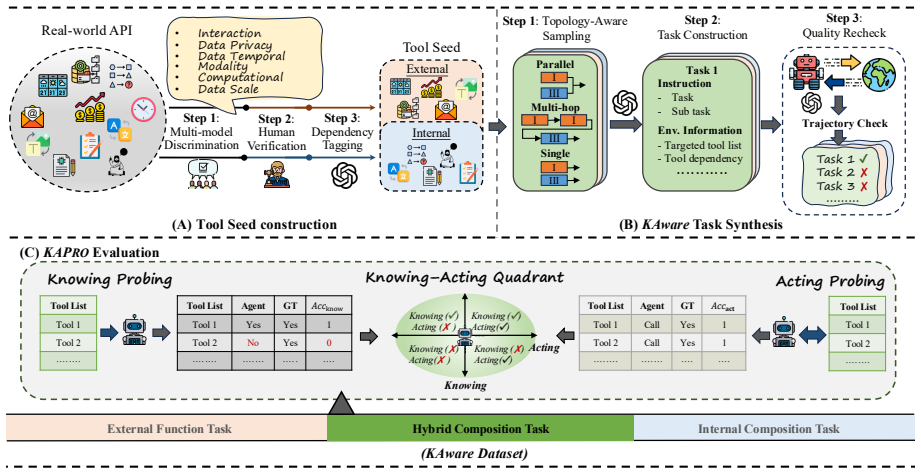
The KAware dataset's partitioning of tasks into external, internal, and hybrid subspaces accurately reflects true epistemic boundaries without selection bias or mislabeling of what counts as solvable via internal parametric knowledge.
What would settle it
A controlled re-labeling of a subset of KAware tasks as internal when they are actually external (or vice versa) followed by re-running the agent evaluations to check whether the reported correlation between self-awareness scores and success rates disappears.
Figures


read the original abstract
The integration of external tools has transitioned LLM agents from passive responders to autonomous systems. However, current benchmarks prioritize execution success, neglecting self-awareness capability, the ability to discern whether a problem requires necessary external resources or can be solved via internal parametric knowledge. To address this, we introduce KAPRO (Knowing-Acting Quadrant PRObe), a framework that evaluates cognitive-behavioral alignment by decoupling an agent's metacognitive judgment (Knowing) from its spontaneous execution (Acting). We further construct KAware, a dataset rigorously partitioning tasks into external, internal, and hybrid subspaces to systematically probe these epistemic boundaries. Extensive experiments across diverse agent architectures show that self-awareness capability is strongly correlated with task success but degrades sharply in internal-capability settings. Moreover, open-source and instruction-following models exhibit stronger tool overuse due to shallow pattern matching, while proprietary and reasoning-oriented models demonstrate more reliable cognitive gating. Benchmark and codes are available at https://github.com/AI-Santiago/KAware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the KAPRO framework, which decouples metacognitive judgment ('Knowing') from spontaneous execution ('Acting') to probe self-awareness in LLM agents. It constructs the KAware dataset by partitioning tasks into external, internal, and hybrid subspaces, then reports experiments across agent architectures showing that self-awareness correlates strongly with task success, degrades sharply in internal-capability settings, and differs by model type (open-source/instruction-following models show more tool overuse via shallow matching, while proprietary/reasoning models exhibit better cognitive gating).
Significance. If the central claims hold, the work supplies a useful new lens and dataset for evaluating metacognition in tool-using agents, moving beyond pure execution metrics. The public release of the benchmark and code is a clear strength that supports reproducibility.
major comments (2)
- [§3] §3 (KAware construction): the partitioning into internal vs. external subspaces is described as 'rigorous' but appears to rely on generic human criteria or zero-shot solvability checks that are not model-specific. This directly undermines the load-bearing claim that observed degradation and 'cognitive gating' differences reflect metacognition rather than inconsistent subspace assignment across proprietary vs. open-source models.
- [§4] §4 (experimental results): the reported correlations between self-awareness scores and success, and the model-type differences in tool overuse, rest on the assumption that KAware labels accurately reflect each model's parametric knowledge boundaries. Without per-model validation experiments (e.g., zero-shot accuracy on the 'internal' subset for each evaluated model), these correlations risk being artifacts of labeling rather than evidence of self-awareness.
minor comments (2)
- [Abstract / §1] The abstract and introduction use 'self-awareness capability' without a crisp operational definition that distinguishes it from related constructs such as calibration or refusal behavior; a short clarifying paragraph would help.
- [Figures] Figure captions and axis labels in the result plots could be expanded to explicitly state the exact metrics used for 'Knowing' and 'Acting' scores.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the KAware construction and the experimental validation. We address each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (KAware construction): the partitioning into internal vs. external subspaces is described as 'rigorous' but appears to rely on generic human criteria or zero-shot solvability checks that are not model-specific. This directly undermines the load-bearing claim that observed degradation and 'cognitive gating' differences reflect metacognition rather than inconsistent subspace assignment across proprietary vs. open-source models.
Authors: The KAware partitioning relies on human expert criteria assessing whether tasks are solvable from parametric knowledge alone, augmented by zero-shot checks using a reference model. This yields a fixed, model-agnostic benchmark intended for cross-architecture comparison. We acknowledge that the labels are not derived from per-model testing and therefore agree that additional validation is warranted to rule out assignment artifacts. revision: yes
-
Referee: [§4] §4 (experimental results): the reported correlations between self-awareness scores and success, and the model-type differences in tool overuse, rest on the assumption that KAware labels accurately reflect each model's parametric knowledge boundaries. Without per-model validation experiments (e.g., zero-shot accuracy on the 'internal' subset for each evaluated model), these correlations risk being artifacts of labeling rather than evidence of self-awareness.
Authors: The reported correlations are based on consistent behavioral patterns observed across the tested models. To strengthen the evidence that the subspaces align with each model's actual knowledge boundaries, we will add per-model zero-shot accuracy results on the internal subset in the revised manuscript. revision: yes
Circularity Check
No circularity: new benchmark and empirical evaluation are self-contained.
full rationale
The paper constructs a new dataset (KAware) and framework (KAPRO) to measure self-awareness via task partitioning and agent behavior. Claims about correlations, degradation in internal settings, and model-type differences are derived from experiments on this fresh benchmark rather than from any fitted parameter renamed as prediction, self-referential definition, or self-citation chain. No equations or derivations reduce the output to the input by construction; the epistemic-boundary labeling is a methodological assumption open to external validation, not a circular step. This matches the default expectation for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks can be partitioned into external, internal, and hybrid categories based on whether they require external resources or can be solved with internal parametric knowledge.
Reference graph
Works this paper leans on
-
[1]
The Keyword (Google Blog). Published Nov 18, 2025. Introduces Gemini 3 and Gemini 3 Pro (preview). Accessed 2026-01-17. Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, and Yang Liu. 2024. StableToolBench: Towards stable large-scale benchmarking on tool learning of large language models. InFindings of the As...
Pith/arXiv arXiv 2025
-
[2]
arXiv preprint arXiv:2507.04037
Ready jurist one: Benchmarking language agents for legal intelligence in dynamic environments. arXiv preprint arXiv:2507.04037. Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, and 1 others. 2022. Language mod- els (mostly) know what they know.arXiv ...
arXiv 2022
-
[3]
InInternational Conference on Learning Representa- tions (ICLR)
Gaia: A benchmark for general AI assistants. InInternational Conference on Learning Representa- tions (ICLR). Chunyu Miao, Henry Peng Zou, Yangning Li, Yankai Chen, Yibo Wang, Fangxin Wang, Yifan Li, Wooseong Yang, Bowei He, Xinni Zhang, and 1 oth- ers. 2025. Recode-h: A benchmark for research code development with interactive human feedback.arXiv preprin...
arXiv 2025
-
[4]
Send Email
Interaction Scope Assessment Logic:Does the tool alter the state of the world or system? • True:State-mutating operations (e.g., Create/Update/Delete, “Send Email”, “Buy Stock”, “Reboot Server”). • False:Read-only or informational (e.g., “Get Weather”, “Search Docs”, “Read File”). • Unknown:Vague verbs without specify- ing read/write
-
[5]
• False:Uses public-domain knowledge (e.g., Wikipedia facts, general reasoning, open web)
Data Privacy Scope Assessment Logic:Does the tool require restricted data access? • True:Accesses private/sensitive data (e.g., PII, internal DBs, user-auth content). • False:Uses public-domain knowledge (e.g., Wikipedia facts, general reasoning, open web). • Unknown:Data source/permission level not mentioned
-
[6]
• False:Uses static/historical knowledge or timeless principles
Data Temporal Scope Assessment Logic:Does the tool require real-time synchronization? • True:Depends on real-time/dynamic data (e.g., current stock price, live traffic, breaking news). • False:Uses static/historical knowledge or timeless principles. •Unknown:Time sensitivity unclear
-
[7]
• False:Standard native modalities (e.g., text, code)
Modality Scope Assessment Logic:Does the tool handle data formats or media types unsupported by standard LLMs? • True:Unsupported/specialized modali- ties (e.g., video generation, 3D models/- point clouds, CAD files). • False:Standard native modalities (e.g., text, code). • Unknown:Input/output media format not specified
-
[8]
• False:Semantic reasoning or basic arith- metic (e.g., summarization, classification, creative writing,1+1)
Computational Scope Assessment Logic:Does the task require rigorous calculation or exact execution? • True:Hard logic where LLMs often fail (e.g., complex math, cryptography, code execution). • False:Semantic reasoning or basic arith- metic (e.g., summarization, classification, creative writing,1+1). • Unknown:Computational complexity un- clear
-
[9]
tool_name
Data Scale Scope Assessment Logic:Does the data volume exceed context limits? • True:Out-of-core processing (e.g., ter- abytes of logs, bulk DB aggregation). • False:In-context processing (fits within a standard prompt window). •Unknown:Data volume not specified. FINAL CLASSIFICATION RULES: Apply these rules in order to determine final_classification: •Tr...
2025
-
[10]
The Trigger: Who is the user and what is their immediate pain point?
-
[11]
The Action: How is this specific tool invoked to handle the situation?
-
[12]
Do not include headers, explana- tions, or introductory text
The Outcome: What is the immediate value or result gained? Output Format Returnonlythe paragraph containing the scenario. Do not include headers, explana- tions, or introductory text. Question Quality Assessment Prompt Role You are aQuestion Quality Assessment Analyst. Your task is to analyze the pro- vided tool use question and assess its qual- ity acros...
-
[13]
Check server logs
Is the Question Beyond LLM Knowl- edge Boundary? Definition:Is it impossible for the LLM to answer correctly using only internal train- ing data? • Yes: Asks forprivate/proprietary data(e.g., "Check server logs") or real-time/future events(e.g., "What is the weather now?"). • No: Asks for general knowledge, cod- ing syntax, or historical facts (e.g., "Cap...
-
[14]
• No: Explicitly names the func- tion/API, or the intent is trivially obvi- ous (1-to-1 match)
Is Tool Selection Challenging? Definition:Does the model need to infer the tool from the goal rather than explicit instructions? • Yes: No specific tool name is men- tioned; mapping intent requires rea- soning. • No: Explicitly names the func- tion/API, or the intent is trivially obvi- ous (1-to-1 match)
-
[15]
• No: Multiple tools could solve the problem equally well
Is Tool Selection Unique? Definition:Is the selected tool the only logical way to solve the problem? • Yes: No redundant tools exist; specific capabilities are required. • No: Multiple tools could solve the problem equally well
-
[16]
Restartprod-db-01
Is Parameter Complete? Definition:Does the question naturally contain the arguments (ID, Time, Location) required for execution? • Yes: Includes specific details (e.g., "Restartprod-db-01"). • No: Lacks specific targets, forcing guesses (e.g., "Restart the server")
-
[17]
• No: The scenario feels contrived, arti- ficial, or theoretically impossible
Is Scenario Realistic? Definition:Does this represent a genuine user need in a real-world workflow? • Yes: Sounds like a request from a de- veloper, operator, or real user. • No: The scenario feels contrived, arti- ficial, or theoretically impossible
-
[18]
• No: The expected answer is purely subjective, creative, or open-ended
Is the Answer Verifiable? Definition:Can the correctness of the final answer be objectively proven? • Yes: Relies on objective data (num- bers, status codes, specific strings). • No: The expected answer is purely subjective, creative, or open-ended. Output Format You MUST respond using exactly the fol- lowing XML format. Do not add any text before or afte...
-
[19]
Rely strictly on tool documentation, task and answer
-
[20]
t o o l _ d e c i s i o n s
Do not use external knowledge or com- mon sense. Assessment Logic:Determine whether the final answer accurately completes the task. The answer must be consistent with the ground truth answer and must not contra- dict any relevant tool response. Judgment Rules: • True: The answer is accurate, sup- ported by the ground truth answer and tool response, and fu...
2024
-
[21]
Intent Analysis: Understand the spe- cific goal in theUser Task
-
[22]
Trajectory Review: Examine theTool Calling Trajectoryto see if the agent took appropriate actions
-
[23]
content" : (String) Your reason- ing explaining why you assigned the status. •
Answer Verification: Compare theAgent’s Final Answeragainst theReference(if available) and the Solved/Unsolved criteria defined above. Output Format You must respond with a single, valid JSON object containing exactly these keys: •"content" : (String) Your reason- ing explaining why you assigned the status. •"answer_status" : (String) Must be exactly "Sol...
arXiv 2087
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.