Annealed Softmax Greedy in Many-Armed Bayesian Bandits
Pith reviewed 2026-06-28 23:48 UTC · model grok-4.3
The pith
Under a linear upper-tail prior condition, annealed softmax greedy achieves Bayes regret Õ(m + T/m) in many-armed Bayesian bandits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the β=1 case of β-regularity on the prior, which implies an abundance of near-optimal arms throughout learning, the annealed softmax (Boltzmann) policy that selects actions by softmax over empirical mean rewards achieves Bayes regret Õ(m + T/m). In particular this rate is Õ(√T) when m = Θ(√T). The same rate is attained by empirical-mean greedy. Under β-regularity many arms maintain empirical means close to the optimum, so non-greedy softmax samples are typically other near-optimal arms rather than inferior ones. With few arms the same softmax policy can suffer linear regret. The construction supplies a structural analogy to RLVR, where a base policy with non-negligible probability of c
What carries the argument
Annealed softmax (Boltzmann) policy that selects actions according to a softmax of empirical mean rewards, under the linear upper-tail (β=1) condition on the prior.
If this is right
- When m scales as Θ(√T) the policy attains the near-optimal Õ(√T) Bayes regret rate.
- Throughout learning, many arms maintain empirical means close to the optimum.
- When the softmax samples an arm other than the current empirical best, that arm is typically another near-optimal one rather than a clearly inferior arm.
- The same regret rate is achieved by the simpler empirical-mean greedy rule under the same prior condition.
- The construction supplies an analogy in which a base policy that frequently produces correct completions plays the structural role of β-regularity.
Where Pith is reading between the lines
- The same abundance mechanism may allow uncertainty-agnostic updates to succeed in other large-action-space RL problems whose effective priors are similarly regular.
- One could test the necessity of the tail condition by comparing regret curves on synthetic bandits whose priors are drawn from distributions with heavier or lighter upper tails.
- The analogy suggests that RL base policies should be initialized or regularized to place non-negligible mass on high-reward outputs even before fine-tuning.
Load-bearing premise
The prior satisfies a linear upper-tail condition that keeps an abundance of near-optimal arms available at every stage of learning.
What would settle it
A direct calculation or simulation in which the prior is altered to remove the linear upper-tail property while keeping m = Θ(√T), after which the annealed softmax policy exhibits linear regret.
Figures
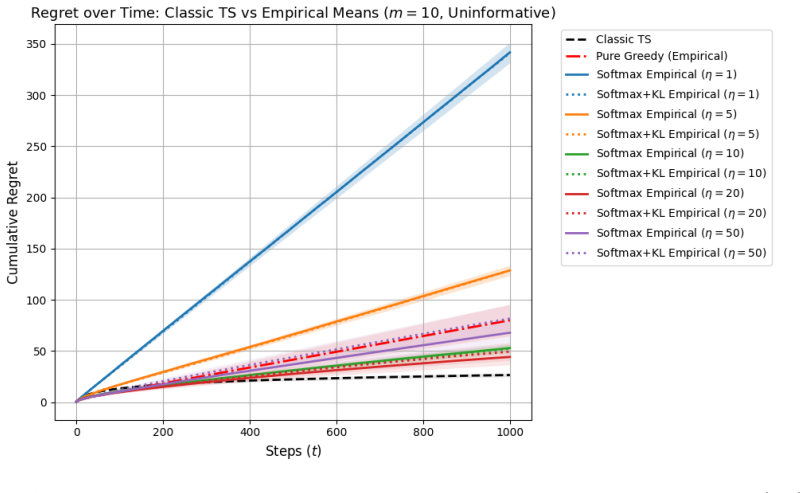
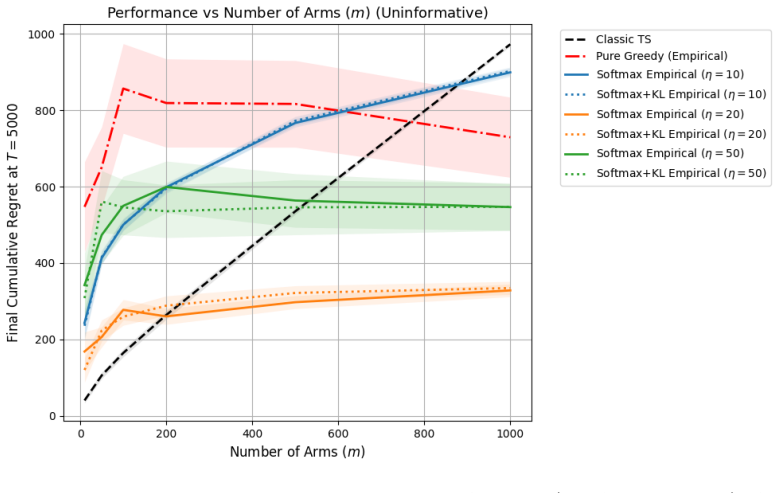
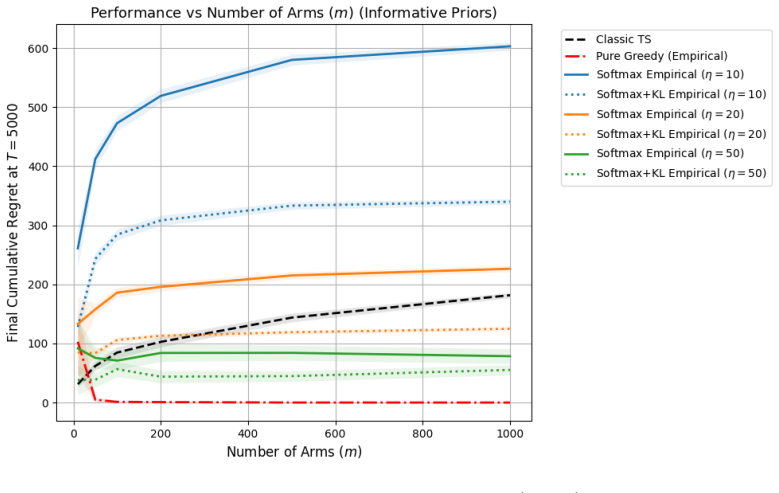
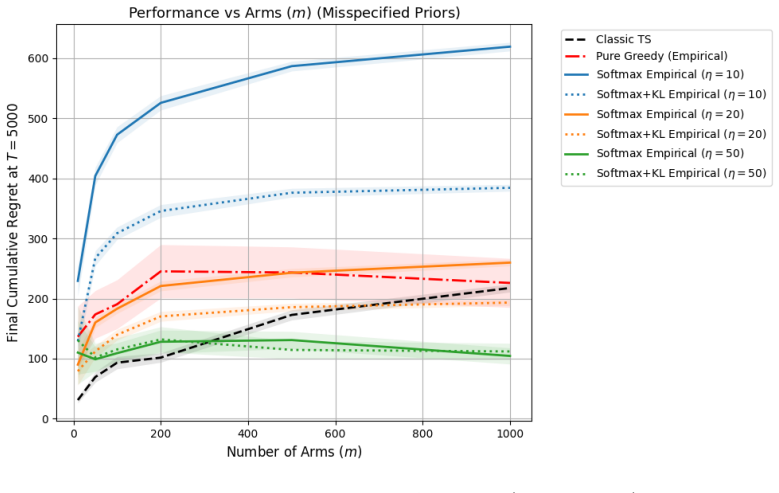
read the original abstract
Reinforcement learning with verifiable rewards (RLVR) and group-based policy optimization methods such as GRPO update a stochastic policy by sampling multiple completions per prompt and increasing the policy's probability on those with higher reward, regularized by a KL penalty toward a reference policy. These updates do not include explicit mechanisms that track epistemic uncertainty. This paper studies a stylized explanation for why such uncertainty-agnostic updates can nevertheless be effective. We analyze an annealed softmax (Boltzmann) policy that selects actions according to a softmax of empirical mean rewards in a many-armed Bayesian Bernoulli bandit. Under a linear upper-tail condition on the prior (the $\beta=1$ case of $\beta$-regularity), which implies an abundance of near-optimal arms, we prove that annealed softmax greedy achieves Bayes regret $\tilde{O}(m + T/m)$, and in particular $\tilde{O}(\sqrt{T})$ when the number of arms scales as $m = \Theta(\sqrt{T})$. This is the near-optimal Bayes regret rate in this regime, attained also by empirical-mean greedy. Under $\beta$-regularity, many arms maintain empirical means close to the optimum throughout learning, so when softmax samples an arm other than the empirically best, that arm tends to be another near-optimal one rather than a clearly inferior one. By contrast, with a small number of arms, the same kind of softmax policy can suffer linear regret. The result also provides a structural analogy to RLVR, where a base policy with a non-negligible probability of producing a correct completion plays the role of $\beta$-regularity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes annealed softmax (Boltzmann) greedy in many-armed Bayesian Bernoulli bandits. Under the linear upper-tail condition on the prior (the β=1 case of β-regularity), which ensures an abundance of near-optimal arms, it claims to prove that the policy attains Bayes regret Õ(m + T/m), and in particular Õ(√T) when m = Θ(√T). This rate is described as near-optimal in the regime and is already known to be achieved by empirical-mean greedy. The result is positioned as a structural analogy to uncertainty-agnostic updates in RLVR/group-based policy optimization, where a base policy with non-negligible probability of correct completions plays the role of the β-regularity condition.
Significance. If the stated regret bound holds under the given prior condition, the result would provide a clean explanation for why softmax-based, uncertainty-agnostic updates remain effective when the number of arms (or candidate completions) is large: the abundance of near-optimal arms ensures that softmax selections away from the empirical best are still competitive rather than clearly inferior. The explicit matching to the known rate of empirical-mean greedy and the RLVR analogy are useful structural insights.
major comments (1)
- [Abstract / central claim] Abstract (and stated central claim): the manuscript asserts a proof of the Bayes regret bound Õ(m + T/m) under the explicit β=1 linear upper-tail condition, but the full derivation, verification of the upper-tail condition implications, and any technical lemmas are unavailable in the text provided for review. Without these steps it is not possible to confirm that the condition indeed yields the claimed abundance of near-optimal arms throughout learning or that the annealed softmax policy inherits the same rate as empirical-mean greedy.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting the need for explicit verification of the central claim. We address the major comment below and will revise the manuscript accordingly to improve accessibility of the proof.
read point-by-point responses
-
Referee: [Abstract / central claim] Abstract (and stated central claim): the manuscript asserts a proof of the Bayes regret bound Õ(m + T/m) under the explicit β=1 linear upper-tail condition, but the full derivation, verification of the upper-tail condition implications, and any technical lemmas are unavailable in the text provided for review. Without these steps it is not possible to confirm that the condition indeed yields the claimed abundance of near-optimal arms throughout learning or that the annealed softmax policy inherits the same rate as empirical-mean greedy.
Authors: The full derivation appears in Sections 3–4 of the manuscript (with supporting technical lemmas in the appendix). Section 3 first recalls the linear upper-tail condition and proves that it implies a sufficient density of near-optimal arms at every round (via a direct application of the prior tail bound to the posterior means). Section 4 then decomposes the Bayes regret of annealed softmax into a term controlled by the number of arms m and a term controlled by T/m, showing that the softmax temperature schedule ensures the policy only incurs sublinear regret when sampling away from the empirical leader. The argument mirrors the known analysis for empirical-mean greedy but replaces the deterministic selection with a softmax whose deviation probability is bounded using the same abundance property. We agree that these steps should be more prominently summarized in the main body and will add a short proof sketch immediately after the statement of the main theorem in the revised version. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper states a conditional proof of the Bayes regret bound Õ(m + T/m) for annealed softmax greedy, explicitly conditioned on the linear upper-tail prior condition (β=1 case of β-regularity) that is given as an assumption rather than derived. This prior condition is independent of the algorithm and is used to argue that non-best softmax selections remain near-optimal. The result is compared to the known rate for empirical-mean greedy but is not reduced to it by construction, nor does the text indicate any fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes smuggled via prior work. The derivation chain is therefore self-contained against the stated external assumption on the prior.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption linear upper-tail condition on the prior (the β=1 case of β-regularity)
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Published in Nature 645, 633–638 (2025), doi:10.1038/s41586-025-09422-z. John C. Gittins. Bandit processes and dynamic allocation indices.Journal of the Royal Statistical Society: Series B (Methodological), 41(2):148–164, 1979. doi: 10.1111/j.2517-6161.1979.tb01068. x. URLhttps://doi.org/10.1111/j.2517-6161.1979.tb0106...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09422-z 2025
-
[2]
Training language models to follow instructions with human feedback
URLhttps://arxiv.org/abs/2203.02155. Advances in Neural Information Processing Systems 35 (NeurIPS 2022). Ruotian Peng, Yi Ren, Zhouliang Yu, Weiyang Liu, and Yandong Wen. Simko: Simple pass@K policy optimization, 2025. URLhttps://arxiv.org/abs/2510.14807. Manish Raghavan, Aleksandrs Slivkins, Jennifer Wortman Vaughan, and Zhiwei Steven Wu. The externalit...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1287/moor.2014.0650 2022
-
[3]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
URLhttps://arxiv.org/abs/2504.13837. Guanning Zeng, Zhaoyi Zhou, Daman Arora, and Andrea Zanette. Shrinking the variance: Shrinkage baselines for reinforcement learning with verifiable rewards, 2025. URLhttps: //arxiv.org/abs/2511.03710. Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
free exploration
withc η >1. Then PT t=1 e−ηtδ =O(1). IfAlog(T∨2)/m≤δ 0, thenδ=Alog(T∨2)/mandT e −cmδ =T 1−cA ≤1 sincecA >1. The other terms in (7) arem,T δ=Alog(T∨2)·T /m,m(1 + log(1/δ)) = ˜O(m), and (1/δ)P t e−ηtδ = ˜O(m), summing to ˜O(m+T /m). IfAlog(T∨2)/m > δ 0 (i.e.,m < Alog(T∨2)/δ 0), the cap binds andT /m > δ 0T /(Alog(T∨2)) = ˜Ω(T), so ˜O(m+T /m) already absorbs...
1985
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.