Make Your VLA More Robust Without More Data By Interleaving Motion Planning
Pith reviewed 2026-06-28 17:29 UTC · model grok-4.3
The pith
Interleaving a motion planner with a vision-language-action model improves long-horizon task robustness without additional training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
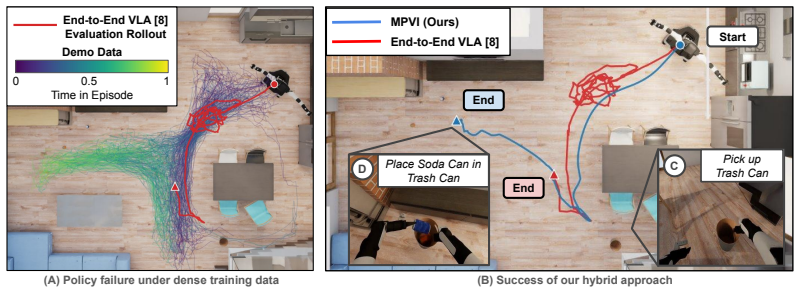
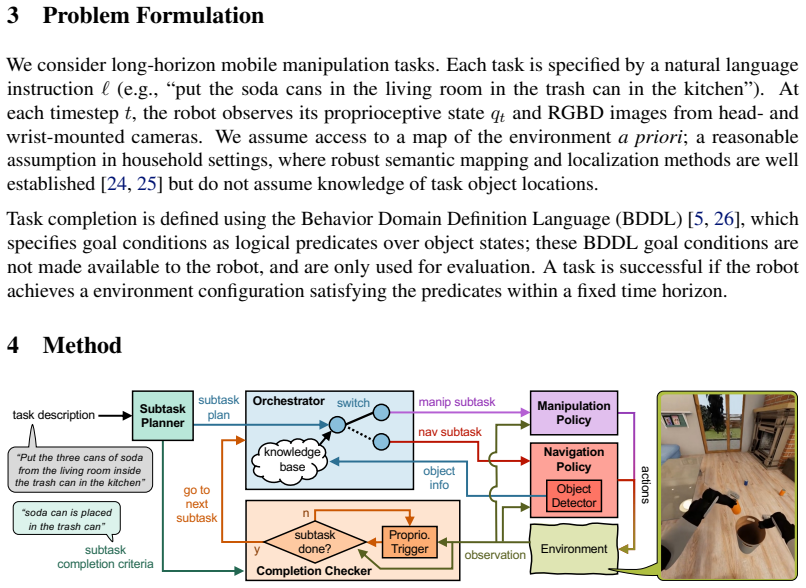
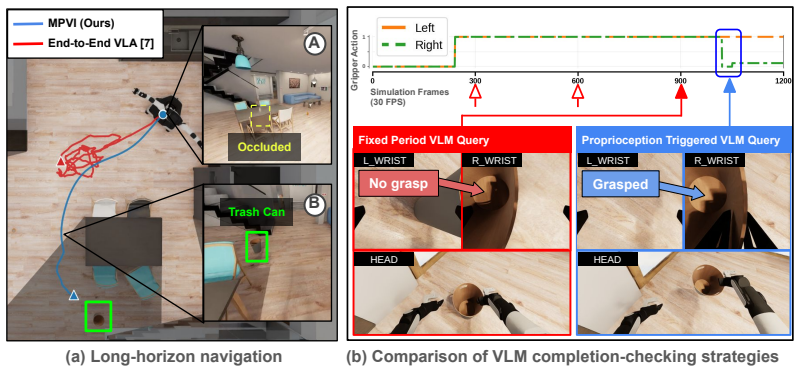
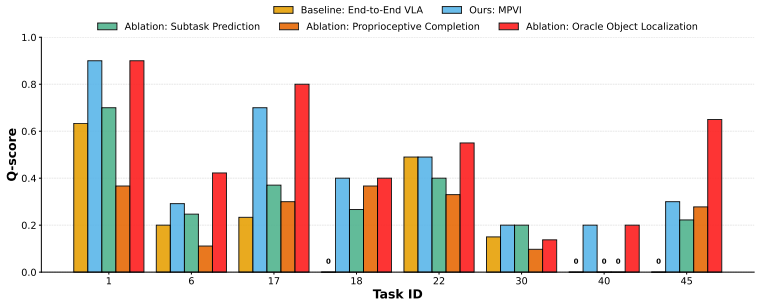
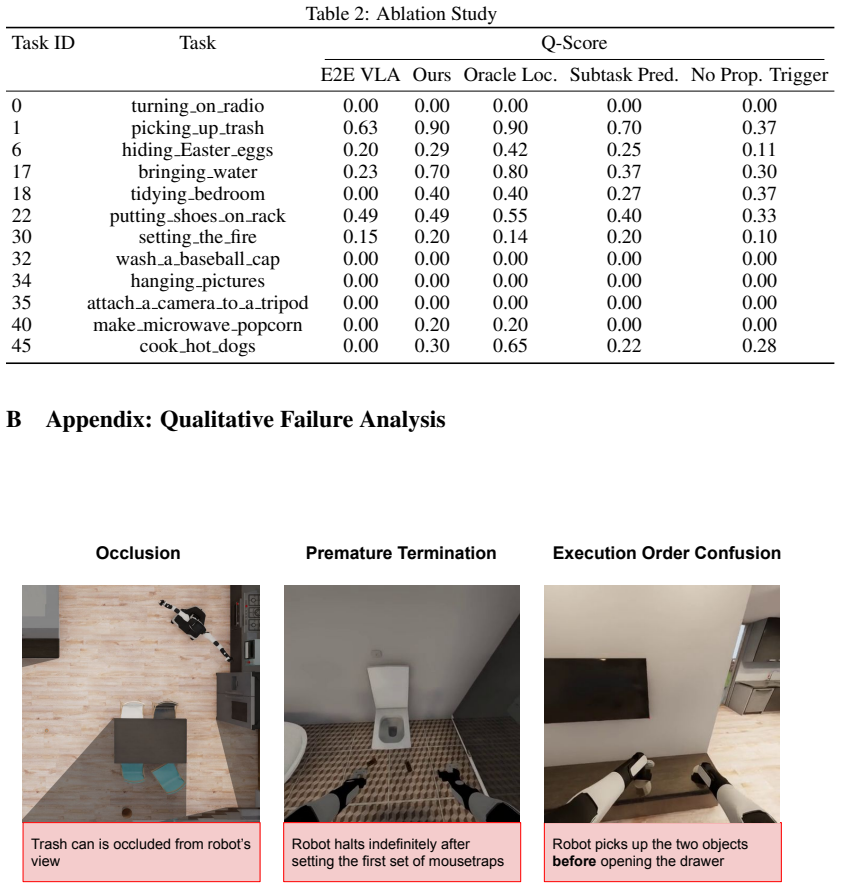
MPVI integrates model-based motion planning with VLAs to enable localization and navigation to distant or occluded targets through cluttered scenes using open-vocabulary object detection, frontier exploration and motion planning; reliable module switching is achieved via VLM-based completion checking with proprioceptive triggers, producing a 113% improvement in task progress over a top end-to-end VLA baseline on the BEHAVIOR-1K benchmark.
What carries the argument
MPVI framework for interleaving motion planning and VLAs, using VLM-based completion checking with proprioceptive triggers to decide when to switch modules.
If this is right
- Navigation and recovery subtasks can be offloaded to model-based planners while the VLA retains high-level decision making.
- Robustness gains on long-horizon tasks are attainable without collecting additional teleoperation data.
- The same interleaving pattern applies to any VLA evaluated on spatially distributed mobile manipulation benchmarks.
- Proprioceptive signals combined with vision-language verification suffice to trigger module handoffs in the tested setting.
Where Pith is reading between the lines
- The same hybrid pattern could be tested with other classical planners or with learned low-level controllers.
- Replacing the VLM checker with a lightweight learned classifier might reduce latency while preserving switching accuracy.
- Real-robot deployment would expose whether perception noise reduces the measured gains relative to simulation.
Load-bearing premise
Reliable switching between the VLA policy and the motion planner can be achieved with VLM-based completion checking plus proprioceptive triggers.
What would settle it
A controlled test in which the VLM completion checker is replaced by a noisy or inaccurate oracle and the reported task-progress gain disappears.
Figures
read the original abstract
Vision-Language-Action (VLA) models have shown remarkable progress for mobile manipulation, but their performance on long-horizon tasks remains poor. These tasks are especially challenging because (1) progress toward high-level goals must be maintained across extended sequences of spatially distributed subtasks, and (2) early execution errors compound rapidly over the task horizon. These challenges persist despite finetuning on large human teleoperated mobile manipulation data, indicating that more data alone may not resolve the problem. To address these challenges, we propose MPVI: Motion Planner / VLA Interleaving, a framework that integrates model-based motion planning with VLAs to improve robustness without further training. The proposed integration enables localization and navigation to distant or occluded target objects through cluttered scenes using open-vocabulary object detection, frontier exploration and motion planning. However, such integration is non-trivial, requiring reliable switching between modules; we show one way forward via VLM-based completion checking with proprioceptive triggers. We evaluate our approach on the BEHAVIOR-1K benchmark and demonstrate 113% improvement in task progress over a top end-to-end VLA baseline. Additional details are available at the project page: https://mpvi.netlify.app/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MPVI, a framework that interleaves a model-based motion planner with Vision-Language-Action (VLA) models to improve robustness on long-horizon mobile manipulation tasks without additional training. Integration uses open-vocabulary object detection, frontier exploration, and motion planning, with module switching implemented via VLM-based completion checking augmented by proprioceptive triggers. The central empirical result is a reported 113% improvement in task progress on the BEHAVIOR-1K benchmark relative to a top end-to-end VLA baseline.
Significance. If the performance gain can be rigorously verified and attributed to the interleaving mechanism, the work would offer a practical, data-efficient route to mitigating error compounding in extended tasks by combining the generalization of VLAs with the reliability of classical planning. This hybrid direction addresses a recognized limitation in current VLA deployments and could influence subsequent research on modular robot architectures.
major comments (2)
- [Abstract] Abstract: The headline claim of a 113% improvement in task progress supplies no experimental protocol, baseline implementation details, number of trials, statistical tests, or failure-mode analysis. This information is load-bearing for the central empirical claim and its attribution to MPVI.
- [Abstract] Abstract: The framework is described as non-trivial precisely because it requires reliable switching; the VLM-based completion checker with proprioceptive triggers is offered as one solution, yet no quantitative switching-error rates, false-positive/negative statistics, or ablation isolating the checker appear. Without these, the source of the reported gain cannot be isolated from potential new failure modes introduced by the hybrid system.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point-by-point below. We agree that the abstract would benefit from additional detail and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of a 113% improvement in task progress supplies no experimental protocol, baseline implementation details, number of trials, statistical tests, or failure-mode analysis. This information is load-bearing for the central empirical claim and its attribution to MPVI.
Authors: The abstract is a concise summary; the full experimental protocol (including task selection from BEHAVIOR-1K, number of evaluation episodes, baseline VLA implementation details, statistical reporting, and failure-mode categorization) is provided in the Experiments section. We will add a short clause to the abstract referencing the evaluation scale and protocol to make the claim self-contained. revision: yes
-
Referee: [Abstract] Abstract: The framework is described as non-trivial precisely because it requires reliable switching; the VLM-based completion checker with proprioceptive triggers is offered as one solution, yet no quantitative switching-error rates, false-positive/negative statistics, or ablation isolating the checker appear. Without these, the source of the reported gain cannot be isolated from potential new failure modes introduced by the hybrid system.
Authors: We acknowledge that dedicated quantitative metrics on the completion checker (error rates, false positives/negatives) and an ablation isolating its contribution are not reported. The current results attribute gains to the overall interleaving framework via end-to-end task progress. We will add an ablation study and switching statistics in the revision to better isolate the checker's role. revision: yes
Circularity Check
No circularity: empirical performance claim on external benchmark
full rationale
The paper proposes the MPVI framework for interleaving motion planning with VLAs and reports a measured 113% task progress improvement on the BEHAVIOR-1K benchmark. The supplied text contains no equations, derivations, fitted parameters, or self-citations. The central claim is an empirical result on an external benchmark rather than any reduction of outputs to inputs by construction, self-definition, or load-bearing self-reference. No load-bearing steps exist that match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption BEHAVIOR-1K is an appropriate and representative benchmark for evaluating long-horizon mobile manipulation robustness
Reference graph
Works this paper leans on
-
[1]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . Myers, M. J. Kim, M. Du, A. Lee, K. Fang, C. Finn, and S. Levine. Bridgedata v2: A dataset for robot learning at scale. In J. Tan, M. Toussaint, and K. Darvish, editors,Proceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Re...
2023
-
[2]
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Herzog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakrishna, A. Wahid, B. Burgess-Limerick, B. Kim, B. Sch ¨olkopf,...
-
[3]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[5]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart´ın-Mart´ın, C. Wang, G. Levine, M. Lingelbach, J. Sun, M. Anvari, M. Hwang, M. Sharma, A. Aydin, D. Bansal, S. Hunter, K.-Y . Kim, A. Lou, C. R. Matthews, I. Villa-Renteria, J. H. Tang, C. Tang, F. Xia, S. Savarese, H. Gweon, K. Liu, J. Wu, and L. Fei-Fei. Behavior-1k: A benchmark for embodied ai...
2023
-
[6]
The 2025 BEHA VIOR challenge
Stanford Vision and Learning Lab. The 2025 BEHA VIOR challenge. NeurIPS 2025 Competition Track, 2025. URLhttps://behavior.stanford.edu/challenge/index.html
2025
-
[7]
Larchenko, G
I. Larchenko, G. Zarin, and A. Karnatak. Task adaptation of vision-language-action model: 1st place solution for the 2025 behavior challenge, 2025. URL https://arxiv.org/abs/2512. 06951
2025
-
[8]
Openpi comet: Competition solution for 2025 behavior challenge,
J. Bai, Y .-W. Chao, Q. Chen, J. Gu, M. J. Kim, Z. Li, X. Li, T.-Y . Lin, M.-Y . Liu, N. Ma, et al. Openpi comet: Competition solution for 2025 behavior challenge.arXiv preprint arXiv:2512.10071, 2025
-
[9]
How VLAs (Really) Work In Open-World Environments
A. Rasouli, Y . Wu, Z. Li, R. H. Yang, X. Zhao, C. Eret, and S. Pakdamansavoji. How vlas (really) work in open-world environments.arXiv preprint arXiv:2604.21192, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Z. Wu, A. Ma, X. Xu, H. Yin, Y . Liang, Z. Wang, J. Lu, and H. Yan. Moto: A zero-shot plug-in interaction-aware navigation for general mobile manipulation. In9th Annual Conference on Robot Learning, 2025. URLhttps://openreview.net/forum?id=Th1kFSnjUW
2025
- [11]
-
[12]
K. Gubernatorov, A. V oronov, R. V oronov, S. Pasynkov, S. Perminov, Z. Guo, and D. Tset- serukou. Anywherevla: Language-conditioned exploration and mobile manipulation, 2025. URLhttps://arxiv.org/abs/2509.21006
-
[13]
Konidaris and A
G. Konidaris and A. Barto. Skill discovery in continuous reinforcement learning domains using skill chaining. In Y . Bengio, D. Schuurmans, J. Lafferty, C. Williams, and A. Culotta, editors,Advances in Neural Information Processing Systems, volume 22. Curran Associates, Inc., 2009. URL https://proceedings.neurips.cc/paper_files/paper/2009/file/ e0cf1f4711...
2009
-
[14]
Z. Chen, Z. Ji, J. Huo, and Y . Gao. Scar: Refining skill chaining for long-horizon robotic manipulation via dual regularization.Advances in Neural Information Processing Systems, 37: 111679–111714, 2024
2024
- [15]
-
[16]
J. Wen, Y . Zhu, J. Li, Z. Tang, C. Shen, and F. Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [19]
- [20]
- [21]
-
[22]
${\pi}_{0.7}$: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
P. Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokinsky, S. Cao, T. Charbonnier, et al. π0.7: a steerable generalist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Z. Wu, Y . Zhou, X. Xu, Z. Wang, and H. Yan. MoManipVLA: Transferring Vision-language- action Models for General Mobile Manipulation . In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1714–1723, Los Alamitos, CA, USA, June
-
[24]
IEEE Computer Society. doi:10.1109/CVPR52734.2025.00167. URL https://doi. ieeecomputersociety.org/10.1109/CVPR52734.2025.00167
-
[25]
S. Raychaudhuri and A. X. Chang. Semantic mapping in indoor embodied ai–a comprehensive survey and future directions.arXiv preprint arXiv:2501.05750, 3, 2025
-
[26]
X. Song, X. Liang, and Z. Huaidong. Semantic mapping techniques for indoor mobile robots: Review and prospect.Measurement and Control, 58(3):377–393, 2025. doi: 10.1177/00202940241259903. URLhttps://doi.org/10.1177/00202940241259903
-
[27]
Srivastava, C
S. Srivastava, C. Li, M. Lingelbach, R. Mart´ın-Mart´ın, F. Xia, K. E. Vainio, Z. Lian, C. Gokmen, S. Buch, K. Liu, S. Savarese, H. Gweon, J. Wu, and L. Fei-Fei. BEHA VIOR: Benchmark for everyday household activities in virtual, interactive, and ecological environments. In Proceedings of the 5th Conference on Robot Learning, Proceedings of Machine Learnin...
2022
-
[28]
Karaman and E
S. Karaman and E. Frazzoli. Sampling-based algorithms for optimal motion planning.The International Journal of Robotics Research, 30(7):846–894, 2011
2011
-
[29]
Dolgov, S
D. Dolgov, S. Thrun, M. Montemerlo, and J. Diebel. Path planning for autonomous vehicles in unknown semi-structured environments.The International Journal of Robotics Research, 29(5): 485–501, 2010
2010
-
[30]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024
2024
-
[31]
Yamauchi
B. Yamauchi. A frontier-based approach for autonomous exploration. InProceedings 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation (CIRA’97), pages 146–151. IEEE, 1997
1997
-
[32]
Gemini Team, Google. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
C. Li, F. Xia, R. Mart´ın-Mart´ın, M. Lingelbach, S. Srivastava, B. Shen, K. E. Vainio, C. Gokmen, G. Dharan, T. Jain, A. Kurenkov, K. Liu, H. Gweon, J. Wu, L. Fei-Fei, and S. Savarese. igibson 2.0: Object-centric simulation for robot learning of everyday household tasks. In A. Faust, D. Hsu, and G. Neumann, editors,Proceedings of the 5th Conference on Ro...
-
[34]
URLhttps://proceedings.mlr.press/v164/li22b.html
-
[35]
J. Gu, E. Stefani, Q. Wu, J. Thomason, and X. Wang. Vision-and-language navigation: A survey of tasks, methods, and future directions. In S. Muresan, P. Nakov, and A. Villav- icencio, editors,Proceedings of the 60th Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long Papers), pages 7606–7623, Dublin, Ireland, May
-
[36]
doi:10.18653/v1/2022.acl-long.524
Association for Computational Linguistics. doi:10.18653/v1/2022.acl-long.524. URL https://aclanthology.org/2022.acl-long.524/
-
[37]
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models
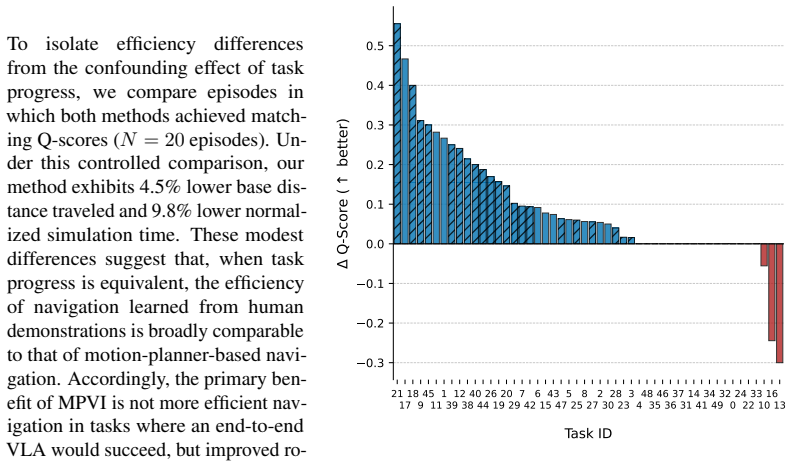
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg. ProgPrompt: Generating Situated Robot Task Plans using Large Language Models, Sept. 2022. URLhttp://arxiv.org/abs/2209.11302. arXiv:2209.11302. 12 A Appendix: Full Results Table 1: Q-Score Per Task Task ID Task End-to-End VLA Ours∆Q 21 collecting childrens ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
navigation
Type: "navigation" (move to a location) or "manipulation" (interact with objects)
-
[39]
Description: Brief description of the action
-
[40]
Completion criteria: Observable condition indicating segment is complete (describe the END STATE)
-
[41]
The object is in the container
Target: For navigation segments, the destination IMPORTANT for completion criteria: - Describe the terminal state, NOT the action - Good: "The object is in the container" - Bad: "The robot puts the object in the container" Output as JSON: ‘‘‘json { "task_name": "short task name", "segments": [ { "type": "navigation", "description": "Navigate to the kitche...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.