Curvature-aware dynamic precision approach for physics-informed neural networks
Pith reviewed 2026-06-28 07:30 UTC · model grok-4.3
The pith
A curvature controller from L-BFGS switches PINN training between FP32 and FP64 to match full double-precision accuracy at lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
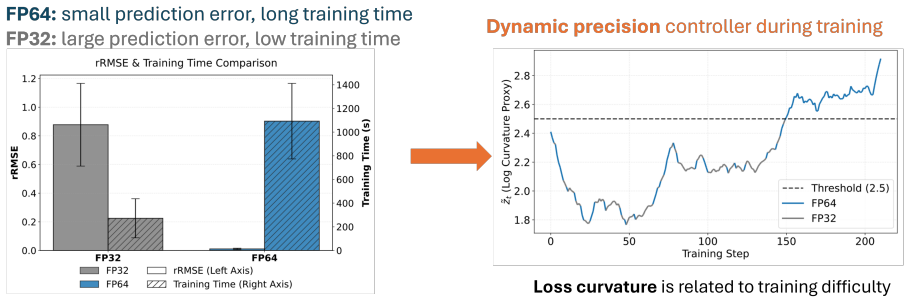
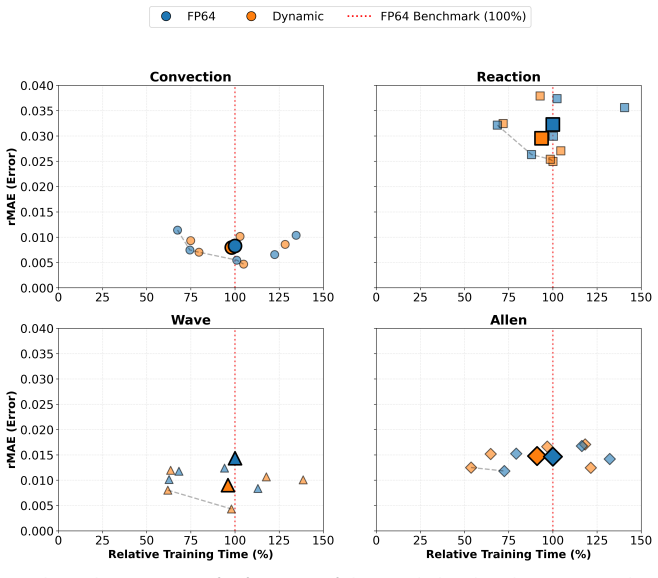
A precision controller constructed from L-BFGS curvature information detects phases of numerical sensitivity or stagnation and raises computation from FP32 to FP64 only during those intervals, producing predictions whose accuracy matches or exceeds that of full FP64 training while reducing wall-clock training time on all tested equations.
What carries the argument
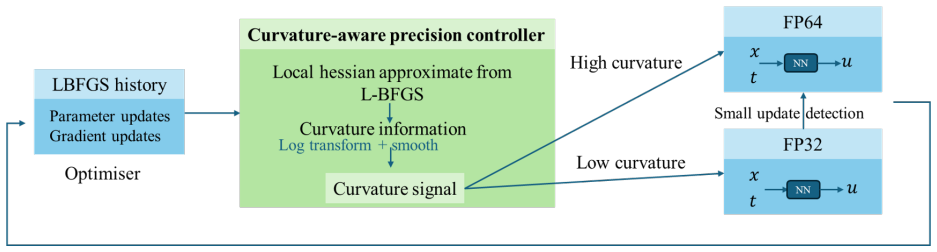
The curvature-aware precision controller, which converts second-derivative estimates already computed by L-BFGS into a signal that triggers an increase in floating-point precision when lower precision appears to limit progress.
If this is right
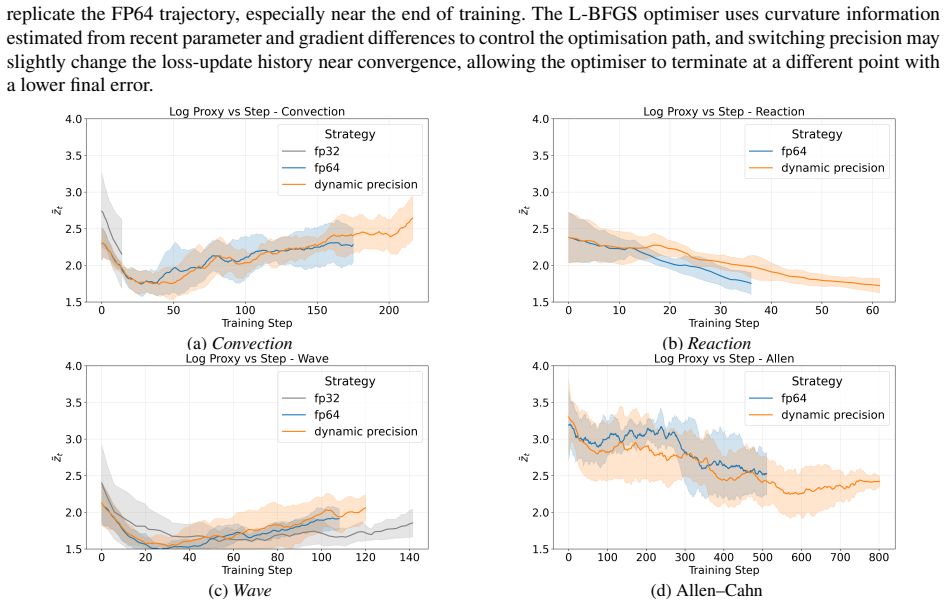
- Precision requirements during PINN training are phase-dependent rather than constant across the entire optimization.
- Higher precision can be applied selectively without sacrificing final solution quality on the tested PDEs and architectures.
- Training cost can be lowered on the same hardware by avoiding unnecessary FP64 operations outside critical intervals.
Where Pith is reading between the lines
- The same curvature signal might be usable with other second-order or quasi-Newton optimizers that already compute Hessian approximations.
- Further savings could be explored by testing an additional drop to FP16 during the safest low-curvature phases.
- The phase-dependent view suggests that memory-bandwidth limits in large-scale PINN training may also be addressable by dynamic precision rather than uniform high precision.
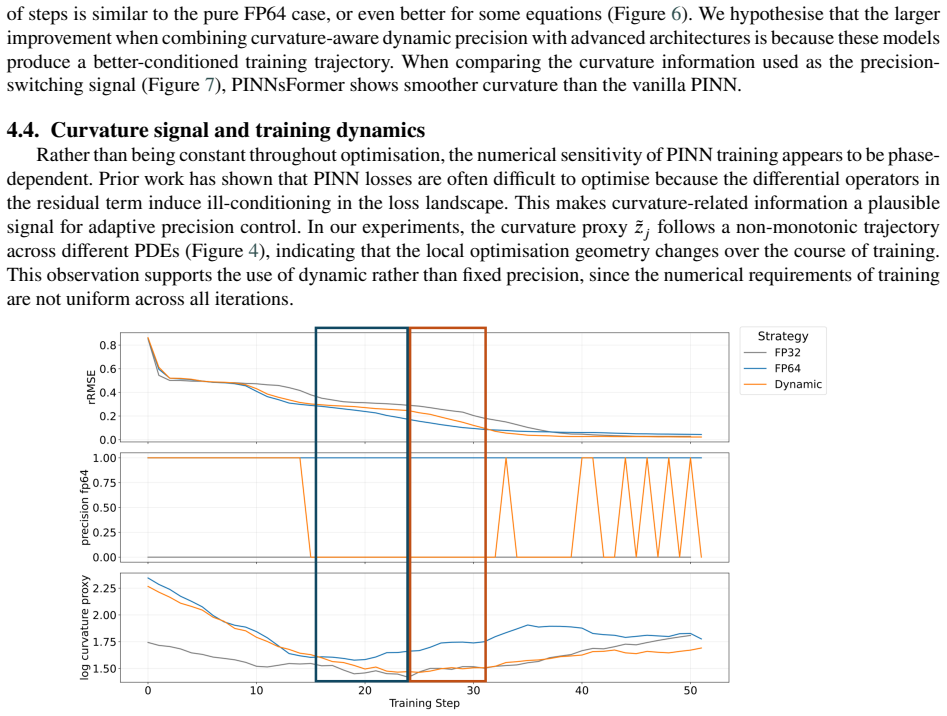
Load-bearing premise
Curvature values produced by L-BFGS reliably indicate when the current precision level is causing stagnation or numerical error in the loss landscape.
What would settle it
Apply the controller to a new PINN benchmark where the method either fails to reach FP64-level accuracy on the test points or shows no reduction in training time relative to constant FP64.
Figures
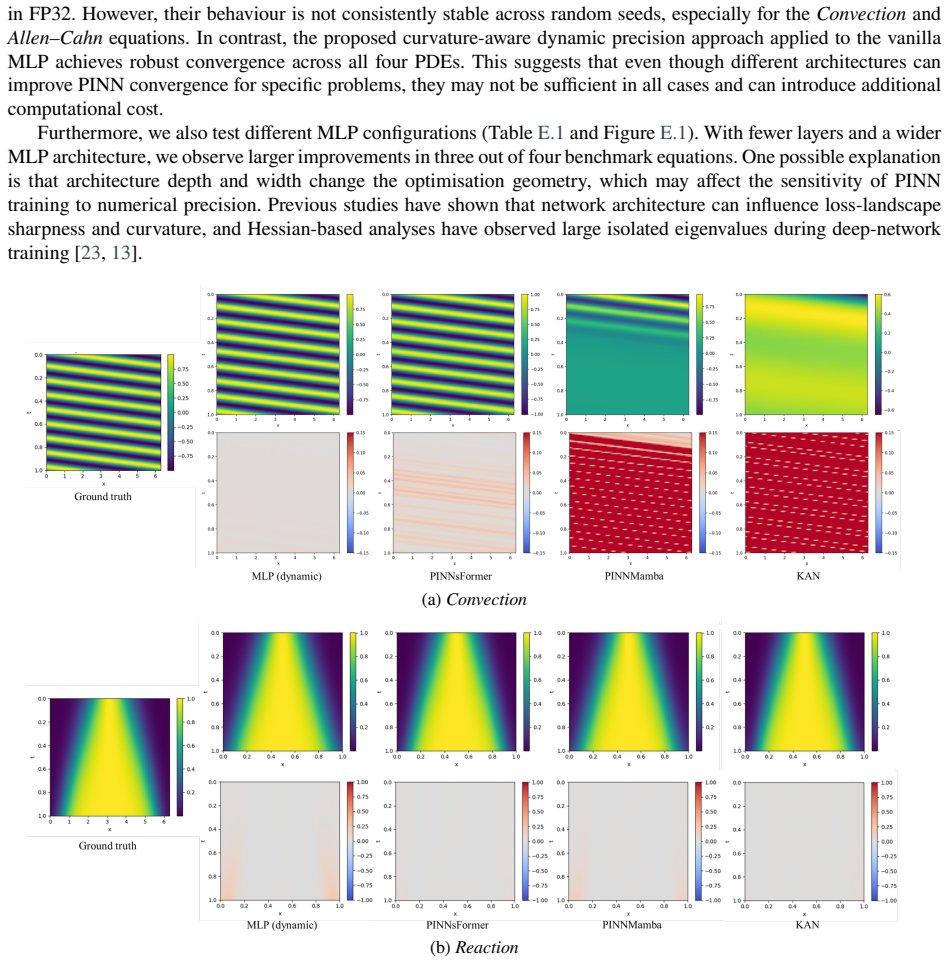
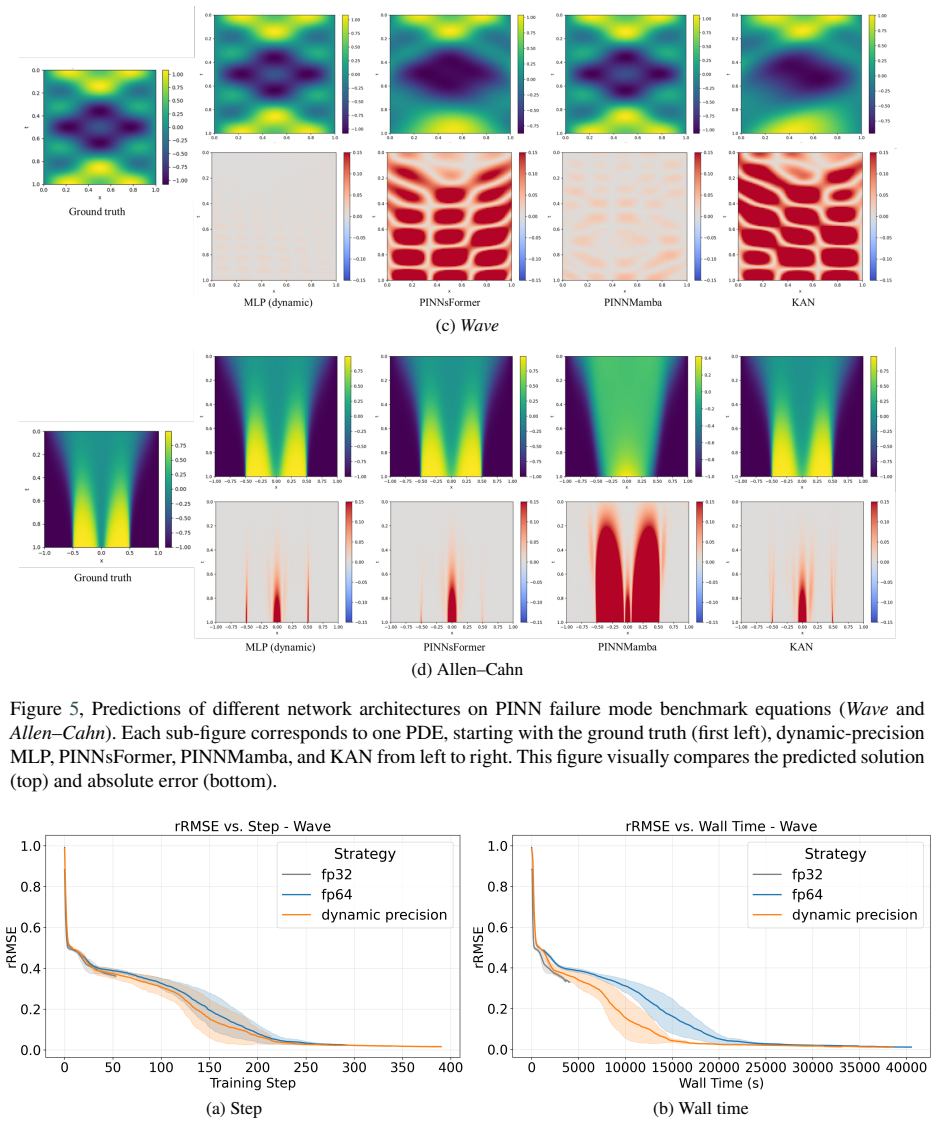
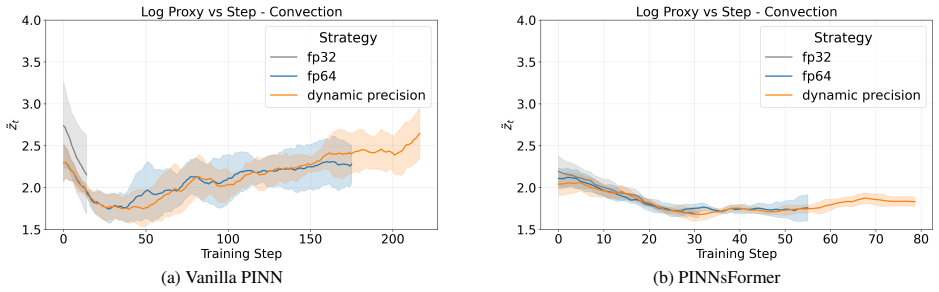
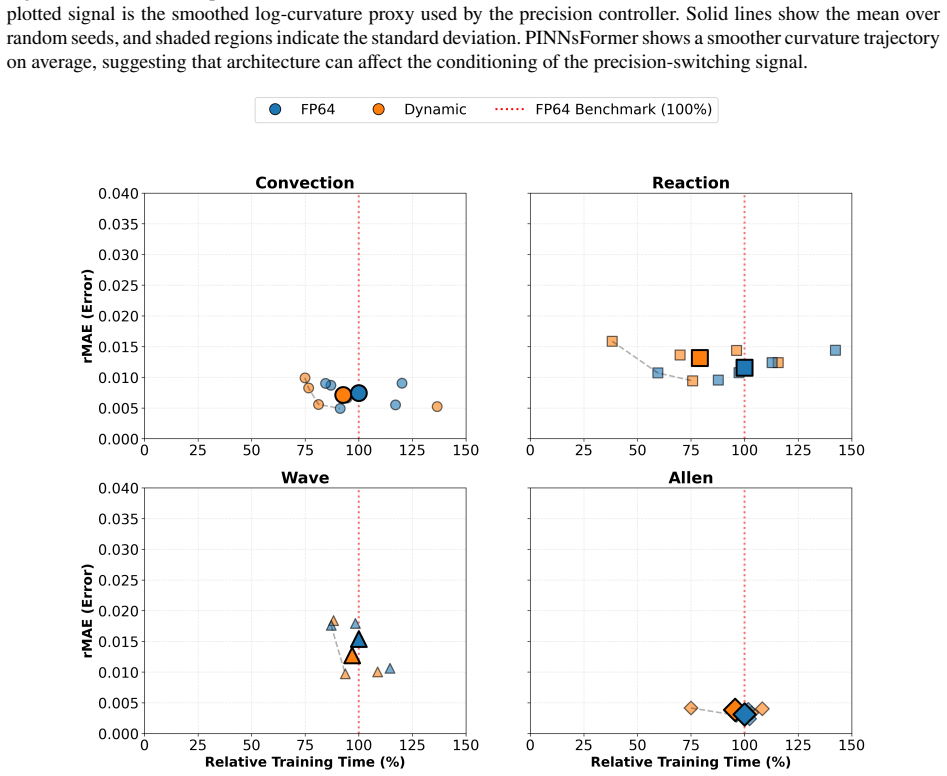
read the original abstract
Physics-informed neural networks (PINNs) have become a promising framework for simulating partial differential equations (PDEs) by embedding physical laws directly into neural network training. However, recent studies show that PINN optimisation is sensitive to numerical precision. Existing implementations commonly use either single precision (FP32), which is computationally efficient but prone to failure modes, or double precision (FP64), which is robust but substantially expensive. This creates a trade-off between computational efficiency and numerical accuracy. To reduce the computational cost of double-precision training while retaining prediction accuracy, we propose a curvature-aware precision controller that adapts numerical precision during training rather than treating it as a fixed implementation choice. The proposed method reuses curvature information derived from the limited-memory BFGS (L-BFGS) optimiser to construct a precision controller, retaining FP32 when lower precision is sufficient and promoting computation to FP64 when the training dynamics indicate numerical sensitivity or precision-limited stagnation. We evaluate the proposed approach on four canonical PINN failure-mode benchmarks and an irradiance-driven ordinary differential equation example. We further test the proposed approach across different neural network architectures. The method consistently matches or even slightly exceeds full FP64 solution accuracy while reducing training time relative to full double-precision training on all benchmark equations. The obtained results indicate that precision sensitivity in PINN optimisation is phase-dependent, and that selectively applying higher precision only during numerically critical stages can lower computational cost without sacrificing predictive accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a curvature-aware dynamic precision controller for PINNs that reuses L-BFGS curvature information to adaptively switch between FP32 and FP64 during training. It evaluates the approach on four canonical PINN failure-mode benchmarks plus an irradiance-driven ODE example, across multiple network architectures, and claims that the method consistently matches or exceeds full FP64 accuracy while reducing training time relative to fixed double-precision training. Precision sensitivity is characterized as phase-dependent.
Significance. If substantiated, the result would demonstrate a practical, low-overhead way to exploit phase-dependent numerical sensitivity in PINN optimization by selectively invoking higher precision only when L-BFGS curvature signals stagnation or sensitivity. Reusing existing optimizer state without new free parameters beyond thresholds is a clear strength and supports the efficiency claim.
major comments (2)
- [Abstract] Abstract: the central empirical claim that the controller 'consistently matches or even slightly exceeds full FP64 solution accuracy while reducing training time' is stated without any quantitative metrics, error values, or references to tables/figures showing effect sizes or wall-clock comparisons; this is load-bearing for assessing whether the performance result holds.
- [Evaluation section] Evaluation on benchmarks: the manuscript reports positive outcomes on the four canonical cases and the ODE example but supplies no specific quantitative metrics, implementation details, or analysis of potential failure cases, which prevents verification that the curvature controller reliably detects precision-limited phases.
minor comments (1)
- The abstract would be strengthened by including at least one concrete quantitative result (e.g., relative L2 error or time reduction) to summarize the empirical findings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive overall assessment. We address the two major comments below and will revise the manuscript to improve verifiability of the empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that the controller 'consistently matches or even slightly exceeds full FP64 solution accuracy while reducing training time' is stated without any quantitative metrics, error values, or references to tables/figures showing effect sizes or wall-clock comparisons; this is load-bearing for assessing whether the performance result holds.
Authors: We agree that the abstract should be more self-contained. In the revised version we will insert concise quantitative results (relative L2 errors and wall-clock speedups) together with explicit citations to the corresponding tables and figures that document the FP64-matching accuracy and reduced training time across the benchmarks. revision: yes
-
Referee: [Evaluation section] Evaluation on benchmarks: the manuscript reports positive outcomes on the four canonical cases and the ODE example but supplies no specific quantitative metrics, implementation details, or analysis of potential failure cases, which prevents verification that the curvature controller reliably detects precision-limited phases.
Authors: We acknowledge the need for greater detail. The revision will expand the evaluation section with tabulated error metrics and timing results for each benchmark and architecture, explicit controller threshold values, and a short subsection discussing observed edge cases or instances where curvature signals were ambiguous. These additions will allow direct verification of the phase-dependent detection behavior. revision: yes
Circularity Check
No circularity in empirical algorithmic proposal
full rationale
The paper proposes an algorithmic precision controller for PINN training that reuses standard L-BFGS curvature estimates to switch between FP32 and FP64. All load-bearing claims are empirical performance results on fixed benchmarks (four PDEs plus one ODE) with direct FP64 baselines; no derivation, prediction, or uniqueness theorem is offered that reduces to a fitted parameter, self-citation chain, or input by construction. The method is self-contained against external benchmarks and does not invoke any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- precision switching thresholds
axioms (1)
- domain assumption L-BFGS curvature information is available and indicative of numerical precision needs in PINN optimization
Reference graph
Works this paper leans on
-
[1]
PDE models for vegetation biomass and autotoxicity
Abbas, M., Giannino, F., Iuorio, A., Ahmad, Z., Calabró, F., 2025. PDE models for vegetation biomass and autotoxicity. Mathematics andComputersinSimulation228,386–401. URL:https://www.sciencedirect.com/science/article/pii/S0378475424002544, doi:10.1016/j.matcom.2024.07.004
-
[2]
Al-Baali, M., Spedicato, E., Maggioni, F., 2014. Broyden’s quasi-Newton methods for a nonlinear system of equations and unconstrained optimization: a review and open problems. Optimization Methods and Software 29, 937–954. doi:10.1080/10556788.2013.856909
-
[3]
Convex Optimization
Boyd, S., Vandenberghe, L., 2004. Convex Optimization. Cambridge University Press
2004
-
[4]
Acceleration of PDE-Based Biological Simulation Through the Development of Neural Network Metamodels
Burzawa, L., Li, L., Wang, X., Buganza-Tepole, A., Umulis, D.M., 2020. Acceleration of PDE-Based Biological Simulation Through the Development of Neural Network Metamodels. Current Pathobiology Reports 8, 121–131. URL:https://doi.org/10.1007/ s40139-020-00216-8, doi:10.1007/s40139-020-00216-8
-
[5]
Ananalysisandsolutionofill-conditioninginphysics-informedneuralnetworks
Cao,W.,Zhang,W.,2025. Ananalysisandsolutionofill-conditioninginphysics-informedneuralnetworks. JournalofComputationalPhysics 520, 113494. URL:https://www.sciencedirect.com/science/article/pii/S0021999124007423, doi:https://doi.org/10. 1016/j.jcp.2024.113494
arXiv 2025
-
[6]
Scientific Machine Learning Through Physics–Informed Neural Networks: Where we are and What’s Next
Cuomo, S., Di Cola, V.S., Giampaolo, F., Rozza, G., Raissi, M., Piccialli, F., 2022. Scientific Machine Learning Through Physics–Informed Neural Networks: Where we are and What’s Next. Journal of Scientific Computing 92, 88. URL:https://doi.org/10.1007/ s10915-022-01939-z, doi:10.1007/s10915-022-01939-z
-
[7]
Fasttrainingofaccurate physics-informedneuralnetworkswithoutgradientdescent,in:TheFourteenthInternationalConferenceonLearningRepresentations
Datar,C.,Kapoor,T.,Chandra,A.,Sun,Q.,Bolager,E.L.,Burak,I.,Veselovska,A.,Fornasier,M.,Dietrich,F.,2026. Fasttrainingofaccurate physics-informedneuralnetworkswithoutgradientdescent,in:TheFourteenthInternationalConferenceonLearningRepresentations. URL: https://openreview.net/forum?id=3VdSuh3sie
2026
-
[8]
Mitigating Propagation Failures in Physics-informed Neural Networks using Retain-Resample-Release (R3) Sampling, in: International Conference on Machine Learning, PMLR
Daw, A., Bu, J., Wang, S., Perdikaris, P., Karpatne, A., 2023. Mitigating Propagation Failures in Physics-informed Neural Networks using Retain-Resample-Release (R3) Sampling, in: International Conference on Machine Learning, PMLR. pp. 7264–7302
2023
-
[9]
HAWQ-V2: Hessian aware trace-Weighted quantization of neural networks, in: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H
Dong, Z., Yao, Z., Arfeen, D., Gholami, A., Mahoney, M.W., Keutzer, K., 2020. HAWQ-V2: Hessian aware trace-Weighted quantization of neural networks, in: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (Eds.), Advances in neural information processing systems, Curran Associates, Inc.. pp. 18518–18529. URL:https://proceedings.neurips.cc/paper_...
2020
-
[10]
Hawq: Hessian aware quantization of neural networks with mixed- precision, in: Proceedings of the IEEE/CVF international conference on computer vision, pp
Dong, Z., Yao, Z., Gholami, A., Mahoney, M.W., Keutzer, K., 2019. Hawq: Hessian aware quantization of neural networks with mixed- precision, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 293–302
2019
-
[11]
A family of embedded Runge-Kutta formulae
Dormand, J., Prince, P., 1980. A family of embedded Runge-Kutta formulae. Journal of Computational and Applied Mathematics 6, 19–26. URL:https://www.sciencedirect.com/science/article/pii/0771050X80900133, doi:10.1016/0771-050X(80)90013-3
-
[12]
Gao,Y.,Wang,B.,Lu,J.,Tian,Z.,2025. ML-PINN:Amemory-efficientphysics-informedMamba-LSTMnetworkforfastandaccuratePDE solving. Neurocomputing 655, 131446. doi:10.1016/j.neucom.2025.131446
-
[13]
Ghorbani,B.,Krishnan,S.,Xiao,Y.,2019.Theeffectofnetworkdepthontheoptimizationlandscape,in:ICML2019WorkshoponIdentifying and Understanding Deep Learning Phenomena
2019
-
[14]
Gie, G.M., Hong, Y., Jung, C.Y., Lee, D., 2026. Singular layer physics-informed neural network method for convection-dominated boundary layerproblemsintwodimensions. JournalofComputationalandAppliedMathematics474,116918. URL:https://www.sciencedirect. com/science/article/pii/S0377042725004327, doi:https://doi.org/10.1016/j.cam.2025.116918
-
[15]
Engineering Analysis with Boundary Elements 174, 106161
Gladstone,R.J.,Nabian,M.A.,Sukumar,N.,Srivastava,A.,Meidani,H.,2025.FO-PINN:afirst-orderformulationforphysics-informedneural networks. Engineering Analysis with Boundary Elements 174, 106161. URL:https://www.sciencedirect.com/science/article/ pii/S0955799725000499, doi:https://doi.org/10.1016/j.enganabound.2025.106161
-
[16]
Curvature-Aware Optimization for High-Accuracy Physics-Informed Neural Networks
Jnini, A., Kiyani, E., Shukla, K., Urban, J.F., Daryakenari, N.A., Muller, J., Zeinhofer, M., Karniadakis, G.E., 2026. Curvature-Aware Optimization for High-Accuracy Physics-Informed Neural Networks. arXiv preprint arXiv:2604.05230
Pith/arXiv arXiv 2026
-
[17]
Kapoor,T.,Wang,H.,Núñez,A.,Dollevoet,R.,2023. Physics-informedneuralnetworksforsolvingforwardandinverseproblemsincomplex beam systems. IEEE Transactions on Neural Networks and Learning Systems 35, 5981–5995. doi:10.1109/TNNLS.2023.3310585
-
[18]
Mixed-precision numerics in scientific applications: survey and perspectives
Kashi, A., Lu, H., Brewer, W., Rogers, D., Matheson, M., Shankar, M., Wang, F., 2026. Mixed-precision numerics in scientific applications: survey and perspectives. The Journal of Supercomputing 82, 287. URL:https://doi.org/10.1007/s11227-026-08264-4, doi:10. 1007/s11227-026-08264-4
-
[19]
Physics-informed neural networks for differential equation solutions: A comprehensive review
Khanra, S., Kukreja, V.K., Bala, I., 2026. Physics-informed neural networks for differential equation solutions: A comprehensive review. Neurocomputing 680, 133317. doi:10.1016/j.neucom.2026.133317
-
[20]
Implementing spectral methods for partial differential equations: Algorithms for scientists and engineers
Kopriva, D.A., 2009. Implementing spectral methods for partial differential equations: Algorithms for scientists and engineers. Springer Science & Business Media
2009
-
[21]
Characterizing possible failure modes in physics-informed neural networks
Krishnapriyan, A.S., Gholami, A., Zhe, S., Kirby, R.M., Mahoney, M.W., 2021. Characterizing possible failure modes in physics-informed neural networks. Advances in neural information processing systems 34, 26548–26560
2021
-
[22]
Adaptive Precision Training (AdaPT): A dynamic quantized training approach for DNNs, in: Proceedings of the 2023 SIAM International Conference on Data Mining (SDM), SIAM
Kummer, L., Sidak, K., Reichmann, T., Gansterer, W., 2023. Adaptive Precision Training (AdaPT): A dynamic quantized training approach for DNNs, in: Proceedings of the 2023 SIAM International Conference on Data Mining (SDM), SIAM. pp. 559–567
2023
-
[23]
Visualizing the loss landscape of neural nets
Li, H., Xu, Z., Taylor, G., Studer, C., Goldstein, T., 2018. Visualizing the loss landscape of neural nets. Advances in neural information processing systems 31, 6391–6401
2018
-
[24]
On the limited memory BFGS method for large scale optimization
Liu, D.C., Nocedal, J., 1989. On the limited memory BFGS method for large scale optimization. Mathematical Programming 45, 503–528. URL:https://doi.org/10.1007/BF01589116, doi:10.1007/BF01589116
-
[25]
KAN: Kolmogorov–Arnold Networks, in: The Thirteenth International Conference on Learning Representations
Liu, Z., Wang, Y., Vaidya, S., Ruehle, F., Halverson, J., Soljacic, M., Hou, T.Y., Tegmark, M., 2025. KAN: Kolmogorov–Arnold Networks, in: The Thirteenth International Conference on Learning Representations
2025
-
[26]
DeepXDE: a deep learning library for solving differential equations
Lu, L., Meng, X., Mao, Z., Karniadakis, G.E., 2021. DeepXDE: a deep learning library for solving differential equations. SIAM Review 63, 208–228. URL:https://doi.org/10.1137/19M1274067, doi:10.1137/19M1274067. tex.eprint: https://doi.org/10.1137/19M1274067. : Page 23 of 24
-
[27]
Partial differential equations: Modeling, analysis, computation
Mattheij, R., Rienstra, S., Boonkkamp, J., 2005. Partial differential equations: Modeling, analysis, computation. Mathematical modeling and computation, Society for Industrial and Applied Mathematics (SIAM, 3600 Market Street, Floor 6, Philadelphia, PA 19104). URL: https://books.google.nl/books?id=eNoEWxLes38C. tex.lccn: 2005049795
2005
-
[28]
Mixed precision training with 8-bit floating point
Mellempudi, N., Srinivasan, S., Das, D., Kaul, B., 2019. Mixed precision training with 8-bit floating point. arXiv preprint arXiv:1905.12334
Pith/arXiv arXiv 2019
-
[29]
Micikevicius, P., Narang, S., Alben, J., Diamos, G., Elsen, E., Garcia, D., Ginsburg, B., Houston, M., Kuchaiev, O., Venkatesh, G., Wu, H.,
-
[30]
Mixed Precision Training, in: International Conference on Learning Representations
-
[31]
Achieving High Accuracy with PINNs via Energy Natural Gradient Descent, in: Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J
Müller, J., Zeinhofer, M., 2023. Achieving High Accuracy with PINNs via Energy Natural Gradient Descent, in: Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J. (Eds.), Proceedings of the 40th International Conference on Machine Learning, PMLR. pp. 25471–25485. URL:https://proceedings.mlr.press/v202/muller23b.html
2023
-
[32]
Efficienttrainingofphysics-informedneuralnetworksviaimportancesampling
Nabian,M.A.,Gladstone,R.J.,Meidani,H.,2021. Efficienttrainingofphysics-informedneuralnetworksviaimportancesampling. Computer- AidedCivilandInfrastructureEngineering36,962–977. URL:https://onlinelibrary.wiley.com/doi/abs/10.1111/mice.12685, doi:https://doi.org/10.1111/mice.12685,arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1111/mice.12685
-
[33]
Updating Quasi-Newton Matrices With Limited Storage
Nocedal, J., 1980. Updating Quasi-Newton Matrices With Limited Storage. Mathematics of Computation 35, 773–782. URL:https: //api.semanticscholar.org/CorpusID:9033333, doi:10.1090/S0025-5718-1980-0572855-7
-
[34]
Raissi, M., Perdikaris, P., Karniadakis, G., 2019. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics 378, 686–707. URL:https://www. sciencedirect.com/science/article/pii/S0021999118307125, doi:https://doi.org/10.1016/j.jc...
-
[35]
Multi-precision policy enforced training (MuPPET): A precision-switching strategy for quantised fixed-point training of CNNs, in: International Conference on Machine Learning, PMLR
Rajagopal, A., Vink, D., Venieris, S., Bouganis, C.S., 2020. Multi-precision policy enforced training (MuPPET): A precision-switching strategy for quantised fixed-point training of CNNs, in: International Conference on Machine Learning, PMLR. pp. 7943–7952
2020
-
[36]
Challenges in Training PINNs: A Loss Landscape Perspective, in: Proceedings of the 41st International Conference on Machine Learning, PMLR
Rathore, P., Lei, W., Frangella, Z., Lu, L., Udell, M., 2024. Challenges in Training PINNs: A Loss Landscape Perspective, in: Proceedings of the 41st International Conference on Machine Learning, PMLR. pp. 42159–42191
2024
-
[37]
Control Chart Tests Based on Geometric Moving Averages
Roberts, S.W., 1959. Control Chart Tests Based on Geometric Moving Averages. Technometrics 1, 239–250. URL:http://www.jstor. org/stable/1266443
arXiv 1959
-
[38]
A noise-tolerant quasi-newton algorithm for unconstrained optimization
Shi, H.J.M., Xie, Y., Byrd, R., Nocedal, J., 2022. A noise-tolerant quasi-newton algorithm for unconstrained optimization. SIAM Journal on Optimization 32, 29–55. URL:https://doi.org/10.1137/20M1373190, doi:10.1137/20M1373190. tex.eprint: https://doi.org/10.1137/20M1373190
-
[39]
The Logarithmic Transformation
Stevens, W.L., 1946. The Logarithmic Transformation. Nature 158, 622–622. URL:https://doi.org/10.1038/158622b0, doi:10. 1038/158622b0
-
[40]
DAS-PINNs:Adeepadaptivesamplingmethodforsolvinghigh-dimensionalpartialdifferentialequations
Tang,K.,Wan,X.,Yang,C.,2023. DAS-PINNs:Adeepadaptivesamplingmethodforsolvinghigh-dimensionalpartialdifferentialequations. Journal of Computational Physics 476, 111868. doi:10.1016/j.jcp.2022.111868
-
[41]
Trefethen,L.N.,Bau,D.,. PartV:Eigenvalues. pp.179–240. URL:https://epubs.siam.org/doi/abs/10.1137/1.9781611977165. ch5, doi:10.1137/1.9781611977165.ch5,arXiv:https://epubs.siam.org/doi/pdf/10.1137/1.9781611977165.ch5
-
[42]
Urbán, J.F., Stefanou, P., Pons, J.A., 2025. Unveiling the optimization process of physics informed neural networks: How accurate and competitive can PINNs be? Journal of Computational Physics 523, 113656. URL:https://www.sciencedirect.com/science/ article/pii/S0021999124009045, doi:https://doi.org/10.1016/j.jcp.2024.113656
-
[43]
van Voorn, G.A.K., Boer, M.P., Truong, S.H., Friedenberg, N.A., Gugushvili, S., McCormick, R., Bustos Korts, D., Messina, C.D., van Eeuwijk, F.A., 2023. A conceptual framework for the dynamic modeling of time-resolved phenotypes for sets of genotype-environment- management combinations: a model library. Frontiers in Plant Science Volume 14 - 2023. URL:htt...
-
[44]
When and why PINNs fail to train: A neural tangent kernel perspective
Wang, S., Yu, X., Perdikaris, P., 2022. When and why PINNs fail to train: A neural tangent kernel perspective. Journal of Computational Physics 449, 110768. doi:10.1016/j.jcp.2021.110768
-
[45]
Kolmogorov–Arnold-Informedneuralnetwork: A physics-informed deep learning framework for solving forward and inverse problems based on Kolmogorov–Arnold Networks
Wang,Y.,Sun,J.,Bai,J.,Anitescu,C.,Eshaghi,M.S.,Zhuang,X.,Rabczuk,T.,Liu,Y.,2025. Kolmogorov–Arnold-Informedneuralnetwork: A physics-informed deep learning framework for solving forward and inverse problems based on Kolmogorov–Arnold Networks. Computer Methods in Applied Mechanics and Engineering 433, 117518
2025
-
[46]
Acomprehensivestudyofnon-adaptiveandresidual-basedadaptivesamplingforphysics- informedneuralnetworks
Wu,C.,Zhu,M.,Tan,Q.,Kartha,Y.,Lu,L.,2023. Acomprehensivestudyofnon-adaptiveandresidual-basedadaptivesamplingforphysics- informedneuralnetworks. ComputerMethodsinAppliedMechanicsandEngineering403,115671. URL:https://www.sciencedirect. com/science/article/pii/S0045782522006260, doi:https://doi.org/10.1016/j.cma.2022.115671
-
[47]
Self-adaptive loss balanced Physics-informed neural networks
Xiang, Z., Peng, W., Liu, X., Yao, W., 2022. Self-adaptive loss balanced Physics-informed neural networks. Neurocomputing 496, 11–34. doi:10.1016/j.neucom.2022.05.015
-
[48]
Analysis of the BFGS method with errors
Xie, Y., Byrd, R.H., Nocedal, J., 2020. Analysis of the BFGS method with errors. SIAM Journal on Optimization 30, 182–209. URL: https://doi.org/10.1137/19M1240794, doi:10.1137/19M1240794. tex.eprint: https://doi.org/10.1137/19M1240794
-
[49]
Xu, C., Liu, D., Hu, Y., Li, J., Qin, R., Zheng, Q., Xiong, J., 2025a. Sub-Sequential Physics-Informed Learning with State Space Model, in: Proceedings of the 42nd International Conference on Machine Learning, PMLR. ArXiv:2502.00318
-
[50]
FP64 is All You Need: Rethinking Failure Modes in Physics-Informed Neural Networks
Xu, C., Liu, D., Nassereldine, A., Xiong, J., 2025b. FP64 is All You Need: Rethinking Failure Modes in Physics-Informed Neural Networks. Advances in Neural Information Processing Systems ArXiv:2505.10949
-
[51]
A novel automatic mixed precision approach for physics informed training, in: Machine Learning and the Physical Sciences Workshop, NeurIPS 2022
Xue, J., Subramaniam, A., Hoemmen, M., 2022. A novel automatic mixed precision approach for physics informed training, in: Machine Learning and the Physical Sciences Workshop, NeurIPS 2022
2022
-
[52]
Zhao, R., Vogel, B., Ahmed, T., Luk, W., 2021. Reducing underflow in mixed precision training by gradient scaling, in: Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, pp. 2922–2928. doi:10.24963/ijcai.2020/404
-
[53]
Zhao, Z., Ding, X., Prakash, B.A., 2024. PINNsFormer: A Transformer-Based Framework For Physics-Informed Neural Networks, in: The Twelfth International Conference on Learning Representations. ArXiv:2307.11833. : Page 24 of 24
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.