Recognition: 2 theorem links
· Lean TheoremCurvature-Aware Optimization for High-Accuracy Physics-Informed Neural Networks
Pith reviewed 2026-05-10 18:52 UTC · model grok-4.3
The pith
Curvature-aware optimizers like natural gradient and self-scaling BFGS accelerate PINN convergence to high accuracy on complex differential equations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By using curvature-aware optimization techniques including the natural gradient and quasi-Newton methods, PINNs can achieve faster convergence and higher accuracy when solving partial and ordinary differential equations that are difficult for standard optimizers.
What carries the argument
Natural Gradient optimizer and Self-Scaling BFGS/Broyden quasi-Newton methods, which approximate the curvature of the loss landscape to provide better update directions for training PINNs.
If this is right
- High-accuracy solutions for inviscid flows and stiff systems become feasible with PINNs.
- Quasi-Newton methods can be scaled for batched training in large-scale scientific ML.
- New PINN formulations for Burgers and Euler equations match high-order numerical accuracy.
Where Pith is reading between the lines
- These optimizers might reduce the need for architecture-specific tuning in PINNs across different physical domains.
- Integration with other ML techniques could further improve performance on high-dimensional problems.
- Similar curvature-aware methods could apply to other scientific computing neural network tasks beyond PINNs.
Load-bearing premise
That the curvature information from these optimizers can be computed and applied efficiently at scale for batched training without prohibitive memory or time costs.
What would settle it
A demonstration that on one of the tested equations, such as the inviscid Burgers, the new optimizers fail to reach the accuracy of high-order numerical methods within reasonable training time or resources.
Figures




















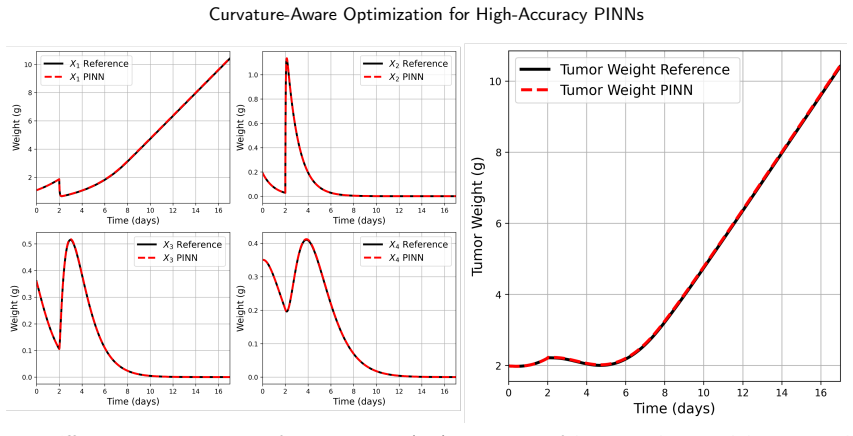



read the original abstract
Efficient and robust optimization is essential for neural networks, enabling scientific machine learning models to converge rapidly to very high accuracy -- faithfully capturing complex physical behavior governed by differential equations. In this work, we present advanced optimization strategies to accelerate the convergence of physics-informed neural networks (PINNs) for challenging partial (PDEs) and ordinary differential equations (ODEs). Specifically, we provide efficient implementations of the Natural Gradient (NG) optimizer, Self-Scaling BFGS and Broyden optimizers, and demonstrate their performance on problems including the Helmholtz equation, Stokes flow, inviscid Burgers equation, Euler equations for high-speed flows, and stiff ODEs arising in pharmacokinetics and pharmacodynamics. Beyond optimizer development, we also propose new PINN-based methods for solving the inviscid Burgers and Euler equations, and compare the resulting solutions against high-order numerical methods to provide a rigorous and fair assessment. Finally, we address the challenge of scaling these quasi-Newton optimizers for batched training, enabling efficient and scalable solutions for large data-driven problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces efficient implementations of curvature-aware optimizers (Natural Gradient, self-scaling BFGS, and Broyden) for physics-informed neural networks (PINNs) applied to challenging PDEs and ODEs, including the Helmholtz equation, Stokes flow, inviscid Burgers equation, Euler equations for high-speed flows, and stiff ODEs from pharmacokinetics/pharmacodynamics. It proposes new PINN formulations for the inviscid Burgers and Euler equations with comparisons against high-order numerical methods, and develops a scaling approach to enable batched training with these quasi-Newton methods.
Significance. If the reported convergence and accuracy improvements are substantiated, the work would provide practical, scalable tools for high-fidelity scientific machine learning on differential equations. The explicit comparisons to high-order numerics and the batched-training scaling strategy are strengths that support reproducibility and broader applicability.
minor comments (2)
- [Abstract] Abstract: the claim of performance gains on multiple benchmark problems is stated without any quantitative metrics, error norms, or convergence rates; adding a short summary of key results (e.g., final L2 errors or iteration counts) would make the abstract self-contained.
- [Section on batched training] Implementation details for the batched quasi-Newton scaling (mentioned in the final paragraph) should include explicit pseudocode or complexity analysis to clarify how curvature information is maintained across batches without prohibitive memory cost.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work on curvature-aware optimizers for PINNs and for recommending minor revision. The assessment correctly identifies the key contributions, including efficient implementations of Natural Gradient, self-scaling BFGS, and Broyden methods, new PINN formulations for inviscid Burgers and Euler equations with high-order numerical comparisons, and the batched scaling strategy for quasi-Newton methods. No specific major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The manuscript presents algorithmic implementations of established curvature-aware optimizers (Natural Gradient, self-scaling BFGS, Broyden) together with empirical benchmarks on standard PDE/ODE test problems. No derivation chain is claimed that reduces a first-principles result or prediction to its own fitted inputs by construction. The work is framed as engineering and numerical demonstration rather than a closed mathematical derivation; therefore no self-definitional, fitted-input-renamed-as-prediction, or self-citation-load-bearing steps are present. All performance claims rest on direct comparison with high-order numerical references, which are external to the optimizer formulations themselves.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We provide efficient implementations of the Natural Gradient (NG) optimizer, Self-Scaling BFGS and Broyden optimizers... Gauss–Newton introduce the approximate Hessian H_k ≈ J^T_k J_k
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
loss landscape in parameter space... projections onto pairs of singular vectors... NG updates correct the error much better
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
GRAFT-ATHENA: Self-Improving Agentic Teams for Autonomous Discovery and Evolutionary Numerical Algorithms
GRAFT-ATHENA projects combinatorial method choices into factored trees that embed as fingerprints in a metric space, enabling an agentic system to accumulate experience across domains and autonomously discover new num...
-
Convergence Analysis of Newton's Method for Neural Networks in the Overparameterized Limit
In the infinite-width limit, regularized Newton's method for neural networks converges exponentially to global minimizers with uniform rates across the frequency spectrum using the Newton neural tangent kernel.
-
A Physics-Informed Neural Network for Solving the Quasi-static Magnetohydrodynamic Equations
A PINN solves the time-dependent quasi-static MHD equations in axisymmetric tokamak geometry without training data and reproduces vertical plasma displacement seen in ground-truth simulations.
-
Lightweight Geometric Adaptation for Training Physics-Informed Neural Networks
A secant-based adaptive correction augments first-order optimizers to improve convergence speed, stability, and accuracy when training PINNs on challenging PDEs.
-
Two-scale Neural Networks for Singularly Perturbed Dynamical Systems with Multiple Parameters
A neural network augmented with the geometric mean of multiple small parameters approximates solutions to singularly perturbed dynamical systems with satisfactory accuracy on tested coupled cases.
Reference graph
Works this paper leans on
-
[1]
Physics-informed machine learning in biomedical science and engineering
Ahmadi, N., Cao, Q., Humphrey, J.D., Karniadakis, G.E., 2025. Physics-informed machine learning in biomedical science and engineering. arXiv preprint arXiv:2510.05433
-
[2]
Ahmadi Daryakenari, N., Shukla, K., Karniadakis, G.E., 2026. Representation meets optimization: Training PINNs and PIKANs for gray- box discovery in systems pharmacology. Computers in Biology and Medicine 201, 111393. URL:https://www.sciencedirect.com/ science/article/pii/S0010482525017470, doi:https://doi.org/10.1016/j.compbiomed.2025.111393
-
[3]
Global and superlinear convergence of a class of self-scaling methods with inexact line searches
Al-Baali, M., 1998. Global and superlinear convergence of a class of self-scaling methods with inexact line searches. Computational Optimization and Applications 9, 191–203. doi:10.1023/A:1018315205474
-
[4]
Wide interval for efficient self-scaling quasi-newton algorithms
Al-Baali, M., Khalfan, H., 2005. Wide interval for efficient self-scaling quasi-newton algorithms. Optimization Methods and Software 20, 679–691. doi:10.1080/10556780410001709448
-
[5]
Al-Baali, M., Spedicato, E., Maggioni, F., 2014. Broyden’s quasi-newton methods for a nonlinear system of equations and unconstrained optimization: A review and open problems. Optimization Methods and Software 29, 937–954. doi:10.1080/10556788.2013.856909
-
[6]
Information geometry
Amari, S., 1997. Information geometry. Contemporary Mathematics 203, 4
1997
-
[7]
Naturalgradientworksefficientlyinlearning
ichiAmari,S.,1998. Naturalgradientworksefficientlyinlearning. NeuralComputation10,251–276. doi:10.1162/089976698300017746
-
[8]
Functional neural wavefunction optimization
Armegioiu, V., Carrasquilla, J., Mishra, S., Müller, J., Nys, J., Zeinhofer, M., Zhang, H., 2025. Functional neural wavefunction optimization. arXiv preprint arXiv:2507.10835
-
[9]
Ontheoptimizationofdeepnetworks:Implicitaccelerationbyoverparameterization,in:International conference on machine learning, PMLR
Arora,S.,Cohen,N.,Hazan,E.,2018. Ontheoptimizationofdeepnetworks:Implicitaccelerationbyoverparameterization,in:International conference on machine learning, PMLR. pp. 244–253
2018
-
[10]
A progressive batching l-bfgs method for machine learning, in: International Conference on Machine Learning, PMLR
Bollapragada, R., Nocedal, J., Mudigere, D., Shi, H.J., Tang, P.T.P., 2018. A progressive batching l-bfgs method for machine learning, in: International Conference on Machine Learning, PMLR. pp. 620–629
2018
-
[11]
The convergence of a class of double-rank minimization algorithms 1
Broyden, C.G., 1970. The convergence of a class of double-rank minimization algorithms 1. general considerations. IMA Journal of Applied Mathematics 6, 76–90. doi:10.1093/imamat/6.1.76
-
[12]
Nektar++: An open-source spectral/hp element framework
Cantwell, C.D., Moxey, D., Comerford, A., Bolis, A., Rocco, G., Mengaldo, G., De Grazia, D., Yakovlev, S., Lombard, J.E., Ekelschot, D., et al., 2015. Nektar++: An open-source spectral/hp element framework. Computer physics communications 192, 205–219
2015
-
[13]
Ondiscretelyentropyconservativeandentropystablediscontinuousgalerkinmethods
Chan,J.,2018. Ondiscretelyentropyconservativeandentropystablediscontinuousgalerkinmethods. JournalofComputationalPhysics362, 346–374
2018
-
[14]
Separablephysics-informedneuralnetworks
Cho,J.,Nam,S.,Yang,H.,Yun,S.B.,Hong,Y.,Park,E.,2023. Separablephysics-informedneuralnetworks. AdvancesinNeuralInformation Processing Systems 36, 23761–23788
2023
-
[15]
Trust region methods
Conn, A.R., Gould, N.I., Toint, P.L., 2000. Trust region methods. SIAM
2000
-
[16]
Kronecker-factored approximate curvature for physics-informed neural networks
Dangel, F., Müller, J., Zeinhofer, M., 2024. Kronecker-factored approximate curvature for physics-informed neural networks. Advances in Neural Information Processing Systems 37, 34582–34636. Jnini et al.:Preprint submitted to ElsevierPage 47 of 53 Curvature-Aware Optimization for High-Accuracy PINNs
2024
-
[17]
CMINNs: Compartment model informed neural networks—unlocking drug dynamics
Daryakenari, N.A., Wang, S., Karniadakis, G., 2025. CMINNs: Compartment model informed neural networks—unlocking drug dynamics. Computers in Biology and Medicine 184, 109392
2025
-
[18]
Variable Metric Method for Minimization
Davidon, W.C., 1959. Variable Metric Method for Minimization. Technical Report ANL-5990. Argonne National Laboratory
1959
-
[19]
Numerical Methods for Unconstrained Optimization and Nonlinear Equations
Dennis Jr, J., Schnabel, R.B., 1996. Numerical Methods for Unconstrained Optimization and Nonlinear Equations. SIAM
1996
-
[20]
Adaptive Subgradient Methods for Online Learning and Stochastic Optimization
Duchi, J., Hazan, E., Singer, Y., 2011. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. Journal of Machine Learning Research 12, 2121–2159. URL:http://jmlr.org/papers/v12/duchi11a.html
2011
-
[21]
Gradient-annihilated pinns for solving riemannproblems:Applicationtorelativistichydrodynamics
Ferrer-Sánchez, A., Martín-Guerrero, J.D., de Austri-Bazan, R.R., Torres-Forné, A., Font, J.A., 2024. Gradient-annihilated pinns for solving riemannproblems:Applicationtorelativistichydrodynamics. ComputerMethodsinAppliedMechanicsandEngineering424,116906. URL: https://www.sciencedirect.com/science/article/pii/S0045782524001622, doi:https://doi.org/10.1016...
-
[22]
Fischer,P.,Kerkemeier,S.,Min,M.,Lan,Y.H.,Phillips,M.,Rathnayake,T.,Merzari,E.,Tomboulides,A.,Karakus,A.,Chalmers,N.,etal.,
-
[23]
Parallel Computing 114, 102982
Nekrs, a gpu-accelerated spectral element navier–stokes solver. Parallel Computing 114, 102982
-
[24]
Fletcher, R., 1970. A new approach to variable metric algorithms. The Computer Journal 13, 317–322. doi:10.1093/comjnl/13.3.317
-
[25]
Arapidlyconvergentdescentmethodforminimization
Fletcher,R.,Powell,M.J.D.,1963. Arapidlyconvergentdescentmethodforminimization. TheComputerJournal6,163–168. doi:10.1093/ comjnl/6.2.163
1963
-
[26]
A family of variable-metric methods derived by variational means
Goldfarb, D., 1970. A family of variable-metric methods derived by variational means. Mathematics of Computation 24, 23–26. doi:10.1090/S0025-5718-1970-0258249-6
-
[27]
Journal of Computational Physics 516, 113351
Goldshlager,G.,Abrahamsen,N.,Lin,L.,2024.Akaczmarz-inspiredapproachtoacceleratetheoptimizationofneuralnetworkwavefunctions. Journal of Computational Physics 516, 113351
2024
-
[28]
A sketch-and-project analysis of subsampled natural gradient algorithms
Goldshlager, G., Hu, J., Lin, L., 2025. A sketch-and-project analysis of subsampled natural gradient algorithms. arXiv preprint arXiv:2508.21022
-
[29]
Deep learning
Goodfellow, I., Bengio, Y., Courville, A., Bengio, Y., 2016. Deep learning. volume 1. MIT press Cambridge
2016
-
[30]
Shampoo: Preconditioned stochastic tensor optimization, in: Proceedings of the 35th International Conference on Machine Learning (ICML)
Gupta, V., Koren, T., Singer, Y., 2018. Shampoo: Preconditioned stochastic tensor optimization, in: Proceedings of the 35th International Conference on Machine Learning (ICML)
2018
-
[31]
Improving energy natural gradient descent through woodbury, momentum, and randomization, in: The Thirty-ninth Annual Conference on Neural Information Processing Systems
Guzman-Cordero, A., Dangel, F., Goldshlager, G., Zeinhofer, M., 2025. Improving energy natural gradient descent through woodbury, momentum, and randomization, in: The Thirty-ninth Annual Conference on Neural Information Processing Systems. URL:https: //openreview.net/forum?id=5YMZfufpfY
2025
-
[32]
Aprovablyentropystablesubcellshockcapturingapproachfor high order split form dg for the compressible euler equations
Hennemann,S.,Rueda-Ramírez,A.M.,Hindenlang,F.J.,Gassner,G.J.,2021. Aprovablyentropystablesubcellshockcapturingapproachfor high order split form dg for the compressible euler equations. Journal of Computational Physics 426, 109935
2021
-
[33]
Numerical methods for conservation laws: From analysis to algorithms
Hesthaven, J.S., 2017. Numerical methods for conservation laws: From analysis to algorithms. SIAM
2017
-
[34]
State-space models are accurate and efficient neural operators for dynamical systems
Hu, Z., Daryakenari, N.A., Shen, Q., Kawaguchi, K., Karniadakis, G.E., 2024. State-space models are accurate and efficient neural operators for dynamical systems. arXiv preprint arXiv:2409.03231
-
[35]
Dual cone gradient descent for training physics-informed neural networks
Hwang, Y., Lim, D.Y., 2024. Dual cone gradient descent for training physics-informed neural networks. Advances in Neural Information Processing Systems 37, 98563–98595
2024
-
[36]
Conservative physics-informed neural networks on discrete domains for conservation laws: Applications to forward and inverse problems
Jagtap, A.D., Kharazmi, E., Karniadakis, G.E., 2020. Conservative physics-informed neural networks on discrete domains for conservation laws: Applications to forward and inverse problems. Computer Methods in Applied Mechanics and Engineering 365, 113028
2020
-
[37]
Physics-informed neural networks for inverse problems in supersonic flows
Jagtap, A.D., Mao, Z., Adams, N., Karniadakis, G.E., 2022. Physics-informed neural networks for inverse problems in supersonic flows. Journal of Computational Physics 466, 111402
2022
-
[38]
Dual natural gradient descent for scalable training of physics-informed neural networks
Jnini, A., Vella, F., 2025. Dual natural gradient descent for scalable training of physics-informed neural networks. Transactions on Machine Learning Research URL:https://openreview.net/forum?id=GDHVRy6SDd
2025
-
[39]
Gauss-Newton Natural Gradient Descent for Physics-informed Computational Fluid Dynamics
Jnini, A., Vella, F., Zeinhofer, M., 2025. Gauss-Newton Natural Gradient Descent for Physics-informed Computational Fluid Dynamics. Computers & Fluids , 106955
2025
-
[40]
Spectral/hp element methods for computational fluid dynamics
Karniadakis, G., Sherwin, S., 2013. Spectral/hp element methods for computational fluid dynamics. American Chemical Society
2013
-
[41]
Deep learning without poor local minima
Kawaguchi, K., 2016. Deep learning without poor local minima. Advances in neural information processing systems 29
2016
-
[42]
Adam: A Method for Stochastic Optimization
Kingma, D.P., 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[43]
Kiyani, E., Shukla, K., Karniadakis, G.E., Karttunen, M., 2023. A framework based on symbolic regression coupled with extended physics- informedneuralnetworksforgray-boxlearningofequationsofmotionfromdata. ComputerMethodsinAppliedMechanicsandEngineering 415, 116258. doi:https://doi.org/10.1016/j.cma.2023.116258
-
[44]
Optimizing the optimizer for physics-informed neural networks and kolmogorov-arnold networks
Kiyani, E., Shukla, K., Urbán, J.F., Darbon, J., Karniadakis, G.E., 2025. Optimizing the optimizer for physics-informed neural networks and kolmogorov-arnold networks. Computer Methods in Applied Mechanics and Engineering 446, 118308
2025
-
[45]
Introduction to optimization methods for training sciml models
Kopaničáková, A., Riccietti, E., 2026. Introduction to optimization methods for training sciml models. arXiv preprint arXiv:2601.10222
-
[46]
Characterizing possible failure modes in physics-informed neural networks, in: Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W
Krishnapriyan, A., Gholami, A., Zhe, S., Kirby, R., Mahoney, M.W., 2021. Characterizing possible failure modes in physics-informed neural networks, in: Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W. (Eds.), Advances in Neural Information Processing Systems, Curran Associates, Inc.. pp. 26548–26560. URL:https://proceedings.neurips.cc/p...
2021
-
[47]
Deep learning
LeCun, Y., Bengio, Y., Hinton, G., 2015. Deep learning. nature 521, 436–444
2015
-
[48]
Visualizing the loss landscape of neural nets
Li, H., Xu, Z., Taylor, G., Studer, C., Goldstein, T., 2018. Visualizing the loss landscape of neural nets. Advances in neural information processing systems 31
2018
-
[49]
Canweremovethesquare-rootinadaptivegradientmethods? a second-order perspective
Lin,W.,Dangel,F.,Eschenhagen,R.,Bae,J.,Turner,R.E.,Makhzani,A.,2024. Canweremovethesquare-rootinadaptivegradientmethods? a second-order perspective. International Conference on Machine Learning
2024
-
[50]
Lin,W.,Lowe,S.C.,Dangel,F.,Eschenhagen,R.,Xu,Z.,Grosse,R.B.,2025. Understandingandimprovingshampooandsoapviakullback- leibler minimization. arXiv preprint arXiv:2509.03378 . Jnini et al.:Preprint submitted to ElsevierPage 48 of 53 Curvature-Aware Optimization for High-Accuracy PINNs
-
[51]
Liu, J., Zheng, S., Song, X., Xu, D., 2024. Locally linearized physics informed neural networks for riemann problems of hyperbolic conservation laws. Physics of Fluids 36, 116135. doi:10.1063/5.0238865
-
[52]
Decoupled weight decay regularization, in: International Conference on Learning Representations
Loshchilov, I., Hutter, F., 2019. Decoupled weight decay regularization, in: International Conference on Learning Representations. URL: https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[53]
Viscous and resistive eddies near a sharp corner
Moffatt, H.K., 1964. Viscous and resistive eddies near a sharp corner. Journal of Fluid Mechanics 18, 1–18
1964
-
[54]
Achieving High Accuracy with PINNs via Energy Natural Gradient Descent, in: International Conference on Machine Learning, PMLR
Müller, J., Zeinhofer, M., 2023. Achieving High Accuracy with PINNs via Energy Natural Gradient Descent, in: International Conference on Machine Learning, PMLR. pp. 25471–25485
2023
-
[55]
Position:OptimizationinSciMLshouldemploythefunctionspacegeometry,in:Salakhutdinov,R.,Kolter,Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F
Müller,J.,Zeinhofer,M.,2024. Position:OptimizationinSciMLshouldemploythefunctionspacegeometry,in:Salakhutdinov,R.,Kolter,Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F. (Eds.), Proceedings of the 41st International Conference on Machine Learning, PMLR. pp. 36705–36722. URL:https://proceedings.mlr.press/v235/muller24d.html
2024
-
[56]
Numerical optimization
Nocedal, J., Wright, S.J., 2006. Numerical optimization. Springer
2006
-
[57]
Invariance properties of the natural gradient in overparametrised systems: J
van Oostrum, J., Müller, J., Ay, N., 2023. Invariance properties of the natural gradient in overparametrised systems: J. van oostrum et al. Information geometry 6, 51–67
2023
-
[58]
Oren,S.S.,Luenberger,D.G.,1974. Self-scalingvariablemetric(ssvm)algorithms,parti:Criteriaandsufficientconditionsforscalingaclass of algorithms. Management Science 20, 845–862. doi:10.1287/mnsc.20.5.845
-
[59]
Optimistix: modular optimisation in JAX and Equinox.arXiv:2402.09983, 2024
Rader, J., Lyons, T., Kidger, P., 2024. Optimistix: modular optimisation in jax and equinox. arXiv preprint arXiv:2402.09983
-
[60]
Raissi, M., Perdikaris, P., Karniadakis, G., 2019. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics 378, 686–707. URL:https://www. sciencedirect.com/science/article/pii/S0021999118307125, doi:https://doi.org/10.1016/j.jc...
-
[61]
Ranocha,H.,Schlottke-Lakemper,M.,Winters,A.R.,Faulhaber,E.,Chan,J.,Gassner,G.J.,2021. Adaptivenumericalsimulationswithtrixi. jl: A case study of julia for scientific computing. arXiv preprint arXiv:2108.06476
-
[62]
Approximate riemann solvers, parameter vectors, and difference schemes
Roe, P., 1981. Approximate riemann solvers, parameter vectors, and difference schemes. Journal of Computational Physics 43, 357–372. URL:https://www.sciencedirect.com/science/article/pii/0021999181901285,doi:https://doi.org/10.1016/ 0021-9991(81)90128-5
-
[63]
Anagram: A natural gradient relative to adapted model for efficient pinns learning
Schwencke, N., Furtlehner, C., 2025. Anagram: A natural gradient relative to adapted model for efficient pinns learning. URL:https: //arxiv.org/abs/2412.10782,arXiv:2412.10782
-
[64]
Amstramgram: Adaptive multi-cutoff strategy modification for anagram
Schwencke, N., Rousselot, C., Shilova, A., Furtlehner, C., 2025. Amstramgram: Adaptive multi-cutoff strategy modification for anagram. URL:https://arxiv.org/abs/2510.15998,arXiv:2510.15998
-
[65]
Conditioning of quasi-newton methods for function minimization
Shanno, D.F., 1970. Conditioning of quasi-newton methods for function minimization. Mathematics of Computation 24, 647–656. doi:10.1090/S0025-5718-1970-0274029-X
-
[66]
Condition numbers and equilibration of matrices
van der Sluis, A., 1969. Condition numbers and equilibration of matrices. Numerische Mathematik 14, 14–23. doi:10.1007/BF02165968
-
[67]
The numerical viscosity of entropy stable schemes for systems of conservation laws
Tadmor, E., 1987. The numerical viscosity of entropy stable schemes for systems of conservation laws. i. Mathematics of Computation 49, 91–103
1987
-
[68]
Divide the gradient by a running average of its recent magnitude
Tieleman, T., Hinton, G., 2017. Divide the gradient by a running average of its recent magnitude. coursera: Neural networks for machine learning, in: Technical report. University of Toronto
2017
-
[69]
Restoration of the contact surface in the hll-riemann solver
Toro, E.F., Spruce, M., Speares, W., 1994. Restoration of the contact surface in the hll-riemann solver. Shock waves 4, 25–34
1994
-
[70]
Frompinnstopikans:Recent advances in physics-informed machine learning
Toscano,J.D.,Oommen,V.,Varghese,A.J.,Zou,Z.,AhmadiDaryakenari,N.,Wu,C.,Karniadakis,G.E.,2025. Frompinnstopikans:Recent advances in physics-informed machine learning. Machine Learning for Computational Science and Engineering 1, 15
2025
-
[71]
Unveiling the optimization process of physics informed neural networks: How accurate and competitive can pinns be? Journal of Computational Physics 523, 113656
Urbán, J.F., Stefanou, P., Pons, J.A., 2025. Unveiling the optimization process of physics informed neural networks: How accurate and competitive can pinns be? Journal of Computational Physics 523, 113656
2025
-
[72]
Urbán,J.F.,Pons,J.A.,2025. Anapproximateriemannsolverapproachinphysics-informedneuralnetworksforhyperbolicconservationlaws. Physics of Fluids 37, 096114. doi:10.1063/5.0285282
-
[73]
SOAP: Improving and Stabilizing Shampoo using Adam
Vyas, N., Morwani, D., Zhao, R., Kwun, M., Shapira, I., Brandfonbrener, D., Janson, L., Kakade, S., 2024. SOAP: Improving and stabilizing Shampoo using Adam. arXiv preprint arXiv:2409.11321
work page internal anchor Pith review arXiv 2024
-
[74]
Understandingandmitigatinggradientflowpathologiesinphysics-informedneuralnetworks
Wang,S.,Teng,Y.,Perdikaris,P.,2021. Understandingandmitigatinggradientflowpathologiesinphysics-informedneuralnetworks. SIAM Journal on Scientific Computing 43, A3055–A3081
2021
-
[75]
Roofline: an insightful visual performance model for multicore architectures
Williams, S., Waterman, A., Patterson, D., 2009. Roofline: an insightful visual performance model for multicore architectures. Communica- tions of the ACM 52, 65–76
2009
-
[76]
Convergence conditions for ascent methods
Wolfe, P., 1969. Convergence conditions for ascent methods. SIAM review 11, 226–235
1969
-
[77]
Towards understanding convergence and generalization of adamw
Zhou, P., Xie, X., Lin, Z., Yan, S., 2024. Towards understanding convergence and generalization of adamw. IEEE transactions on pattern analysis and machine intelligence 46, 6486–6493. Jnini et al.:Preprint submitted to ElsevierPage 49 of 53 Curvature-Aware Optimization for High-Accuracy PINNs A. Details on Self-Scaled Quasi-Newton Methods Theparameters(𝜏 ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.