Group-Graph Policy Optimization for Long-Horizon Agentic Reinforcement Learning
Pith reviewed 2026-06-26 08:42 UTC · model grok-4.3
The pith
G2PO turns linear agent trajectories into a shared state-transition graph to cut variance in long-horizon value estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
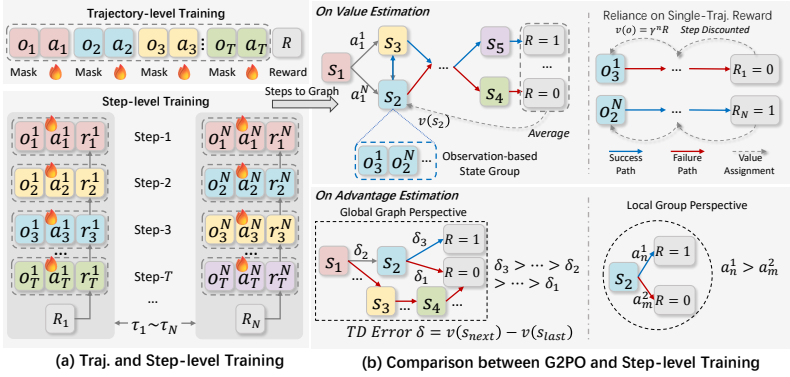
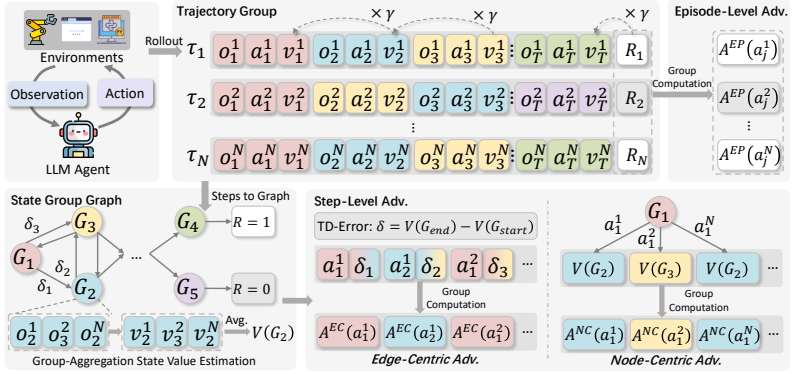
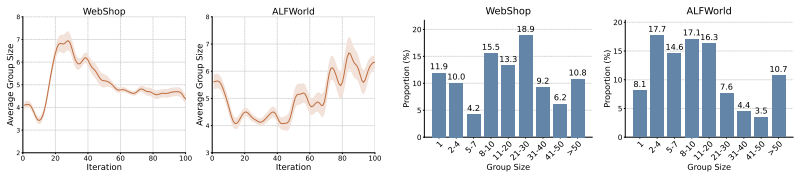
G2PO explicitly transforms linear interaction trajectories into a global state-transition graph. By aggregating identical observations across different trajectories, group-aggregation state-value estimation reduces sampling variance and trajectory-dependent bias. Furthermore, the method redefines actions as edges and applies an edge-centric advantage estimator that globally standardizes TD errors, thereby identifying and prioritizing the transitions that drive absolute task progress.
What carries the argument
Global state-transition graph whose nodes aggregate identical observations and whose edges carry standardized TD-error advantages.
If this is right
- State-value estimates become independent of any single trajectory once the same observation is seen elsewhere.
- Credit assignment can favor transitions that advance the global task even when they appear in low-reward local paths.
- Policy updates prioritize edges with high standardized advantage rather than locally high TD error.
- The same aggregation step simultaneously lowers variance and removes trajectory-specific bias.
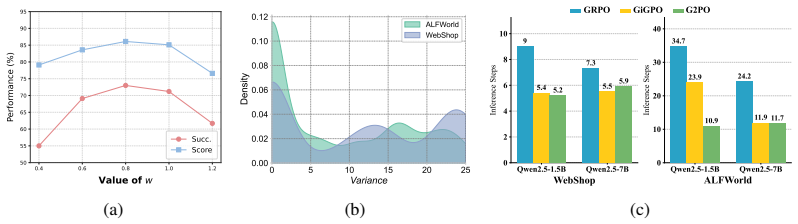
- Success-rate gains appear on WebShop, ALFWorld, and AppWorld when compared with GRPO.
Where Pith is reading between the lines
- The same graph-construction step could be applied to any episodic setting where states recur across episodes.
- If observation matching is noisy, the variance-reduction benefit may shrink faster than the bias cost grows.
- Edge-centric standardization might combine with existing graph neural network value functions for larger state spaces.
Load-bearing premise
Observations that look identical across separate trajectories can be merged without discarding history-dependent information or creating systematic bias.
What would settle it
Run the same agent on a benchmark where two trajectories reach an observation that is textually identical but requires different future actions; measure whether merging those states lowers final success rate relative to a non-aggregated baseline.
Figures




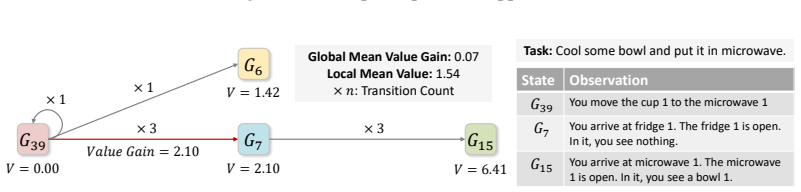
read the original abstract
Group-based Reinforcement Learning (RL) has significantly enhanced Large Language Models (LLMs) in agentic scenarios. To achieve finer-grained policy updates, recent agentic RL frameworks have shifted from trajectory-level to step-level training. However, long-horizon agentic RL suffers from severe reward sparsity and delay, as feedback is often deferred for dozens of interaction steps. While existing step-level frameworks refine training granularity, their credit assignment remains coarse-grained and still treats agent exploration as isolated, linear trajectories. This oversimplified perspective ignores the inherent graph structure of state transitions, leading to high-variance state-value estimation and myopic, localized credit assignment. To overcome these critical bottlenecks, we propose Group-Graph Policy Optimization (G2PO), a novel group-based RL algorithm tailored for multi-turn agentic tasks. G2PO explicitly transforms linear interaction trajectories into a global state-transition graph. By aggregating identical observations across different trajectories, we introduce group-aggregation state-value estimation that reduces sampling variance and trajectory-dependent bias. Furthermore, we redefine agent actions as transitions between state nodes and propose an edge-centric advantage estimation strategy. By globally standardizing Temporal Difference (TD) errors across the entire graph, G2PO explicitly identifies and prioritizes critical transitions that drive absolute task progress. Extensive experiments on representative long-horizon benchmarks-WebShop, ALFWorld, and AppWorld-demonstrate that G2PO substantially outperforms state-of-the-art prompt-based and RL baselines, achieving remarkable success rate improvements of up to 22.2% over GRPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Group-Graph Policy Optimization (G2PO) for long-horizon agentic RL with LLMs. It claims to convert linear trajectories into a global state-transition graph by aggregating identical observations across trajectories, introduce group-aggregation state-value estimation to reduce sampling variance and trajectory-dependent bias, and propose edge-centric advantage estimation that globally standardizes TD errors to identify critical transitions, yielding up to 22.2% success-rate gains over GRPO on WebShop, ALFWorld, and AppWorld.
Significance. If the state-equivalence assumption holds and the graph-based aggregation and standardization deliver the claimed variance reduction without introducing bias, the work would provide a concrete mechanism for finer-grained, global credit assignment in sparse-reward, multi-turn agentic settings, extending group-based RL beyond isolated trajectories. The multi-benchmark empirical gains would then constitute a practically relevant advance.
major comments (2)
- [Abstract] Abstract (and method description): the central variance-reduction and bias-reduction claims rest on aggregating 'identical observations' into shared state nodes, yet no equivalence relation, embedding, history augmentation, or test for state identity is supplied. In the POMDP benchmarks cited (ALFWorld, WebShop), the same textual observation can arise from distinct histories, so the aggregation step risks conflating non-Markovian states; this directly undermines the 'reduces sampling variance and trajectory-dependent bias' claim.
- [Abstract] Abstract: the edge-centric advantage is described as 'globally standardizing TD errors across the entire graph,' but no equation, pseudocode, or definition of the standardization operator (e.g., how per-edge TD errors are collected, normalized, or used in the policy gradient) is provided. Without this, the 'prioritizes critical transitions' mechanism cannot be verified or reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (and method description): the central variance-reduction and bias-reduction claims rest on aggregating 'identical observations' into shared state nodes, yet no equivalence relation, embedding, history augmentation, or test for state identity is supplied. In the POMDP benchmarks cited (ALFWorld, WebShop), the same textual observation can arise from distinct histories, so the aggregation step risks conflating non-Markovian states; this directly undermines the 'reduces sampling variance and trajectory-dependent bias' claim.
Authors: We agree this is a substantive gap. The manuscript relies on exact string matching of textual observations for state identity without an explicit equivalence relation or discussion of non-Markovian effects in POMDPs. We will revise the method section to formally define state equivalence via exact observation matching, add a limitations paragraph on potential bias in POMDP settings, and qualify the variance-reduction claim accordingly. revision: yes
-
Referee: [Abstract] Abstract: the edge-centric advantage is described as 'globally standardizing TD errors across the entire graph,' but no equation, pseudocode, or definition of the standardization operator (e.g., how per-edge TD errors are collected, normalized, or used in the policy gradient) is provided. Without this, the 'prioritizes critical transitions' mechanism cannot be verified or reproduced.
Authors: We concur that the description is insufficient for verification. Although the full manuscript outlines the approach in Section 3, it lacks the explicit standardization equation and pseudocode. We will add the z-score normalization formula for per-edge TD errors, the collection procedure across the graph, and its integration into the policy gradient, along with pseudocode, to ensure reproducibility. revision: yes
Circularity Check
No circularity: new graph construction and aggregation applied to standard TD errors
full rationale
The paper proposes G2PO as a novel algorithmic structure that converts trajectories to a state-transition graph, aggregates identical observations for group state-value estimation, and applies edge-centric advantage via global TD standardization. No equations, derivations, or self-citations are shown that reduce these mechanisms to fitted parameters renamed as predictions or to self-definitional identities. The central claims rest on the new graph structure and empirical results on WebShop/ALFWorld/AppWorld rather than any reduction to prior inputs by construction. The Markovian aggregation assumption is a modeling choice open to critique on POMDP grounds but does not constitute circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Observations can be treated as identical across trajectories for the purpose of state aggregation
Reference graph
Works this paper leans on
-
[1]
Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12248–12267, 2024
2024
-
[2]
Playing text-adventure games with graph-based deep reinforcement learning
Prithviraj Ammanabrolu and Mark Riedl. Playing text-adventure games with graph-based deep reinforcement learning. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 3557–3565, 2019
2019
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Lang Cao, Renhong Chen, Yingtian Zou, Chao Peng, Huacong Xu, Yuxian Wang, Wu Ning, Qian Chen, Mofan Peng, Zijie Chen, et al. More bang for the buck: Process reward modeling with entropy-driven uncertainty.arXiv preprint arXiv:2503.22233, 2025
-
[5]
Dreamprm: Domain-reweighted process reward model for multimodal reasoning
Qi Cao, Ruiyi Wang, Ruiyi Zhang, Sai Ashish Somayajula, and Pengtao Xie. Dreamprm: Domain-reweighted process reward model for multimodal reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[6]
Qwen3-Coder-Next Technical Report
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, et al. Qwen3-coder-next technical report.arXiv preprint arXiv:2603.00729, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Reinforcement learning for long-horizon interactive llm agents.arXiv preprint arXiv:2502.01600, 2025
Kevin Chen, Marco Cusumano-Towner, Brody Huval, Aleksei Petrenko, Jackson Hamburger, Vladlen Koltun, and Philipp Krähenbühl. Reinforcement learning for long-horizon interactive llm agents.arXiv preprint arXiv:2502.01600, 2025
-
[8]
Context-lite multi-turn reinforcement learning for llm agents
Wentse Chen, Jiayu Chen, Hao Zhu, and Jeff Schneider. Context-lite multi-turn reinforcement learning for llm agents. InES-FoMo III: 3rd Workshop on Efficient Systems for Foundation Models, 2025
2025
-
[9]
Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[10]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
2023
-
[12]
Towards efficient online tuning of vlm agents via counterfactual soft reinforcement learning
Lang Feng, Weihao Tan, Zhiyi Lyu, Longtao Zheng, Haiyang Xu, Ming Yan, Fei Huang, and Bo An. Towards efficient online tuning of vlm agents via counterfactual soft reinforcement learning. InInternational Conference on Machine Learning, pages 16884–16903. PMLR, 2025
2025
-
[13]
Group-in-group policy optimization for llm agent training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[14]
From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review
Mohamed Amine Ferrag, Norbert Tihanyi, and Merouane Debbah. From llm reasoning to autonomous ai agents: A comprehensive review.arXiv preprint arXiv:2504.19678, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Soft Adaptive Policy Optimization
Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. Soft adaptive policy optimization.arXiv preprint arXiv:2511.20347, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
A new era of intelligence with gemini 3, 2025
Google. A new era of intelligence with gemini 3, 2025
2025
-
[17]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[18]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023
2023
-
[19]
Agentgen: Enhancing planning abilities for large language model based agent via environment and task generation
Mengkang Hu, Pu Zhao, Can Xu, Qingfeng Sun, Jian-Guang Lou, Qingwei Lin, Ping Luo, and Saravan Rajmohan. Agentgen: Enhancing planning abilities for large language model based agent via environment and task generation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 496–507, 2025
2025
-
[20]
Understanding the planning of LLM agents: A survey
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. Understanding the planning of llm agents: A survey.arXiv preprint arXiv:2402.02716, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Search-r1: Training llms to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling
-
[22]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[23]
Process reward model with q-value rankings
Wendi Li and Yixuan Li. Process reward model with q-value rankings. InThe Thirteenth International Conference on Learning Representations
-
[24]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Llm collaboration with multi-agent reinforcement learning.arXiv preprint arXiv:2508.04652, 2025
Shuo Liu, Tianle Chen, Zeyu Liang, Xueguang Lyu, and Christopher Amato. Llm collaboration with multi-agent reinforcement learning.arXiv preprint arXiv:2508.04652, 2025
-
[26]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, et al. Large language model agent: A survey on methodology, applications and challenges.arXiv preprint arXiv:2503.21460, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Xufang Luo, Yuge Zhang, Zhiyuan He, Zilong Wang, Siyun Zhao, Dongsheng Li, Luna K Qiu, and Yuqing Yang. Agent lightning: Train any ai agents with reinforcement learning.arXiv preprint arXiv:2508.03680, 2025
-
[28]
Simpo: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
2024
-
[29]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[30]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
2015
-
[31]
Language understanding for text- based games using deep reinforcement learning
Karthik Narasimhan, Tejas Kulkarni, and Regina Barzilay. Language understanding for text- based games using deep reinforcement learning. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1–11, 2015
2015
-
[32]
Introducing gpt-5.2, 2025
OpenAI. Introducing gpt-5.2, 2025. 11
2025
-
[33]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[34]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[35]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[36]
ZZ Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, et al. Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition.arXiv preprint arXiv:2504.21801, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
2023
-
[38]
Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
2025
-
[39]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[42]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mot- taghi, Luke Zettlemoyer, and Dieter Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10740–10749, 2020
2020
-
[43]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[44]
Reinforcement learning: An introduction second edition
Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction second edition. Adaptive computation and machine learning: The MIT Press, Cambridge, MA and London, 2018
2018
-
[45]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024
2024
-
[46]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
2024
-
[47]
Weixun Wang, Shaopan Xiong, Gengru Chen, Wei Gao, Sheng Guo, Yancheng He, Ju Huang, Jiaheng Liu, Zhendong Li, Xiaoyang Li, et al. Reinforcement learning optimization for large- scale learning: An efficient and user-friendly scaling library.arXiv preprint arXiv:2506.06122, 2025. 12
-
[48]
Executable code actions elicit better llm agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents. InForty-first International Conference on Machine Learning, 2024
2024
-
[49]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, et al. Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning.arXiv preprint arXiv:2504.20073, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Ziliang Wang, Xuhui Zheng, Kang An, Cijun Ouyang, Jialu Cai, Yuhang Wang, and Yichao Wu. Stepsearch: Igniting llms search ability via step-wise proximal policy optimization.arXiv preprint arXiv:2505.15107, 2025
-
[51]
A brain-inspired agentic architec- ture to improve planning with llms.Nature Communications, 16(1):8633, 2025
Taylor Webb, Shanka Subhra Mondal, and Ida Momennejad. A brain-inspired agentic architec- ture to improve planning with llms.Nature Communications, 16(1):8633, 2025
2025
-
[52]
Agentic reasoning: Reasoning llms with tools for the deep research
Junde Wu, Jiayuan Zhu, and Yuyuan Liu. Agentic reasoning: Reasoning llms with tools for the deep research
-
[53]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
2024
-
[54]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
2022
-
[56]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[57]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, et al. Memagent: Reshaping long-context llm with multi-conv rl-based memory agent.arXiv preprint arXiv:2507.02259, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Douzero: Mastering doudizhu with self-play deep reinforcement learning
Daochen Zha, Jingru Xie, Wenye Ma, Sheng Zhang, Xiangru Lian, Xia Hu, and Ji Liu. Douzero: Mastering doudizhu with self-play deep reinforcement learning. Ininternational conference on machine learning, pages 12333–12344. PMLR, 2021
2021
-
[60]
Hanchen Zhang, Xiao Liu, Bowen Lv, Xueqiao Sun, Bohao Jing, Iat Long Iong, Zhenyu Hou, Zehan Qi, Hanyu Lai, Yifan Xu, et al. Agentrl: Scaling agentic reinforcement learning with a multi-turn, multi-task framework.arXiv preprint arXiv:2510.04206, 2025
-
[61]
Language agent tree search unifies reasoning, acting, and planning in language models
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning, acting, and planning in language models. In Proceedings of the 41st International Conference on Machine Learning, pages 62138–62160, 2024
2024
-
[62]
Webarena: A realistic web environment for build- ing autonomous agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for build- ing autonomous agents. InThe Twelfth International Conference on Learning Representations
-
[63]
Wpo: Enhancing rlhf with weighted pref- erence optimization
Wenxuan Zhou, Ravi Agrawal, Shujian Zhang, Sathish Reddy Indurthi, Sanqiang Zhao, Kaiqiang Song, Silei Xu, and Chenguang Zhu. Wpo: Enhancing rlhf with weighted pref- erence optimization. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8328–8340, 2024. 13 A Limitations One limitation of our paper is that we o...
2024
-
[64]
into interactive, text-based environments using TextWorld. The benchmark features six categories of household tasks that require agents to perceive environment states, plan long-horizon trajectories, and generalize their knowledge across diverse indoor scenes. AppWorld. AppWorld serves as a rigorous testing ground for LLM-based agents, providing a control...
2048
-
[65]
spotify_password) in the example above were only for demonstration
The email addresses, access tokens and variables (e.g. spotify_password) in the example above were only for demonstration. Obtain the correct information by calling relevant APIs yourself
-
[66]
Any thoughts should be put as code comments
Only generate valid code blocks, i.e., do not put them in “‘...“‘ or add any extra formatting. Any thoughts should be put as code comments
-
[67]
You can use the variables from the previous code blocks in the subsequent code blocks
-
[68]
If the task requires an answer, provide it using the answer argument — for example, ‘apis.supervisor.complete_task(answer=<answer>)‘
Once you believe the task is complete, you MUST call ‘apis.supervisor.complete_task()‘ to finalize it. If the task requires an answer, provide it using the answer argument — for example, ‘apis.supervisor.complete_task(answer=<answer>)‘. For tasks that do not require an answer, either omit the argument. The task will not end automatically — it will remain ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.