UniEdit-Flow: Unleashing Inversion and Editing in the Era of Flow Models
Pith reviewed 2026-05-22 18:49 UTC · model grok-4.3
The pith
Flow models support tuning-free inversion and region-aware editing through a predictor-corrector approach.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that a predictor-corrector-based framework for inversion and editing works effectively in flow models. Uni-Inv achieves accurate reconstruction by using prediction and correction steps along the model's trajectories. Uni-Edit applies the idea of delayed injection in a region-aware fashion to enable robust editing. The overall methodology is presented as tuning-free, model-agnostic, efficient, and capable of diverse edits with strong preservation of edit-irrelevant regions.
What carries the argument
The predictor-corrector inversion method that leverages straight-line non-crossing trajectories for accurate reconstruction and supports delayed-injection for editing.
If this is right
- Accurate reconstruction becomes possible for images generated by flow models.
- Diverse edits can be made while ensuring strong preservation of regions not involved in the edit.
- The methods function without any tuning or model-specific adjustments.
- Effective performance is maintained even in low-cost computational settings.
- Generalizability is shown across various generative flow models.
Where Pith is reading between the lines
- The geometry of trajectories in generative models may be central to the design of future inversion and editing techniques.
- This could lead to simpler editing pipelines for flow-based systems in practical applications.
- Extensions to other modalities like video generation might follow similar principles.
Load-bearing premise
The straight-line, non-crossing trajectories of flow models allow predictor-corrector inversion and delayed-injection editing to work accurately and robustly without post-hoc tuning or model-specific adjustments.
What would settle it
Applying the Uni-Inv method to reconstruct an image and finding that the output differs substantially from the input in pixel accuracy or perceptual quality would challenge the claim of accurate reconstruction.
Figures








read the original abstract
Flow matching models have emerged as a strong alternative to diffusion models, but existing inversion and editing methods designed for diffusion are often ineffective or inapplicable to them. The straight-line, non-crossing trajectories of flow models pose challenges for diffusion-based approaches but also open avenues for novel solutions. In this paper, we introduce a predictor-corrector-based framework for inversion and editing in flow models. First, we propose Uni-Inv, an effective inversion method designed for accurate reconstruction. Building on this, we extend the concept of delayed injection to flow models and introduce Uni-Edit, a region-aware, robust image editing approach. Our methodology is tuning-free, model-agnostic, efficient, and effective, enabling diverse edits while ensuring strong preservation of edit-irrelevant regions. Extensive experiments across various generative models demonstrate the superiority and generalizability of Uni-Inv and Uni-Edit, even under low-cost settings. Project page: https://uniedit-flow.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Uni-Inv, a predictor-corrector inversion method tailored to the straight-line trajectories of flow matching models for accurate reconstruction, and Uni-Edit, which adapts delayed injection for region-aware editing that preserves edit-irrelevant areas. It claims these techniques are tuning-free, model-agnostic, efficient, and effective, with extensive experiments across generative models demonstrating superiority even under low-cost settings.
Significance. If the central claims hold, the work would offer a practical, general-purpose framework for inversion and editing in flow-based generative models, which are emerging as strong alternatives to diffusion models. This could enable more reliable image manipulation applications without per-model calibration or high computational overhead, addressing a gap in current editing pipelines.
major comments (1)
- [§4, §3.2] §4 (Experiments) and §3.2 (Uni-Inv): The tuning-free and model-agnostic claims rest on using a single fixed set of hyperparameters (corrector iteration count, step schedule, and injection delay fraction) across multiple flow models. The reported quantitative results (e.g., reconstruction PSNR/SSIM and editing metrics) do not include an ablation or sensitivity analysis demonstrating that performance remains stable when these values are perturbed on architectures with differing velocity-field accuracies or training distributions; without this, the generalizability assertion is not fully load-bearing.
minor comments (2)
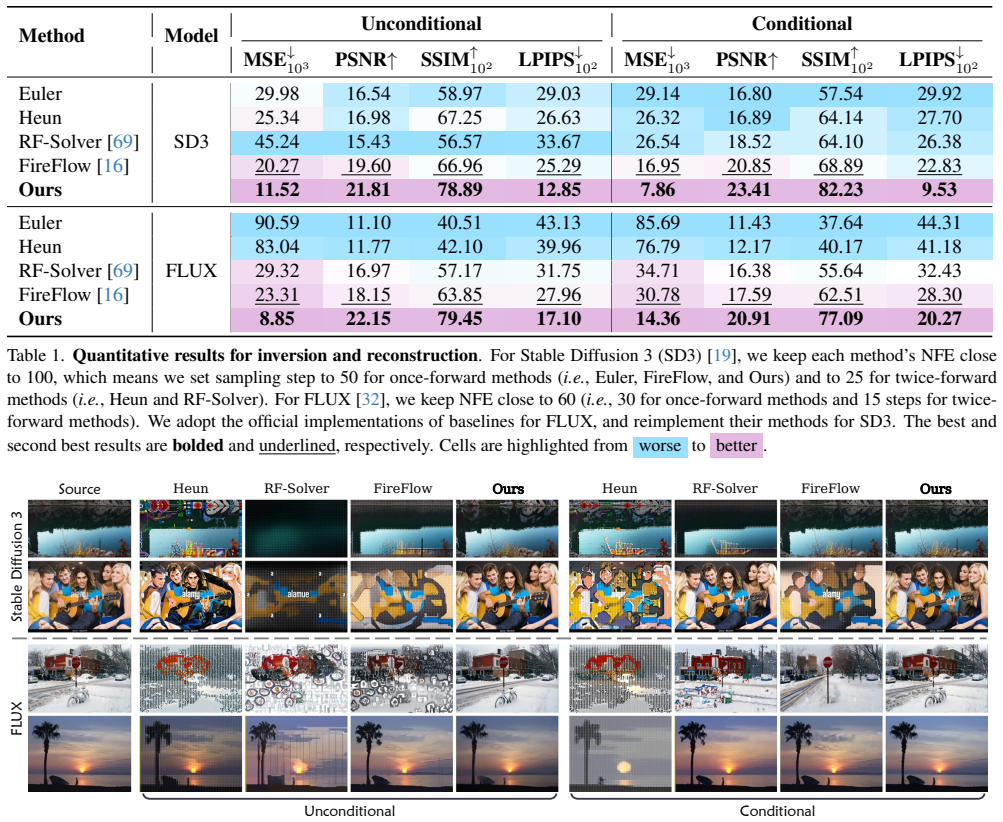
- [Figures 3-4] Figure 3 and 4: The qualitative editing examples would benefit from explicit annotation of the source and target regions to make the preservation of edit-irrelevant areas more immediately verifiable.
- [§2] Related work section: The discussion of prior diffusion-based inversion methods (e.g., DDIM inversion) could more explicitly contrast the non-crossing property of flow trajectories with the stochasticity in diffusion paths.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The suggestion to bolster evidence for the tuning-free and model-agnostic properties is well-taken, and we address it directly below.
read point-by-point responses
-
Referee: [§4, §3.2] §4 (Experiments) and §3.2 (Uni-Inv): The tuning-free and model-agnostic claims rest on using a single fixed set of hyperparameters (corrector iteration count, step schedule, and injection delay fraction) across multiple flow models. The reported quantitative results (e.g., reconstruction PSNR/SSIM and editing metrics) do not include an ablation or sensitivity analysis demonstrating that performance remains stable when these values are perturbed on architectures with differing velocity-field accuracies or training distributions; without this, the generalizability assertion is not fully load-bearing.
Authors: We appreciate this observation. Our experiments already show that the same fixed hyperparameter set produces competitive reconstruction and editing results across several flow-based models without per-model tuning. Nevertheless, we agree that an explicit sensitivity analysis would make the generalizability claim more robust. In the revised version we will add an ablation that perturbs the corrector iteration count, step schedule, and injection delay fraction on models with different velocity-field characteristics and report the resulting changes in PSNR, SSIM, and editing metrics. This addition will directly address the concern while preserving the tuning-free nature of the proposed methods. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives Uni-Inv and Uni-Edit from the geometric properties of flow-matching trajectories (straight-line, non-crossing paths) by adapting predictor-corrector inversion and delayed-injection editing. These steps are presented as direct consequences of the flow ODE structure rather than quantities fitted to target editing outputs or defined circularly in terms of each other. No load-bearing self-citation chain, ansatz smuggling, or renaming of known results is required for the central claims; the tuning-free and model-agnostic assertions rest on the stated trajectory properties and are tested externally across models. The derivation remains self-contained against the independent mathematical features of flow models.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow matching models possess straight-line, non-crossing trajectories that differ from diffusion paths.
Forward citations
Cited by 4 Pith papers
-
FlowAnchor: Stabilizing the Editing Signal for Inversion-Free Video Editing
FlowAnchor stabilizes editing signals in flow-based inversion-free video editing via spatial-aware attention refinement and adaptive magnitude modulation for improved faithfulness and temporal coherence.
-
Beyond Prompts: Unconditional 3D Inversion for Out-of-Distribution Shapes
Text-to-3D models lose prompt sensitivity for out-of-distribution shapes due to sink traps but retain geometric diversity via unconditional priors, enabling a decoupled inversion method for robust editing.
-
Dress-ED: Instruction-Guided Editing for Virtual Try-On and Try-Off
Dress-ED is the first large-scale benchmark unifying virtual try-on, try-off, and text-guided garment editing with 146k verified samples plus a multimodal diffusion baseline.
-
StreamGVE: Training-Free Video Editing via Few-Step Streaming Video Generation
StreamGVE enables high-quality training-free video editing by converting the task to noise-to-data streaming generation with dual-branch fast sampling, self-attention bridges, cross-attention grounding, source-oriente...
Reference graph
Works this paper leans on
-
[1]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S Albergo, Nicholas M Boffi, and Eric Vanden- Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions. arXiv preprint arXiv:2303.08797,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Blended diffusion for text-driven editing of natural images
Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18208–18218, 2022. 1, 2
work page 2022
-
[3]
Omri Avrahami, Ohad Fried, and Dani Lischinski. Blended latent diffusion. ACM transactions on graphics (TOG) , 42 (4):1–11, 2023. 1
work page 2023
-
[4]
Stable flow: Vital layers for training-free image editing
Omri Avrahami, Or Patashnik, Ohad Fried, Egor Nemchi- nov, Kfir Aberman, Dani Lischinski, and Daniel Cohen- Or. Stable flow: Vital layers for training-free image editing. arXiv preprint arXiv:2411.14430, 2024. 2
-
[5]
Zigzag diffusion sampling: Diffusion models can self-improve via self-reflection
Lichen Bai, Shitong Shao, Zikai Zhou, Zipeng Qi, Zhiqiang Xu, Haoyi Xiong, and Zeke Xie. Zigzag diffusion sampling: Diffusion models can self-improve via self-reflection. InThe Thirteenth International Conference on Learning Represen- tations, 2024. 2
work page 2024
-
[6]
Multidiffusion: Fusing diffusion paths for controlled image generation
Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. Multidiffusion: Fusing diffusion paths for controlled image generation. 2023. 1
work page 2023
-
[7]
Sega: Instructing text-to-image models using semantic guidance
Manuel Brack, Felix Friedrich, Dominik Hintersdorf, Lukas Struppek, Patrick Schramowski, and Kristian Kersting. Sega: Instructing text-to-image models using semantic guidance. Advances in Neural Information Processing Systems , 36: 25365–25389, 2023. 2
work page 2023
-
[8]
Ledits++: Limitless image editing using text-to-image models
Manuel Brack, Felix Friedrich, Katharia Kornmeier, Linoy Tsaban, Patrick Schramowski, Kristian Kersting, and Apolin´ario Passos. Ledits++: Limitless image editing using text-to-image models. In Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition , pages 8861–8870, 2024. 3
work page 2024
-
[9]
Classifier- free guidance is a predictor-corrector
Arwen Bradley and Preetum Nakkiran. Classifier- free guidance is a predictor-corrector. arXiv preprint arXiv:2408.09000, 2024. 2
-
[10]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18392–18402, 2023. 6, 4
work page 2023
-
[11]
Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xi- aohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing. In Proceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV) , pages 22560–22570,
-
[12]
Fs- coco: Towards understanding of freehand sketches of com- mon objects in context
Pinaki Nath Chowdhury, Aneeshan Sain, Ayan Kumar Bhu- nia, Tao Xiang, Yulia Gryaditskaya, and Yi-Zhe Song. Fs- coco: Towards understanding of freehand sketches of com- mon objects in context. InEuropean conference on computer vision, pages 253–270. Springer, 2022. 8
work page 2022
-
[13]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sam- pling for general noisy inverse problems. arXiv preprint arXiv:2209.14687, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Diffedit: Diffusion-based semantic image editing with mask guidance,
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based seman- tic image editing with mask guidance. arXiv preprint arXiv:2210.11427, 2022. 2, 3, 5, 6, 8
-
[15]
Fluxs- pace: Disentangled semantic editing in rectified flow trans- formers
Yusuf Dalva, Kavana Venkatesh, and Pinar Yanardag. Fluxs- pace: Disentangled semantic editing in rectified flow trans- formers. arXiv preprint arXiv:2412.09611, 2024. 2
-
[16]
Fireflow: Fast inversion of rectified flow for image semantic editing, 2024
Yingying Deng, Xiangyu He, Changwang Mei, Peisong Wang, and Fan Tang. Fireflow: Fast inversion of rectified flow for image semantic editing, 2024. 2, 6, 7, 4
work page 2024
-
[17]
Ccd-3dr: Consistent conditioning in diffusion for single-image 3d reconstruction
Yan Di, Chenyangguang Zhang, Pengyuan Wang, Guangyao Zhai, Ruida Zhang, Fabian Manhardt, Benjamin Busam, Xi- angyang Ji, and Federico Tombari. Ccd-3dr: Consistent conditioning in diffusion for single-image 3d reconstruction. arXiv preprint arXiv:2308.07837, 2023. 1
-
[18]
Prompt tuning inversion for text-driven image editing using diffusion models
Wenkai Dong, Song Xue, Xiaoyue Duan, and Shumin Han. Prompt tuning inversion for text-driven image editing using diffusion models. In Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 7430–7440,
-
[19]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning,
-
[20]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patash- nik, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. An image is worth one word: Personalizing text-to- image generation using textual inversion. arXiv preprint arXiv:2208.01618, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Renoise: Real image inversion through iterative noising, 2024
Daniel Garibi, Or Patashnik, Andrey V oynov, Hadar Averbuch-Elor, and Daniel Cohen-Or. Renoise: Real image inversion through iterative noising, 2024. 2, 4, 6, 3
work page 2024
-
[22]
Generative adversarial networks
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. Commu- nications of the ACM, 63(11):139–144, 2020. 2
work page 2020
-
[23]
Improving tuning-free real image editing with proximal guidance
Ligong Han, Song Wen, Qi Chen, Zhixing Zhang, Kunpeng Song, Mengwei Ren, Ruijiang Gao, Anastasis Stathopoulos, Xiaoxiao He, Yuxiao Chen, et al. Improving tuning-free real image editing with proximal guidance. arXiv preprint arXiv:2306.05414, 2023. 2
-
[24]
Proxedit: Improving tuning-free real image editing with proximal guidance
Ligong Han, Song Wen, Qi Chen, Zhixing Zhang, Kunpeng Song, Mengwei Ren, Ruijiang Gao, Anastasis Stathopou- los, Xiaoxiao He, Yuxiao Chen, et al. Proxedit: Improving tuning-free real image editing with proximal guidance. In Proceedings of the IEEE/CVF Winter Conference on Appli- cations of Computer Vision , pages 4291–4301, 2024. 5, 6, 8
work page 2024
-
[25]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022. 6, 7, 4 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020. 1, 2
work page 2020
-
[27]
An edit friendly ddpm noise space: Inversion and manipulations
Inbar Huberman-Spiegelglas, Vladimir Kulikov, and Tomer Michaeli. An edit friendly ddpm noise space: Inversion and manipulations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12469– 12478, 2024. 3, 6, 7, 4
work page 2024
-
[28]
Hq-edit: A high-quality dataset for instruction-based image editing
Mude Hui, Siwei Yang, Bingchen Zhao, Yichun Shi, Heng Wang, Peng Wang, Yuyin Zhou, and Cihang Xie. Hq-edit: A high-quality dataset for instruction-based image editing. arXiv preprint arXiv:2404.09990, 2024. 7, 8, 11
-
[29]
Scope of va- lidity of psnr in image/video quality assessment
Quan Huynh-Thu and Mohammed Ghanbari. Scope of va- lidity of psnr in image/video quality assessment. Electronics letters, 44(13):800–801, 2008. 6
work page 2008
-
[30]
Pnp inversion: Boosting diffusion-based editing with 3 lines of code
Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Pnp inversion: Boosting diffusion-based editing with 3 lines of code. International Conference on Learning Representations (ICLR), 2024. 2, 3, 6, 7, 4, 8, 9
work page 2024
-
[31]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4401–4410, 2019. 3
work page 2019
-
[32]
Black Forest Labs. Flux. https://github.com/ black-forest-labs/flux, 2023. 6, 7
work page 2023
-
[33]
Black Forest Labs. Flux. https://github.com/ black-forest-labs/flux, 2024. 2
work page 2024
-
[34]
Open-vocabulary object segmenta- tion with diffusion models
Ziyi Li, Qinye Zhou, Xiaoyun Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Open-vocabulary object segmenta- tion with diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7667– 7676, 2023. 1
work page 2023
-
[35]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling. arXiv preprint arXiv:2210.02747, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003, 2022. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Instaflow: One step is enough for high-quality diffusion- based text-to-image generation
Xingchao Liu, Xiwen Zhang, Jianzhu Ma, Jian Peng, et al. Instaflow: One step is enough for high-quality diffusion- based text-to-image generation. In The Twelfth International Conference on Learning Representations, 2023. 3
work page 2023
-
[38]
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongx- uan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. arXiv preprint arXiv:2211.01095, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Pnp-flow: Plug-and-play image restoration with flow matching
S ´egol`ene Martin, Anne Gagneux, Paul Hagemann, and Gabriele Steidl. Pnp-flow: Plug-and-play image restoration with flow matching. arXiv preprint arXiv:2410.02423, 2024. 3
-
[40]
Null-text inversion for editing real im- ages using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real im- ages using guided diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6038–6047, 2023. 2, 6, 3, 4
work page 2023
-
[41]
Zero-shot image-to-image translation
Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, and Jun-Yan Zhu. Zero-shot image-to-image translation. In ACM SIGGRAPH 2023 Conference Proceed- ings, SIGGRAPH 2023, Los Angeles, CA, USA, August 6-10, 2023, pages 11:1–11:11. ACM, 2023. 3, 4
work page 2023
-
[42]
Maitreya Patel, Song Wen, Dimitris N. Metaxas, and Yezhou Yang. Steering rectified flow models in the vec- tor field for controlled image generation. arXiv preprint arXiv:2412.00100, 2024. 3
-
[43]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF inter- national conference on computer vision , pages 4195–4205,
-
[44]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis. arXiv preprint arXiv:2307.01952, 2023. 7, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bel´aez, Alexander Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation. arXiv:1704.00675, 2017. 9, 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[47]
Siminver- sion: A simple framework for inversion-based text-to-image editing
Qi Qian, Haiyang Xu, Ming Yan, and Juhua Hu. Siminver- sion: A simple framework for inversion-based text-to-image editing. arXiv preprint arXiv:2409.10476, 2024. 2
-
[48]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. In International conference on machine learning, pages 8748–8763. PMLR, 2021. 7
work page 2021
-
[49]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents. arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[50]
DreamGaussian4D: Generative 4D gaussian splatting.arXiv preprint arXiv:2312.17142,
Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, and Ziwei Liu. Dreamgaussian4d: Genera- tive 4d gaussian splatting. arXiv preprint arXiv:2312.17142,
-
[51]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1
work page 2022
-
[52]
Semantic im- age inversion and editing using rectified stochastic differen- tial equations
Litu Rout, Yujia Chen, Nataniel Ruiz, Constantine Carama- nis, Sanjay Shakkottai, and Wen-Sheng Chu. Semantic im- age inversion and editing using rectified stochastic differen- tial equations. arXiv preprint arXiv:2410.10792, 2024. 2, 7, 4
-
[53]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. 2022. 1
work page 2022
-
[54]
Mohammad Shahab Sepehri, Zalan Fabian, Maryam Soltanolkotabi, and Mahdi Soltanolkotabi. Mediconfusion: Can you trust your ai radiologist? probing the reliability 11 of multimodal medical foundation models. arXiv preprint arXiv:2409.15477, 2024. 1
-
[55]
Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning. In Pro- ceedings of ACL, 2018. 6, 5
work page 2018
-
[56]
Seededit: Align image re-generation to image editing
Yichun Shi, Peng Wang, and Weilin Huang. Seededit: Align image re-generation to image editing. arXiv preprint arXiv:2411.06686, 2024. 6, 4
-
[57]
Stochastic sampling from deterministic flow models.arXiv preprint arXiv:2410.02217,
Saurabh Singh and Ian Fischer. Stochastic sampling from deterministic flow models.arXiv preprint arXiv:2410.02217,
-
[58]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[59]
Leveraging previous steps: A training-free fast solver for flow diffusion
Kaiyu Song and Hanjiang Lai. Leveraging previous steps: A training-free fast solver for flow diffusion. arXiv preprint arXiv:2411.07627, 2024. 2
-
[60]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions. arXiv preprint arXiv:2011.13456, 2020. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[61]
Rectifid: Personalizing rectified flow with an- chored classifier guidance
Zhicheng Sun, Zhenhao Yang, Yang Jin, Haozhe Chi, Kun Xu, Liwei Chen, Hao Jiang, Yang Song, Kun Gai, and Yadong Mu. Rectifid: Personalizing rectified flow with an- chored classifier guidance. Advances in Neural Information Processing Systems, 37:96993–97026, 2024. 3
work page 2024
-
[62]
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for effi- cient 3d content creation. arXiv preprint arXiv:2309.16653,
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Ledits: Real image editing with ddpm inversion and semantic guidance
Linoy Tsaban and Apolin ´ario Passos. Ledits: Real image editing with ddpm inversion and semantic guidance. arXiv preprint arXiv:2307.00522, 2023. 3
-
[64]
Splicing vit features for semantic appearance transfer
Narek Tumanyan, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Splicing vit features for semantic appearance transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10748–10757, 2022. 7
work page 2022
-
[65]
Plug-and-play diffusion features for text-driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Van- couver, BC, Canada, June 17-24, 2023 , pages 1921–1930. IEEE, 2023. 2, 6, 7, 4
work page 2023
-
[66]
Edict: Exact diffusion inversion via coupled transformations
Bram Wallace, Akash Gokul, and Nikhil Naik. Edict: Exact diffusion inversion via coupled transformations. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22532–22541, 2023. 2
work page 2023
-
[67]
Belm: Bidirec- tional explicit linear multi-step sampler for exact inversion in diffusion models
Fangyikang Wang, Hubery Yin, Yue-Jiang Dong, Huminhao Zhu, Hanbin Zhao, Hui Qian, Chen Li, et al. Belm: Bidirec- tional explicit linear multi-step sampler for exact inversion in diffusion models. Advances in Neural Information Process- ing Systems, 37:46118–46159, 2025. 2
work page 2025
-
[68]
Fu-Yun Wang, Ling Yang, Zhaoyang Huang, Mengdi Wang, and Hongsheng Li. Rectified diffusion: Straightness is not your need in rectified flow.arXiv preprint arXiv:2410.07303,
-
[69]
Tam- ing rectified flow for inversion and editing
Jiangshan Wang, Junfu Pu, Zhongang Qi, Jiayi Guo, Yue Ma, Nisha Huang, Yuxin Chen, Xiu Li, and Ying Shan. Tam- ing rectified flow for inversion and editing. arXiv preprint arXiv:2411.04746, 2024. 2, 6, 7, 4
-
[70]
Moa: Mixture-of-attention for subject-context disentanglement in personalized image gen- eration
Kuan-Chieh Wang, Daniil Ostashev, Yuwei Fang, Sergey Tulyakov, and Kfir Aberman. Moa: Mixture-of-attention for subject-context disentanglement in personalized image gen- eration. In SIGGRAPH Asia 2024 Conference Papers, pages 1–12, 2024. 1
work page 2024
-
[71]
Mdp: A generalized framework for text-guided image edit- ing by manipulating the diffusion path
Qian Wang, Biao Zhang, Michael Birsak, and Peter Wonka. Mdp: A generalized framework for text-guided image edit- ing by manipulating the diffusion path. arXiv preprint arXiv:2303.16765, 2023. 3
-
[72]
Image quality assessment: from error visibility to structural similarity
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004. 6
work page 2004
-
[73]
Wan: Open and Advanced Large-Scale Video Generative Models
WanTeam, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jin- gren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Omniedit: Building image edit- ing generalist models through specialist supervision
Cong Wei, Zheyang Xiong, Weiming Ren, Xinrun Du, Ge Zhang, and Wenhu Chen. Omniedit: Building image edit- ing generalist models through specialist supervision. arXiv preprint arXiv:2411.07199, 2024. 6, 4
-
[75]
A latent space of stochastic diffusion models for zero-shot image editing and guidance
Chen Henry Wu and Fernando De la Torre. A latent space of stochastic diffusion models for zero-shot image editing and guidance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7378–7387, 2023. 3
work page 2023
-
[76]
Uncovering the disentanglement capability in text- to-image diffusion models
Qiucheng Wu, Yujian Liu, Handong Zhao, Ajinkya Kale, Trung Bui, Tong Yu, Zhe Lin, Yang Zhang, and Shiyu Chang. Uncovering the disentanglement capability in text- to-image diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 1900–1910, 2023. 3
work page 1900
-
[77]
Turboedit: Instant text-based image editing
Zongze Wu, Nicholas Kolkin, Jonathan Brandt, Richard Zhang, and Eli Shechtman. Turboedit: Instant text-based image editing. In European Conference on Computer Vision, pages 365–381. Springer, 2024. 6, 4
work page 2024
-
[78]
Fastcomposer: Tuning-free multi- subject image generation with localized attention
Guangxuan Xiao, Tianwei Yin, William T Freeman, Fr ´edo Durand, and Song Han. Fastcomposer: Tuning-free multi- subject image generation with localized attention. Interna- tional Journal of Computer Vision, pages 1–20, 2024. 3
work page 2024
-
[79]
Inversion-free image editing with natural language
Sihan Xu, Yidong Huang, Jiayi Pan, Ziqiao Ma, and Joyce Chai. Inversion-free image editing with natural language
-
[80]
Yu Xu, Fan Tang, Juan Cao, Yuxin Zhang, Xiaoyu Kong, Jintao Li, Oliver Deussen, and Tong-Yee Lee. Head- router: A training-free image editing framework for mm- dits by adaptively routing attention heads. arXiv preprint arXiv:2411.15034, 2024. 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.