Path-level Hindsight Instructions for Semantic Exploration in Vision-Language Navigation
Pith reviewed 2026-07-03 14:02 UTC · model grok-4.3
The pith
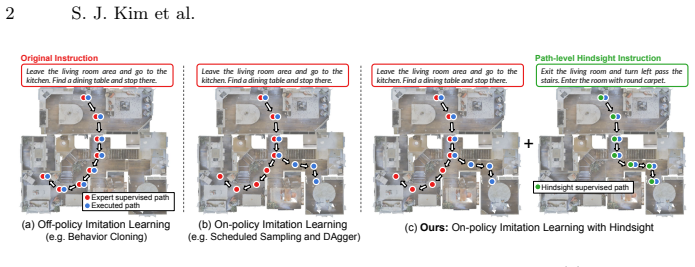
Phi-Nav turns on-policy exploration trajectories into additional expert demonstrations by synthesizing path-level hindsight instructions from visual observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
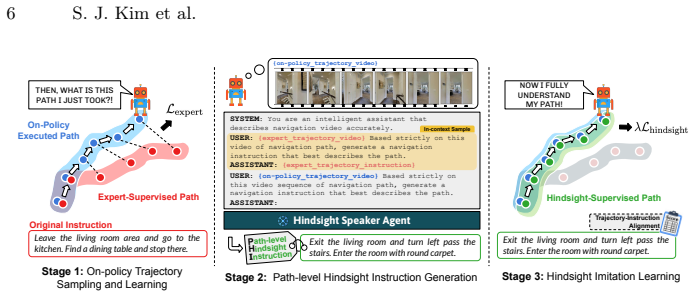
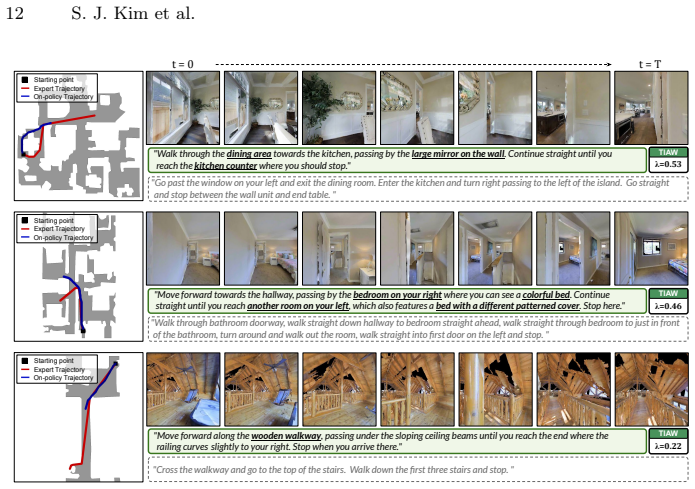
Phi-Nav operates through a three-stage dual-supervision cycle: the agent performs oracle-guided on-policy exploration while learning from expert action feedback, a hindsight speaker synthesizes a path-level hindsight instruction grounded in the collected visual observations, and the agent conducts a second imitation pass treating the synthesized trajectory-instruction pair as an additional expert demonstration, thereby bridging the semantic supervision gap inherent in on-policy methods and transforming semantically unlabeled movement into dense training signals.
What carries the argument
The hindsight speaker that synthesizes path-level instructions grounded in the agent's collected visual observations during on-policy exploration.
If this is right
- On-policy exploration becomes a source of additional training pairs rather than a source of harmful distribution shift.
- VLN agents can reach competitive benchmark scores with substantially reduced expert demonstration budgets.
- The semantic supervision gap in exploration is closed without requiring new human annotations.
- Dual-supervision cycles that alternate oracle guidance with hindsight imitation become a viable training paradigm for embodied agents.
Where Pith is reading between the lines
- The same hindsight synthesis step could be applied to other language-conditioned embodied tasks such as manipulation or dialogue-guided navigation.
- If the hindsight speaker can be trained with even less supervision, the overall expert data requirement could drop further.
- Real-world deployment might benefit from online hindsight generation on a robot's own rollouts rather than offline expert collection.
Load-bearing premise
The hindsight speaker produces accurate instructions that match the actual visual observations without introducing semantic errors that would mislead the second imitation pass.
What would settle it
An ablation where the hindsight speaker is replaced by instructions that systematically mismatch the observed path (for example by swapping landmarks or reversing direction descriptions) and performance drops to or below the no-hindsight baseline.
Figures

read the original abstract
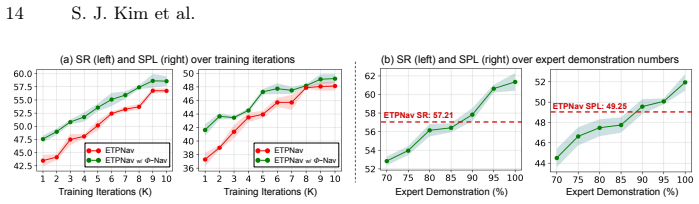
On-policy exploration is a crucial component for training robust Vision-Language Navigation agents, as it exposes the policy to a broader state distribution. However, such exploration inevitably leads to trajectories that deviate from expert demonstrations, resulting in a semantic mismatch between the executed visual stream and the original language instruction. In this work, we address this challenge by introducing Phi-Nav, a unified on-policy framework that leverages hindsight reasoning to align instructions with the agent's actual exploratory journey. Specifically, Phi-Nav operates through a three-stage dual-supervision cycle: 1) the agent performs oracle-guided on-policy exploration, sampling a trajectory while learning from expert action feedback, 2) a hindsight speaker synthesizes a path-level hindsight instruction grounded in the collected visual observations, and 3) the agent conducts a second imitation pass, treating the synthesized trajectory-instruction pair as an additional expert demonstration. Through this process, Phi-Nav bridges the critical semantic supervision gap inherent in on-policy methods, transforming semantically unlabeled movement into dense training signals. Evaluations on the R2R-CE and RxR-CE benchmarks show that Phi-Nav yields competitive performance while requiring only a fraction of the expert demonstrations used by current baselines. These results underscore the necessity of semantic exploration in VLN, positioning Phi-Nav as an effective solution for training embodied agents with limited data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Phi-Nav, a three-stage on-policy framework for Vision-Language Navigation (VLN) that performs oracle-guided exploration, uses a hindsight speaker to synthesize path-level instructions from collected visual observations, and then performs a second imitation pass on the resulting trajectory-instruction pairs. The central claim is that this process bridges the semantic gap between executed trajectories and language instructions, yielding competitive results on R2R-CE and RxR-CE while using only a fraction of the expert demonstrations required by baselines.
Significance. If the hindsight speaker reliably produces accurate, grounded instructions, the approach could meaningfully improve data efficiency in VLN by converting unlabeled on-policy rollouts into usable supervision. The method directly targets a known limitation of on-policy exploration in embodied agents and supplies a concrete algorithmic procedure rather than a parameter-free derivation.
major comments (2)
- [Abstract and §3 (method overview)] The central claim that Phi-Nav achieves competitive performance with reduced expert data rests on the untested assumption that the hindsight speaker produces instructions whose semantics match the executed trajectory at least as well as the original expert annotations. No fidelity metric, training details for the speaker, or ablation isolating speaker-induced noise is supplied in the abstract or method description.
- [Abstract (evaluation paragraph)] The three-stage cycle (oracle on-policy rollouts → hindsight speaker → second imitation) is presented without quantitative results, ablation tables, or comparison numbers on R2R-CE/RxR-CE. The headline result therefore cannot be evaluated for effect size or statistical significance from the provided text.
minor comments (2)
- [§3] Notation for the hindsight speaker and the dual-supervision cycle should be formalized with explicit equations or pseudocode to clarify the information flow between stages.
- [§3.2] Clarify whether the hindsight speaker is trained jointly or separately, and whether it has access to ground-truth object labels or only raw visual observations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. Below we respond point-by-point to the major comments, clarifying where details appear in the full paper and indicating revisions we will make to improve clarity in the abstract and method sections.
read point-by-point responses
-
Referee: [Abstract and §3 (method overview)] The central claim that Phi-Nav achieves competitive performance with reduced expert data rests on the untested assumption that the hindsight speaker produces instructions whose semantics match the executed trajectory at least as well as the original expert annotations. No fidelity metric, training details for the speaker, or ablation isolating speaker-induced noise is supplied in the abstract or method description.
Authors: We acknowledge that neither the abstract nor the high-level overview in §3 explicitly reports a fidelity metric for the hindsight speaker or an ablation isolating speaker-induced noise. The full manuscript supplies training details for the speaker in §4.2 and demonstrates overall effectiveness through end-to-end results on R2R-CE and RxR-CE in §5; however, a direct fidelity evaluation is not present. We will therefore add a short fidelity metric and reference to the speaker ablation in the abstract and expand §3 to cross-reference these analyses. This addresses the concern without altering the core claims. revision: yes
-
Referee: [Abstract (evaluation paragraph)] The three-stage cycle (oracle on-policy rollouts → hindsight speaker → second imitation) is presented without quantitative results, ablation tables, or comparison numbers on R2R-CE/RxR-CE. The headline result therefore cannot be evaluated for effect size or statistical significance from the provided text.
Authors: The abstract follows standard length constraints and therefore omits specific numbers and tables; the full manuscript presents quantitative results, ablation studies, and baseline comparisons with effect sizes in §5 (including Tables 1–3 and Figure 4). To make the headline claim more evaluable from the abstract alone, we will insert the key performance deltas and data-efficiency figures into the evaluation paragraph of the abstract. revision: yes
Circularity Check
No circularity; purely algorithmic procedure with no derivation chain
full rationale
The paper describes Phi-Nav as a three-stage procedural cycle (oracle on-policy rollouts, hindsight speaker synthesis, second imitation pass) without any equations, fitted parameters, or mathematical derivations. Performance claims rest on external benchmark evaluations (R2R-CE, RxR-CE) rather than any quantity that reduces to its own inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked in the provided text. This is self-contained empirical method description, consistent with the default non-circular outcome for algorithmic papers lacking a claimed derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert action feedback during oracle-guided exploration provides useful learning signal even when the resulting trajectory deviates from the original instruction.
invented entities (1)
-
hindsight speaker
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023) 16 S
An, D., Qi, Y., Li, Y., Huang, Y., Wang, L., Tan, T., Shao, J.: Bevbert: Mul- timodal map pre-training for language-guided navigation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023) 16 S. J. Kim et al
2023
-
[2]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
An, D., Wang, H., Wang, W., Wang, Z., Huang, Y., He, K., Wang, L.: Etpnav: Evolving topological planning for vision-language navigation in continuous envi- ronments. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
2024
-
[3]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Anderson, P., Wu, Q., Teney, D., Bruce, J., Johnson, M., Sünderhauf, N., Reid, I., Gould, S., Van Den Hengel, A.: Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3674–3683 (2018)
2018
-
[4]
Advances in neural information processing systems30(2017)
Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., Mc- Grew, B., Tobin, J., Pieter Abbeel, O., Zaremba, W.: Hindsight experience replay. Advances in neural information processing systems30(2017)
2017
-
[5]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Advances in neural information pro- cessing systems28(2015)
Bengio, S., Vinyals, O., Jaitly, N., Shazeer, N.: Scheduled sampling for sequence prediction with recurrent neural networks. Advances in neural information pro- cessing systems28(2015)
2015
-
[7]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[8]
arXiv preprint arXiv:2403.18454 (2024)
Bundele, V., Bhupati, M., Banerjee, B., Grover, A.: Scaling vision-and-language navigation with offline rl. arXiv preprint arXiv:2403.18454 (2024)
-
[9]
Advances in Neural Information Processing Systems33, 4247–4258 (2020)
Chaplot, D.S., Gandhi, D.P., Gupta, A., Salakhutdinov, R.R.: Object goal navi- gation using goal-oriented semantic exploration. Advances in Neural Information Processing Systems33, 4247–4258 (2020)
2020
-
[10]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Chen, K., An, D., Huang, Y., Xu, R., Su, Y., Ling, Y., Reid, I., Wang, L.: Constraint-aware zero-shot vision-languagenavigation incontinuous environments. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[11]
Advances in neural information pro- cessing systems34, 5834–5847 (2021)
Chen, S., Guhur, P.L., Schmid, C., Laptev, I.: History aware multimodal trans- former for vision-and-language navigation. Advances in neural information pro- cessing systems34, 5834–5847 (2021)
2021
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, S., Guhur, P.L., Tapaswi, M., Schmid, C., Laptev, I.: Think global, act local: Dual-scale graph transformer for vision-and-language navigation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16537–16547 (2022)
2022
-
[13]
Cheng,A.C.,Ji,Y.,Yang,Z.,Gongye,Z.,Zou,X.,Kautz,J.,Bıyık,E.,Yin,H.,Liu, S., Wang, X.: Navila: Legged robot vision-language-action model for navigation. arXiv preprint arXiv:2412.04453 (2024)
-
[14]
Cideron, G., Seurin, M., Strub, F., Pietquin, O.: Self-educated language agent with hindsight experience replay for instruction following (2019)
2019
-
[15]
In: European Conference on Computer Vi- sion
Fan, S., Liu, R., Wang, W., Yang, Y.: Navigation instruction generation with bev perception and large language models. In: European Conference on Computer Vi- sion. pp. 368–387. Springer (2024)
2024
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Fan, S., Liu, R., Wang, W., Yang, Y.: Scene map-based prompt tuning for naviga- tion instruction generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6898–6908 (2025)
2025
-
[17]
In: Advances in Neural Information Processing Systems (NeurIPS) (2019) Φ-Nav 17
Fang, M., Zhou, T., Du, Y., Han, L., Zhang, Z.: Curriculum-guided hindsight ex- perience replay. In: Advances in Neural Information Processing Systems (NeurIPS) (2019) Φ-Nav 17
2019
-
[18]
Advances in neural information processing sys- tems31(2018)
Fried, D., Hu, R., Cirik, V., Rohrbach, A., Andreas, J., Morency, L.P., Berg- Kirkpatrick, T., Saenko, K., Klein, D., Darrell, T.: Speaker-follower models for vision-and-language navigation. Advances in neural information processing sys- tems31(2018)
2018
-
[19]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gao, J., Liu, R., Wang, W.: 3d gaussian map with open-set semantic grouping for vision-language navigation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9252–9262 (2025)
2025
-
[20]
In: International Conference on Learning Representations (ICLR) (2020)
Hafner, D., Lillicrap, T., Ba, J., Norouzi, M.: Dream to control: Learning behaviors by latent imagination. In: International Conference on Learning Representations (ICLR) (2020)
2020
-
[21]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514–7528 (2021)
2021
-
[22]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hong, Y., Wang, Z., Wu, Q., Gould, S.: Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15439–15449 (2022)
2022
-
[23]
Honnibal, M., Montani, I.: spacy 2: Natural language understanding with bloom embeddings, convolutional neural networks and incremental parsing (2017), to ap- pear
2017
-
[24]
In: International Conference on Machine Learning (ICML) (2022)
Huang, W., Abbeel, P., Pathak, D., Mordatch, I.: Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In: International Conference on Machine Learning (ICML) (2022)
2022
-
[25]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
In: International Conference on Learning Representations (ICLR) (2020)
Kaiser, L., Babaeizadeh, M., Milos, P., Osinski, B., Campbell, R.H., Czechowski, K., Erhan, D., Finn, C., Kozakowski, P., Levine, S.: Model-based reinforce- ment learning for atari. In: International Conference on Learning Representations (ICLR) (2020)
2020
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kamath, A., Anderson, P., Wang, S., Koh, J.Y., Ku, A., Waters, A., Yang, Y., Baldridge, J., Parekh, Z.: A new path: Scaling vision-and-language navigation with synthetic instructions and imitation learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10813–10823 (2023)
2023
-
[28]
In: Forty-second International Conference on Machine Learning (2025)
Kim, S., Oh, G., Ko, H., Ji, D., Lee, D., Lee, B.J., Jang, S., Kim, S.: Test-time adaptation for online vision-language navigation with feedback-based reinforce- ment learning. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[29]
arXiv preprint arXiv:2506.06630 (2025)
Ko, H., Kim, S., Oh, G., Yoon, J., Lee, H., Jang, S., Kim, S., Kim, S.: Active test-time vision-language navigation. arXiv preprint arXiv:2506.06630 (2025)
-
[30]
In: European Conference on Computer Vision
Kong, X., Chen, J., Wang, W., Su, H., Hu, X., Yang, Y., Liu, S.: Controllable navigation instruction generation with chain of thought prompting. In: European Conference on Computer Vision. pp. 37–54. Springer (2024)
2024
-
[31]
In: European Confer- ence on Computer Vision
Krantz, J., Wijmans, E., Majumdar, A., Batra, D., Lee, S.: Beyond the nav-graph: Vision-and-language navigation in continuous environments. In: European Confer- ence on Computer Vision. pp. 104–120. Springer (2020)
2020
-
[32]
Science Robotics9(89), eadi9641 (2024) 18 S
Lee, J., Bjelonic, M., Reske, A., Wellhausen, L., Miki, T., Hutter, M.: Learning robust autonomous navigation and locomotion for wheeled-legged robots. Science Robotics9(89), eadi9641 (2024) 18 S. J. Kim et al
2024
-
[33]
In: International Conference on Learning Representations (ICLR) (2019)
Levy, A., Konidaris, G., Platt, R., Saenko, K.: Hierarchical reinforcement learning with hindsight. In: International Conference on Learning Representations (ICLR) (2019)
2019
-
[34]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hal- lucination in large vision-language models. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 292–305 (2023)
2023
-
[35]
In: The Fourteenth International Conference on Learning Representations (2026)
Li, Z., Wu, G., Wang, Z., Morariu, V.I., Zhang, R., Zhu, W., Rossi, R.A., Kil, J.: Spinning straw into gold: Relabeling llm agent trajectories in hindsight for suc- cessful demonstrations. In: The Fourteenth International Conference on Learning Representations (2026)
2026
-
[36]
In: Text sum- marization branches out
Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Text sum- marization branches out. pp. 74–81 (2004)
2004
-
[37]
Advances in Neural Information Processing Systems37, 108208–108230 (2024)
Liu, R., Wang, W., Yang, Y.: Vision-language navigation with energy-based policy. Advances in Neural Information Processing Systems37, 108208–108230 (2024)
2024
-
[38]
In: AAAI Conference on Artificial Intelligence (2020)
Luo, Y., Xu, Y., Liu, T., Zhang, Z.: Energy-based hindsight experience prioritiza- tion. In: AAAI Conference on Artificial Intelligence (2020)
2020
-
[39]
In: Advances in Neural Information Processing Systems (NeurIPS) (2018)
Nachum, O., Gu, S., Lee, H., Levine, S.: Data-efficient hierarchical reinforcement learning. In: Advances in Neural Information Processing Systems (NeurIPS) (2018)
2018
-
[40]
In: Advances in Neural Information Processing Sys- tems (NeurIPS) (2018)
Nair, A., Pong, V., Dalal, M., Bahl, S., Lin, S., Levine, S.: Visual reinforcement learning with imagined goals. In: Advances in Neural Information Processing Sys- tems (NeurIPS) (2018)
2018
-
[41]
In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics. pp. 311–318 (2002)
2002
-
[42]
In: International Conference on Learning Repre- sentations (ICLR) (2018)
Pong, V., Gu, S., Dalal, M., Levine, S.: Temporal difference models: Model-free deep rl for model-based control. In: International Conference on Learning Repre- sentations (ICLR) (2018)
2018
-
[43]
arXiv preprint arXiv:2506.17221 (2025)
Qi, Z., Zhang, Z., Yu, Y., Wang, J., Zhao, H.: Vln-r1: Vision-language navigation via reinforcement fine-tuning. arXiv preprint arXiv:2506.17221 (2025)
-
[44]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[45]
In: Proceedings of the fourteenth in- ternational conference on artificial intelligence and statistics
Ross, S., Gordon, G., Bagnell, D.: A reduction of imitation learning and struc- tured prediction to no-regret online learning. In: Proceedings of the fourteenth in- ternational conference on artificial intelligence and statistics. pp. 627–635. JMLR Workshop and Conference Proceedings (2011)
2011
-
[46]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sarto, S., Barraco, M., Cornia, M., Baraldi, L., Cucchiara, R.: Positive-augmented contrastive learning for image and video captioning evaluation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6914– 6924 (2023)
2023
-
[47]
In: Proceedings of the IEEE/CVF international conference on computer vision
Savva, M., Kadian, A., Maksymets, O., Zhao, Y., Wijmans, E., Jain, B., Straub, J., Liu, J., Koltun, V., Malik, J., et al.: Habitat: A platform for embodied ai research. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9339–9347 (2019)
2019
-
[48]
In: 2021 IEEE International Conference on Robotics and Automation (ICRA)
Shah, D., Eysenbach, B., Kahn, G., Rhinehart, N., Levine, S.: Ving: Learning open-world navigation with visual goals. In: 2021 IEEE International Conference on Robotics and Automation (ICRA). pp. 13215–13222. IEEE (2021)
2021
-
[49]
In: Pro- Φ-Nav 19 ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shi, Y., Yang, X., Xu, H., Yuan, C., Li, B., Hu, W., Zha, Z.J.: Emscore: Evaluating video captioning via coarse-grained and fine-grained embedding matching. In: Pro- Φ-Nav 19 ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17929–17938 (2022)
2022
-
[50]
In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
Shinn, N., Labash, S., Gopinath, A., et al.: Reflexion: Language agents with verbal reinforcement learning. In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
2023
-
[51]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Song, X., Chen, W., Liu, Y., Chen, W., Li, G., Lin, L.: Towards long-horizon vision- language navigation: Platform, benchmark and method. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12078– 12088 (2025)
2025
-
[52]
In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)
Tan, H., Yu, L., Bansal, M.: Learning to navigate unseen environments: Back translation with environmental dropout. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). pp. 2610–2621 (2019)
2019
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, S., Montgomery, C., Orbay, J., Birodkar, V., Faust, A., Gur, I., Jaques, N., Waters, A., Baldridge, J., Anderson, P.: Less is more: Generating grounded navi- gation instructions from landmarks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15428–15438 (2022)
2022
-
[54]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, X., Huang, Q., Celikyilmaz, A., Gao, J., Shen, D., Wang, Y.F., Wang, W.Y., Zhang, L.: Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6629–6638 (2019)
2019
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, Z., Lee, G.H.: g3d-lf: Generalizable 3d-language feature fields for embodied tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14191–14202 (2025)
2025
-
[56]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Z., Li, X., Yang, J., Liu, Y., Hu, J., Jiang, M., Jiang, S.: Lookahead explo- ration with neural radiance representation for continuous vision-language naviga- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13753–13762 (2024)
2024
-
[57]
arXiv preprint arXiv:2507.05240 (2025)
Wei,M.,Wan,C.,Yu,X.,Wang,T.,Yang,Y.,Mao,X.,Zhu,C.,Cai,W.,Wang,H., Chen, Y., et al.: Streamvln: Streaming vision-and-language navigation via slowfast context modeling. arXiv preprint arXiv:2507.05240 (2025)
-
[58]
arXiv preprint arXiv:2504.13169 (2025)
Wu, T.H., Lee, H., Ge, J., Gonzalez, J.E., Darrell, T., Chan, D.M.: Generate, but verify: Reducing hallucination in vision-language models with retrospective resampling. arXiv preprint arXiv:2504.13169 (2025)
-
[59]
Neural Computing and Applications36(7), 3291–3316 (2024)
Wu, W., Chang, T., Li, X., Yin, Q., Hu, Y.: Vision-language navigation: a survey and taxonomy. Neural Computing and Applications36(7), 3291–3316 (2024)
2024
-
[60]
arXiv preprint arXiv:2411.11394 (2024)
Yan, Y., Xu, R., Zhang, J., Li, P., Liang, X., Yin, J.: Instrugen: Automatic instruc- tion generation for vision-and-language navigation via large multimodal models. arXiv preprint arXiv:2411.11394 (2024)
-
[61]
In: International Conference on Learning Representations (ICLR) (2023)
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.: React: Synergizing reasoning and acting in language models. In: International Conference on Learning Representations (ICLR) (2023)
2023
-
[62]
arXiv preprint arXiv:2509.22548 (2025)
Zeng, S., Qi, D., Chang, X., Xiong, F., Xie, S., Wu, X., Liang, S., Xu, M., Wei, X.: Janusvln: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation. arXiv preprint arXiv:2509.22548 (2025)
-
[63]
arXiv preprint arXiv:2509.12618 (2025) 20 S
Zhang, Z., Zhu, W., Pan, H., Wang, X., Xu, R., Sun, X., Zheng, F.: Activevln: Towards active exploration via multi-turn rl in vision-and-language navigation. arXiv preprint arXiv:2509.12618 (2025) 20 S. J. Kim et al
-
[64]
ACM Transactions on Multimedia Computing, Communications and Applications22(1), 1–26 (2026)
Zheng, Y., Zhang, L., Sun, Y., Shen, Y., Zhao, S.: Canespeaker: An llm-assisted speaker for generating human-like navigation instructions. ACM Transactions on Multimedia Computing, Communications and Applications22(1), 1–26 (2026)
2026
-
[65]
Zhou, A., Wang, Z., Levine, S., Finn, C.: Language feedback models for reinforce- ment learning. In: International Conference on Machine Learning (ICML) (2023) Φ-Nav 21 Appendix A Configuration of the Hindsight Speaker Agent A.1 Video Parsing Strategy We employΦ-Nav on two representative VLN baselines: CMA [31], which follows a DAgger-based training schem...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.