In LLM Reasoning, there is Irrationality on top of Value Misalignment
Pith reviewed 2026-06-29 17:34 UTC · model grok-4.3
The pith
LLMs can fail to maximize aligned values in reasoning even after successful post-training alignment due to rational value risk.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper formalizes rational value risk as the utility discrepancy between a model's deployed reasoning strategy and its rational counterpart, defined to be the responses that maximise expected utility in the steepest direction; the estimation error of this risk decomposes into three components arising from finite candidates, finite prompts, and imperfect verifiers.
What carries the argument
Rational value risk, the utility discrepancy between deployed reasoning and the steepest-utility rational counterpart.
If this is right
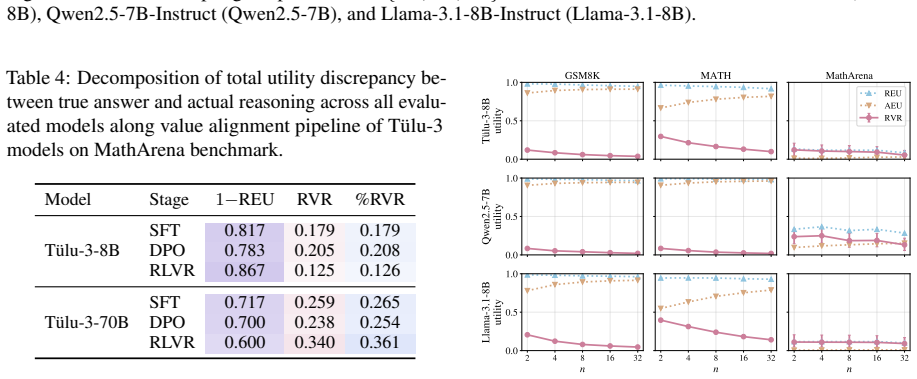
- Rational value risk remains widespread even in aligned models from multiple families and sizes.
- Value alignment during training reduces but does not eliminate rational value risk.
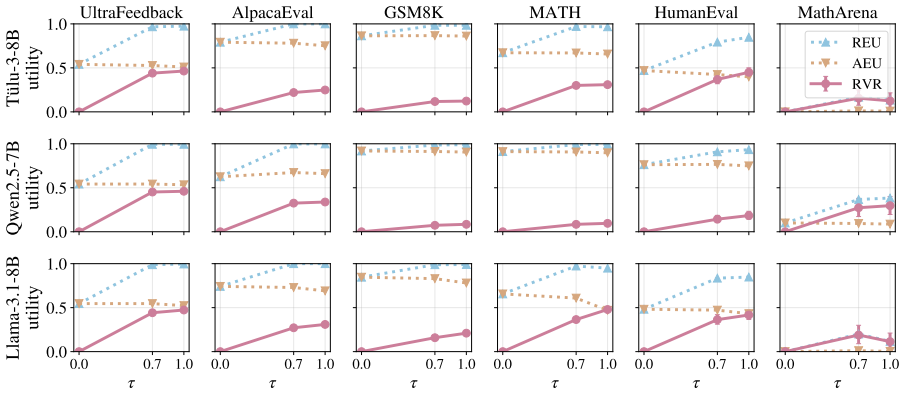
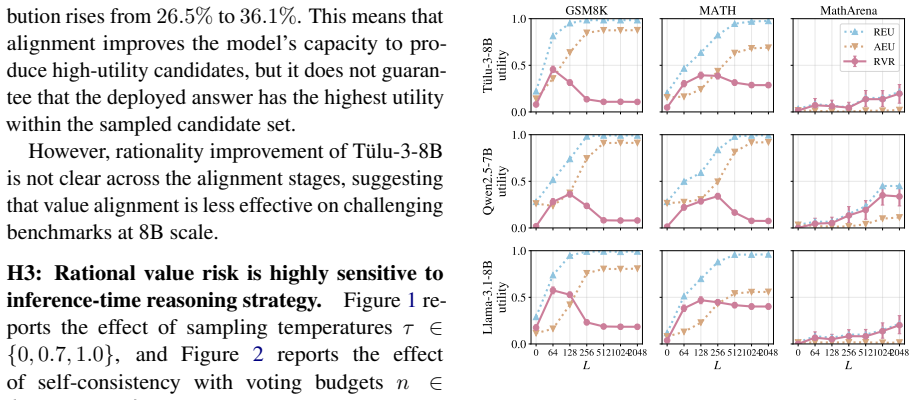
- The magnitude of the risk depends strongly on the inference-time reasoning strategy employed.
- Extending reasoning length improves rationality, yet gains diminish after a point.
Where Pith is reading between the lines
- Post-training alignment may need to be supplemented by inference-time mechanisms that explicitly search for steepest-utility responses.
- The three error components suggest targeted improvements in candidate generation, prompt design, or verifier accuracy could shrink the risk.
- Tasks requiring precise value maximization, such as safety-critical decisions, may remain unreliable until rational value risk is directly addressed.
- The same gap between alignment and rational deployment could appear in non-LLM agent systems that optimize under uncertainty.
Load-bearing premise
The rational counterpart can be identified as responses that maximise expected utility in the steepest direction, and the three-component decomposition fully captures all sources of the risk.
What would settle it
A controlled experiment in which a model's deployed reasoning strategy is shown to achieve equal or higher expected utility than the identified steepest-direction responses on the same task would falsify the presence of rational value risk.
Figures
read the original abstract
Significant progress has been made in aligning LLMs with target value functions. We argue that, even when an LLM has been well aligned in (post-)training, it may still fail to maximise the aligned value in reasoning. We mathematically formalise this gap as rational value risk: the utility discrepancy between a model's deployed reasoning strategy and its rational counterpart, which is defined to be the responses that maximise expected utility in the steepest direction. The estimation error of rational value risk is further decomposed into three components from finite candidates, finite prompts, and imperfect verifiers. Extensive experiments are conducted, covering models Llama-3.1, Qwen-2.5, T{\"}ulu-3 families (7B-72B), GPT-5.2, GPT-5.5, and DeepSeek-V4, and benchmarks UltraFeedback, AlpacaEval, GSM8K, MATH, HumanEval, and MathArena. The results validate that (1) rational value risk is widespread; (2) value alignment can reduce, but cannot eliminate, it; (3) the risk is highly sensitive to inference-time reasoning strategy; and (4) longer reasoning improves rationality with diminishing returns. The code is at https://github.com/EVIEHub/LLM-Rationality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that even after value alignment in post-training, LLMs may still fail to maximize the aligned value during reasoning. This gap is formalized as rational value risk: the utility discrepancy between a model's deployed reasoning strategy and its rational counterpart (defined as the responses that maximize expected utility in the steepest direction). The estimation error of this risk is decomposed into three components arising from finite candidates, finite prompts, and imperfect verifiers. Experiments across Llama-3.1, Qwen-2.5, Tulu-3 (7B-72B), GPT-5.2/5.5, and DeepSeek-V4 on benchmarks including UltraFeedback, AlpacaEval, GSM8K, MATH, HumanEval, and MathArena show that rational value risk is widespread, reduced but not eliminated by alignment, highly sensitive to inference-time strategies, and decreases with longer reasoning (with diminishing returns).
Significance. If the formalization holds without circularity, the work usefully separates value alignment from rational maximization in reasoning, with practical implications for inference-time methods. The broad empirical scope across model families, sizes, and tasks provides concrete evidence that the phenomenon is not isolated; the public code release supports reproducibility.
major comments (2)
- [Abstract / Formalization] Abstract and formalization (likely §3): the rational counterpart is defined as responses that 'maximise expected utility in the steepest direction.' In discrete token/output spaces this requires an explicit metric, embedding, or operator (e.g., a policy gradient or continuous relaxation) to define 'direction' and 'steepest'; none is supplied in the visible description. Without such an operator independent of the deployed strategy, the discrepancy measure risks being partly tautological with the alignment process itself.
- [Error decomposition] Abstract and § on error decomposition: the three-component decomposition (finite candidates, finite prompts, imperfect verifiers) inherits the same ambiguity in the definition of the rational benchmark. If the benchmark itself is under-specified, the attribution of estimation error to these sources cannot be cleanly separated from the definitional issue.
minor comments (1)
- [Experiments] The abstract states that 'the results validate' the four claims but does not report how the steepest-direction strategy was computed or cross-checked against the paper's own data; adding a short methods paragraph or appendix table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the formalization and error decomposition. We address each major point below and will incorporate clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Formalization] Abstract and formalization (likely §3): the rational counterpart is defined as responses that 'maximise expected utility in the steepest direction.' In discrete token/output spaces this requires an explicit metric, embedding, or operator (e.g., a policy gradient or continuous relaxation) to define 'direction' and 'steepest'; none is supplied in the visible description. Without such an operator independent of the deployed strategy, the discrepancy measure risks being partly tautological with the alignment process itself.
Authors: We agree that the current high-level phrasing of 'maximise expected utility in the steepest direction' requires an explicit operator to be well-defined in discrete output spaces. The manuscript does not supply this operator in the provided description. In revision we will add a precise definition (e.g., via a continuous relaxation of the token embedding space or a directional derivative with respect to the aligned value function) that is independent of any deployed reasoning strategy. This will also make explicit that the rational benchmark is computed solely from the aligned value function and is therefore not tautological with post-training alignment. revision: yes
-
Referee: [Error decomposition] Abstract and § on error decomposition: the three-component decomposition (finite candidates, finite prompts, imperfect verifiers) inherits the same ambiguity in the definition of the rational benchmark. If the benchmark itself is under-specified, the attribution of estimation error to these sources cannot be cleanly separated from the definitional issue.
Authors: We concur that the error decomposition presupposes a well-specified rational benchmark. Once the operator for the steepest direction is formalized as described above, each of the three error sources can be attributed relative to that benchmark. The revised manuscript will include an expanded derivation showing how the finite-candidate, finite-prompt, and verifier-error terms are isolated from the now-explicit rational reference. revision: yes
Circularity Check
No significant circularity; definition is explicit and claims rest on independent experiments
full rationale
The paper explicitly defines rational value risk as the utility discrepancy to a separately defined rational counterpart (responses maximising expected utility in the steepest direction). The three-component decomposition applies only to estimation error of this quantity, not to the quantity itself. Validation rests on empirical results across multiple model families and benchmarks (Llama-3.1, Qwen-2.5, etc.; UltraFeedback, GSM8K, etc.), which are external to the definition. No equations reduce the central claim to a fit or self-citation by construction, and no load-bearing self-citation or ansatz smuggling is present in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Li, Lihong and Wiewiora, Eric and Langford, John and Littman, Michael L
Strehl, Alexander L. and Li, Lihong and Wiewiora, Eric and Langford, John and Littman, Michael L. , title =. 2006 , publisher =. doi:10.1145/1143844.1143955 , booktitle =
-
[2]
1998 , publisher=
Statistical Learning Theory , author=. 1998 , publisher=
1998
-
[3]
Robust Multi-Agent Reinforcement Learning via Adversarial Regularization: Theoretical Foundation and Stable Algorithms , volume =
Bukharin, Alexander and Li, Yan and Yu, Yue and Zhang, Qingru and Chen, Zhehui and Zuo, Simiao and Zhang, Chao and Zhang, Songan and Zhao, Tuo , booktitle =. Robust Multi-Agent Reinforcement Learning via Adversarial Regularization: Theoretical Foundation and Stable Algorithms , volume =
-
[4]
Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , pages =
Coarse-Grained Smoothness for Reinforcement Learning in Metric Spaces , author =. Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , pages =. 2023 , volume =
2023
-
[5]
Munchausen Reinforcement Learning , volume =
Vieillard, Nino and Pietquin, Olivier and Geist, Matthieu , booktitle =. Munchausen Reinforcement Learning , volume =
-
[6]
Substantive Rationality and Backward Induction , journal =. 2001 , issn =. doi:https://doi.org/10.1006/game.2000.0838 , url =
-
[7]
Journal of Machine Learning Research , year =
Peter Sunehag and Marcus Hutter , title =. Journal of Machine Learning Research , year =
-
[8]
Dean, James W. and Sharfman, Mark P. , title =. Journal of Management Studies , volume =. doi:https://doi.org/10.1111/j.1467-6486.1993.tb00317.x , year =
-
[9]
Thermodynamics as a theory of decision-making with information-processing costs , journal =. 2013 , author =. doi:10.1098/rspa.2012.0683 , month_numeric =
-
[10]
Theory and decision , volume=
Subjective expected utility: A review of normative theories , author=. Theory and decision , volume=. 1981 , publisher=
1981
-
[11]
Max Weber's Types of Rationality: Cornerstones for the Analysis of Rationalization Processes in History , urldate =
Stephen Kalberg , journal =. Max Weber's Types of Rationality: Cornerstones for the Analysis of Rationalization Processes in History , urldate =
-
[12]
2018 , eprint=
Equivalence Between Policy Gradients and Soft Q-Learning , author=. 2018 , eprint=
2018
-
[13]
2016 , eprint=
Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks , author=. 2016 , eprint=
2016
-
[14]
Maximum-Entropy Adversarial Data Augmentation for Improved Generalization and Robustness , url =
Zhao, Long and Liu, Ting and Peng, Xi and Metaxas, Dimitris , booktitle =. Maximum-Entropy Adversarial Data Augmentation for Improved Generalization and Robustness , url =
-
[15]
Proceedings of Thirty Third Conference on Learning Theory , pages =
Provably efficient reinforcement learning with linear function approximation , author =. Proceedings of Thirty Third Conference on Learning Theory , pages =. 2020 , volume =
2020
-
[16]
Kakade and Jason D
Alekh Agarwal and Sham M. Kakade and Jason D. Lee and Gaurav Mahajan , title =. Journal of Machine Learning Research , year =
-
[17]
Improved algorithms for linear stochastic bandits , year =
Abbasi-Yadkori, Yasin and P\'. Improved algorithms for linear stochastic bandits , year =. Proceedings of the 25th International Conference on Neural Information Processing Systems , pages =
-
[18]
the Annals of Probability , pages=
On tail probabilities for martingales , author=. the Annals of Probability , pages=. 1975 , publisher=
1975
-
[19]
2022 , eprint=
Near-Optimal Randomized Exploration for Tabular Markov Decision Processes , author=. 2022 , eprint=
2022
-
[20]
2024 , eprint=
Efficient, Low-Regret, Online Reinforcement Learning for Linear MDPs , author=. 2024 , eprint=
2024
-
[21]
International Conference on Machine Learning , pages=
Randomized exploration in reinforcement learning with general value function approximation , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[22]
2019 , eprint=
Q-learning with UCB Exploration is Sample Efficient for Infinite-Horizon MDP , author=. 2019 , eprint=
2019
-
[23]
Utility and probability , pages=
Bounded rationality , author=. Utility and probability , pages=. 1990 , publisher=
1990
-
[24]
Reinforcement learning: State-of-the-art , pages=
Game theory and multi-agent reinforcement learning , author=. Reinforcement learning: State-of-the-art , pages=. 2012 , publisher=
2012
-
[25]
, author=
Algorithms for inverse reinforcement learning. , author=. Icml , volume=
-
[26]
Cognitive, Affective, & Behavioral Neuroscience , volume=
Decision theory, reinforcement learning, and the brain , author=. Cognitive, Affective, & Behavioral Neuroscience , volume=. 2008 , publisher=
2008
-
[27]
2023 , eprint=
On the Power of Pre-training for Generalization in RL: Provable Benefits and Hardness , author=. 2023 , eprint=
2023
-
[28]
International Conference on Machine Learning , pages=
Risk bounds and rademacher complexity in batch reinforcement learning , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[29]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Playing Atari with Deep Reinforcement Learning
Playing atari with deep reinforcement learning , author=. arXiv preprint arXiv:1312.5602 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
2018 , publisher=
Reinforcement learning: An introduction , author=. 2018 , publisher=
2018
-
[32]
A survey of sim-to-real methods in rl: Progress, prospects and challenges with foundation models , author=. arXiv preprint arXiv:2502.13187 , year=
-
[33]
, title =
Dietterich, Thomas G. , title =. Journal of Artificial Intelligence Research , pages =. 2000 , issue_date =
2000
-
[34]
Assessing Generalization in Deep Reinforcement Learning
Assessing generalization in deep reinforcement learning , author=. arXiv preprint arXiv:1810.12282 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
nature , volume=
Mastering the game of go without human knowledge , author=. nature , volume=. 2017 , publisher=
2017
-
[36]
2019 Third IEEE international conference on robotic computing (IRC) , pages=
Review of deep reinforcement learning for robot manipulation , author=. 2019 Third IEEE international conference on robotic computing (IRC) , pages=. 2019 , organization=
2019
-
[37]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
IEEE transactions on intelligent transportation systems , volume=
Deep reinforcement learning for autonomous driving: A survey , author=. IEEE transactions on intelligent transportation systems , volume=. 2021 , publisher=
2021
-
[39]
ACM Computing Surveys (CSUR) , volume=
Reinforcement learning in healthcare: A survey , author=. ACM Computing Surveys (CSUR) , volume=. 2021 , publisher=
2021
-
[40]
arXiv preprint arXiv:1911.10107 , year=
Deep reinforcement learning for trading , author=. arXiv preprint arXiv:1911.10107 , year=
-
[41]
International Conference on Artificial Intelligence and Statistics , pages=
Feasible Q -Learning for Average Reward Reinforcement Learning , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[42]
Advances in Neural Information Processing Systems , volume=
Regret minimization for reinforcement learning by evaluating the optimal bias function , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Near-Optimal Regret Bounds for Multi-batch Reinforcement Learning , url =
Zhang, Zihan and Jiang, Yuhang and Zhou, Yuan and Ji, Xiangyang , booktitle =. Near-Optimal Regret Bounds for Multi-batch Reinforcement Learning , url =
-
[44]
Mathematics of Operations Research , volume=
Efficient reinforcement learning in deterministic systems with value function generalization , author=. Mathematics of Operations Research , volume=. 2017 , publisher=
2017
-
[45]
2023 , eprint=
Nearly Minimax Optimal Reinforcement Learning for Linear Markov Decision Processes , author=. 2023 , eprint=
2023
-
[46]
, title =
Jiang, Nan and Krishnamurthy, Akshay and Agarwal, Alekh and Langford, John and Schapire, Robert E. , title =. Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =. 2017 , abstract =
2017
-
[47]
Advances in Neural Information Processing Systems , volume=
Eluder dimension and the sample complexity of optimistic exploration , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
International Conference on Machine Learning , pages=
Improved regret for efficient online reinforcement learning with linear function approximation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[49]
, author=
Reinforcement Learning in Finite MDPs: PAC Analysis. , author=. Journal of Machine Learning Research , volume=
-
[50]
Near Instance-Optimal PAC Reinforcement Learning for Deterministic MDPs , url =
Tirinzoni, Andrea and Al Marjani, Aymen and Kaufmann, Emilie , booktitle =. Near Instance-Optimal PAC Reinforcement Learning for Deterministic MDPs , url =
-
[51]
Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =
Distributionally Robust Off-Dynamics Reinforcement Learning: Provable Efficiency with Linear Function Approximation , author =. Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =. 2024 , volume =
2024
-
[52]
Dense reinforcement learning for safety validation of autonomous vehicles , volume =. Nature , author =. 2023 , pages =. doi:10.1038/s41586-023-05732-2 , number =
-
[53]
FinRL-Meta: Market Environments and Benchmarks for Data-Driven Financial Reinforcement Learning , volume =
Liu, Xiao-Yang and Xia, Ziyi and Rui, Jingyang and Gao, Jiechao and Yang, Hongyang and Zhu, Ming and Wang, Christina and Wang, Zhaoran and Guo, Jian , booktitle =. FinRL-Meta: Market Environments and Benchmarks for Data-Driven Financial Reinforcement Learning , volume =
-
[54]
Proceedings of the 34th International Conference on Machine Learning , pages =
Minimax Regret Bounds for Reinforcement Learning , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , volume =
2017
-
[55]
Journal of Economic Theory , volume=
Algorithmic rationality: Game theory with costly computation , author=. Journal of Economic Theory , volume=. 2015 , publisher=
2015
-
[56]
Matteo Leonetti and Luca Iocchi and Peter Stone , keywords =. A synthesis of automated planning and reinforcement learning for efficient, robust decision-making , journal =. 2016 , issn =. doi:https://doi.org/10.1016/j.artint.2016.07.004 , url =
-
[57]
Bounded Rationality , urldate =
Reinhard Selten , journal =. Bounded Rationality , urldate =
-
[58]
The collected works of Wassily Hoeffding , pages=
Probability inequalities for sums of bounded random variables , author=. The collected works of Wassily Hoeffding , pages=. 1994 , publisher=
1994
-
[59]
Machine learning , volume=
Linear least-squares algorithms for temporal difference learning , author=. Machine learning , volume=. 1996 , publisher=
1996
-
[60]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Robust Action Gap Increasing with Clipped Advantage Learning , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2022 , pages=. doi:10.1609/aaai.v36i8.20900 , abstractNote=
-
[61]
2002 , publisher=
Rationality and freedom , author=. 2002 , publisher=
2002
-
[62]
2025 , eprint=
Modelling bounded rational decision-making through Wasserstein constraints , author=. 2025 , eprint=
2025
-
[63]
doi:10.1515/9781400829460 , year =
Theory of Games and Economic Behavior , author =. doi:10.1515/9781400829460 , year =
-
[64]
Computational Economics , pages=
Reinforcement learning in economics and finance , author=. Computational Economics , pages=. 2021 , publisher=
2021
-
[65]
Journal of economic literature , volume=
Why bounded rationality? , author=. Journal of economic literature , volume=. 1996 , publisher=
1996
-
[66]
Gershman and Eric J
Samuel J. Gershman and Eric J. Horvitz and Joshua B. Tenenbaum , title =. Science , volume =. 2015 , doi =
2015
-
[67]
Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , pages =
Frequentist Regret Bounds for Randomized Least-Squares Value Iteration , author =. Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , pages =. 2020 , volume =
2020
-
[68]
and Krishnamurthy, Akshay , title =
Wang, Yining and Wang, Ruosong and Du, Simon S. and Krishnamurthy, Akshay , title =. 2021 International Conference on Learning Representations , year =
2021
-
[69]
An analysis of model-based Interval Estimation for Markov Decision Processes , journal =. 2008 , note =. doi:https://doi.org/10.1016/j.jcss.2007.08.009 , url =
-
[70]
Sequential Complexities and Uniform Martingale Laws of Large Numbers , volume =
Rakhlin, Alexander and Sridharan, Karthik and Tewari, Ambuj , year =. Sequential Complexities and Uniform Martingale Laws of Large Numbers , volume =. Probability Theory and Related Fields , doi =
-
[71]
Learning via Wasserstein-Based High Probability Generalisation Bounds , url =
Viallard, Paul and Haddouche, Maxime and Simsekli, Umut and Guedj, Benjamin , booktitle =. Learning via Wasserstein-Based High Probability Generalisation Bounds , url =
-
[72]
Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =
Sequence Length Independent Norm-Based Generalization Bounds for Transformers , author =. Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =. 2024 , editor =
2024
-
[73]
2024 IEEE International Symposium on Information Theory (ISIT) , pages=
An extension of mcdiarmid's inequality , author=. 2024 IEEE International Symposium on Information Theory (ISIT) , pages=. 2024 , organization=
2024
-
[74]
Surveys in combinatorics , volume=
On the method of bounded differences , author=. Surveys in combinatorics , volume=. 1989 , publisher=
1989
-
[75]
Provable Model-based Nonlinear Bandit and Reinforcement Learning: Shelve Optimism, Embrace Virtual Curvature , url =
Dong, Kefan and Yang, Jiaqi and Ma, Tengyu , booktitle =. Provable Model-based Nonlinear Bandit and Reinforcement Learning: Shelve Optimism, Embrace Virtual Curvature , url =
-
[76]
Advances in Neural Information Processing Systems , volume=
Understanding deep neural function approximation in reinforcement learning via -greedy exploration , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
Proceedings of the 36th International Conference on Machine Learning , pages =
On the Generalization Gap in Reparameterizable Reinforcement Learning , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , series =
2019
-
[78]
Generalization Bounds for Domain Adaptation , volume =
Zhang, Chao and Zhang, Lei and Ye, Jieping , booktitle =. Generalization Bounds for Domain Adaptation , volume =
-
[79]
1964 , publisher=
Information and Information Stability of Random Variables and Processes , author=. 1964 , publisher=
1964
-
[80]
2013 , month =
Boucheron, Stéphane and Lugosi, Gábor and Massart, Pascal , title =. 2013 , month =
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.