TrajLoc: Trajectory-Attention Localization for Multi-Object Motion Control
Pith reviewed 2026-07-02 14:19 UTC · model grok-4.3
The pith
Substituting cross-attention weights with per-object Gaussian heatmaps isolates trajectories for multi-object video control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
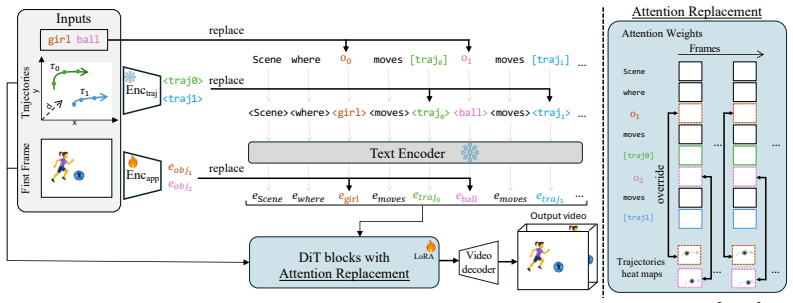
TrajLoc enforces strict per-object spatial constraints directly within the attention layers by substituting the cross-attention weights of each object token with a Gaussian heatmap centered on its target location at every frame. The same per-object token interface carries trajectory and depth through a learned embedding and preserves identity by encoding first frame appearance in place of an object token.
What carries the argument
Substitution of cross-attention weights with per-object Gaussian heatmaps centered on target locations at every frame.
If this is right
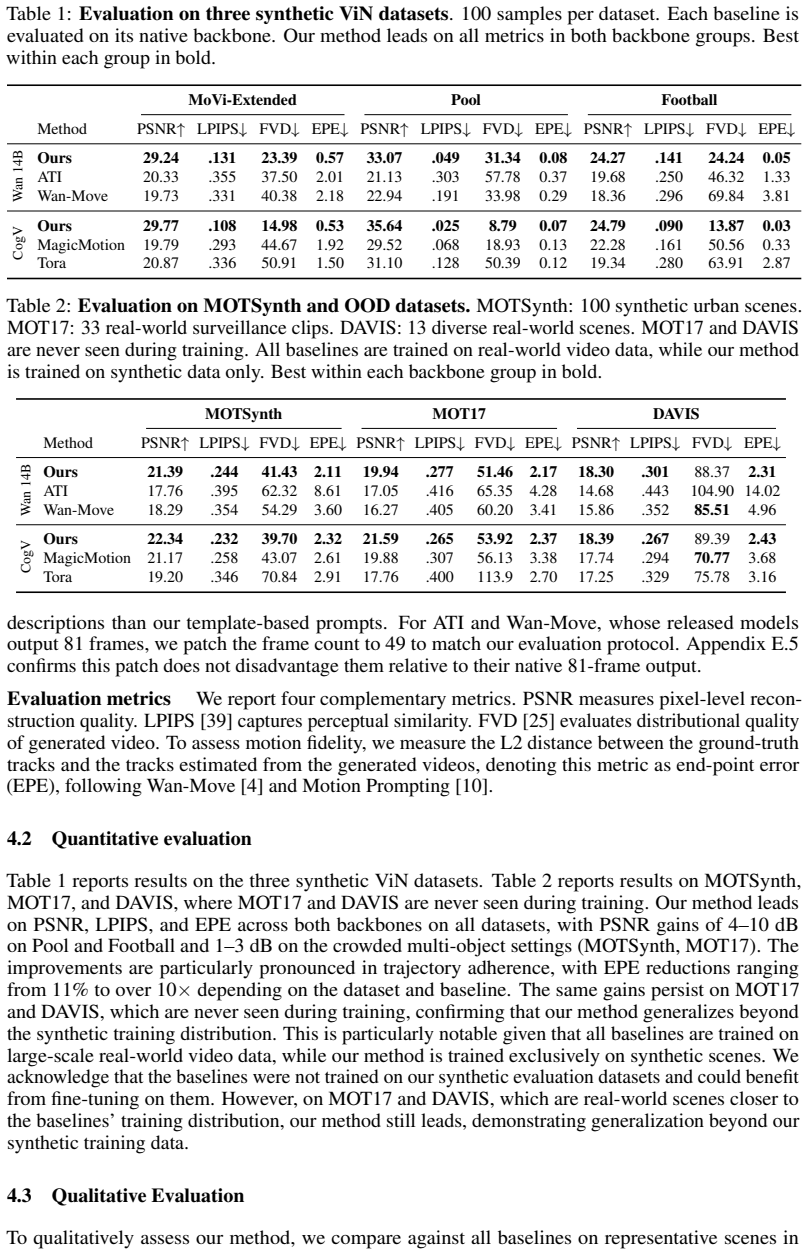
- Achieves average gains of +4.3 dB PSNR in visual fidelity across datasets.
- Reduces trajectory end point error by 51 percent relative to strongest baselines.
- Scales to scenes containing up to 20 simultaneously controlled objects.
- Applies to two architecturally distinct video generation backbones.
- Maintains improvements on out-of-distribution real-world scenes.
Where Pith is reading between the lines
- The per-object token interface could support additional conditioning signals such as velocity or interaction rules without redesigning the attention structure.
- The method may extend to tasks that require spatial localization in other generative domains such as image editing or 3D asset animation.
- Overlapping heatmaps at intersection points could be monitored to detect and resolve potential identity swaps automatically.
Load-bearing premise
The per-object Gaussian heatmaps isolate instances and enforce spatial constraints independently without introducing artifacts or breaking coherent video synthesis when paths intersect or occlude.
What would settle it
Apply the method to a video scene where two object trajectories cross or one occludes the other and check whether object identities merge or video coherence visibly breaks.
Figures



read the original abstract
Controlling the motion of multiple objects in image-to-video (I2V) generation requires preserving object identities while enforcing adherence to distinct target trajectories. This becomes particularly challenging as the number of objects increases and their paths intersect or occlude one another. Existing approaches entangle multiple trajectories within a shared, dense conditioning signal, making object-level correspondence difficult to preserve in crowded scenes. We depart from this paradigm and enforce a strict, per object spatial constraint that isolates instances independently. Our method, TrajLoc, achieves this directly within the attention layers by substituting the cross-attention weights of each object token with a Gaussian heatmap centered on its target location at every frame. The same per object token interface carries trajectory and depth through a learned embedding and preserves identity by encoding first frame appearance in place of an object token. Evaluations across six datasets, featuring up to 20 simultaneously controlled objects and out of distribution real world scenes, demonstrate that our method consistently improves both visual fidelity and trajectory adherence. Applied to two architecturally distinct backbones (CogVideoX 5B and WaN 2.1 14B), our approach achieves average gains of +4.3 dB PSNR and a 51% reduction in trajectory end point error compared to the strongest baselines. Project page: https://sela-omer.github.io/traj-loc/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TrajLoc for multi-object motion control in image-to-video generation. It enforces per-object spatial constraints by substituting cross-attention weights of each object token with an independent Gaussian heatmap centered on the target location at every frame, while carrying trajectory and depth via a learned embedding and preserving identity through first-frame appearance encoding. The authors claim that this yields consistent gains in visual fidelity and trajectory adherence, with average improvements of +4.3 dB PSNR and 51% reduction in endpoint error versus strongest baselines when applied to CogVideoX 5B and WaN 2.1 14B across six datasets featuring up to 20 objects and out-of-distribution real-world scenes.
Significance. If the reported gains prove robust, the approach would provide a lightweight, backbone-agnostic mechanism for object isolation inside existing attention layers of large video diffusion models. The evaluation across two architecturally distinct backbones and on out-of-distribution scenes is a strength that supports broader applicability.
major comments (2)
- [Abstract] Abstract: The central claim concerns performance in crowded scenes where paths intersect or occlude, yet the reported aggregate metrics (+4.3 dB PSNR, 51% EPE reduction) provide no breakdown or separate results on the intersecting/occluding subset. This leaves the load-bearing assumption that independent Gaussian substitutions preserve coherence without identity leakage or artifacts untested by the presented evidence.
- [Method] Method description: The substitution of cross-attention weights with per-object Gaussians is presented as operating directly inside the model's attention layers, but no equations, pseudocode, or implementation details specify whether the replacement occurs before or after softmax, per attention head, or with cross-object normalization. This underspecification directly affects whether the joint attention computation can still model interactions when trajectories cross.
minor comments (2)
- The quantitative claims would be strengthened by reporting error bars, standard deviations, or per-dataset breakdowns rather than averages alone.
- Dataset statistics (number of sequences, resolution, trajectory generation procedure, and annotation protocol) are not described, which hinders assessment of the evaluation scope.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation breakdown and method specification. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim concerns performance in crowded scenes where paths intersect or occlude, yet the reported aggregate metrics (+4.3 dB PSNR, 51% EPE reduction) provide no breakdown or separate results on the intersecting/occluding subset. This leaves the load-bearing assumption that independent Gaussian substitutions preserve coherence without identity leakage or artifacts untested by the presented evidence.
Authors: We agree that the central claim focuses on crowded scenes with intersections and occlusions, and that aggregate metrics alone leave this aspect under-tested. The six datasets do contain such cases (up to 20 objects), but no subset analysis is currently reported. In the revised manuscript we will add a dedicated breakdown of PSNR and endpoint error on the intersecting/occluding subset to directly evaluate coherence preservation. revision: yes
-
Referee: [Method] Method description: The substitution of cross-attention weights with per-object Gaussians is presented as operating directly inside the model's attention layers, but no equations, pseudocode, or implementation details specify whether the replacement occurs before or after softmax, per attention head, or with cross-object normalization. This underspecification directly affects whether the joint attention computation can still model interactions when trajectories cross.
Authors: The current manuscript does not provide these implementation specifics, which is an oversight in the method description. We will revise the method section to include explicit equations and pseudocode clarifying the substitution timing (relative to softmax), per-head application, and normalization procedure. This will make the interaction modeling behavior reproducible and address the concern about cross-trajectory coherence. revision: yes
Circularity Check
No circularity: architectural substitution applied to external backbones
full rationale
The paper presents TrajLoc as a direct per-object substitution of cross-attention weights by Gaussian heatmaps inside unmodified diffusion backbones (CogVideoX 5B, WaN 2.1 14B). No equations, fitted parameters, or predictions are shown that reduce the reported PSNR/EPE gains to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central mechanism and empirical results on six datasets stand as an independent architectural change evaluated against external baselines.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned embedding for trajectory and depth
axioms (1)
- domain assumption Gaussian heatmap substitution isolates object instances and enforces spatial constraints without side effects on coherence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. InSIGGRAPH, 2023
2023
-
[3]
Motion-zero: Zero-shot moving object control framework for diffusion-based video generation
Changgu Chen, Junwei Shu, Gaoqi He, Changbo Wang, and Yang Li. Motion-zero: Zero-shot moving object control framework for diffusion-based video generation. InAAAI, 2025
2025
-
[4]
Wan-move: Motion-controllable video generation via latent trajectory guidance
Ruihang Chu, Yefei He, Zhekai Chen, Shiwei Zhang, Xiaogang Xu, Bin Xia, Dingdong Wang, Hongwei Yi, Xihui Liu, Hengshuang Zhao, Yu Liu, Yingya Zhang, and Yujiu Yang. Wan-move: Motion-controllable video generation via latent trajectory guidance. InNeurIPS, 2025
2025
-
[5]
Motchallenge: A benchmark for single-camera multiple target tracking.IJCV, 2021
Patrick Dendorfer, Aljoša Ošep, Anton Milan, Konrad Schindler, Daniel Cremers, Ian Reid, Stefan Roth, and Laura Leal-Taixé. Motchallenge: A benchmark for single-camera multiple target tracking.IJCV, 2021
2021
-
[6]
Tenenbaum, Dale Schuurmans, and Pieter Abbeel
Yilun Du, Mengjiao Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. InNeurIPS, 2023
2023
-
[7]
Georgios D. Evangelidis and Emmanouil Z. Psarakis. Parametric image alignment using enhanced correlation coefficient maximization.IEEE Trans. Pattern Anal. Mach. Intell., 30(10): 1858–1865, 2008. doi: 10.1109/TPAMI.2008.113
-
[8]
Motsynth: How can synthetic data help pedestrian detection and tracking? InICCV, 2021
Matteo Fabbri, Guillem Brasó, Gianluca Maugeri, Orcun Cetintas, Riccardo Gasparini, Aljoša Ošep, Simone Calderara, Laura Leal-Taixé, and Rita Cucchiara. Motsynth: How can synthetic data help pedestrian detection and tracking? InICCV, 2021
2021
-
[9]
Two-frame motion estimation based on polynomial expansion
Gunnar Farnebäck. Two-frame motion estimation based on polynomial expansion. InImage Analysis (SCIA 2003), volume 2749 ofLecture Notes in Computer Science, pages 363–370. Springer, 2003. doi: 10.1007/3-540-45103-X_50
-
[10]
Motion prompting: Controlling video generation with motion trajectories
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Ta- tiana Lopez-Guevara, Carl Doersch, Yusuf Aytar, Michael Rubinstein, et al. Motion prompting: Controlling video generation with motion trajectories. InCVPR, 2025
2025
-
[11]
Gem: A generalizable ego-vision multimodal world model for fine-grained ego-motion, object dynamics, and scene composition control
Mariam Hassan, Sebastian Stapf, Ahmad Rahimi, Pedro Rezende, Yasaman Haghighi, David Brüggemann, Isinsu Katircioglu, Lin Zhang, Xiaoran Chen, Suman Saha, et al. Gem: A generalizable ego-vision multimodal world model for fine-grained ego-motion, object dynamics, and scene composition control. InCVPR, pages 22404–22415, 2025
2025
-
[12]
Prompt-to-prompt image editing with cross attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. InICLR, 2023
2023
-
[13]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. GAIA-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InICLR, 2022
2022
-
[15]
Peekaboo: Interactive video generation via masked-diffusion
Yash Jain, Anshul Nasery, Vibhav Vineet, and Harkirat Behl. Peekaboo: Interactive video generation via masked-diffusion. InCVPR, 2024
2024
-
[16]
Posetraj: Pose-aware trajectory control in video diffusion
Longbin Ji, Lei Zhong, Pengfei Wei, and Changjian Li. Posetraj: Pose-aware trajectory control in video diffusion. InCVPR, 2025. 10
2025
-
[17]
Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance
Quanhao Li, Zhen Xing, Rui Wang, Hui Zhang, Qi Dai, and Zuxuan Wu. Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance. InICCV, 2025
2025
-
[18]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InCVPR, 2023
2023
-
[19]
Dreamitate: Real-world visuomotor policy learning via video generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, and Carl V ondrick. Dreamitate: Real-world visuomotor policy learning via video generation. InConference on Robot Learning (CoRL), 2024
2024
-
[20]
Zuhao Liu, Aleksandar Yanev, Ahmad Mahmood, Ivan Nikolov, Saman Motamed, Wei-Shi Zheng, Xi Wang, Lei Sun, Luc Van Gool, and Danda Pani Paudel. Intragen: Trajectory- controlled video generation for object interactions.arXiv preprint arXiv:2411.16804, 2024
-
[21]
Trailblazer: Trajectory control for diffusion-based video generation
Wan-Duo Kurt Ma, John P Lewis, and W Bastiaan Kleijn. Trailblazer: Trajectory control for diffusion-based video generation. InSIGGRAPH Asia, 2024
2024
-
[22]
Sg-i2v: Self-guided trajectory control in image-to-video generation
Koichi Namekata, Sherwin Bahmani, Ziyi Wu, Yash Kant, Igor Gilitschenski, and David B Lindell. Sg-i2v: Self-guided trajectory control in image-to-video generation. InICLR, 2025
2025
-
[23]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv:1704.00675, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Freetraj: Tuning-free trajectory control in video diffusion models, 2024
Haonan Qiu, Zhaoxi Chen, Zhouxia Wang, Yingqing He, Menghan Xia, and Ziwei Liu. Freetraj: Tuning-free trajectory control in video diffusion models, 2024. URL https://arxiv.org/ abs/2406.16863
-
[25]
Towards accurate generative models of video: A new metric & challenges,
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges,
-
[26]
URLhttps://arxiv.org/abs/1812.01717
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Dragentity: Trajectory guided video generation using entity and positional relationships
Zhang Wan, Sheng Tang, Jiawei Wei, Ruize Zhang, and Juan Cao. Dragentity: Trajectory guided video generation using entity and positional relationships. InACM MM, 2024
2024
-
[29]
Angtian Wang, Haibin Huang, Jacob Zhiyuan Fang, Yiding Yang, and Chongyang Ma. Ati: Any trajectory instruction for controllable video generation.arXiv preprint arXiv:2505.22944, 2025
-
[30]
Levitor: 3d trajectory oriented image-to-video synthesis
Hanlin Wang, Hao Ouyang, Qiuyu Wang, Wen Wang, Ka Leong Cheng, Qifeng Chen, Yujun Shen, and Limin Wang. Levitor: 3d trajectory oriented image-to-video synthesis. InCVPR, 2025
2025
-
[31]
Boximator: Generating rich and controllable motions for video synthesis
Jiawei Wang, Yuchen Zhang, Jiaxin Zou, Yan Zeng, Guoqiang Wei, Liping Yuan, and Hang Li. Boximator: Generating rich and controllable motions for video synthesis. InICML, 2024
2024
-
[32]
Cinemaster: A 3d-aware and controllable framework for cinematic text-to-video generation
Qinghe Wang, Yawen Luo, Xiaoyu Shi, Xu Jia, Huchuan Lu, Tianfan Xue, Xintao Wang, Pengfei Wan, Di Zhang, and Kun Gai. Cinemaster: A 3d-aware and controllable framework for cinematic text-to-video generation. InSIGGRAPH, 2025
2025
-
[33]
Drive- Dreamer: Towards real-world-driven world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drive- Dreamer: Towards real-world-driven world models for autonomous driving. InECCV, 2024
2024
-
[34]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InSIGGRAPH, 2024
2024
-
[35]
Draganything: Motion control for anything using entity representation
Weijia Wu, Zhuang Li, Yuchao Gu, Rui Zhao, Yefei He, David Junhao Zhang, Mike Zheng Shou, Yan Li, Tingting Gao, and Di Zhang. Draganything: Motion control for anything using entity representation. InECCV, 2024. 11
2024
-
[36]
Motioncanvas: Cinematic shot design with controllable image- to-video generation
Jinbo Xing, Long Mai, Cusuh Ham, Jiahui Huang, Aniruddha Mahapatra, Chi-Wing Fu, Tien-Tsin Wong, and Feng Liu. Motioncanvas: Cinematic shot design with controllable image- to-video generation. InSIGGRAPH, 2025
2025
-
[37]
Depth anything v2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2. InNeurIPS, 2024
2024
-
[38]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer. InICLR, 2025
2025
-
[39]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InICCV, 2023
2023
-
[40]
The unreason- able effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric. InCVPR, 2018
2018
-
[41]
Tora: Trajectory-oriented diffusion transformer for video generation
Zhenghao Zhang, Junchao Liao, Menghao Li, Zuozhuo Dai, Bingxue Qiu, Siyu Zhu, Long Qin, and Weizhi Wang. Tora: Trajectory-oriented diffusion transformer for video generation. In CVPR, 2025
2025
-
[42]
Zhiyuan Zhang, Can Wang, Dongdong Chen, and Jing Liao. Flextraj: Image-to-video generation with flexible point trajectory control.arXiv preprint arXiv:2510.08527, 2025
-
[43]
Motionpro: A precise motion controller for image-to-video generation
Zhongwei Zhang, Fuchen Long, Zhaofan Qiu, Yingwei Pan, Wu Liu, Ting Yao, and Tao Mei. Motionpro: A precise motion controller for image-to-video generation. InCVPR, 2025
2025
-
[44]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404, 2024. 12 Appendix Contents A Additional Qualitative Comparisons 13 B Failure Cases 16 B.1 GTA-V Training-Distribution Leakage on Out-of-Distribu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.