Uncertainty Quantification for Flow-Based Vision-Language-Action Models
Pith reviewed 2026-06-27 00:41 UTC · model grok-4.3
The pith
A small ensemble of flow models quantifies epistemic uncertainty in vision-language-action systems by measuring velocity-field disagreement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
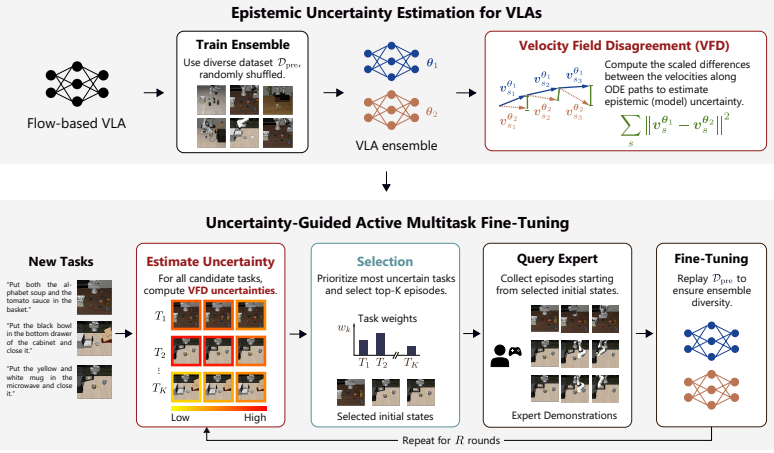
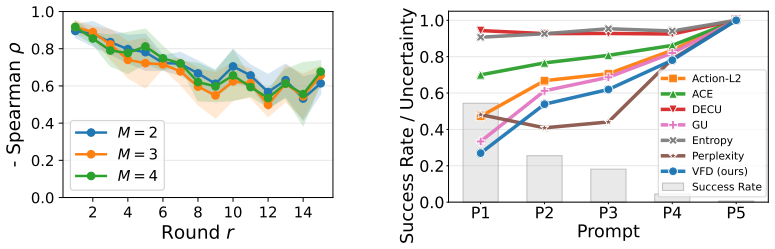
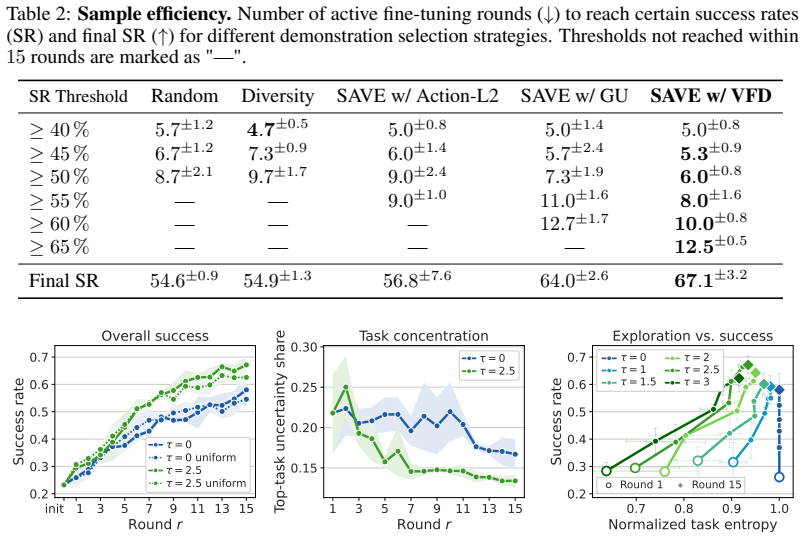
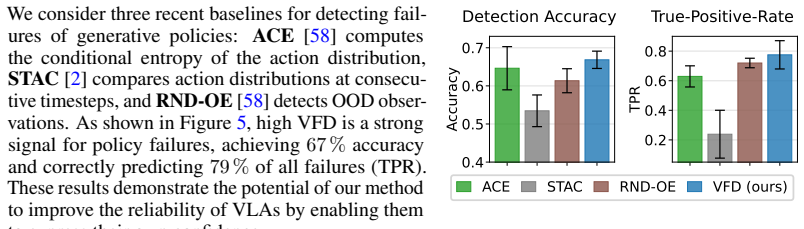
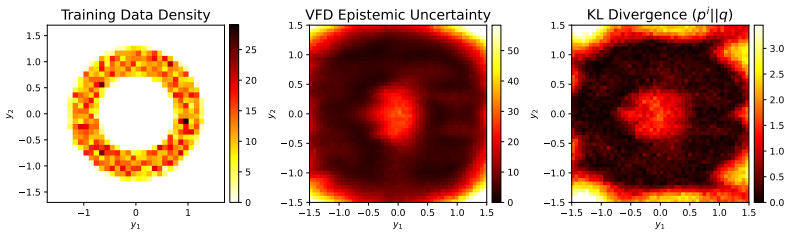
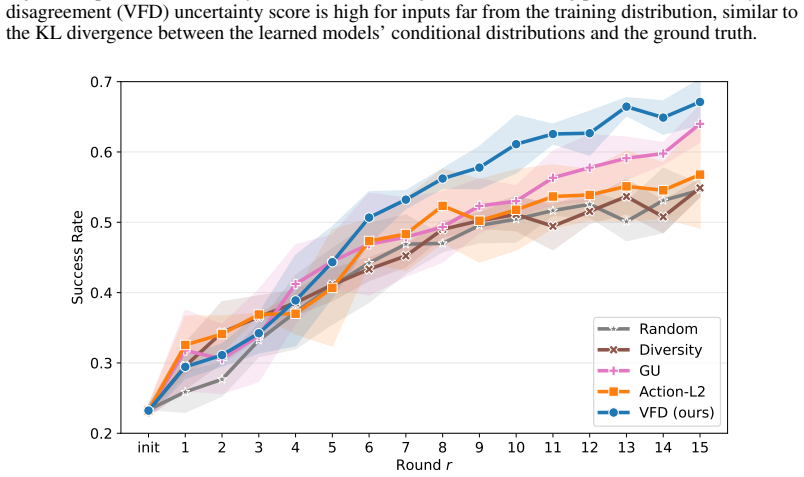
The authors derive velocity-field disagreement across a small ensemble of flow-matching models as an efficient estimator of epistemic uncertainty in the action head. On the LIBERO benchmark this estimator produces better-calibrated scores that predict downstream performance, detects failures effectively, and enables the SAVE active fine-tuning framework that requires at least 22 percent fewer expert demonstrations than baseline acquisition strategies.
What carries the argument
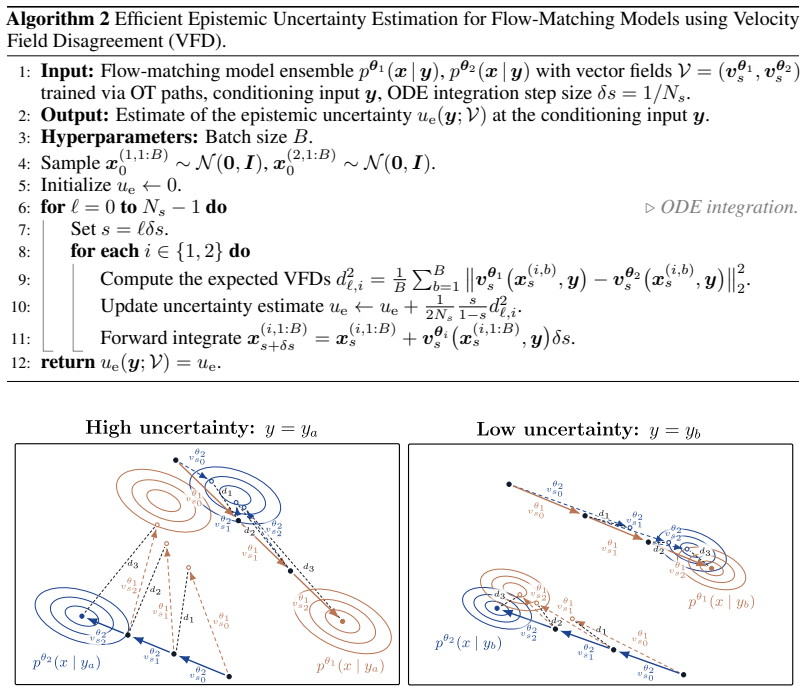
Velocity-field disagreement (VFD) across a small ensemble of flow models, which isolates epistemic uncertainty by measuring differences in predicted action velocities.
If this is right
- Models gain the ability to flag unreliable actions during deployment in non-stationary environments.
- Uncertainty-guided acquisition reduces the number of expert demonstrations needed to adapt to new tasks.
- VFD scores are predictive of downstream task performance.
- The method applies to existing flow-based VLA architectures without full retraining.
Where Pith is reading between the lines
- Disagreement measures of this type could extend to diffusion-based or other generative action heads.
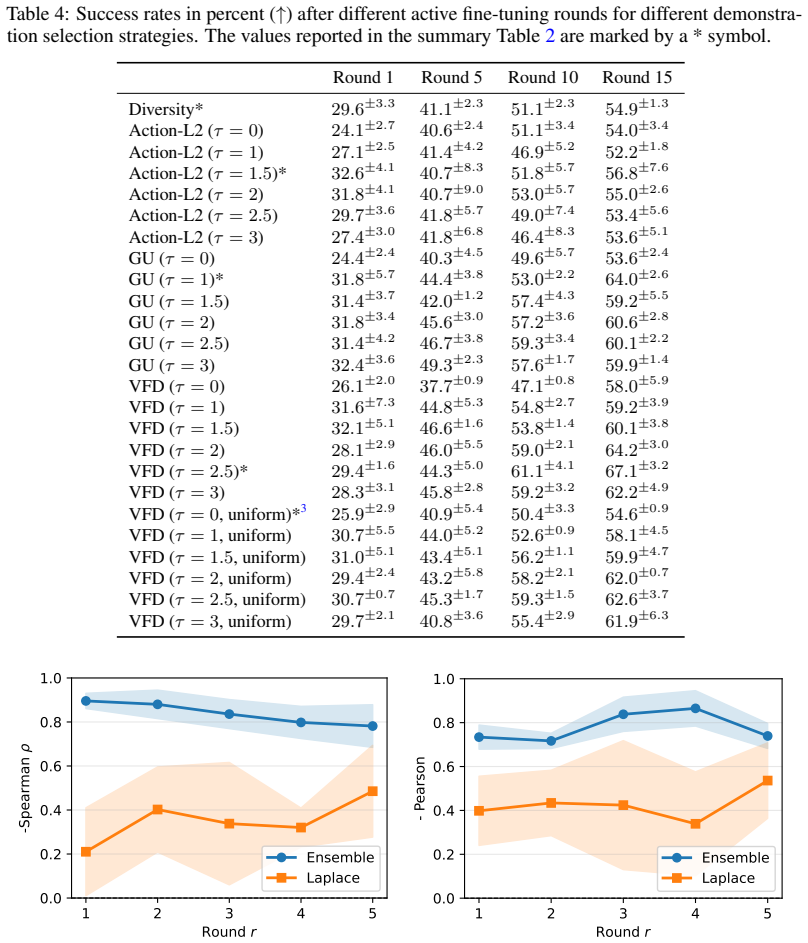
- In multi-agent robotic teams the same signal might coordinate when one agent should defer to another.
- Further reduction of ensemble size could enable onboard uncertainty estimation on resource-limited platforms.
Load-bearing premise
Disagreement among velocity fields from a small ensemble reliably isolates epistemic uncertainty rather than aleatoric noise or model-specific artifacts.
What would settle it
An experiment in which VFD scores show no correlation with actual failure rates on held-out tasks, or in which uncertainty-guided sample selection requires as many or more demonstrations as random selection.
Figures
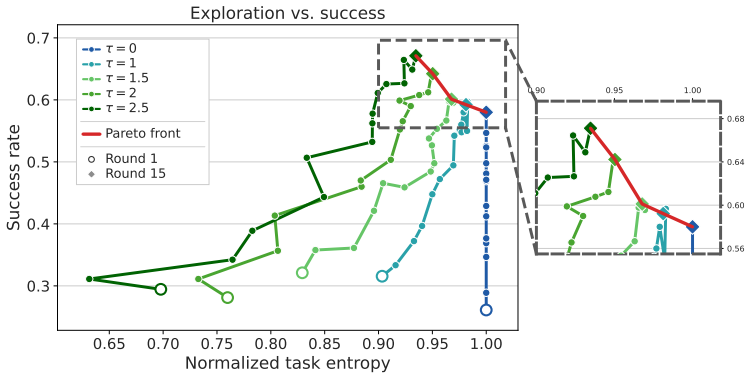
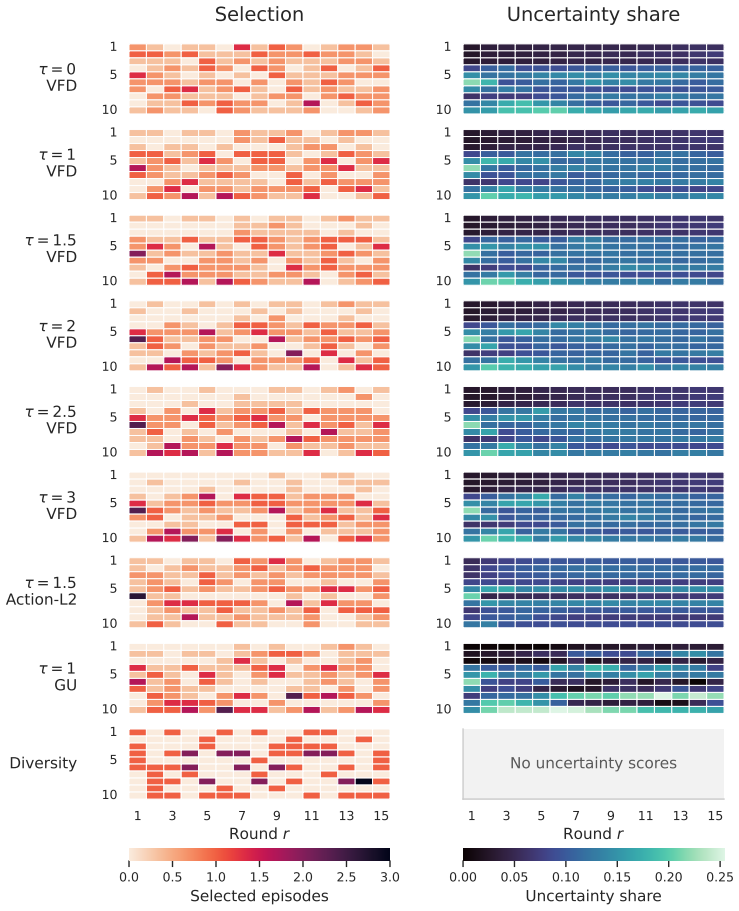
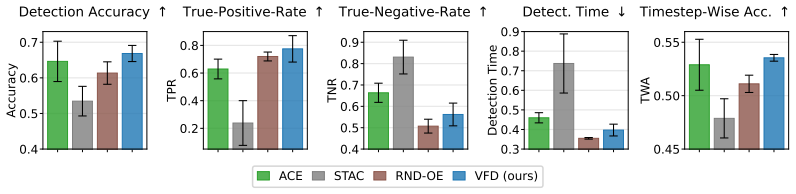
read the original abstract
Vision-language-action models (VLAs) combine vision-language backbones with expressive generative action heads trained via flow matching on large-scale robotic datasets. Despite their strong empirical performance in robotic manipulation, VLAs lack mechanisms to quantify confidence in their predictions and to detect when their actions may be unreliable. This presents a critical limitation for real-world deployment in non-stationary environments, where models inevitably encounter scenarios outside their pretraining distribution and may fail without warning. To address this, we derive an efficient method for quantifying epistemic uncertainty in flow-matching models by leveraging velocity-field disagreement (VFD) across a small ensemble. We successfully use this uncertainty estimate for failure detection during deployment and active fine-tuning of flow-based VLAs. To this end, we propose SAVE, a framework for uncertainty-guided active multitask fine-tuning that reduces the number of costly expert demonstrations required to adapt VLAs to new tasks. Through extensive experiments on the LIBERO benchmark, we demonstrate that VFD yields better-calibrated uncertainty estimates predictive of downstream performance, that VFD achieves strong performance in detecting failures, and that uncertainty-guided data acquisition with SAVE requires at least 22% fewer samples than baselines. In summary, our work shows that quantifying epistemic uncertainty in flow-based VLAs improves both failure awareness and adaptation. Project website: tum-lsy.github.io/uq_vla/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to derive an efficient epistemic uncertainty quantification method for flow-matching VLAs via velocity-field disagreement (VFD) across a small ensemble of velocity fields. It introduces the SAVE framework for uncertainty-guided active multitask fine-tuning and reports on LIBERO that VFD yields better-calibrated estimates predictive of performance, achieves strong failure detection, and enables SAVE to require at least 22% fewer expert demonstrations than baselines.
Significance. If VFD reliably isolates epistemic uncertainty from aleatoric or optimization artifacts in flow-matching models, the approach would meaningfully advance safe deployment and efficient adaptation of VLAs. The reported sample-efficiency gain and failure-detection results on LIBERO would be practically relevant for robotics, provided the core separation holds under controlled tests.
major comments (3)
- [Abstract, §3] Abstract and §3: The central claim that VFD isolates epistemic uncertainty (rather than optimization stochasticity or aleatoric action noise) is load-bearing for both the failure-detection AUC and the 22% SAVE gain, yet no experiment is described that holds aleatoric variance fixed while injecting controlled OOD support gaps (e.g., via synthetic action noise or distribution shift with matched variance).
- [§4.2, Table 2] §4.2 and Table 2: The reported 22% reduction in required samples for SAVE is presented without statistical significance tests, variance across random seeds, or explicit confirmation that baseline implementations match the original papers; this directly affects whether the cross-method comparison supports the efficiency claim.
- [§3.1, Eq. (3)–(5)] §3.1, Eq. (3)–(5): The VFD quantity is defined as disagreement among velocity fields v_θ_i; because each v_θ is a deterministic function of its parameters, the derivation does not include a term or proof separating parameter uncertainty from sensitivity to the stochasticity of the flow-matching training objective or to inherent action multimodality.
minor comments (2)
- [Abstract] The abstract states 'at least 22% fewer samples' without specifying the exact baseline methods or the precise metric (e.g., demonstrations until a performance threshold); this should be clarified for reproducibility.
- [§4] Ensemble size is listed as a free parameter in the axiom ledger but no sensitivity analysis or recommended default is provided in the experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of validating the epistemic nature of VFD and strengthening the empirical claims. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3: The central claim that VFD isolates epistemic uncertainty (rather than optimization stochasticity or aleatoric action noise) is load-bearing for both the failure-detection AUC and the 22% SAVE gain, yet no experiment is described that holds aleatoric variance fixed while injecting controlled OOD support gaps (e.g., via synthetic action noise or distribution shift with matched variance).
Authors: We agree that the current LIBERO task-shift experiments, while showing VFD's predictive power for performance drops, do not include the precise controlled isolation suggested. In the revision we will add a new experiment subsection that fixes aleatoric variance (via matched synthetic action noise) while systematically varying support gaps, to more directly test whether VFD isolates epistemic uncertainty. revision: yes
-
Referee: [§4.2, Table 2] §4.2 and Table 2: The reported 22% reduction in required samples for SAVE is presented without statistical significance tests, variance across random seeds, or explicit confirmation that baseline implementations match the original papers; this directly affects whether the cross-method comparison supports the efficiency claim.
Authors: We acknowledge that the efficiency claim would be more robust with these details. We will revise §4.2 and Table 2 to report means and standard deviations over at least five random seeds, include statistical significance tests (e.g., paired t-tests), and add an appendix section confirming that all baselines were reimplemented following the original papers' protocols and hyperparameters. revision: yes
-
Referee: [§3.1, Eq. (3)–(5)] §3.1, Eq. (3)–(5): The VFD quantity is defined as disagreement among velocity fields v_θ_i; because each v_θ is a deterministic function of its parameters, the derivation does not include a term or proof separating parameter uncertainty from sensitivity to the stochasticity of the flow-matching training objective or to inherent action multimodality.
Authors: VFD follows the standard ensemble approach where disagreement across differently initialized models approximates epistemic uncertainty arising from parameter variability. The shared training procedure across ensemble members is intended to keep optimization stochasticity comparable. We will expand the discussion around Eq. (3)–(5) to explicitly state these assumptions and limitations regarding training stochasticity and action multimodality, without claiming a formal separation proof. revision: partial
Circularity Check
No circularity: VFD is direct ensemble disagreement, not a fitted or self-defined quantity
full rationale
The paper derives epistemic uncertainty via velocity-field disagreement (VFD) computed directly from an ensemble of flow-matching velocity fields v_θ. This is a standard, non-circular construction: disagreement is measured on the outputs of independently trained models without any parameter being fitted to the target uncertainty or downstream metric. SAVE then uses the resulting scalar as a selection criterion for active fine-tuning; the selection rule does not reduce to the input demonstrations by definition. No self-citation load-bearing step, uniqueness theorem, or ansatz smuggling is present in the abstract or described derivation chain. The method remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- ensemble size
- uncertainty threshold for failure detection / data selection
axioms (2)
- domain assumption Ensemble disagreement in velocity fields captures epistemic rather than aleatoric uncertainty for flow-matching policies.
- domain assumption LIBERO task splits simulate realistic non-stationary deployment shifts.
invented entities (2)
-
VFD (velocity-field disagreement)
no independent evidence
-
SAVE framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abdar et al
M. Abdar et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges.Information Fusion, 76:243–297, 2021
2021
-
[2]
C. Agia, R. Sinha, J. Yang, Z. Cao, R. Antonova, M. Pavone, and J. Bohg. Unpacking failure modes of generative policies: Runtime monitoring of consistency and progress. InConference on Robot Learning (CoRL), 2025
2025
-
[3]
AgiBot World Colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems
AgiBot-World et al. AgiBot World Colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. InInternational Conference on Intelligent Robots and Systems (IROS), 2025
2025
-
[4]
A. N. Angelopoulos and S. Bates. Conformal prediction: A gentle introduction.Foundations and Trends in Machine Learning, 16(4):494–591, 2023
2023
-
[5]
J. T. Ash, C. Zhang, A. Krishnamurthy, J. Langford, and A. Agarwal. Deep batch active learning by diverse, uncertain gradient lower bounds. InInternational Conference on Learning Representations (ICLR), 2020
2020
-
[6]
Awais, M
M. Awais, M. Naseer, S. Khan, R. M. Anwer, H. Cholakkal, M. Shah, M.-H. Yang, and F. S. Khan. Foundation models defining a new era in vision: a survey and outlook.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(4):2245–2264, 2025
2025
-
[7]
M. S. Ayhan and P. Berens. Test-time data augmentation for estimation of heteroscedastic aleatoric uncertainty in deep neural networks. InMedical Imaging with Deep Learning, 2018
2018
-
[8]
Bagatella, J
M. Bagatella, J. Hübotter, G. Martius, and A. Krause. Active fine-tuning of multi-task policies. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[9]
Berry, A
L. Berry, A. Brando, and D. Meger. Shedding light on large generative networks: Estimating epistemic uncertainty in diffusion models. InConference on Uncertainty in Artificial Intelligence (UAI), 2024
2024
-
[10]
Black et al
K. Black et al. π0.5: a vision-language-action model with open-world generalization. In Conference on Robot Learning (CoRL), 2025
2025
-
[11]
Cadene, S
R. Cadene, S. Alibert, F. Capuano, M. Aractingi, A. Zouitine, P. Kooijmans, J. Choghari, M. Russi, C. Pascal, S. Palma, et al. LeRobot: An open-source library for end-to-end robot learning. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[12]
Chaloner and I
K. Chaloner and I. Verdinelli. Bayesian experimental design: A review.Statistical science, 10: 273–304, 1995
1995
-
[13]
M. Chan, M. Molina, and C. Metzler. Estimating epistemic and aleatoric uncertainty with a single model.Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[14]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.Robotics: Science and Systems (RSS), 2023
2023
-
[15]
Y . Cui, D. Isele, S. Niekum, and K. Fujimura. Uncertainty-aware data aggregation for deep imitation learning. InIEEE International Conference on Robotics and Automation (ICRA), 2019. 11
2019
-
[16]
Daxberger, A
E. Daxberger, A. Kristiadi, A. Immer, R. Eschenhagen, M. Bauer, and P. Hennig. Laplace redux - effortless Bayesian deep learning.Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[17]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InNorth American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2019
2019
-
[18]
Diquigiovanni, M
J. Diquigiovanni, M. Fontana, S. Vantini, et al. The importance of being a band: Finite-sample exact distribution-free prediction sets for functional data.STATISTICA SINICA, 1:1–41, 2024
2024
-
[19]
Dohare, J
S. Dohare, J. F. Hernandez-Garcia, Q. Lan, P. Rahman, A. R. Mahmood, and R. S. Sutton. Loss of plasticity in deep continual learning.Nature, 632:768–774, 2024
2024
-
[20]
Dosovitskiy et al
A. Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[21]
B. Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106:1602–1614, 2011
2011
-
[22]
Esser, S
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In International Conference on Machine Learning (ICML), 2024
2024
-
[23]
Fadeeva et al
E. Fadeeva et al. Fact-checking the output of large language models via token-level uncertainty quantification. InFindings of the Association for Computational Linguistics: ACL 2024, pages 9367–9385, 2024
2024
-
[24]
Franchi, N
G. Franchi, N. Belkhir, D. N. Trong, G. Xia, and A. Pilzer. Towards understanding and quantifying uncertainty for text-to-image generation. InConference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[25]
Gal and Z
Y . Gal and Z. Ghahramani. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. InInternational Conference on Machine Learning (ICML), 2016
2016
-
[26]
Y . Gal, R. Islam, and Z. Ghahramani. Deep Bayesian active learning with image data. In International Conference on Machine Learning (ICML), 2017
2017
-
[27]
Q. Gu, Y . Ju, S. Sun, I. Gilitschenski, H. Nishimura, M. Itkina, and F. Shkurti. SAFE: Multi- task failure detection for vision-language-action models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[28]
Z. He, Y . Cao, and M. Ciocarlie. Uncertainty comes for free: Human-in-the-loop policies with diffusion models.arXiv preprint arXiv:2503.01876, 2025
arXiv 2025
-
[29]
Hejna, S
J. Hejna, S. Mirchandani, A. Balakrishna, A. Xie, A. Wahid, J. Tompson, P. Sanketi, D. Shah, C. Devin, and D. Sadigh. Robot data curation with mutual information estimators.Robotics: Science and Systems (RSS), 2025
2025
-
[30]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS), 33:6840–6851, 2020
2020
-
[31]
Holzmüller, V
D. Holzmüller, V . Zaverkin, J. Kästner, and I. Steinwart. A framework and benchmark for deep batch active learning for regression.Journal of Machine Learning Research (JMLR), 24(164): 1–81, 2023
2023
-
[32]
Hüllermeier and W
E. Hüllermeier and W. Waegeman. Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods.Machine Learning, 110:457–506, 2021
2021
-
[33]
Jazbec, E
M. Jazbec, E. Wong-Toi, G. Xia, D. Zhang, E. Nalisnick, and S. Mandt. Generative uncertainty in diffusion models. InConference on Uncertainty in Artificial Intelligence (UAI), 2025
2025
-
[34]
L. Ju, M. Nautiyal, A. Hellander, E. Vats, and P. Singh. Epistemic uncertainty quantification for pre-trained VLMs via Riemannian flow matching.arXiv preprint arXiv:2601.21662, 2026. 12
Pith/arXiv arXiv 2026
-
[35]
Judah, A
K. Judah, A. Fern, and T. G. Dietterich. Active imitation learning via reduction to IID active learning. InConference on Uncertainty in Artificial Intelligence (UAI), 2012
2012
-
[36]
Karczewski, M
R. Karczewski, M. Heinonen, and V . Garg. Diffusion models as cartoonists: The curious case of high density regions. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[37]
U. B. Karli, T. Kurumisawa, and T. Fitzgerald. Ask before you act: Token-level uncertainty for intervention in vision-language-action models. InSecond Workshop on Out-of-Distribution Generalization in Robotics at RSS, 2025
2025
-
[38]
Khazatsky et al
A. Khazatsky et al. DROID: A large-scale in-the-wild robot manipulation dataset. InRobotics: Science and Systems, 2024
2024
-
[39]
M. J. Kim et al. OpenVLA: An open-source vision-language-action model. InConference on Robot Learning (CoRL), 2024
2024
-
[40]
Kirsch, J
A. Kirsch, J. van Amersfoort, and Y . Gal. BatchBALD: Efficient and diverse batch acquisition for deep Bayesian active learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[41]
Lakshminarayanan, A
B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and scalable predictive uncertainty es- timation using deep ensembles.Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[42]
S.-W. Lee, X. Kang, and Y .-L. Kuo. Diff-DAgger: Uncertainty estimation with diffusion policy for robotic manipulation. InIEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[43]
Q. Li, B. Yin, W. Huang, R. Liu, B. Zou, R. Yu, J. Ye, W. Yu, and X. Wang. Vision- language-action safety: Threats, challenges, evaluations, and mechanisms.arXiv preprint arXiv:2604.23775, 2026
Pith/arXiv arXiv 2026
-
[44]
Ling et al
C. Ling et al. Uncertainty quantification for in-context learning of large language models. In North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2024
2024
-
[45]
Lipman, R
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[46]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[47]
Loquercio, M
A. Loquercio, M. Segu, and D. Scaramuzza. A general framework for uncertainty estimation in deep learning.IEEE Robotics and Automation Letters, 2020
2020
-
[48]
H. Ma, J. Chen, J. T. Zhou, G. Wang, and C. Zhang. Estimating LLM uncertainty with evidence. arXiv preprint arXiv:2502.00290, 2025
arXiv 2025
-
[49]
Malinin and M
A. Malinin and M. Gales. Uncertainty estimation in autoregressive structured prediction. In International Conference on Learning Representations (ICLR), 2021
2021
-
[50]
Z. Mei, T. Yin, M. Baker, O. Shorinwa, and A. Majumdar. World models that know when they don’t know: Controllable video generation with calibrated uncertainty.arXiv preprint arXiv:2512.05927, 2025
arXiv 2025
-
[51]
Nalisnick, A
E. Nalisnick, A. Matsukawa, Y . W. Teh, D. Gorur, and B. Lakshminarayanan. Do deep generative models know what they don’t know? InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[52]
NVIDIA et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 13
Pith/arXiv arXiv 2025
-
[53]
O’Neill et al
A. O’Neill et al. Open X-embodiment: Robotic learning datasets and RT-X models: Open X-embodiment collaboration. InIEEE International Conference on Robotics and Automation (ICRA), 2024
2024
-
[54]
π0: A vision-language-action flow model for general robot control
Physical Intelligence et al. π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[55]
A. Z. Ren et al. Robots that ask for help: Uncertainty alignment for large language model planners. InConference on Robot Learning (CoRL), 2023
2023
-
[56]
J. Ren, J. Luo, Y . Zhao, K. Krishna, M. Saleh, B. Lakshminarayanan, and P. J. Liu. Out-of- distribution detection and selective generation for conditional language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[57]
Reuss, H
M. Reuss, H. Zhou, M. Rühle, Ö. E. Ya˘gmurlu, F. Otto, and R. Lioutikov. FLOWER: Democra- tizing generalist robot policies with efficient vision-language-flow policies. InConference on Robot Learning (CoRL), 2025
2025
-
[58]
Römer, A
R. Römer, A. Kobras, L. Worbis, and A. P. Schoellig. Failure prediction at runtime for generative robot policies.Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[59]
Römer, J
R. Römer, J. Balletshofer, J. Thumm, M. Pavone, A. P. Schoellig, and M. Althoff. From demonstrations to safe deployment: Path-consistent safety filtering for diffusion policies. In IEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[60]
R. Römer, Y . Zhang, and A. P. Schoellig. CLARE: Continual learning for vision-language-action models via autonomous adapter routing and expansion.arXiv preprint arXiv:2601.09512, 2026
Pith/arXiv arXiv 2026
-
[61]
Sener and S
O. Sener and S. Savarese. Active learning for convolutional neural networks: A core-set approach. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[62]
B. Settles. Active learning literature survey. Technical report, University of Wisconsin–Madison, 2009
2009
-
[63]
Shorinwa, Z
O. Shorinwa, Z. Mei, J. Lidard, A. Z. Ren, and A. Majumdar. A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions.ACM Computing Surveys, 58:1–38, 2025
2025
-
[64]
M. Shukor et al. SmolVLA: A vision-language-action model for affordable and efficient robotics. arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[65]
C. Xu, T. Khuong Nguyen, E. Dixon, C. Rodriguez, P. Miller, R. Lee, P. Shah, R. Ambrus, H. Nishimura, and M. Itkina. Can we detect failures without failure data? Uncertainty-aware runtime failure detection for imitation learning policies. InRobotics: Science and Systems (RSS), 2025
2025
-
[66]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 11975–11986, 2023
2023
-
[67]
Zitkovich et al
B. Zitkovich et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), 2023. 14 Appendix Table of Contents A Theoretical Results 16 A.1 Flow Matching Fundamentals . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 A.2 Proof of Theorem 4.1 . . . . . . . . . . . . . . . . . . . . . . ....
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.