REVIEW 3 major objections 2 minor 1 cited by
Multimodal LLMs show uneven resistance to cognitive biases in Chinese short-video health misinformation, with Gemini-2.5-Pro scoring 71.5 and o3 scoring 35.2 on a belief metric.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-21 15:07 UTC pith:I4QXRJI5
load-bearing objection The paper adds a new annotated set of 200 Chinese health videos and tests MLLMs on visual plus social misinformation cues, but the belief scoring and annotation checks stay underspecified. the 3 major comments →
Probing Multimodal Large Language Models on Cognitive Biases in Chinese Short-Video Misinformation
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
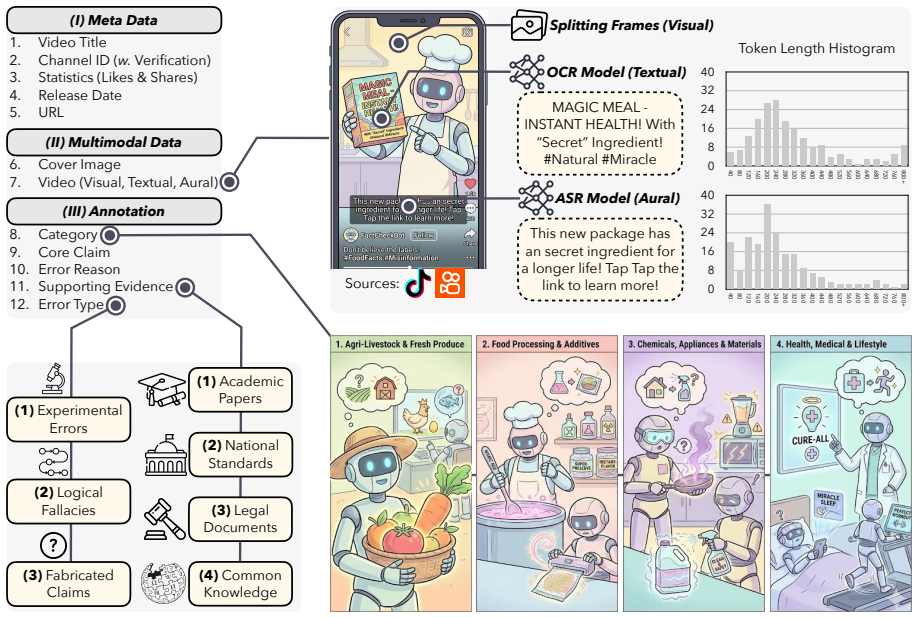
A dataset of 200 Chinese short videos spanning four health domains supplies fine-grained annotations for three deceptive patterns—experimental errors, logical fallacies, and fabricated claims—each checked against national standards and academic sources. When eight frontier multimodal LLMs are tested in five modality settings, Gemini-2.5-Pro records the highest belief score of 71.5 out of 100 while o3 records the lowest at 35.2, and the models prove vulnerable to social cues such as authoritative channel IDs that trigger false beliefs.
What carries the argument
The manually annotated dataset of 200 short videos with labels for deceptive patterns, together with a belief score that quantifies model resistance across modality settings.
Load-bearing premise
The manually annotated dataset of 200 short videos supplies accurate fine-grained labels for deceptive patterns verified by national standards and literature, and the belief score accurately reflects each model's susceptibility to cognitive biases.
What would settle it
Running the identical eight models on a fresh collection of 200 short videos that preserve the same distribution of deceptive patterns and social cues and obtaining a reversed model ranking or loss of susceptibility to channel IDs.
If this is right
- Gemini-2.5-Pro maintains higher resistance than other models when given full video input.
- Authoritative channel IDs reliably increase false belief rates across tested models.
- Performance varies with the modality setting, from text-only to complete video.
- The three deceptive patterns produce measurable differences in model belief scores.
- The framework supplies a repeatable benchmark for tracking progress on video misinformation.
Where Pith is reading between the lines
- Models trained on longer-form content may need targeted fine-tuning on short, fast-paced video formats to reduce these biases.
- Platforms that rely on MLLMs for moderation would still need separate checks for channel authority signals.
- The same evaluation could be repeated on non-health topics to test whether bias patterns generalize.
- Human viewers exposed to the same videos may exhibit parallel vulnerabilities, offering a comparison point for model behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a manually annotated dataset of 200 Chinese short videos across four health domains with fine-grained labels for three deceptive patterns (experimental errors, logical fallacies, fabricated claims) verified against national standards and literature. It evaluates eight frontier MLLMs across five modality settings using a belief score to quantify susceptibility to cognitive biases in misinformation, reporting Gemini-2.5-Pro at 71.5/100 (highest) and o3 at 35.2 (lowest) in the multimodal setting, while also analyzing social cues such as authoritative channel IDs that induce false beliefs.
Significance. If the measurement pipeline is validated, the work would offer timely empirical evidence on MLLM vulnerabilities to visually and socially entangled misinformation in short-video platforms, with direct relevance to public health communication and AI safety in non-English contexts.
major comments (3)
- [Abstract and Evaluation Framework] Abstract and §4 (Evaluation): The headline model rankings rest on the belief score (e.g., 71.5 vs 35.2), yet the manuscript supplies no explicit definition, formula, or mapping from raw model outputs to the 0-100 scale, nor any inter-annotator agreement or statistical significance for the 200-video results; this directly undermines verification of the susceptibility claims.
- [Dataset Construction] §3 (Dataset): The claim that annotations are 'fine-grained' and 'verified by national standards' is load-bearing for all downstream results, but no annotation protocol, annotator count, agreement metric, or validation procedure is described, leaving open the possibility that label noise could reverse the reported ordering between models.
- [Social Cue Investigation] §5 (Social Cue Analysis): The finding that models are susceptible to biases like authoritative channel IDs inherits the same unverified belief-score pipeline; without details on how social cues are isolated or scored, the causal attribution to specific cues cannot be assessed.
minor comments (2)
- [Experimental Setup] Clarify the precise definitions of the five modality settings and how prompts differ across them.
- [Results] Add a table summarizing per-model, per-modality belief scores with standard deviations or confidence intervals.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and have revised the manuscript to incorporate additional methodological details where the comments correctly identify gaps in the current version.
read point-by-point responses
-
Referee: [Abstract and Evaluation Framework] Abstract and §4 (Evaluation): The headline model rankings rest on the belief score (e.g., 71.5 vs 35.2), yet the manuscript supplies no explicit definition, formula, or mapping from raw model outputs to the 0-100 scale, nor any inter-annotator agreement or statistical significance for the 200-video results; this directly undermines verification of the susceptibility claims.
Authors: We agree that an explicit definition and formula for the belief score are required for reproducibility and verification. In the revised manuscript we have expanded §4 to include the precise definition of the belief score, the formula mapping raw model outputs (e.g., assessed belief level or probability) to the 0-100 scale, inter-annotator agreement statistics for the underlying annotations, and statistical significance tests for the reported model differences. revision: yes
-
Referee: [Dataset Construction] §3 (Dataset): The claim that annotations are 'fine-grained' and 'verified by national standards' is load-bearing for all downstream results, but no annotation protocol, annotator count, agreement metric, or validation procedure is described, leaving open the possibility that label noise could reverse the reported ordering between models.
Authors: The referee is correct that the current description of the annotation process is incomplete. We have revised §3 to provide the full annotation protocol, the number of annotators, the inter-annotator agreement metric employed, and the specific validation steps used to cross-check labels against national standards and academic literature. revision: yes
-
Referee: [Social Cue Investigation] §5 (Social Cue Analysis): The finding that models are susceptible to biases like authoritative channel IDs inherits the same unverified belief-score pipeline; without details on how social cues are isolated or scored, the causal attribution to specific cues cannot be assessed.
Authors: We acknowledge that the social-cue analysis requires additional methodological transparency to support causal claims. In the revised §5 we have added explicit descriptions of how social cues (such as channel IDs) are isolated within the videos, the scoring procedure for their influence on model belief scores, and any controls applied to attribute effects to individual cues. revision: yes
Circularity Check
No circularity: direct empirical evaluation on new annotated dataset
full rationale
The paper constructs a new dataset of 200 short videos with manual annotations for deceptive patterns, then directly evaluates eight MLLMs across modality settings to produce belief scores. No equations, fitted parameters, predictions derived from subsets, or self-citations are invoked to justify the core results. The reported scores (71.5 for Gemini-2.5-Pro, 35.2 for o3) are outputs of the evaluation pipeline rather than inputs renamed or forced by definition. The framework is self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manual annotations by experts using national standards and academic literature accurately capture the three deceptive patterns in the videos.
read the original abstract
Short-video platforms have become major channels for misinformation, where deceptive claims frequently leverage visual experiments and social cues. While Multimodal Large Language Models (MLLMs) have demonstrated impressive reasoning capabilities, their robustness against misinformation entangled with cognitive biases remains under-explored. In this paper, we introduce a comprehensive evaluation framework using a high-quality, manually annotated dataset of 200 short videos spanning four health domains. This dataset provides fine-grained annotations for three deceptive patterns-experimental errors, logical fallacies, and fabricated claims-each verified by evidence such as national standards and academic literature. We evaluate eight frontier MLLMs across five modality settings. Experimental results demonstrate that Gemini-2.5-Pro achieves the highest performance in the multimodal setting with a belief score of 71.5/100, while o3 performs the worst at 35.2. Furthermore, we investigate social cues that induce false beliefs in videos and find that models are susceptible to biases like authoritative channel IDs.
Figures












Forward citations
Cited by 1 Pith paper
-
When Seeing Is Not Believing -- A Benchmark for Search-Grounded Video Misinformation Detection
EVID-Bench supplies 222 videos across nine manipulation types in three categories and shows that frontier multimodal models reach at most 61.43% point-level accuracy when forced to use web search to identify false inf...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.