FinInvest-GTCN: Explainable Graph-Temporal-Causal Modeling for Risk-Aware Investment Decision Optimization
Pith reviewed 2026-06-30 09:32 UTC · model grok-4.3
The pith
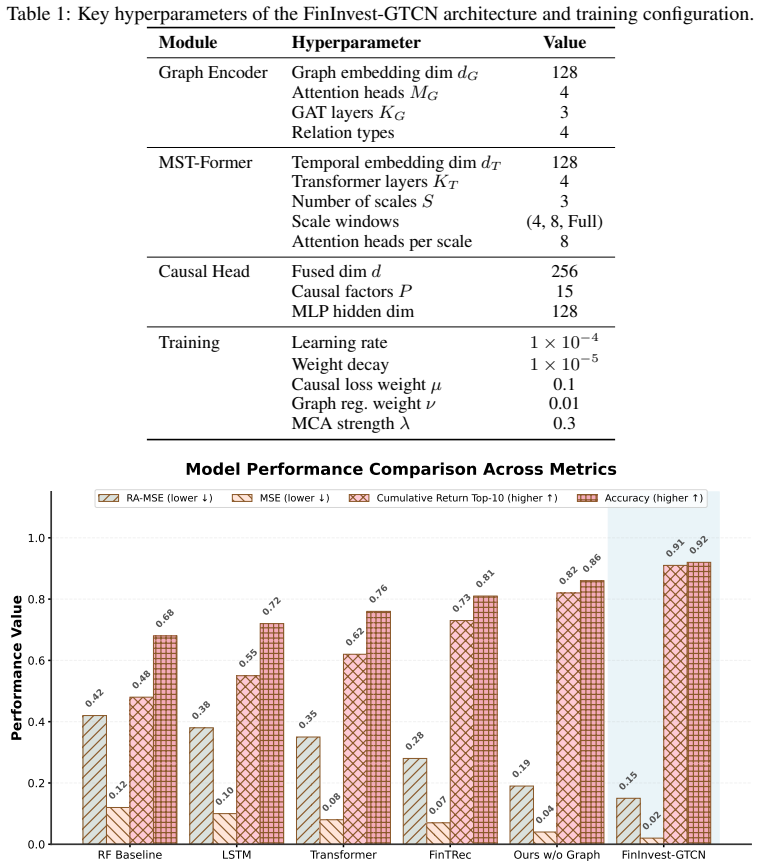
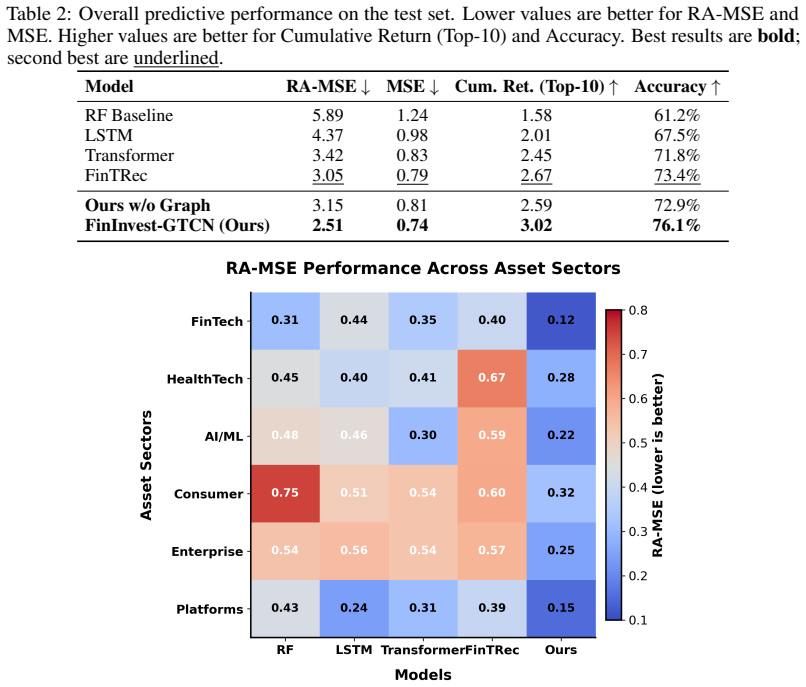
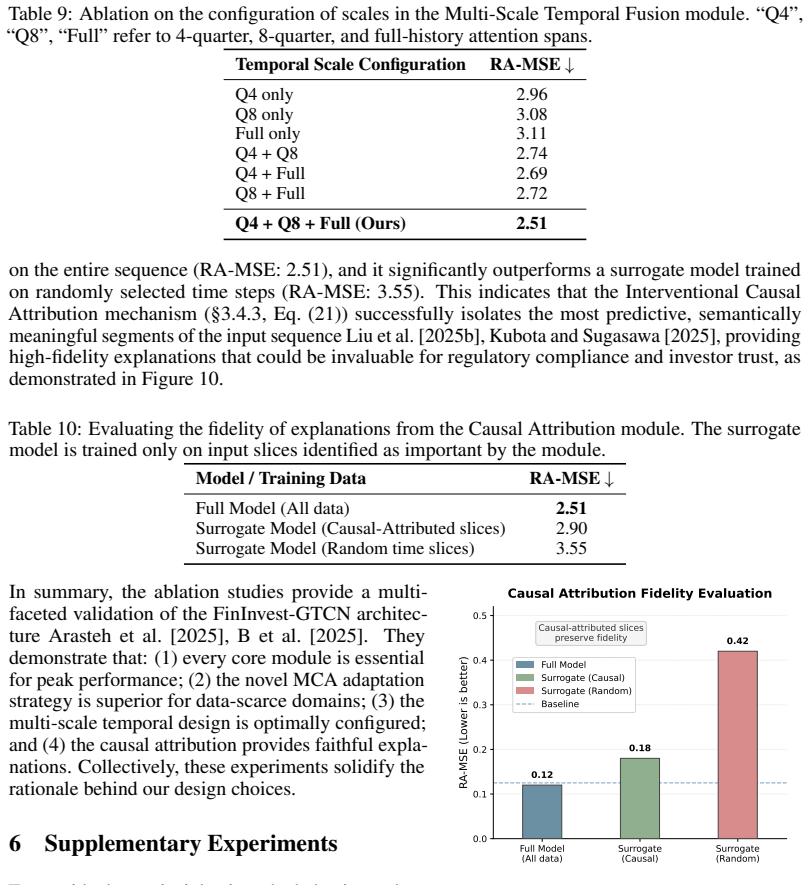
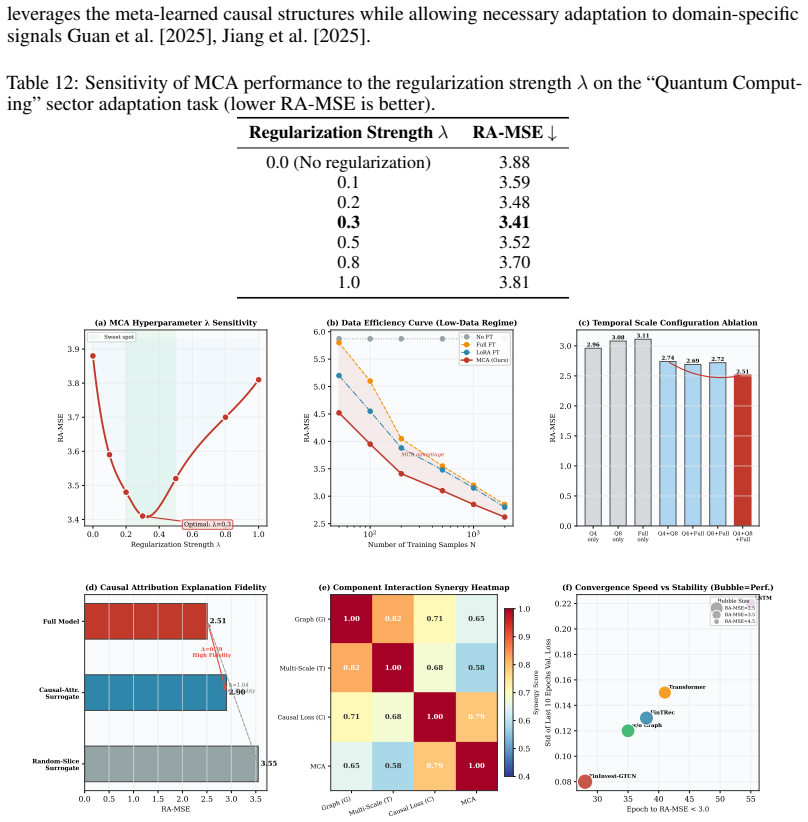
FinInvest-GTCN integrates graph, temporal and causal components to reduce VC risk-adjusted prediction error to 2.51 while raising simulated returns 18.7 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
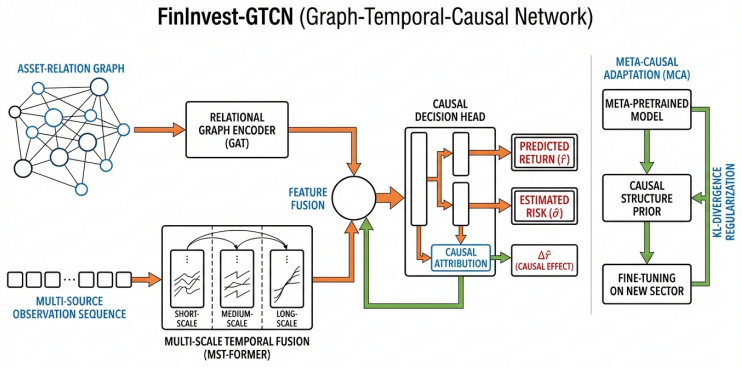
FinInvest-GTCN redefines venture capital assessment through a relational graph encoder that captures investment ecosystem topology, a multi-scale temporal fusion module that manages long-term dependencies and non-stationarity, and a causal decision head that produces risk-adjusted predictions together with interpretable causal attributions, all supported by a Meta-Causal Adaptation strategy that aligns fine-tuning updates with causally plausible structures obtained from meta-pretraining on the investment graph.
What carries the argument
The Meta-Causal Adaptation strategy inside the Graph-Temporal-Causal Network, which derives causally-plausible update directions from meta-pretraining on the investment ecosystem graph and applies them during fine-tuning on scarce data.
If this is right
- Each architectural piece contributes measurably to the gains, as shown when any one is removed.
- The model maintains stability and produces interpretable outputs across the tested VC datasets.
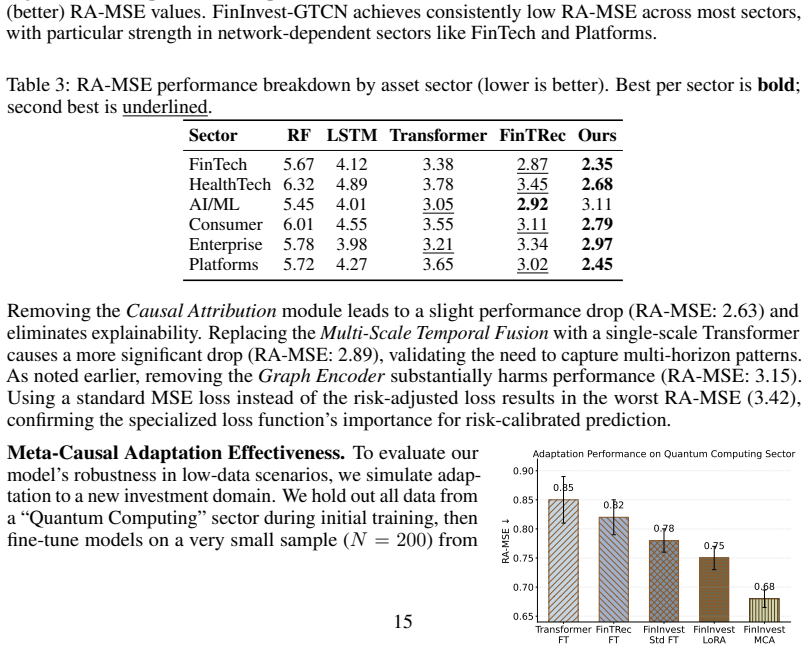
- Fine-tuning on limited data from a new sector becomes reliable once meta-pretraining on the broader graph has occurred.
- Simulated portfolios built from the model's outputs achieve an 18.7 percent higher cumulative return than those from baseline methods.
Where Pith is reading between the lines
- The same graph-plus-causal structure could be tested on other non-stationary financial tasks such as credit scoring or insurance pricing where data for new categories is also scarce.
- If the causal attributions remain consistent when the model is retrained on later time windows, they could serve as an ongoing monitor for shifts in risk drivers.
- Public release of the graph topology alone, without proprietary deal data, would allow independent checks of whether the reported error reduction generalizes beyond the original dataset.
- Pairing the adaptation step with streaming market signals might let the system update predictions continuously rather than in batch retraining cycles.
Load-bearing premise
The causal decision head produces accurate risk-adjusted predictions together with reliable causal attributions, and the Meta-Causal Adaptation step yields robust fine-tuning for new sectors from meta-pretraining on the investment graph.
What would settle it
Running the model on a held-out sector without the meta-pretraining step and finding that error stays at or above the 3.05 baseline, or that the generated causal attributions do not match the factors domain experts identify as driving actual investment outcomes.
Figures





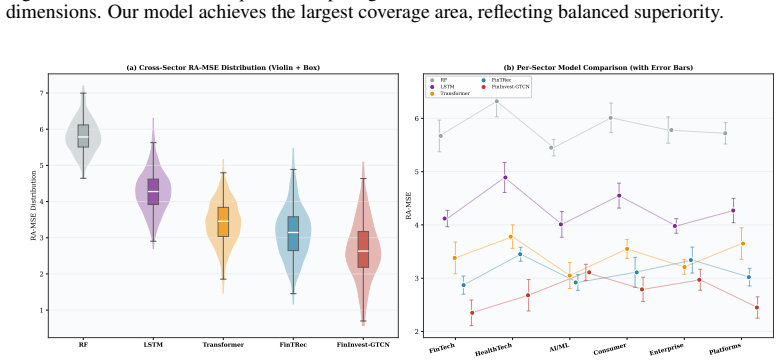
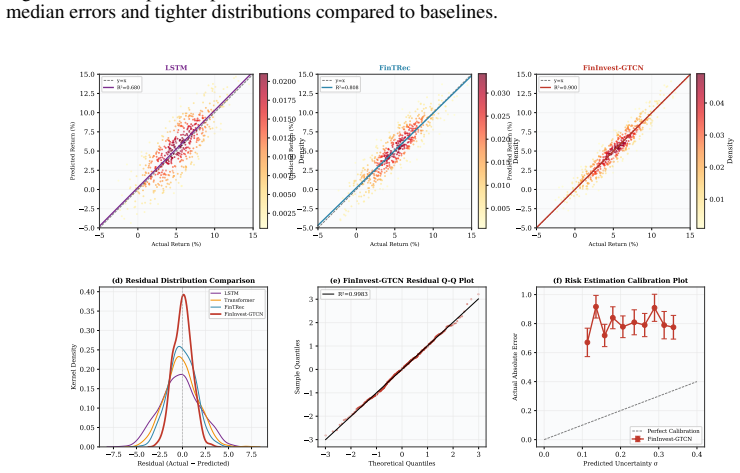
read the original abstract
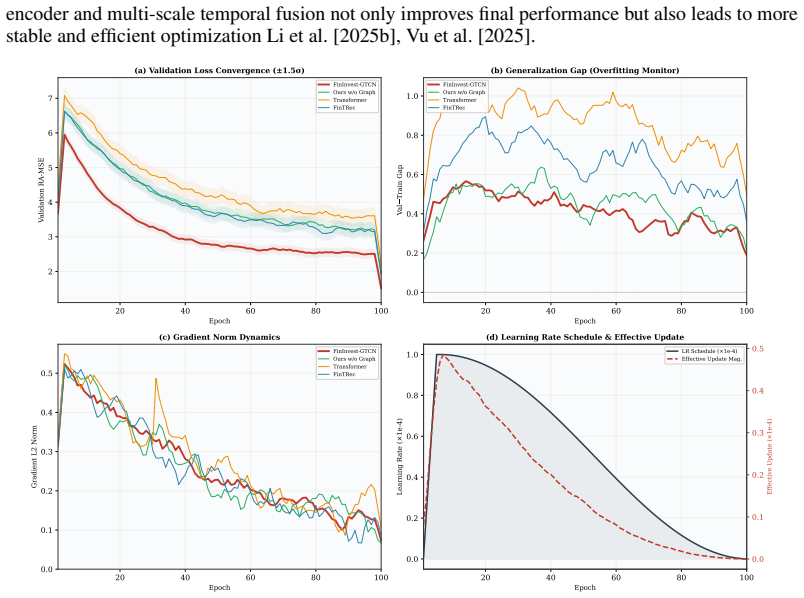
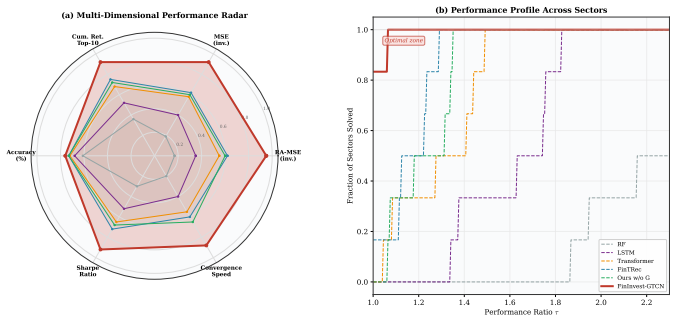
Venture capital (VC) investment decisions face distinct challenges, such as multi-source heterogeneous data, non-stationary time series, and the demand for explainable predictions in high-stakes, low-data settings. To overcome these issues, we introduce \textbf{FinInvest-GTCN}, a Graph-Temporal-Causal Network that redefines the task from content recommendation to quantitative risk-return assessment. This architecture combines a relational graph encoder to capture the investment ecosystem's topology, a multi-scale temporal fusion module to handle long-term dependencies and non-stationarity, and a causal decision head that generates risk-adjusted predictions with interpretable causal attributions. A core innovation is the Meta-Causal Adaptation (MCA) strategy, which facilitates robust fine-tuning for new, data-scarce sectors by aligning updates with causally-plausible structures derived from meta-pretraining. Comprehensive experiments on proprietary VC datasets show that FinInvest-GTCN delivers state-of-the-art results, markedly lowering the primary Risk-Adjusted Mean Squared Error (RA-MSE) to 2.51 from a baseline of 3.05 and boosting the cumulative return of a simulated portfolio by 18.7\%. Ablation studies underscore the essential role of each component, while additional analyses confirm the model's stability, interpretability, and enhanced adaptability. This work pioneers a data-driven, explainable framework for investment decision support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FinInvest-GTCN, a Graph-Temporal-Causal Network for VC investment decisions that integrates a relational graph encoder, multi-scale temporal fusion module, causal decision head with interpretable attributions, and a Meta-Causal Adaptation (MCA) strategy for fine-tuning in data-scarce sectors. On proprietary VC datasets it reports state-of-the-art results, reducing Risk-Adjusted Mean Squared Error (RA-MSE) from 3.05 to 2.51 and improving simulated portfolio cumulative return by 18.7%, with ablation studies asserted to confirm component contributions and additional analyses supporting stability and interpretability.
Significance. If the performance claims and causal interpretability hold under independent scrutiny, the work would offer a concrete advance in explainable, risk-aware modeling for non-stationary financial time series with heterogeneous graph structure. The MCA component targets a genuine practical gap in low-data regimes. However, the exclusive reliance on proprietary data without release or detailed protocol substantially reduces the result's immediate utility and verifiability for the broader community.
major comments (3)
- [Abstract] Abstract: The headline claims (RA-MSE drop from 3.05 to 2.51 and +18.7% cumulative return) are presented solely on proprietary VC datasets; no description of dataset size, sector coverage, temporal splits, baseline implementations, or error bars is supplied, rendering the SOTA assertion unverifiable and the central empirical contribution load-bearing yet unsupported.
- [Abstract] Abstract: Ablation studies are stated to 'underscore the essential role of each component' yet no numerical results, table, or quantitative deltas for the graph encoder, temporal fusion, causal head, or MCA are provided, leaving the necessity of the proposed modules unquantified.
- [Abstract] Abstract: The definitions of RA-MSE and the portfolio simulation protocol (including transaction costs, rebalancing frequency, and risk-adjustment formula) are not specified, which directly affects the interpretability of the reported 2.51 value and the 18.7% return gain.
minor comments (1)
- [Abstract] The abstract introduces 'Meta-Causal Adaptation (MCA)' and 'causal decision head' without a one-sentence high-level description of their mechanisms or how causal attributions are extracted, which would aid reader orientation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript accordingly where feasible, while respecting the constraints of proprietary data.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims (RA-MSE drop from 3.05 to 2.51 and +18.7% cumulative return) are presented solely on proprietary VC datasets; no description of dataset size, sector coverage, temporal splits, baseline implementations, or error bars is supplied, rendering the SOTA assertion unverifiable and the central empirical contribution load-bearing yet unsupported.
Authors: The abstract is subject to strict length limits. The full manuscript describes the proprietary dataset (approximate size, sector coverage, and temporal splits) and baseline implementations in Sections 3 and 4, with error bars reported in the results tables. We will revise the abstract to include a concise statement on dataset scale and evaluation protocol. Full public release remains impossible due to confidentiality. revision: partial
-
Referee: [Abstract] Abstract: Ablation studies are stated to 'underscore the essential role of each component' yet no numerical results, table, or quantitative deltas for the graph encoder, temporal fusion, causal head, or MCA are provided, leaving the necessity of the proposed modules unquantified.
Authors: Detailed numerical ablation results, including quantitative deltas for each component, appear in the main experimental section (with accompanying tables). The abstract offers only a high-level summary. In revision we will add a brief reference to the ablation outcomes or key deltas within the abstract if space allows. revision: yes
-
Referee: [Abstract] Abstract: The definitions of RA-MSE and the portfolio simulation protocol (including transaction costs, rebalancing frequency, and risk-adjustment formula) are not specified, which directly affects the interpretability of the reported 2.51 value and the 18.7% return gain.
Authors: We agree these elements require explicit definition for interpretability. The manuscript defines RA-MSE and details the simulation protocol (costs, rebalancing, risk adjustment) in the evaluation and experimental sections. We will insert concise definitions of both into the revised abstract. revision: yes
- Full release of the proprietary VC datasets or a completely open detailed protocol is not possible owing to confidentiality agreements.
Circularity Check
No circularity in derivation chain; empirical results on proprietary data do not constitute circularity
full rationale
The paper presents a novel architecture (relational graph encoder + multi-scale temporal fusion + causal decision head + Meta-Causal Adaptation) whose claimed performance gains are reported as experimental outcomes on proprietary VC datasets. No equations, self-citations, or fitted-parameter renamings are visible in the abstract or provided text that reduce any prediction to its own inputs by construction. The central claims remain independent empirical assertions rather than self-definitional or load-bearing self-citation reductions. Per the rules, absence of quotable circular steps requires score 0.
Axiom & Free-Parameter Ledger
free parameters (1)
- hyperparameters in MCA and fusion modules
axioms (2)
- domain assumption The investment ecosystem can be represented as a relational graph with meaningful topology
- ad hoc to paper Causal attributions from the decision head are interpretable and valid
invented entities (1)
-
Meta-Causal Adaptation (MCA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Uzair Akbar, Niki Kilbertus, Hao Shen, Krikamol Muandet, and Bo Dai. An analysis of causal effect estimation using outcome invariant data augmentation.arXiv preprint arXiv:2510.25128,
-
[2]
Adewale Akinfaderin and Shreyas Subramanian. Verafi: Verified agentic financial intelligence through neurosymbolic policy generation.arXiv preprint arXiv:2512.14744,
-
[3]
Mohammed Alduais, Xinming Li, and Qipei Mei. Trajgatformer: A graph-based transformer approach for worker and obstacle trajectory prediction in off-site construction environments.arXiv preprint arXiv:2510.22205,
-
[4]
Fazel Arasteh, Arian Haghparast, and Manos Papagelis. Network-constrained policy optimization for adaptive multi-agent vehicle routing.arXiv preprint arXiv:2510.26089,
-
[5]
Knight, Mehdi Azabou, Blake Richards, Cole L
Vinam Arora, Divyansha Lachi, Ian J. Knight, Mehdi Azabou, Blake Richards, Cole L. Hurwitz, Josh Siegle, and Eva L. Dyer. Know thyself by knowing others: Learning neuron identity from population context.arXiv preprint arXiv:2512.01199,
-
[6]
Adnan Ferdous Ashrafi and Hasanul Kabir. Enhanced graph convolutional network with chebyshev spectral graph and graph attention for autism spectrum disorder classification.arXiv preprint arXiv:2511.22178,
-
[7]
23 Sangeeth B, Serena Nicolazzo, Deepa K., and Vinod P. Protecting deep neural network intellectual property with chaos-based white-box watermarking.arXiv preprint arXiv:2512.16658,
-
[8]
Mohit Beniwal. Adaptive weighted genetic algorithm-optimized svr for robust long-term forecasting of global stock indices for investment decisions.arXiv preprint arXiv:2512.15113,
-
[9]
Undral Byambadalai, Tomu Hirata, Tatsushi Oka, and Shota Yasui. Beyond the average: Distributional causal inference under imperfect compliance.arXiv preprint arXiv:2509.15594,
-
[10]
Masoumeh Chapariniya, Teodora Vukovic, Sarah Ebling, and V olker Dellwo. Beyond appear- ance: Transformer-based person identification from conversational dynamics.arXiv preprint arXiv:2510.04753,
-
[11]
MVI-Bench: A Comprehensive Benchmark for Evaluating Robustness to Misleading Visual Inputs in LVLMs
Huiyi Chen, Jiawei Peng, Dehai Min, Changchang Sun, Kaijie Chen, Yan Yan, Xu Yang, and Lu Cheng. Mvi-bench: A comprehensive benchmark for evaluating robustness to misleading visual inputs in lvlms.arXiv preprint arXiv:2511.14159, 2025a. Kaijie Chen, Zihao Lin, Zhiyang Xu, Ying Shen, Yuguang Yao, Joy Rimchala, Jiaxin Zhang, and Lifu Huang. R2i-bench: Bench...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Financial risk relation identification through dual-view adaptation.arXiv preprint arXiv:2509.18775,
Wei-Ning Chiu, Yu-Hsiang Wang, Andy Hsiao, Yu-Shiang Huang, and Chuan-Ju Wang. Financial risk relation identification through dual-view adaptation.arXiv preprint arXiv:2509.18775,
-
[13]
Jeongwhan Choi, Seungjun Park, Sumin Park, Sung-Bae Cho, and Noseong Park. Are graph transformers necessary? efficient long-range message passing with fractal nodes in mpnns.arXiv preprint arXiv:2511.13010,
-
[14]
Entropic causal inference: Graph identifiability.arXiv preprint arXiv:2509.16463,
Spencer Compton, Kristjan Greenewald, Dmitriy Katz, and Murat Kocaoglu. Entropic causal inference: Graph identifiability.arXiv preprint arXiv:2509.16463,
-
[15]
Kaixin Ding, Yang Zhou, Xi Chen, Miao Yang, Jiarong Ou, Rui Chen, Xin Tao, and Hengshuang Zhao. Alchemist: Unlocking efficiency in text-to-image model training via meta-gradient data selection.arXiv preprint arXiv:2512.16905, 2025a. Ning Ding, Keisuke Fujii, and Toru Tamaki. Shot2tactic-caption: Multi-scale captioning of badminton videos for tactical unde...
-
[16]
Bioimageaipub: a toolbox for ai-ready bioimaging data publishing.arXiv preprint arXiv:2512.15820,
Stefan Dvoretskii, Anwai Archit, Constantin Pape, Josh Moore, and Marco Nolden. Bioimageaipub: a toolbox for ai-ready bioimaging data publishing.arXiv preprint arXiv:2512.15820,
-
[17]
Dingya Feng and Dingyuan Xue. Spatiotemporal transformers for predicting avian disease risk from migration trajectories.arXiv preprint arXiv:2510.15254,
-
[18]
Changzeng Fu, Shiwen Zhao, Yunze Zhang, Zhongquan Jian, Shiqi Zhao, and Chaoran Liu. Personality-guided public-private domain disentangled hypergraph-former network for multimodal depression detection.arXiv preprint arXiv:2511.12460,
-
[19]
Love, lies, and language models: Investigating ai’s role in romance- baiting scams.Usenix Security Symposium 2026,
24 Gilad Gressel, Rahul Pankajakshan, Shir Rozenfeld, Ling Li, Ivan Franceschini, Krishnahsree Achuthan, and Yisroel Mirsky. Love, lies, and language models: Investigating ai’s role in romance- baiting scams.Usenix Security Symposium 2026,
2026
-
[20]
Yunchuan Guan, Yu Liu, Ke Zhou, Zhiqi Shen, Jenq-Neng Hwang, Serge Belongie, and Lei Li. Is meta-learning out? rethinking unsupervised few-shot classification with limited entropy.arXiv preprint arXiv:2509.13185,
- [21]
-
[22]
Qian Hong, Cheng Bian, Xiao Zhou, Xiaoyu Li, Yelei Li, and Zijing Zeng. Lost in time? a meta- learning framework for time-shift-tolerant physiological signal transformation.arXiv preprint arXiv:2511.21500,
-
[23]
Jun Hu, Shangheng Chen, Yufei He, Yuan Li, Bryan Hooi, and Bingsheng He. Echoless label- based pre-computation for memory-efficient heterogeneous graph learning.arXiv preprint arXiv:2511.11081,
-
[24]
GUI Agents for Continual Game Generation
Yixu Huang, Bo Li, Na Li, Zhe Wang, Kaijie Chen, Haonan Ge, Qingyi Si, Yuanzhe Shen, Rui- han Yang, Guangjing Wang, et al. Gui agents for continual game generation.arXiv preprint arXiv:2605.28258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Federated learning via meta-variational dropout.Jeon, I., Hong, M., Yun, J., Kim, G
Insu Jeon, Minui Hong, Junhyeog Yun, and Gunhee Kim. Federated learning via meta-variational dropout.Jeon, I., Hong, M., Yun, J., Kim, G. (2023). Federated Learning via Meta-Variational Dropout. Advances in Neural Information Processing Systems 36 (NeurIPS 2023), 2025a. Insu Jeon, Youngjin Park, and Gunhee Kim. Neural variational dropout processes.arXiv p...
-
[26]
Jikai Jin, Lester Mackey, and Vasilis Syrgkanis. It’s hard to be normal: The impact of noise on structure-agnostic estimation.arXiv preprint arXiv:2507.02275,
-
[27]
Inference for batched adaptive experiments.arXiv preprint arXiv:2512.10156,
Jan Kemper and Davud Rostam-Afschar. Inference for batched adaptive experiments.arXiv preprint arXiv:2512.10156,
-
[28]
Benjamin Kempinski and Tal Kachman. Going with the flow: Approximating banzhaf values via graph neural networks.arXiv preprint arXiv:2510.13391,
-
[29]
Hyunsung Kim, Sangwoo Seo, Hoyoung Choi, Tom Boomstra, Jinsung Yoon, and Chanyoung Park. Better prevent than tackle: Valuing defense in soccer based on graph neural networks.arXiv preprint arXiv:2512.10355,
-
[30]
Yu Kiu, Lau, Chao Chen, Ge Jin, and Chen Feng. Flexible and efficient spatio-temporal transformer for sequential visual place recognition.arXiv preprint arXiv:2510.04282,
-
[31]
Kohsuke Kubota and Shonosuke Sugasawa. Causal inference under threshold manipulation: Bayesian mixture modeling and heterogeneous treatment effects.arXiv preprint arXiv:2509.19814,
-
[32]
Ivan Kukanov and Jun Wah Ng. Klassify to verify: Audio-visual deepfake detection using ssl-based audio and handcrafted visual features.arXiv preprint arXiv:2508.07337,
-
[33]
25 Uisang Lee, Changhoon Chung, Junmo Lee, and Soo-Mook Moon. Bugsweeper: Function-level detec- tion of smart contract vulnerabilities using graph neural networks.arXiv preprint arXiv:2512.09385,
-
[34]
Bangyu Li, Boping Gu, and Ziyang Ding. Llm-based personalized portfolio recommender: Integrating large language models and reinforcement learning for intelligent investment strategy optimization. arXiv preprint arXiv:2512.12922, 2025a. Harrison H. Li, Medhanie Irgau, Nabil Janmohamed, Karen Solveig Rieckmann, and David B. Lobell. Scalable vision-guided cr...
-
[35]
Anjie Liu, Jianhong Wang, Samuel Kaski, Jun Wang, and Mengyue Yang. A principle of targeted intervention for multi-agent reinforcement learning.arXiv preprint arXiv:2510.17697, 2025a. Bo Liu, Qiao Qin, and Qinghui He. Causalclip: Causally-informed feature disentanglement and filtering for generalizable detection of generated images.arXiv preprint arXiv:25...
-
[36]
no. 4, pp.2215-2235, 2023, 2025c. Parthiban Loganathan, Elias Zea, Ricardo Vinuesa, and Evelyn Otero. Deep learning-driven down- scaling for climate risk assessment of projected temperature extremes in the nordic region.arXiv preprint arXiv:2511.03770,
-
[37]
Jiangkai Long, Yanran Zhu, Chang Tang, Kun Sun, Yuanyuan Liu, and Xuesong Yan. When genes speak: A semantic-guided framework for spatially resolved transcriptomics data clustering.arXiv preprint arXiv:2511.11380,
-
[38]
Jiayi Luo, Qingyun Sun, Yuecen Wei, Haonan Yuan, Xingcheng Fu, and Jianxin Li. Privacy auditing of multi-domain graph pre-trained model under membership inference attacks.arXiv preprint arXiv:2511.17989,
-
[39]
Xueqi Ma, Xingjun Ma, Sarah Monazam Erfani, Danilo Mandic, and James Bailey. Coarse-to-fine open-set graph node classification with large language models.arXiv preprint arXiv:2512.16244,
-
[40]
Large causal models from large language models.arXiv preprint arXiv:2512.07796,
Sridhar Mahadevan. Large causal models from large language models.arXiv preprint arXiv:2512.07796,
-
[41]
Mingqiao Mo, Yunlong Tan, Hao Zhang, Heng Zhang, and Yangfan He. Shieldedcode: Learning robust representations for virtual machine protected code.arXiv preprint arXiv:2601.20679,
-
[42]
Foundation Models in Biomedical Imaging: Turning Hype into Reality
Amgad Muneer, Kai Zhang, Ibraheem Hamdi, Rizwan Qureshi, Muhammad Waqas, Shereen Fouad, Hazrat Ali, Syed Muhammad Anwar, and Jia Wu. Foundation models in biomedical imaging: Turning hype into reality.arXiv preprint arXiv:2512.15808,
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Ares: Anomaly recogni- tion model for edge streams.arXiv preprint arXiv:2511.22078,
Simone Mungari, Albert Bifet, Giuseppe Manco, and Bernhard Pfahringer. Ares: Anomaly recogni- tion model for edge streams.arXiv preprint arXiv:2511.22078,
-
[44]
Oganesian, Saba Hashemi, and Maryam M
Lucine L. Oganesian, Saba Hashemi, and Maryam M. Shanechi. Barista: Brain scale informed spatiotemporal representation of human intracranial neural activity.NeurIPS 2025,
2025
-
[45]
26 Anna Perekhodko and Robert ´Slepaczuk
URLhttps://arxiv.org/abs/2409.17120. 26 Anna Perekhodko and Robert ´Slepaczuk. Stochastic volatility modelling with lstm networks: A hybrid approach for s&p 500 index volatility forecasting.arXiv preprint arXiv:2512.12250,
-
[46]
Information-Consistent Language Model Recommendations through Group Relative Policy Optimization
Sonal Prabhune, Balaji Padmanabhan, and Kaushik Dutta. Information-consistent language model recommendations through group relative policy optimization.arXiv preprint arXiv:2512.12858,
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
URL https: //arxiv.org/abs/2410.15584. Manonmani Sekar and Nasim Nezamoddini. Optimizing multi-lane intersection performance in mixed autonomy environments.arXiv preprint arXiv:2511.02217,
-
[48]
Rathin Chandra Shit and Sharmila Subudhi. Hierarchical federated graph attention networks for scalable and resilient uav collision avoidance.arXiv preprint arXiv:2511.11616,
-
[49]
Manh Chien Vu, Thang Le Dinh, Manh Chien Vu, Tran Duc Le, and Thi Lien Huong Nguyen. A conceptual model for ai adoption in financial decision-making: Addressing the unique challenges of small and medium-sized enterprises.arXiv preprint arXiv:2512.04339,
-
[50]
Sirui Wang, Zhou Guan, Bingxi Zhao, and Tongjia Gu. Castformer: Causal spatio-temporal trans- former for driving intention prediction.arXiv preprint arXiv:2507.13425, 2025a. Xin Wang, Pietro Lodi Rizzini, Sourav Medya, and Zhiling Lan. Smart: A surrogate model for predicting application runtime in dragonfly systems.arXiv preprint arXiv:2511.11111, 2025b. ...
- [51]
-
[52]
Wendong Yao, Binhua Huang, and Soumyabrata Dev. Multi-modal spatio-temporal transformer for high-resolution land subsidence prediction.arXiv preprint arXiv:2509.25393,
-
[53]
Zhenqiang Ye, Jinjie Lu, Tianlong Gu, Fengrui Hao, and Xuemin Wang. Fairgse: Fairness-aware graph neural network without high false positive rates.arXiv preprint arXiv:2511.12132,
-
[54]
Ziqing Yin, Xuanjing Chen, and Xi Zhang. Ai-integrated decision support system for real-time market growth forecasting and multi-source content diffusion analytics.arXiv preprint arXiv:2511.09962,
-
[55]
Probability-Entropy Calibration: An Elastic Indicator for Adaptive Fine-tuning
Wenhao Yu, Shaohang Wei, Jiahong Liu, Yifan Li, Minda Hu, Aiwei Liu, Hao Zhang, and Irwin King. Probability-entropy calibration: An elastic indicator for adaptive fine-tuning.arXiv preprint arXiv:2602.01745,
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Junhyeog Yun, Minui Hong, and Gunhee Kim. Fedmenf: Privacy-preserving federated meta-learning for neural fields.arXiv preprint arXiv:2508.06301,
- [57]
-
[58]
27 Hao Zhang, Bo Huang, Zhenjia Li, Xi Xiao, Hui Yi Leong, Zumeng Zhang, Xinwei Long, Tianyang Wang, and Hao Xu. Sensitivity-lora: Low-load sensitivity-based fine-tuning for large language models.arXiv preprint arXiv:2509.09119, 2025a. Hao Zhang, Zhenjia Li, Runfeng Bao, Yifan Gao, Xi Xiao, Heng Zhang, Shuyang Zhang, Bo Huang, Yuhang Wu, Tianyang Wang, et...
-
[59]
Qinjian Zhao, Zhihao Dou, Dinggen Zhang, Xiangyu Li, Chaoda Song, Zhongwei Wan, Xinpeng Li, Yanyan Zhang, Kaijie Chen, Qingtao Pan, et al. Stride: Strategic trajectory reasoning via discriminative estimation for verifiable reinforcement learning.arXiv preprint arXiv:2606.15866,
-
[60]
Boosting adversarial transferability via ensemble non-attention.arXiv preprint arXiv:2511.08937,
Yipeng Zou, Qin Liu, Jie Wu, Yu Peng, Guo Chen, Hui Zhou, and Guanghui Ye. Boosting adversarial transferability via ensemble non-attention.arXiv preprint arXiv:2511.08937,
- [61]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.