DeceptionX: Explainable Deception Detection with Multimodal Large Language Models
Pith reviewed 2026-06-27 13:14 UTC · model grok-4.3
The pith
DeceptionX shifts deception detection from black-box classification to an interpretable Observe-Think-Summarize process in multimodal large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
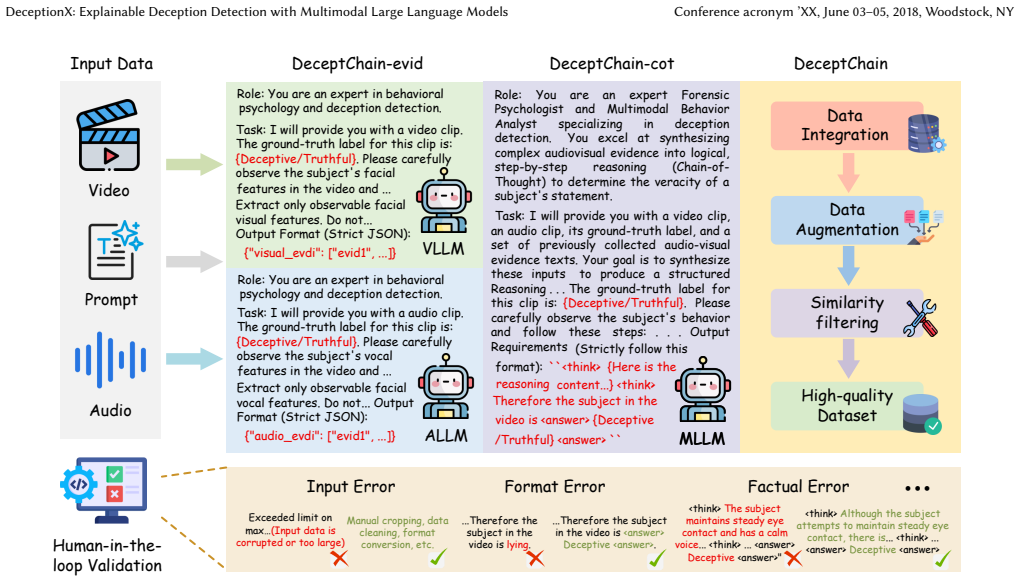
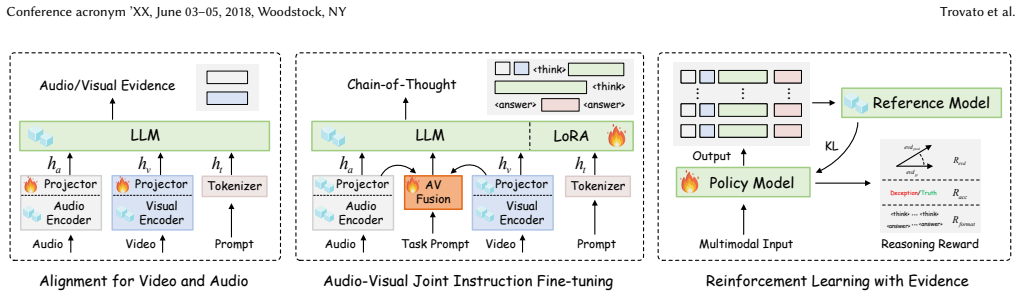
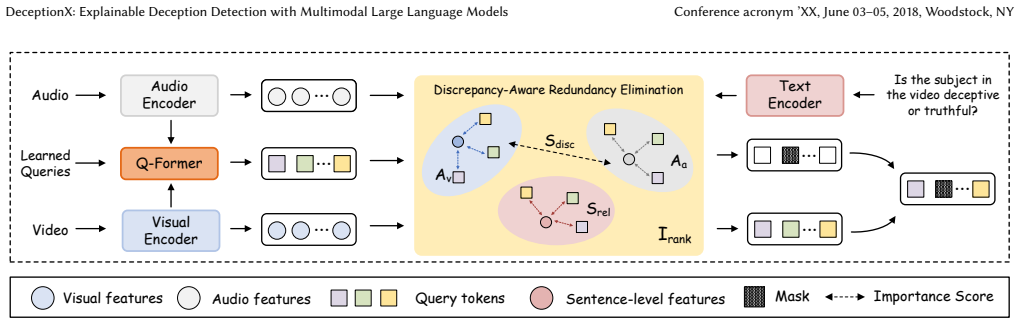
DeceptionX is an MLLM framework that replaces black-box classification with an Observe-Think-Summarize reasoning process; it is trained on the DeceptChain dataset of human-synthesized chain-of-thought traces and employs a three-stage pipeline plus DARE strategy, yielding both superior benchmark performance and expert-level interpretable reasoning paths.
What carries the argument
The Observe-Think-Summarize reasoning process, which converts low-level audiovisual cues into structured logical deduction steps before producing a final verdict.
If this is right
- Deception detection systems can move from opaque yes/no outputs to step-by-step explanations that investigators can audit.
- Training data scarcity for logical reasoning in affective tasks can be addressed by human-guided synthesis of chain-of-thought traces.
- Multimodal models can be made to generalize better on real-world deception benchmarks when discrepancy-aware redundancy removal is applied during training.
- The gap between classification accuracy and interpretability narrows when models are explicitly trained to follow an Observe-Think-Summarize sequence.
Where Pith is reading between the lines
- Similar human-in-the-loop chain-of-thought datasets could be constructed for other affective or behavioral analysis tasks that currently lack interpretable outputs.
- If the reasoning paths prove reliable, downstream applications such as automated interview screening or security screening could incorporate human review of the model's logic rather than only its final label.
- The three-stage training pipeline might transfer to other domains where low-level perceptual signals must be mapped to high-level logical conclusions.
Load-bearing premise
A human-in-the-loop process can reliably turn raw visual and auditory evidence into high-quality chain-of-thought reasoning data that captures how experts actually identify lies.
What would settle it
A controlled test in which the model is evaluated on new deception videos while its generated reasoning steps are scored for alignment with independent expert annotations; performance equal to or below prior black-box methods on the same videos would falsify the central claim.
Figures

read the original abstract
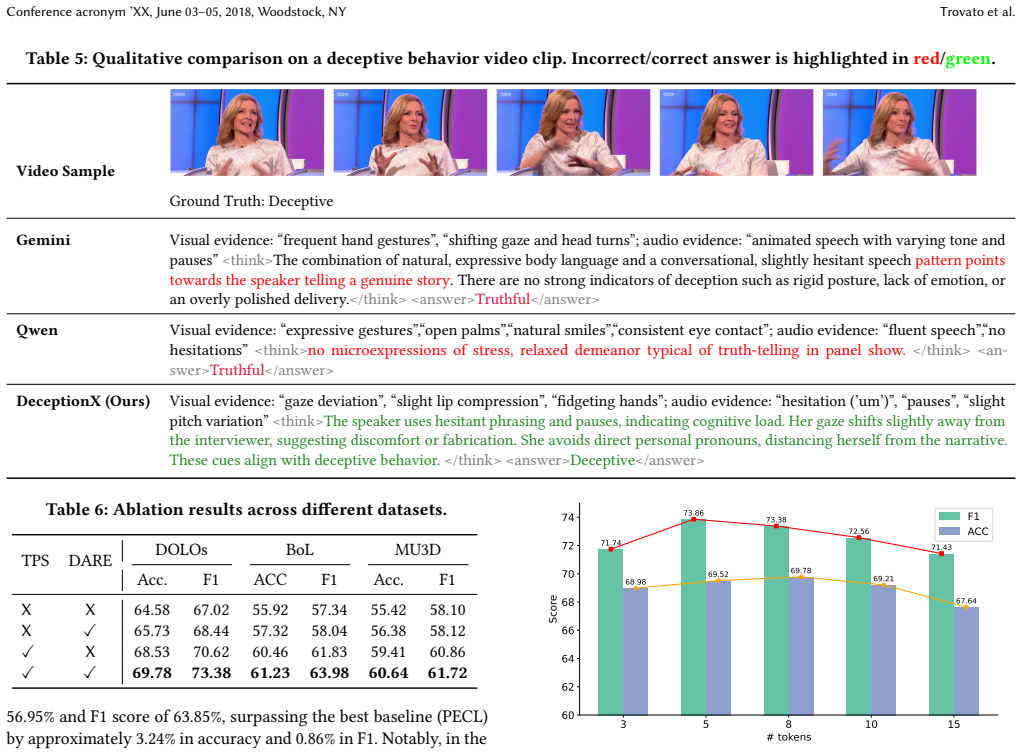
Deception detection is a critical and highly challenging task within affective computing and behavioral analysis. Existing deep learning methods typically treat this task as a straightforward classification problem; however, this black-box approach lacks interpretability and fails to capture the complex logical deduction processes utilized by human experts when identifying lies. While Multimodal Large Language Models (MLLMs) have shown potential, applying them effectively requires a bridge between low-level audiovisual cues and high-level logical reasoning. In this paper, we propose DeceptionX, a novel MLLM framework that shifts the paradigm of deception detection from black-box classification to an interpretable Observe-Think-Summarize reasoning process. To address the scarcity of high-quality reasoning data, we first constructed DeceptChain, a high-quality dataset developed through a human-in-the-loop process. This dataset synthesizes fine-grained visual and auditory evidence (such as micro-expressions and vocal tremors) into structured chain-of-thought reasoning data. Furthermore, we propose a three-stage training pipeline and a Discrepancy-Aware Redundancy Elimination~(DARE) strategy for DeceptionX to further enhance the model's generalization capabilities. Extensive experiments demonstrate that DeceptionX not only outperforms existing MLLM baselines and state-of-the-art methods on standard real-world benchmarks but also provides transparent, expert-level reasoning paths, bridging the critical gap between accuracy and interpretability in multimodal deception detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DeceptionX, an MLLM-based framework for multimodal deception detection that replaces black-box classification with an Observe-Think-Summarize reasoning process. It introduces the DeceptChain dataset, constructed via human-in-the-loop synthesis of fine-grained visual (micro-expressions) and auditory (vocal tremors) cues into structured chain-of-thought reasoning data, and applies a three-stage training pipeline together with a Discrepancy-Aware Redundancy Elimination (DARE) strategy. The central claim is that DeceptionX outperforms existing MLLM baselines and prior SOTA methods on standard real-world benchmarks while also supplying transparent, expert-level reasoning paths.
Significance. If the data-quality and performance claims hold after validation, the work would be significant for affective computing: it directly targets the interpretability gap that has limited prior deep-learning approaches to deception detection and demonstrates how MLLMs can be adapted to capture complex logical deduction from low-level audiovisual signals. The combination of a custom reasoning dataset, staged training, and DARE constitutes a concrete methodological contribution that could be reused in related multimodal reasoning tasks.
major comments (2)
- [Dataset construction / DeceptChain] Dataset construction section: the human-in-the-loop process used to synthesize DeceptChain into expert-level CoT reasoning data is presented without any reported quantitative validation (inter-annotator agreement, expert review scores, or comparison against held-out gold reasoning). This is load-bearing for the central claim, because the asserted outperformance and “expert-level reasoning paths” rest on the premise that the synthesized data faithfully capture complex logical deduction rather than annotator-specific biases or superficial patterns.
- [Experiments / Results] Experiments and results sections: the abstract and introduction assert quantitative outperformance over MLLM baselines and SOTA methods on real-world benchmarks, yet the provided text supplies no numerical results, error bars, dataset statistics, or ablation tables that would allow evaluation of the claim. Without these, the contribution of the three-stage pipeline and DARE cannot be isolated from possible dataset artifacts.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least the headline quantitative metrics (accuracy/F1 deltas, number of benchmarks) that support the outperformance claim.
- [Method / DARE] The description of the DARE strategy would benefit from an explicit equation or pseudocode showing how discrepancy is computed and how redundancy is eliminated.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and will revise the manuscript accordingly to provide the requested quantitative details.
read point-by-point responses
-
Referee: [Dataset construction / DeceptChain] Dataset construction section: the human-in-the-loop process used to synthesize DeceptChain into expert-level CoT reasoning data is presented without any reported quantitative validation (inter-annotator agreement, expert review scores, or comparison against held-out gold reasoning). This is load-bearing for the central claim, because the asserted outperformance and “expert-level reasoning paths” rest on the premise that the synthesized data faithfully capture complex logical deduction rather than annotator-specific biases or superficial patterns.
Authors: We agree that quantitative validation of the DeceptChain construction process is essential. In the revised manuscript we will add inter-annotator agreement statistics (Fleiss’ kappa), expert review scores, and a comparison of the synthesized CoT paths against a held-out set of gold-standard reasoning annotations within the Dataset Construction section. revision: yes
-
Referee: [Experiments / Results] Experiments and results sections: the abstract and introduction assert quantitative outperformance over MLLM baselines and SOTA methods on real-world benchmarks, yet the provided text supplies no numerical results, error bars, dataset statistics, or ablation tables that would allow evaluation of the claim. Without these, the contribution of the three-stage pipeline and DARE cannot be isolated from possible dataset artifacts.
Authors: We acknowledge that the submitted text does not contain the numerical results, error bars, dataset statistics, or ablation tables. In the revision we will expand the Experiments and Results sections to include full performance tables with means and standard deviations, benchmark dataset statistics, and ablation studies that isolate the contributions of the three-stage pipeline and DARE strategy. revision: yes
Circularity Check
No circularity: empirical pipeline evaluated on external benchmarks
full rationale
The paper presents a dataset construction (DeceptChain via human-in-the-loop), a three-stage training pipeline, and DARE strategy, then reports performance on standard real-world benchmarks. No equations, parameter-fitting steps, or derivations are described that reduce any claimed result to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on external benchmark comparisons rather than self-referential definitions or renamed known results. This is a standard empirical ML methods paper whose derivation chain is self-contained against held-out data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mohamed Abouelenien, Mihai Burzo, Verónica Pérez-Rosas, Rada Mihalcea, Haitian Sun, and Bohan Zhao. 2018. Gender differences in multimodal contact- free deception detection.IEEE MultiMedia26, 3 (2018), 19–30
2018
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Chongyang Bai, Maksim Bolonkin, Judee Burgoon, Chao Chen, Norah Dunbar, Bharat Singh, VS Subrahmanian, and Zhe Wu. 2019. Automatic long-term decep- tion detection in group interaction videos. In2019 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1600–1605
2019
-
[4]
Chongyang Bai, Maksim Bolonkin, Viney Regunath, and VS Subrahmanian. 2022. POLLY: A multimodal cross-cultural context-sensitive framework to predict political lying from videos. InProceedings of the 2022 International Conference on Multimodal Interaction. 520–530
2022
-
[5]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Leo Breiman. 2001. Random forests.Machine learning45, 1 (2001), 5–32
2001
-
[7]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. 2024. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, et al. 2024. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. 2023. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models.arXiv preprint arXiv:2311.07919(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Alex Sebastião Constâncio, Denise Fukumi Tsunoda, Helena de Fátima Nunes Silva, Jocelaine Martins da Silveira, and Deborah Ribeiro Carvalho. 2023. De- ception detection with machine learning: A systematic review and statistical analysis.Plos one18, 2 (2023), e0281323
2023
-
[11]
Barry De Ville. 2013. Decision trees.Wiley Interdisciplinary Reviews: Computa- tional Statistics5, 6 (2013), 448–455
2013
-
[12]
Arianna D’Ulizia, Alessia D’Andrea, Patrizia Grifoni, and Fernando Ferri. 2024. Analysis, evaluation, and future directions on multimodal deception detection. Technologies12, 5 (2024), 71
2024
-
[13]
Klaus Greff, Rupesh K Srivastava, Jan Koutník, Bas R Steunebrink, and Jürgen Schmidhuber. 2016. LSTM: A search space odyssey.IEEE transactions on neural networks and learning systems28, 10 (2016), 2222–2232
2016
-
[14]
Xiaobao Guo, Nithish Muthuchamy Selvaraj, Zitong Yu, Adams Wai-Kin Kong, Bingquan Shen, and Alex Kot. 2023. Audio-visual deception detection: Do- los dataset and parameter-efficient crossmodal learning. InProceedings of the IEEE/CVF International Conference on Computer Vision. 22135–22145
2023
-
[15]
Viresh Gupta, Mohit Agarwal, Manik Arora, Tanmoy Chakraborty, Richa Singh, and Mayank Vatsa. 2019. Bag-of-lies: A multimodal dataset for deception detec- tion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 0–0
2019
-
[16]
Hearst, Susan T Dumais, Edgar Osuna, John Platt, and Bernhard Scholkopf
Marti A. Hearst, Susan T Dumais, Edgar Osuna, John Platt, and Bernhard Scholkopf. 1998. Support vector machines.IEEE Intelligent Systems and their applications13, 4 (1998), 18–28
1998
-
[17]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Jian Kang, Wen Qu, Shaoxing Cui, and Xiaoyi Feng. 2024. Deception detection algorithm based on global and local feature fusion with multi-head attention. In2024 3rd International Conference on Image Processing and Media Computing (ICIPMC). IEEE, 162–168
2024
-
[19]
Mohan Karnati, Ayan Seal, Anis Yazidi, and Ondrej Krejcar. 2021. LieNet: a deep convolution neural network framework for detecting deception.IEEE transactions on cognitive and developmental systems14, 3 (2021), 971–984
2021
-
[20]
Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fa- had Shahbaz Khan, and Mubarak Shah. 2022. Transformers in vision: A survey. ACM computing surveys (CSUR)54, 10s (2022), 1–41
2022
-
[21]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
-
[22]
Zewen Li, Fan Liu, Wenjie Yang, Shouheng Peng, and Jun Zhou. 2021. A survey of convolutional neural networks: analysis, applications, and prospects.IEEE transactions on neural networks and learning systems33, 12 (2021), 6999–7019
2021
-
[23]
Zheng Lian, Haoyu Chen, Lan Chen, Haiyang Sun, Licai Sun, Yong Ren, Ze- bang Cheng, Bin Liu, Rui Liu, Xiaojiang Peng, et al . 2025. Affectgpt: A new dataset, model, and benchmark for emotion understanding with multimodal large language models.arXiv preprint arXiv:2501.16566(2025)
-
[24]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[25]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[26]
E Paige Lloyd, Jason C Deska, Kurt Hugenberg, Allen R McConnell, Brandon T Humphrey, and Jonathan W Kunstman. 2019. Miami University deception detec- tion database.Behavior research methods51, 1 (2019), 429–439
2019
-
[27]
Jaume Masip. 2017. Deception detection: State of the art and future prospects. Psicothema29, 2 (2017), 149–159
2017
-
[28]
Merylin Monaro, Stéphanie Maldera, Cristina Scarpazza, Giuseppe Sartori, and Nicolò Navarin. 2022. Detecting deception through facial expressions in a dataset of videotaped interviews: A comparison between human judges and machine learning models.Computers in Human Behavior127 (2022), 107063
2022
-
[29]
Borum Nam, Joo Young Kim, Beomjun Bark, Yeongmyeong Kim, Jiyoon Kim, Soon Won So, Hyung Youn Choi, and In Young Kim. 2023. FacialCueNet: un- masking deception-an interpretable model for criminal interrogation using facial expressions: IY Kim et al.Applied Intelligence53, 22 (2023), 27413–27427
2023
-
[30]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318
2002
-
[31]
Verónica Pérez-Rosas, Mohamed Abouelenien, Rada Mihalcea, and Mihai Burzo
-
[32]
InProceedings of the 2015 ACM on international conference on multimodal interaction
Deception detection using real-life trial data. InProceedings of the 2015 ACM on international conference on multimodal interaction. 59–66
2015
-
[33]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Felix Soldner, Verónica Pérez-Rosas, and Rada Mihalcea. 2019. Box of lies: Mul- timodal deception detection in dialogues. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 1768–1777
2019
-
[35]
Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. 2023. Pandagpt: One model to instruction-follow them all. InProceedings of the 1st Workshop on Taming Large Language Models: Controllability in the era of Interac- tive Assistants!11–23
2023
-
[36]
Pengjie Tang, Jiayu Zhang, Hanli Wang, Yunlan Tan, and Yun Yi. 2025. SRVC- LA: Sparse regularization of visual context and latent attention based model for Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al. video description.Neurocomputing630 (2025), 129639. doi:10.1016/j.neucom. 2025.129639
-
[37]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Taorui Wang, Xun Lin, Yong Xu, Qilang Ye, Dan Guo, Sergio Escalera, Ghada Khoriba, and Zitong Yu. 2026. Micro-gesture recognition: A comprehensive survey of datasets, methods, and challenges.Machine Intelligence Research23, 2 (2026), 308–330
2026
-
[40]
Zhe Wu, Bharat Singh, Larry Davis, and V Subrahmanian. 2018. Deception detection in videos. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
-
[41]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. 2025. Qwen2.5-Omni Technical Report. arXiv:2503.20215 [cs.CL] https://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Jiayu Zhang, Xun Lin, Jiajian Huang, Shuo Ye, Xiaobao Guo, Dongliang Zhu, Ruimin Hu, Dan Guo, Yanyan Liang, Zitong Yu, et al. 2026. Multimodal deception detection: A survey.Machine Intelligence Research23, 2 (2026), 284–307
2026
-
[44]
Jiayu Zhang, Pengjie Tang, Yunlan Tan, and Hanli Wang. 2025. MGTR-MISS: More Ground Truth Retrieving based Multimodal Interaction and Semantic Supervision for video description.Neural Networks192 (2025), 107817. doi:10.1016/j.neunet. 2025.107817
-
[45]
Jiayu Zhang, Shuo Ye, Qilang Ye, Xun Lin, Zihan Song, and Zitong Yu. 2025. AV-Master: Dual-Path Comprehensive Perception Makes Better Audio-Visual Question Answering.arXiv preprint arXiv:2510.18346(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Jiayu Zhang, Shuo Ye, Qilang Ye, Zihan Song, Jiajian Huang, and Zitong Yu. 2026. Retrieving to Recover: Towards Incomplete Audio-Visual Question Answering via Semantic-consistent Purification. arXiv:2604.10695 [cs.CV] https://arxiv.org/ abs/2604.10695
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.