Active Adversarial Perturbation-driven Associative Memory Retrieval for RGB-Event Visual Object Tracking
Pith reviewed 2026-06-26 01:10 UTC · model grok-4.3
The pith
A framework trains RGB-Event trackers to stay accurate when one sensor fails or the target is only partly visible by simulating those degradations with adversarial perturbations and retrieving past features through calibrated memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
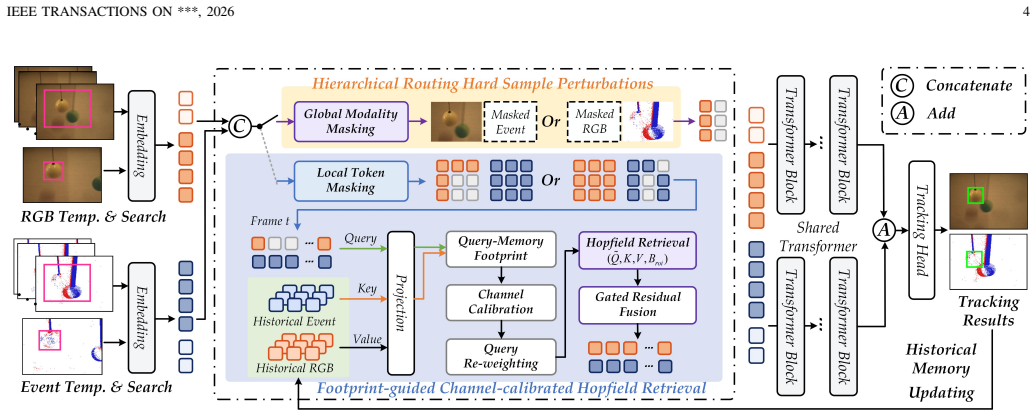
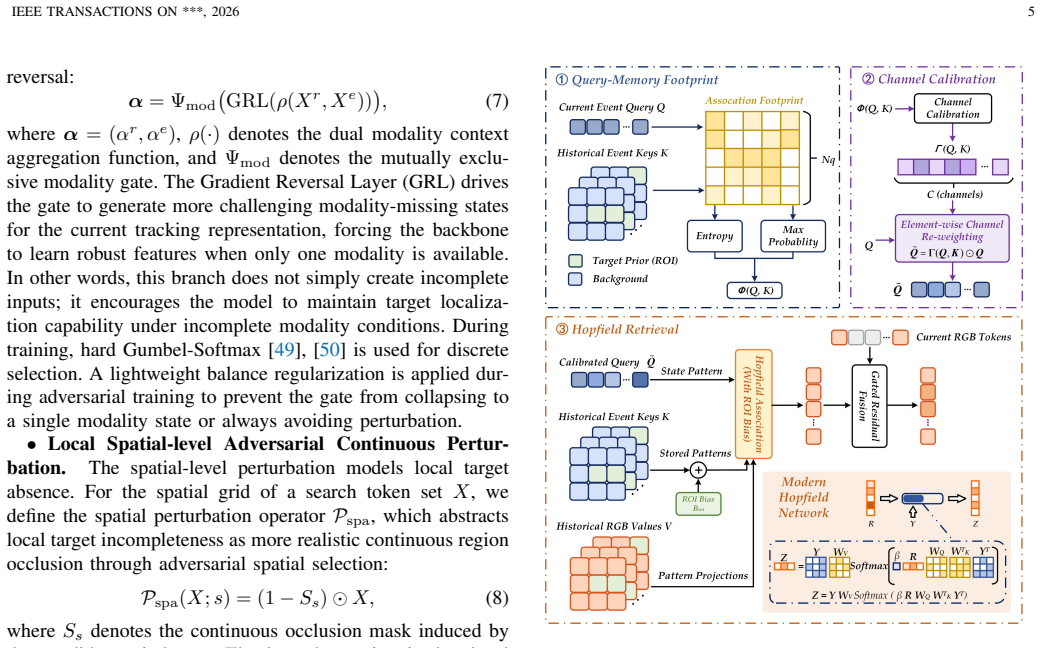
APRTrack constructs structured degradation via two adversarial perturbation branches at the modality and spatial levels, which separately simulate full-modal failure and localized target region absence. A hierarchical routing mechanism disentangles the training pipelines of the two perturbation types. Footprint-guided Channel-calibrated Hopfield Retrieval evaluates retrieval confidence based on association footprints between queries and memory banks, calibrates the retrieval metric space prior to Hopfield matching, and realizes controllable historical feature compensation bounded to target regions.
What carries the argument
Hierarchical adversarial perturbation branches at modality and spatial levels plus Footprint-guided Channel-calibrated Hopfield Retrieval (FCHR) that bounds memory compensation to target regions using association footprints.
If this is right
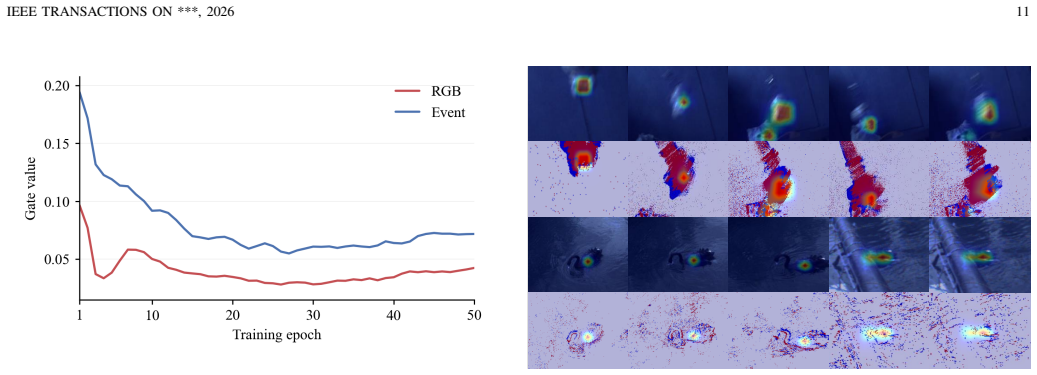
- Trackers retain localization when an entire modality drops out because the training explicitly forces the model to operate without it.
- Partial target absence is handled by learning to ignore or compensate for missing spatial regions rather than relying on complete appearance.
- Historical features are retrieved only when association footprints indicate high relevance, reducing contamination from background or earlier errors.
- The two degradation types can be trained separately without forcing the network into a collapsed feature space.
Where Pith is reading between the lines
- The same perturbation-plus-retrieval pattern could be tested on other multi-modal pairs such as RGB-infrared or RGB-LiDAR tracking.
- The footprint calibration step might be replaced by learned attention masks if the Hopfield component is swapped for a transformer memory.
- If the perturbations prove too specific, adding a third branch that simulates combined degradations could be checked for further gains.
Load-bearing premise
The adversarial perturbations created at training time produce degradations that closely match the sensor failures and partial target losses that actually occur in real RGB-Event videos.
What would settle it
Measure tracker accuracy on a set of real RGB-Event sequences containing modal failures or partial occlusions whose statistics differ from the two perturbation types used in training; a large drop relative to the reported results would falsify the transfer of robustness.
Figures


read the original abstract
RGB-Event tracking improves localization robustness by fusing RGB appearance textures and dense temporal motion cues from event sensors. While this multi-modal scheme broadens tracking applicability, real-world scenes suffer diverse structured signal degradations that hinder traditional multi-modal fusion. In harsh environments, either modality can lose reliability drastically, and targets frequently appear incomplete due to occlusion, edge truncation and foreground clutter.To tackle the above challenges, we present a hierarchical perturbation and retrieval framework tailored for RGB-Event tracking with robustness against partial target missing and modal degradation, termed APRTrack. To mimic real-world signal corruption, APRTrack constructs structured degradation via two adversarial perturbation branches at the modality and spatial levels, which separately simulate full-modal failure and localized target region absence. A hierarchical routing mechanism is designed to disentangle the training pipelines of the two perturbation types, effectively eliminating feature collapse induced by superimposed degradation constraints. Furthermore, we devise Footprint-guided Channel-calibrated Hopfield Retrieval (FCHR) for reliable historical information compensation. This module evaluates retrieval confidence based on association footprints between queries and memory banks, and calibrates the retrieval metric space prior to Hopfield matching, realizing controllable historical feature compensation bounded to target regions. Extensive experiments on FE108, COESOT, VisEvent, and FELT datasets demonstrate the effectiveness of our proposed strategies for the RGB-Event visual object tracking. The source code and pre-trained models will be released on https://github.com/Event-AHU/OpenEvTracking
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes APRTrack, a hierarchical perturbation and retrieval framework for RGB-Event visual object tracking. It constructs structured degradations via two adversarial perturbation branches (modality-level and spatial-level) to simulate full-modal failure and localized target absence, introduces a hierarchical routing mechanism to disentangle training pipelines and avoid feature collapse, and devises Footprint-guided Channel-calibrated Hopfield Retrieval (FCHR) to enable controllable historical feature compensation. Effectiveness is demonstrated via experiments on the FE108, COESOT, VisEvent, and FELT datasets, with code and models to be released.
Significance. If the adversarial perturbations are validated to match the statistics and structure of real RGB-Event degradations (rather than introducing non-physical artifacts) and the routing/FCHR components deliver measurable robustness gains under partial target missing and modal degradation, the work could advance reliable multi-modal tracking in adverse conditions. The explicit commitment to releasing source code and pre-trained models is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: The central robustness claim rests on the modality-level and spatial-level adversarial branches 'mimicking real-world signal corruption' by simulating full-modal failure and localized target absence. However, no quantitative validation is provided (e.g., KL divergence, event-rate histograms, polarity imbalance statistics, or comparison against real degraded sequences from FE108/COESOT) to confirm that the generated perturbations match the structure of actual event-camera noise, occlusion, or truncation rather than arbitrary adversarial patterns. This is load-bearing for whether the learned invariance transfers to real data.
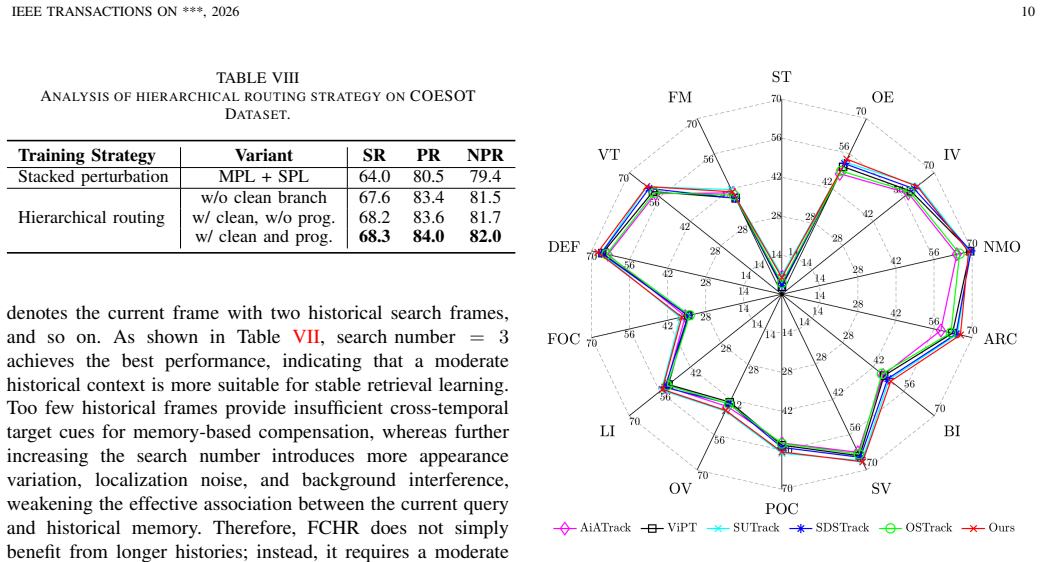
- [Method (hierarchical routing)] The hierarchical routing mechanism is presented as eliminating feature collapse from superimposed degradation constraints, yet the manuscript supplies no ablation or analysis (e.g., feature similarity metrics or training dynamics) showing that the disentanglement is necessary or effective. Without such evidence, it is unclear whether the reported gains on the four datasets are attributable to this component or to other factors.
minor comments (2)
- [Abstract] Abstract: The phrase 'extensive experiments ... demonstrate the effectiveness of our proposed strategies' is vague; specific metrics (e.g., success rate or precision gains over baselines) should be summarized to allow readers to gauge the magnitude of improvement.
- [Method (FCHR)] The FCHR module description refers to 'association footprints' and 'calibrates the retrieval metric space' without defining these terms or providing the corresponding equations; adding a short notation table or explicit formulas would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments point by point below, acknowledging where additional evidence is needed and outlining specific revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central robustness claim rests on the modality-level and spatial-level adversarial branches 'mimicking real-world signal corruption' by simulating full-modal failure and localized target absence. However, no quantitative validation is provided (e.g., KL divergence, event-rate histograms, polarity imbalance statistics, or comparison against real degraded sequences from FE108/COESOT) to confirm that the generated perturbations match the structure of actual event-camera noise, occlusion, or truncation rather than arbitrary adversarial patterns. This is load-bearing for whether the learned invariance transfers to real data.
Authors: We agree that explicit quantitative validation of the generated perturbations against real RGB-Event degradations would strengthen the claim that the simulated corruptions support transfer to real data. The current manuscript motivates the branches via domain-specific design (full-modal dropout for sensor failure and spatial masking for occlusion/truncation) but does not include direct statistical comparisons. In the revision we will add a new subsection (likely 4.3) reporting event-rate histograms, polarity imbalance statistics, and KL-divergence measurements between the adversarial outputs and real degraded sequences drawn from FE108 and COESOT. These results will be used to support or refine the perturbation parameters. revision: yes
-
Referee: [Method (hierarchical routing)] The hierarchical routing mechanism is presented as eliminating feature collapse from superimposed degradation constraints, yet the manuscript supplies no ablation or analysis (e.g., feature similarity metrics or training dynamics) showing that the disentanglement is necessary or effective. Without such evidence, it is unclear whether the reported gains on the four datasets are attributable to this component or to other factors.
Authors: We acknowledge that the manuscript currently states the purpose of the hierarchical routing without accompanying ablation or training-dynamics analysis. To demonstrate necessity, the revised version will include an ablation study (new Table or Figure in Section 4) that reports (i) cosine similarity between modality-level and spatial-level feature embeddings with and without routing, and (ii) training loss curves and final tracking metrics when the routing module is removed. This will clarify the contribution of the disentanglement step to the overall gains. revision: yes
Circularity Check
No circularity: empirical engineering framework with no load-bearing derivations or self-referential predictions
full rationale
The paper presents APRTrack as a proposed architecture consisting of adversarial perturbation branches, hierarchical routing, and FCHR retrieval for RGB-Event tracking. No equations, fitted parameters, or first-principles derivations are described in the provided text that would reduce any claimed robustness or performance gain to a tautology or self-definition. The method is introduced as an empirical contribution validated through experiments on FE108, COESOT, VisEvent, and FELT datasets. No self-citations are invoked as load-bearing uniqueness theorems, and no predictions are made that are statistically forced by construction from inputs. This is a standard non-circular engineering paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Transformer tracking,
X. Chen, B. Yan, J. Zhu, D. Wang, X. Yang, and H. Lu, “Transformer tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8126–8135
2021
-
[2]
Mixformer: End-to-end tracking with iterative mixed attention,
Y . Cui, C. Jiang, L. Wang, and G. Wu, “Mixformer: End-to-end tracking with iterative mixed attention,” inProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, 2022, pp. 13 608– 13 618
2022
-
[3]
Joint feature learning and relation modeling for tracking: A one-stream framework,
B. Ye, H. Chang, B. Ma, S. Shan, and X. Chen, “Joint feature learning and relation modeling for tracking: A one-stream framework,” inEuropean conference on computer vision. Springer, 2022, pp. 341– 357
2022
-
[4]
Seqtrack: Sequence to sequence learning for visual object tracking,
X. Chen, H. Peng, D. Wang, H. Lu, and H. Hu, “Seqtrack: Sequence to sequence learning for visual object tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 14 572–14 581
2023
-
[5]
Event- based vision: A survey,
G. Gallego, T. Delbrück, G. Orchard, C. Bartolozzi, B. Taba, A. Censi, S. Leutenegger, A. J. Davison, J. Conradt, K. Daniilidiset al., “Event- based vision: A survey,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 1, pp. 154–180, 2020
2020
-
[6]
Event-guided structured output tracking of fast-moving objects using a celex sensor,
J. Huang, S. Wang, M. Guo, and S. Chen, “Event-guided structured output tracking of fast-moving objects using a celex sensor,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 9, pp. 2413–2417, 2018
2018
-
[7]
Object tracking by jointly exploiting frame and event domain,
J. Zhang, X. Yang, Y . Fu, X. Wei, B. Yin, and B. Dong, “Object tracking by jointly exploiting frame and event domain,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 13 043–13 052
2021
-
[8]
Visevent: Reliable object tracking via collaboration of frame and event flows,
X. Wang, J. Li, L. Zhu, Z. Zhang, Z. Chen, X. Li, Y . Wang, Y . Tian, and F. Wu, “Visevent: Reliable object tracking via collaboration of frame and event flows,”IEEE Transactions on Cybernetics, vol. 54, no. 3, pp. 1997–2010, 2023
1997
-
[9]
Revisiting color-event based tracking: A unified network, dataset, and metric,
C. Tang, X. Wang, J. Huang, B. Jiang, L. Zhu, S. Chen, J. Zhang, Y . Wang, and Y . Tian, “Revisiting color-event based tracking: A unified network, dataset, and metric,”Pattern Recognition, p. 112718, 2025
2025
-
[10]
Long-term frame-event visual tracking: Benchmark dataset and baseline,
X. Wang, J. Huang, S. Wang, C. Tang, B. Jiang, Y . Tian, J. Tang, and B. Luo, “Long-term frame-event visual tracking: Benchmark dataset and baseline,”arXiv e-prints, pp. arXiv–2403, 2024
2024
-
[11]
Frame- event alignment and fusion network for high frame rate tracking,
J. Zhang, Y . Wang, W. Liu, M. Li, J. Bai, B. Yin, and X. Yang, “Frame- event alignment and fusion network for high frame rate tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 9781–9790
2023
-
[12]
Cross-modal orthogonal high-rank augmentation for rgb-event transformer-trackers,
Z. Zhu, J. Hou, and D. O. Wu, “Cross-modal orthogonal high-rank augmentation for rgb-event transformer-trackers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 045–22 055
2023
-
[13]
Visual prompt multi- modal tracking,
J. Zhu, S. Lai, X. Chen, D. Wang, and H. Lu, “Visual prompt multi- modal tracking,” inProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, 2023, pp. 9516–9526
2023
-
[14]
Distractor-aware event-based tracking,
Y . Fu, M. Li, W. Liu, Y . Wang, J. Zhang, B. Yin, X. Wei, and X. Yang, “Distractor-aware event-based tracking,”IEEE Transactions on Image Processing, vol. 32, pp. 6129–6141, 2023
2023
-
[15]
Revisiting motion information for rgb-event tracking with mot philosophy,
T. Zhang, K. Debattista, Q. Zhang, G. Ding, and J. Han, “Revisiting motion information for rgb-event tracking with mot philosophy,” in Advances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[16]
Exploring historical information for rgbe visual tracking with mamba,
C. Sun, J. Zhang, Y . Wang, H. Ge, Q. Xia, B. Yin, and X. Yang, “Exploring historical information for rgbe visual tracking with mamba,” inProceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 6500–6509
2025
-
[17]
Hopfield networks is all you need,
H. Ramsauer, B. Schäfl, J. Lehner, P. Seidl, M. Widrich, T. Adler, L. Gruber, M. Holzleitner, M. Pavlovi ´c, G. K. Sandveet al., “Hopfield networks is all you need,”arXiv preprint arXiv:2008.02217, 2020
Pith/arXiv arXiv 2008
-
[18]
Event stream-based visual object tracking: A high-resolution bench- mark dataset and a novel baseline,
X. Wang, S. Wang, C. Tang, L. Zhu, B. Jiang, Y . Tian, and J. Tang, “Event stream-based visual object tracking: A high-resolution bench- mark dataset and a novel baseline,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 248–19 257
2024
-
[19]
Single-model and any-modality for video object tracking,
Z. Wu, J. Zheng, X. Ren, F.-A. Vasluianu, C. Ma, D. P. Paudel, L. Van Gool, and R. Timofte, “Single-model and any-modality for video object tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 19 156–19 166
2024
-
[20]
Sutrack: Towards simple and unified single object tracking,
X. Chen, B. Kang, W. Geng, J. Zhu, Y . Liu, D. Wang, and H. Lu, “Sutrack: Towards simple and unified single object tracking,”arXiv preprint arXiv:2412.19138, 2024
arXiv 2024
-
[21]
Sdstrack: Self-distillation symmetric adapter learning for multi-modal visual object tracking,
X. Hou, J. Xing, Y . Qian, Y . Guo, S. Xin, J. Chen, K. Tang, M. Wang, Z. Jiang, L. Liuet al., “Sdstrack: Self-distillation symmetric adapter learning for multi-modal visual object tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 551–26 561
2024
-
[22]
Xtrack: Multimodal training boosts rgb- x video object trackers,
Y . Tan, Z. Wu, Y . Fu, Z. Zhou, G. Sun, E. Zamfi, C. Ma, D. P. Paudel, L. Van Gool, and R. Timofte, “Xtrack: Multimodal training boosts rgb- x video object trackers,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 5734–5744
2025
-
[23]
Mamba-fetrack v2: Revisiting state space model for frame- event based visual object tracking,
S. Wang, J. Huang, Q. Ma, J. Gao, C. Xu, X. Wang, L. Chen, and B. Jiang, “Mamba-fetrack v2: Revisiting state space model for frame- event based visual object tracking,”arXiv preprint arXiv:2506.23783, 2025
arXiv 2025
-
[24]
Missing modality imagination network for emotion recognition with uncertain missing modalities,
J. Zhao, R. Li, and Q. Jin, “Missing modality imagination network for emotion recognition with uncertain missing modalities,” inProceedings IEEE TRANSACTIONS ON ***, 2026 13 of the AAAI Conference on Artificial Intelligence, vol. 35, no. 6, 2021, pp. 5680–5688
2026
-
[25]
Smil: Multimodal learning with severely missing modality,
M. Ma, J. Ren, L. Zhao, S. Tulyakov, C. Wu, and X. Peng, “Smil: Multimodal learning with severely missing modality,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 3, 2021, pp. 2302–2310
2021
-
[26]
Multimodal prompt- ing with missing modalities for visual recognition,
Y .-L. Lee, Y .-H. Tsai, W.-C. Chiu, and C.-Y . Lee, “Multimodal prompt- ing with missing modalities for visual recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 14 943–14 952
2023
-
[27]
Multi-modal learning with missing modality via shared-specific feature modelling,
H. Wang, Y . Chen, C. Ma, J. Avery, L. Hull, and G. Carneiro, “Multi-modal learning with missing modality via shared-specific feature modelling,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15 878–15 887
2023
-
[28]
Re- covering coherent affective patterns: Addressing modality missing in multimodal sentiment analysis,
H. Huang, T. Gong, K. He, W. Wen, W. Zhang, and M. Feng, “Re- covering coherent affective patterns: Addressing modality missing in multimodal sentiment analysis,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 26, 2026, pp. 21 957–21 965
2026
-
[29]
Rag4dmc: Retrieval-augmented generation for data-level modality completion,
N. He, Y . Deng, S. Yue, Y . Fu, Z. Zhang, and T. Gao, “Rag4dmc: Retrieval-augmented generation for data-level modality completion,” in International Conference on Learning Representations, 2026
2026
-
[30]
Mora: Missing modality low-rank adaptation for visual recognition,
S. Zhao, N. Ahuja, T. Yu, T. Shen, and V . Narayanan, “Mora: Missing modality low-rank adaptation for visual recognition,” inInternational Conference on Learning Representations, 2026
2026
-
[31]
Miss-reid: Delivering robust multi-modality object re- identification despite missing modalities,
R. Xi, “Miss-reid: Delivering robust multi-modality object re- identification despite missing modalities,” inAdvances in Neural In- formation Processing Systems, vol. 38, 2025
2025
-
[32]
Inference-time dynamic modality selection for incomplete multimodal classification,
S. Du, X. Luo, D. P. O’Regan, and C. Qin, “Inference-time dynamic modality selection for incomplete multimodal classification,” inInter- national Conference on Learning Representations, 2026
2026
-
[33]
Transformer meets tracker: Exploiting temporal context for robust visual tracking,
N. Wang, W. Zhou, J. Wang, and H. Li, “Transformer meets tracker: Exploiting temporal context for robust visual tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 1571–1580
2021
-
[34]
Learning target candidate association to keep track of what not to track,
C. Mayer, M. Danelljan, D. P. Paudel, and L. Van Gool, “Learning target candidate association to keep track of what not to track,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 13 444–13 454
2021
-
[35]
Hiptrack: Visual tracking with historical prompts,
W. Cai, Q. Liu, and Y . Wang, “Hiptrack: Visual tracking with historical prompts,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 258–19 267
2024
-
[36]
Odtrack: Online dense temporal token learning for visual tracking,
Y . Zheng, B. Zhong, Q. Liang, Z. Mo, S. Zhang, and X. Li, “Odtrack: Online dense temporal token learning for visual tracking,” inProceed- ings of the AAAI conference on artificial intelligence, vol. 38, no. 7, 2024, pp. 7588–7596
2024
-
[37]
Autoregressive queries for adaptive tracking with spatio-temporal trans- formers,
J. Xie, B. Zhong, Z. Mo, S. Zhang, L. Shi, S. Song, and R. Ji, “Autoregressive queries for adaptive tracking with spatio-temporal trans- formers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 300–19 309
2024
-
[38]
Exploring enhanced contextual information for video-level object tracking,
B. Kang, X. Chen, S. Lai, Y . Liu, Y . Liu, and D. Wang, “Exploring enhanced contextual information for video-level object tracking,” in Proceedings of the AAAI conference on Artificial Intelligence, vol. 39, no. 4, 2025, pp. 4194–4202
2025
-
[39]
Universal hopfield networks: A general framework for single-shot associative memory models,
B. Millidge, T. Salvatori, Y . Song, T. Lukasiewicz, and R. Bogacz, “Universal hopfield networks: A general framework for single-shot associative memory models,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 15 561–15 583
2022
-
[40]
Adaptive hopfield network: Rethinking similarities in associative memory,
S. Wang, Y . Pan, Z. Shen, M. Zhang, H. Wang, and G. Li, “Adaptive hopfield network: Rethinking similarities in associative memory,” in International Conference on Learning Representations, 2026
2026
-
[41]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[42]
Cloob: Modern hopfield networks with infoloob outperform clip,
A. Fürst, E. Rumetshofer, J. Lehner, V . T. Tran, F. Tang, H. Ramsauer, D. Kreil, M. Kopp, G. Klambauer, A. Bittoet al., “Cloob: Modern hopfield networks with infoloob outperform clip,”Advances in neural information processing systems, vol. 35, pp. 20 450–20 468, 2022
2022
-
[43]
Outlier-efficient hopfield layers for large transformer-based models,
J. Y .-C. Hu, P.-H. Chang, R. Luo, H.-Y . Chen, W. Li, W.-P. Wang, and H. Liu, “Outlier-efficient hopfield layers for large transformer-based models,”arXiv preprint arXiv:2404.03828, 2024
arXiv 2024
-
[44]
Beyond scaling laws: Understand- ing transformer performance with associative memory,
X. Niu, B. Bai, L. Deng, and W. Han, “Beyond scaling laws: Understand- ing transformer performance with associative memory,”arXiv preprint arXiv:2405.08707, 2024
arXiv 2024
-
[45]
Exploiting memory-aware q-distribution prediction for nuclear fusion via modern hopfield network,
Q. Ma, S. Wang, T. Zheng, X. Dai, Y . Wang, Q. Yang, and X. Wang, “Exploiting memory-aware q-distribution prediction for nuclear fusion via modern hopfield network,” inInternational Conference on Brain Inspired Cognitive Systems. Springer, 2024, pp. 104–114
2024
-
[46]
Conformal prediction for time series with modern hopfield networks,
A. Auer, M. Gauch, D. Klotz, and S. Hochreiter, “Conformal prediction for time series with modern hopfield networks,”Advances in neural information processing systems, vol. 36, pp. 56 027–56 074, 2023
2023
-
[47]
Stanhop: Sparse tandem hopfield model for memory-enhanced time series prediction,
Y .-H. Wu, J. Y .-C. Hu, W. Li, B.-Y . Chen, and H. Liu, “Stanhop: Sparse tandem hopfield model for memory-enhanced time series prediction,” in International Conference on Learning Representations, vol. 2024, 2024, pp. 30 886–30 925
2024
-
[48]
Unsupervised domain adaptation by back- propagation,
Y . Ganin and V . Lempitsky, “Unsupervised domain adaptation by back- propagation,”Proceedings of the International Conference on Machine Learning, pp. 1180–1189, 2015
2015
-
[49]
Categorical reparameterization with gumbel-softmax,
E. Jang, S. Gu, and B. Poole, “Categorical reparameterization with gumbel-softmax,”International Conference on Learning Representa- tions, 2017
2017
-
[50]
The concrete distribution: A continuous relaxation of discrete random variables,
C. J. Maddison, A. Mnih, and Y . W. Teh, “The concrete distribution: A continuous relaxation of discrete random variables,”International Conference on Learning Representations, 2017
2017
-
[51]
Generalized intersection over union: A metric and a loss for bounding box regression,
H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, and S. Savarese, “Generalized intersection over union: A metric and a loss for bounding box regression,” inProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, 2019, pp. 658–666
2019
-
[52]
Cornernet: Detecting objects as paired keypoints,
H. Law and J. Deng, “Cornernet: Detecting objects as paired keypoints,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 734–750
2018
-
[53]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[54]
Hivit: A simpler and more efficient design of hierarchical vision transformer,
X. Zhang, Y . Tian, L. Xie, W. Huang, Q. Dai, Q. Ye, and Q. Tian, “Hivit: A simpler and more efficient design of hierarchical vision transformer,” inThe eleventh international conference on learning representations, 2023
2023
-
[55]
Siamese box adaptive network for visual tracking,
Z. Chen, B. Zhong, G. Li, S. Zhang, and R. Ji, “Siamese box adaptive network for visual tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6668–6677
2020
-
[56]
Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines,
Y . Xu, Z. Wang, Z. Li, Y . Yuan, and G. Yu, “Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 12 549–12 556
2020
-
[57]
Know your surroundings: Exploiting scene information for object tracking,
G. Bhat, M. Danelljan, L. Van Gool, and R. Timofte, “Know your surroundings: Exploiting scene information for object tracking,” in European conference on computer vision. Springer, 2020, pp. 205– 221
2020
-
[58]
Clnet: A compact latent network for fast adjusting siamese trackers,
X. Dong, J. Shen, L. Shao, and F. Porikli, “Clnet: A compact latent network for fast adjusting siamese trackers,” inEuropean conference on computer vision. Springer, 2020, pp. 378–395
2020
-
[59]
Atom: Accurate tracking by overlap maximization,
M. Danelljan, G. Bhat, F. S. Khan, and M. Felsberg, “Atom: Accurate tracking by overlap maximization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4660– 4669
2019
-
[60]
Learning discrim- inative model prediction for tracking,
G. Bhat, M. Danelljan, L. V . Gool, and R. Timofte, “Learning discrim- inative model prediction for tracking,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6182–6191
2019
-
[61]
Probabilistic regression for visual tracking,
M. Danelljan, L. V . Gool, and R. Timofte, “Probabilistic regression for visual tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 7183–7192
2020
-
[62]
Learning spatio-temporal transformer for visual tracking,
B. Yan, H. Peng, J. Fu, D. Wang, and H. Lu, “Learning spatio-temporal transformer for visual tracking,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 448–10 457
2021
-
[63]
Aiatrack: Attention in attention for transformer visual tracking,
S. Gao, C. Zhou, C. Ma, X. Wang, and J. Yuan, “Aiatrack: Attention in attention for transformer visual tracking,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 146–164
2022
-
[64]
Transforming model prediction for tracking,
C. Mayer, M. Danelljan, G. Bhat, M. Paul, D. P. Paudel, F. Yu, and L. Van Gool, “Transforming model prediction for tracking,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8731–8740
2022
-
[65]
Cross-modality distilla- tion for multi-modal tracking,
T. Zhang, Q. Zhang, K. Debattista, and J. Han, “Cross-modality distilla- tion for multi-modal tracking,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[66]
Less is more: Token context-aware learning for object tracking,
C. Xu, B. Zhong, Q. Liang, Y . Zheng, G. Li, and S. Song, “Less is more: Token context-aware learning for object tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 8, 2025, pp. 8824–8832
2025
-
[67]
Fully spiking neural networks for unified frame-event object tracking,
J. Yang, L. Fan, J. Zhang, X. Lian, H. Shen, and D. Hu, “Fully spiking neural networks for unified frame-event object tracking,” vol. 38, 2026, pp. 121 132–121 163. IEEE TRANSACTIONS ON ***, 2026 14
2026
-
[68]
Utptrack: Towards simple and unified token pruning for visual tracking,
H. Wu, X. Wang, J. Zhang, J. Tong, X. Chen, J. Lin, Y . Ma, and X. Shen, “Utptrack: Towards simple and unified token pruning for visual tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 20 963–20 972
2026
-
[69]
Lastracker: A lightweight rgb-e tracking framework with ann-snn adaptive switching,
Z. Wang, S. Liu, H. Zheng, S. Wang, Y . Hu, H. Fan, Y . Li, H. Guo, and L. Deng, “Lastracker: A lightweight rgb-e tracking framework with ann-snn adaptive switching,”Pattern Recognition, p. 113623, 2026
2026
-
[70]
Siamcar: Siamese fully convolutional classification and regression for visual tracking,
D. Guo, J. Wang, Y . Cui, Z. Wang, and S. Chen, “Siamcar: Siamese fully convolutional classification and regression for visual tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6269–6277
2020
-
[71]
Siam r-cnn: Visual tracking by re-detection,
P. V oigtlaender, J. Luiten, P. H. Torr, and B. Leibe, “Siam r-cnn: Visual tracking by re-detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6578–6588
2020
-
[72]
Seatrack: Simple, efficient, and adaptive multimodal tracker,
J. Su, Z. Xue, S. Zhang, K. Chen, W. Hu, and Z. Zhang, “Seatrack: Simple, efficient, and adaptive multimodal tracker,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 28 679–28 689
2026
-
[73]
Backbone is all your need: A simplified architecture for visual object tracking,
B. Chen, P. Li, L. Bai, L. Qiao, Q. Shen, B. Li, W. Gan, W. Wu, and W. Ouyang, “Backbone is all your need: A simplified architecture for visual object tracking,” inEuropean conference on computer vision. Springer, 2022, pp. 375–392
2022
-
[74]
Generalized relation modeling for transformer tracking,
S. Gao, C. Zhou, and J. Zhang, “Generalized relation modeling for transformer tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 18 686–18 695
2023
-
[75]
Robust object modeling for visual tracking,
Y . Cai, J. Liu, J. Tang, and G. Wu, “Robust object modeling for visual tracking,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 9589–9600
2023
-
[76]
Artrackv2: Prompting autore- gressive tracker where to look and how to describe,
Y . Bai, Z. Zhao, Y . Gong, and X. Wei, “Artrackv2: Prompting autore- gressive tracker where to look and how to describe,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 19 048–19 057
2024
-
[77]
Explicit visual prompts for visual object tracking,
L. Shi, B. Zhong, Q. Liang, N. Li, S. Zhang, and X. Li, “Explicit visual prompts for visual object tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 5, 2024, pp. 4838– 4846
2024
-
[78]
Exploring the feature extraction and relation modeling for light-weight transformer tracking,
J. Zheng, M. Liang, S. Huang, and J. Ning, “Exploring the feature extraction and relation modeling for light-weight transformer tracking,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 110– 126
2024
-
[79]
Two- stream beats one-stream: asymmetric siamese network for efficient visual tracking,
J. Zhu, H. Tang, X. Chen, X. Wang, D. Wang, and H. Lu, “Two- stream beats one-stream: asymmetric siamese network for efficient visual tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 10, 2025, pp. 10 959–10 967
2025
-
[80]
Learning occlusion-robust vision transformers for real-time uav tracking,
Y . Wu, X. Wang, X. Yang, M. Liu, D. Zeng, H. Ye, and S. Li, “Learning occlusion-robust vision transformers for real-time uav tracking,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 103–17 113
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.