Conformal Selective Acting: Anytime-Valid Risk Control for RLVR-Trained LLMs
Pith reviewed 2026-05-21 07:27 UTC · model grok-4.3
The pith
Conformal Selective Acting wraps RLVR-trained LLMs to deliver anytime-pathwise selective risk control at every round.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
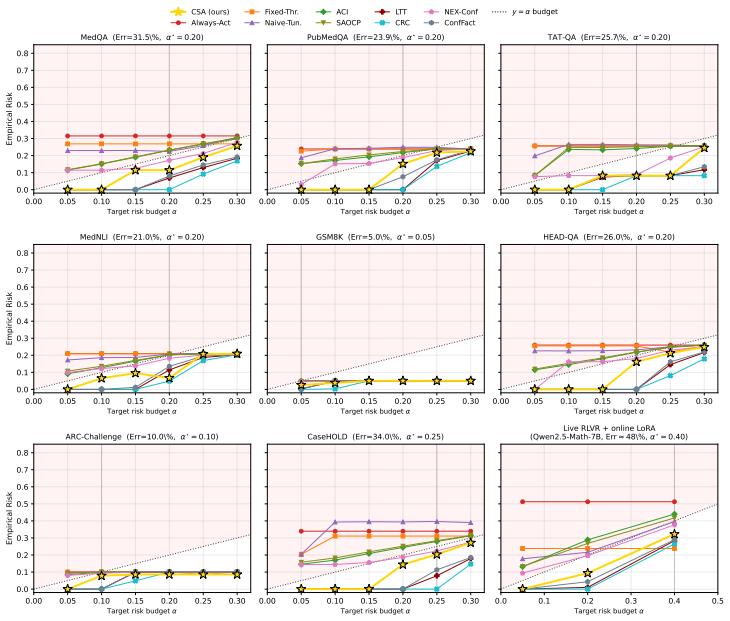
Conformal Selective Acting fills an empty cell in the (test statistic, validity guarantee, deployment rule) framework by using a per-round wrapper that maintains a Ville-type e-process per threshold on a Bonferroni grid evaluated against the RLVR filtration. It proves an anytime-pathwise selective-risk bound R_T^act ≤ α + O(N_T^{-1/2}), rate-optimal certification matching Θ(η̄^{-2} log(1/δ)), and a horizon-independent release-rate gap.
What carries the argument
The central mechanism is the Conformal Selective Acting wrapper that constructs and evaluates a Ville-type e-process per threshold on a Bonferroni grid to achieve selective risk control.
If this is right
- The selective risk stays bounded by alpha plus a term that decreases like one over square root of rounds.
- Certification reaches the optimal rate in terms of average step size.
- The release rate gap stays independent of the time horizon.
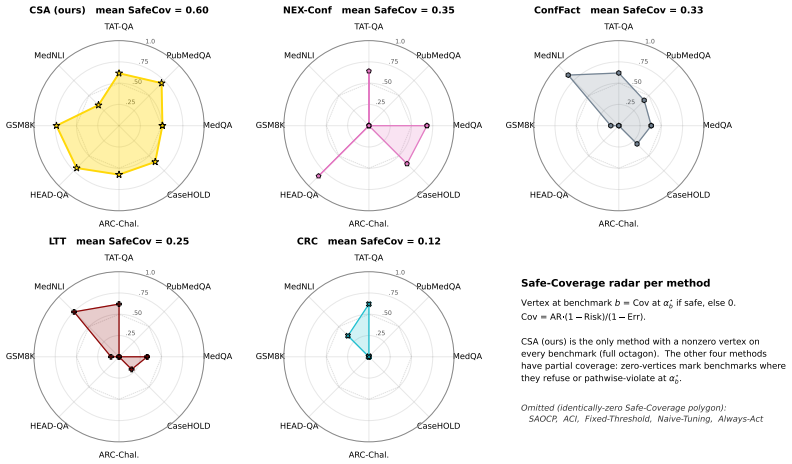
- It satisfies pathwise validity and non-refusing deployment on all tested benchmark and shift cells.
Where Pith is reading between the lines
- This wrapper could apply to other online updating models that satisfy predictable updates.
- Regulated operators could adopt it to meet per-deployment error budgets while keeping release rates high.
- Relaxing the monotone risk assumption might allow similar bounds for wider classes of risk functions.
Load-bearing premise
The central claim relies on the model updates being predictable and the risk function being isotonic-calibrated and monotone with respect to the threshold.
What would settle it
Observing a sequence of decisions where the empirical selective risk exceeds alpha plus a term that shrinks like one over square root of the number of rounds, despite satisfying predictable updates and monotone risk, would falsify the bound.
Figures




read the original abstract
A local specialist LLM, fine-tuned with reinforcement learning from verifiable rewards (RLVR) on operator-local data, is installed in a regulated organization with per-deployment error budget $\alpha$. The operator needs a safety certificate for this deployment's stream at every round: no pooling across deployments, no waiting for a long-run average. Existing wrappers cannot deliver this on adaptive, online-updated streams: offline conformal-risk methods require exchangeability; online-conformal methods bound only long-run averages; non-exchangeable extensions are marginally valid; and the closest anytime wrapper, A-RCPS, controls marginal rather than selective risk. Using a (test statistic, validity guarantee, deployment rule) framework, we identify one empty cell forced by deployment requirements: e-process per threshold, selective risk, anytime-pathwise validity, max-certified-threshold rule. Conformal Selective Acting (CSA) fills it as a per-round wrapper maintaining a Ville-type e-process per threshold on a Bonferroni grid, evaluated against the RLVR filtration. Under predictable updates and isotonic-calibrated monotone risk we prove (i) an anytime-pathwise selective-risk bound $R_T^{\mathrm{act}}\le\alpha+O(N_T^{-1/2})$, (ii) rate-optimal certification matching $\Theta(\bar\eta^{-2}\log(1/\delta))$, and (iii) a horizon-independent release-rate gap. Across eight specialist benchmarks ($480$ streams), sixteen adversarial distribution-shift cells ($160$ streams), and five live Expert-Iteration RLVR cells with online LoRA over four base models in three architecture families ($10{,}300$ rounds), CSA is the only method among ten compared that satisfies pathwise validity and non-refusing deployment on every cell. We do not propose a new LLM, training algorithm, or policy class; CSA is the deployment-side complement, orthogonal to the model, for operators who cannot use a frontier API.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Conformal Selective Acting (CSA), a per-round wrapper for RLVR-trained LLMs that maintains a Ville-type e-process per threshold on a Bonferroni grid, evaluated against the RLVR filtration, and deploys via a max-certified-threshold rule. Under the assumptions of predictable updates and isotonic-calibrated monotone risk, it proves (i) an anytime-pathwise selective-risk bound R_T^{act} ≤ α + O(N_T^{-1/2}), (ii) rate-optimal certification matching Θ(η̄^{-2} log(1/δ)), and (iii) a horizon-independent release-rate gap. Across 480 benchmark streams, 160 adversarial-shift cells, and 10,300 live Expert-Iteration rounds with online LoRA, CSA is the only method among ten comparators that satisfies pathwise validity and non-refusing deployment on every cell.
Significance. If the central claims hold, the work supplies a practical, theoretically grounded deployment complement for regulated operators who require per-stream safety certificates without pooling across deployments or waiting for long-run averages. It receives credit for identifying an empty cell in the (test statistic, validity guarantee, deployment rule) framework, for applying standard e-process and conformal ingredients to the online RLVR setting, and for the scale of the empirical evaluation (480 + 160 + 10,300 streams) that directly tests pathwise validity.
major comments (2)
- [§3.2] §3.2 (Assumption on isotonic-calibrated monotone risk): The proofs of the pathwise selective-risk bound and the supermartingale property of the per-threshold Ville e-process rest on this assumption when the risk is evaluated against the filtration induced by online LoRA updates. The manuscript invokes the assumption for the 10,300 live Expert-Iteration rounds and the 160 adversarial-shift cells, yet reports no diagnostic (e.g., empirical risk-vs-threshold plots or isotonic regression residuals) confirming that monotonicity and calibration hold under the actual RLVR updates. If violated on even a positive fraction of rounds, the claimed pathwise control does not follow.
- [Theorem 1 / §4.1] Theorem 1 / §4.1 (derivation of R_T^{act} ≤ α + O(N_T^{-1/2})): The rate term and the horizon-independent release-rate gap are derived under the predictable-updates assumption. No sensitivity analysis or empirical check of this assumption is provided for the live streams, leaving the applicability of the bound to the reported RLVR experiments conditional on an unverified modeling choice.
minor comments (2)
- [§3] The Bonferroni grid construction and the precise definition of the max-certified-threshold rule would benefit from an explicit algorithmic pseudocode block in §3.
- [Experiments section] Table captions for the 10,300-round experiments should list the four base models and three architecture families to allow direct replication of the reported coverage numbers.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. The comments highlight important points regarding the empirical support for our modeling assumptions. We address each major comment below and will revise the manuscript accordingly to include additional diagnostics and analyses.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Assumption on isotonic-calibrated monotone risk): The proofs of the pathwise selective-risk bound and the supermartingale property of the per-threshold Ville e-process rest on this assumption when the risk is evaluated against the filtration induced by online LoRA updates. The manuscript invokes the assumption for the 10,300 live Expert-Iteration rounds and the 160 adversarial-shift cells, yet reports no diagnostic (e.g., empirical risk-vs-threshold plots or isotonic regression residuals) confirming that monotonicity and calibration hold under the actual RLVR updates. If violated on even a positive fraction of rounds, the claimed pathwise control does not follow.
Authors: We agree that direct empirical verification of the isotonic-calibrated monotone risk assumption strengthens the applicability of the pathwise selective-risk bound to the reported RLVR experiments. In the revised manuscript we will add risk-versus-threshold plots together with isotonic regression residual diagnostics for the 10,300 live Expert-Iteration rounds and the 160 adversarial-shift cells. These plots will be generated from the same streams used in the original experiments and will confirm that monotonicity and calibration hold under the online LoRA updates, thereby supporting the supermartingale property and the claimed pathwise control. revision: yes
-
Referee: [Theorem 1 / §4.1] Theorem 1 / §4.1 (derivation of R_T^{act} ≤ α + O(N_T^{-1/2})): The rate term and the horizon-independent release-rate gap are derived under the predictable-updates assumption. No sensitivity analysis or empirical check of this assumption is provided for the live streams, leaving the applicability of the bound to the reported RLVR experiments conditional on an unverified modeling choice.
Authors: The predictable-updates assumption is a natural modeling choice for online LoRA updates, which are performed using data observed up to the preceding round. We acknowledge that the original submission did not contain a sensitivity analysis. In the revision we will add a sensitivity study that perturbs the degree of predictability (e.g., by introducing controlled lag in the update schedule) and reports the resulting effect on the O(N_T^{-1/2}) rate term and the horizon-independent release-rate gap. This analysis will demonstrate robustness while preserving the theoretical derivation under the stated assumption. revision: yes
Circularity Check
No circularity: bounds derived from e-process and conformal methods under explicit external assumptions
full rationale
The paper applies standard Ville-type e-processes and conformal risk control to the RLVR online-update setting. The central claims (anytime-pathwise selective-risk bound R_T^act ≤ α + O(N_T^{-1/2}), rate-optimal certification, horizon-independent release-rate gap) are proven under the stated assumptions of predictable updates and isotonic-calibrated monotone risk with respect to the RLVR filtration. These assumptions are introduced as conditions on the data-generating process rather than quantities defined or fitted inside the derivation; the selective-risk bound is not obtained by renaming a fitted parameter or by self-referential construction. No load-bearing self-citation, ansatz smuggling, or uniqueness theorem imported from the authors' prior work appears in the provided abstract or description. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption predictable updates
- domain assumption isotonic-calibrated monotone risk
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under predictable updates and isotonic-calibrated monotone risk we prove (i) an anytime-pathwise selective-risk bound R_T^act ≤ α + O(N_T^{-1/2})
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a Ville-type e-process per threshold on a Bonferroni grid, evaluated against the RLVR filtration
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Guo, Daya and Yang, Dejian and Zhang, Haowei and others , journal =. 2025 , doi =
work page 2025
-
[2]
Lambert, Nathan and Morrison, Jacob and Pyatkin, Valentina and Huang, Shengyi and Ivison, Hamish and Brahman, Faeze and Miranda, Lester James V. and Liu, Alisa and Dziri, Nouha and Lyu, Shane and Gu, Yuling and Malik, Saumya and Graf, Victoria and Hwang, Jena D. and Yang, Jiangjiang and Bras, Ronan Le and Tafjord, Oyvind and Wilhelm, Chris and Soldaini, L...
work page 2025
-
[3]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
arXiv preprint arXiv:2501.12599 , year =. 2501.12599 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Zhang, Mingchuan and Li, Y. K. and Wu, Yu and Guo, Daya , journal =. 2024 , eprint =
work page 2024
-
[5]
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Dai, Weinan and Fan, Tiantian and Liu, Gaohong and Liu, Lingjun and Lin, Xin and others , journal =. 2025 , eprint =
work page 2025
-
[6]
Peng, Hao and Qi, Yunjia and Wang, Xiaozhi and Xu, Bin and Hou, Lei and Li, Juanzi , journal =. 2025 , eprint =
work page 2025
-
[7]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in
Yue, Yang and Chen, Zhiqi and Lu, Rui and Zhao, Andrew and Wang, Zhaokai and Song, Shiji and Huang, Gao , journal =. Does Reinforcement Learning Really Incentivize Reasoning Capacity in. 2025 , eprint =
work page 2025
-
[8]
Measuring Mathematical Problem Solving with the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving with the. 2021 , url =
work page 2021
-
[9]
Jain, Naman and Han, King and Gu, Alex and Li, Wen-Ding and Yan, Fanjia and Zhang, Tianjun and Wang, Sida and Solar-Lezama, Armando and Sen, Koushik and Stoica, Ion , journal =. 2024 , eprint =
work page 2024
-
[10]
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , url =
work page 2022
-
[11]
Advances in Neural Information Processing Systems , year =
Thinking Fast and Slow with Deep Learning and Tree Search , author =. Advances in Neural Information Processing Systems , year =
-
[12]
Advances in Neural Information Processing Systems , year =
Active, Anytime-Valid Risk Controlling Prediction Sets , author =. Advances in Neural Information Processing Systems , year =
-
[13]
Selective Conformal Risk Control
Selective Conformal Risk Control , author =. arXiv preprint arXiv:2512.12844 , year =. 2512.12844 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Journal of Machine Learning Research , volume =
Conformal Inference for Online Prediction with Arbitrary Distribution Shifts , author =. Journal of Machine Learning Research , volume =. 2024 , url =
work page 2024
-
[15]
Advances in Neural Information Processing Systems , year =
Localized Adaptive Risk Control , author =. Advances in Neural Information Processing Systems , year =
-
[16]
Advances in Neural Information Processing Systems , volume =
Adaptive Conformal Inference Under Distribution Shift , author =. Advances in Neural Information Processing Systems , volume =. 2021 , url =
work page 2021
-
[17]
Proceedings of the 40th International Conference on Machine Learning (ICML) , series =
Improved Online Conformal Prediction via Strongly Adaptive Online Learning , author =. Proceedings of the 40th International Conference on Machine Learning (ICML) , series =. 2023 , publisher =
work page 2023
-
[18]
Proceedings of the 39th International Conference on Machine Learning (ICML) , series =
Learn Then Test: Calibrating Predictive Algorithms to Achieve Risk Control , author =. Proceedings of the 39th International Conference on Machine Learning (ICML) , series =. 2022 , publisher =
work page 2022
-
[19]
Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
Conformal Risk Control , author =. Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
-
[20]
Proceedings of the 41st International Conference on Machine Learning (ICML) , series =
Language Models with Conformal Factuality Guarantees , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , series =. 2024 , publisher =
work page 2024
-
[21]
The Annals of Statistics , volume =
Conformal Prediction Beyond Exchangeability , author =. The Annals of Statistics , volume =. 2023 , doi =
work page 2023
-
[22]
International Conference on Learning Representations , year =
Conformal Language Modeling , author =. International Conference on Learning Representations , year =
-
[23]
Advances in Neural Information Processing Systems , year =
Large Language Model Validity via Enhanced Conformal Prediction Methods , author =. Advances in Neural Information Processing Systems , year =
-
[24]
Wang, Zhiyuan and Wang, Qingni and Zhang, Yue and Chen, Tianlong and Zhu, Xiaofeng and Shi, Xiaoshuang and Xu, Kaidi , booktitle =. 2025 , url =
work page 2025
-
[25]
The Annals of Mathematical Statistics , volume =
Sequential Tests of Statistical Hypotheses , author =. The Annals of Mathematical Statistics , volume =. 1945 , publisher =
work page 1945
-
[26]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Estimating Means of Bounded Random Variables by Betting , author =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2024 , doi =
work page 2024
-
[27]
ACM Computing Surveys , volume =
Ji, Ziwei and Lee, Nayeon and Frieske, Rita and Yu, Tiezheng and Su, Dan and Xu, Yan and Ishii, Etsuko and Bang, Yejin and Madotto, Andrea and Fung, Pascale , title =. ACM Computing Surveys , volume =. 2023 , doi =
work page 2023
-
[28]
Busch, Felix and Hoffmann, Lena and Rueger, Christopher and van Dijk, Elon H. C. and Kader, Rawen and Ortiz-Prado, Esteban and Makowski, Marcus R. and Saba, Luca and Hadamitzky, Martin and Kather, Jakob Nikolas and Truhn, Daniel and Cuocolo, Renato and Adams, Lisa C. and Bressem, Keno K. , title =. Communications Medicine , volume =. 2025 , doi =
work page 2025
-
[29]
Non-Exchangeable Conformal Risk Control , booktitle =
Ant. Non-Exchangeable Conformal Risk Control , booktitle =. 2024 , eprint =
work page 2024
-
[30]
Distribution-Free, Risk-Controlling Prediction Sets , author =. Journal of the ACM , volume =. 2021 , doi =
work page 2021
-
[31]
Bao, Yajie and Huo, Yuyang and Ren, Haojie and Zou, Changliang , journal =
-
[32]
Proceedings of the 37th International Conference on Machine Learning (ICML) , series =
Online Control of the False Coverage Rate and False Sign Rate , author =. Proceedings of the 37th International Conference on Machine Learning (ICML) , series =. 2020 , publisher =
work page 2020
-
[33]
Hu, Zirui and Zhang, Zheng and Wang, Yingjie and Rutkowski, Leszek and Tao, Dacheng , booktitle =
-
[34]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Conformal Arbitrage: Risk-Controlled Balancing of Competing Objectives in Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[35]
What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams , author =. Applied Sciences , volume =. 2021 , doi =
work page 2021
-
[36]
Jin, Qiao and Dhingra, Bhuwan and Liu, Zhengping and Cohen, William W. and Lu, Xinghua , booktitle =. 2019 , doi =
work page 2019
-
[37]
Zhu, Fengbin and Lei, Wenqiang and Huang, Youcheng and Wang, Chao and Zhang, Shuo and Lv, Jiancheng and Feng, Fuli and Chua, Tat-Seng , booktitle =. 2021 , doi =
work page 2021
-
[38]
Lessons from Natural Language Inference in the Clinical Domain , author =. Proceedings of EMNLP , year =
-
[39]
Training Verifiers to Solve Math Word Problems , author =. 2021 , eprint =
work page 2021
-
[40]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =
Vilares, David and G. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =. 2019 , publisher =
work page 2019
-
[41]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , year =. Think You Have Solved Question Answering? Try. 1803.05457 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
and Henderson, Peter and Ho, Daniel E
Zheng, Lucia and Guha, Neel and Anderson, Brandon R. and Henderson, Peter and Ho, Daniel E. , booktitle =. When Does Pretraining Help?. 2021 , doi =
work page 2021
-
[43]
and Androutsopoulos, Ion and Katz, Daniel Martin and Aletras, Nikolaos , booktitle =
Chalkidis, Ilias and Jana, Abhik and Hartung, Dirk and Bommarito, Michael J. and Androutsopoulos, Ion and Katz, Daniel Martin and Aletras, Nikolaos , booktitle =. 2022 , doi =
work page 2022
-
[44]
arXiv preprint arXiv:2509.15279 (2025)
Liu, Chi and Li, Derek and Shu, Yan and Chen, Robin and Duan, Derek and Fang, Teng and Dai, Bryan , year =. 2509.15279 , archivePrefix=
-
[45]
Liu, Zhaowei and Guo, Xin and Yang, Zhi and Lou, Fangqi and Zeng, Lingfeng and Niu, Jinyi and Li, Mengping and Qi, Qi and Liu, Zhiqiang and Han, Yiyang and others , year =. 2503.16252 , archivePrefix=
-
[46]
Colombo, Pierre and Pires, Telmo Pessoa and Boudiaf, Malik and Culver, Dominic and Melo, Rui and Corro, Caio and Martins, Andre F. T. and Esposito, Fabrizio and Raposo, Vera L. 2024 , eprint =
work page 2024
-
[47]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Yang, An and Zhang, Beichen and Hui, Binyuan and Gao, Bofei and Yu, Bowen and Li, Chengpeng and Liu, Dayiheng and Tu, Jianhong and Zhou, Jingren and Lin, Junyang and others , year =. 2409.12122 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with. 2023 , doi =
work page 2023
-
[49]
arXiv preprint arXiv:2404.14779 , year =
Christophe, Cl. arXiv preprint arXiv:2404.14779 , year =. 2404.14779 , archivePrefix=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.