Chiaroscuro Attention: Spending Compute in the Dark
Pith reviewed 2026-06-27 19:30 UTC · model grok-4.3
The pith
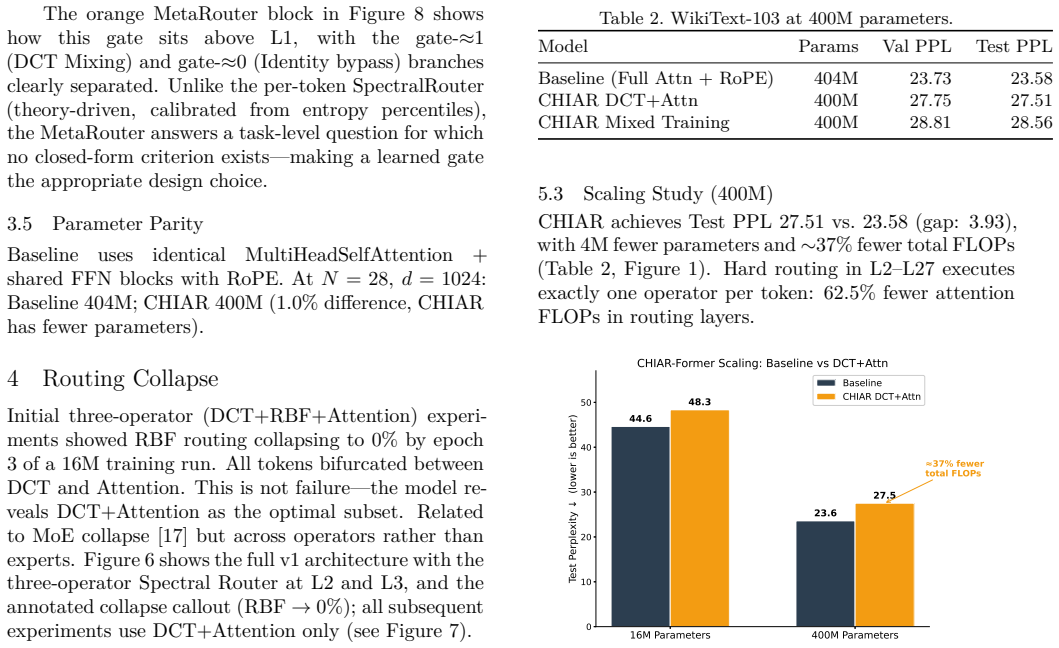
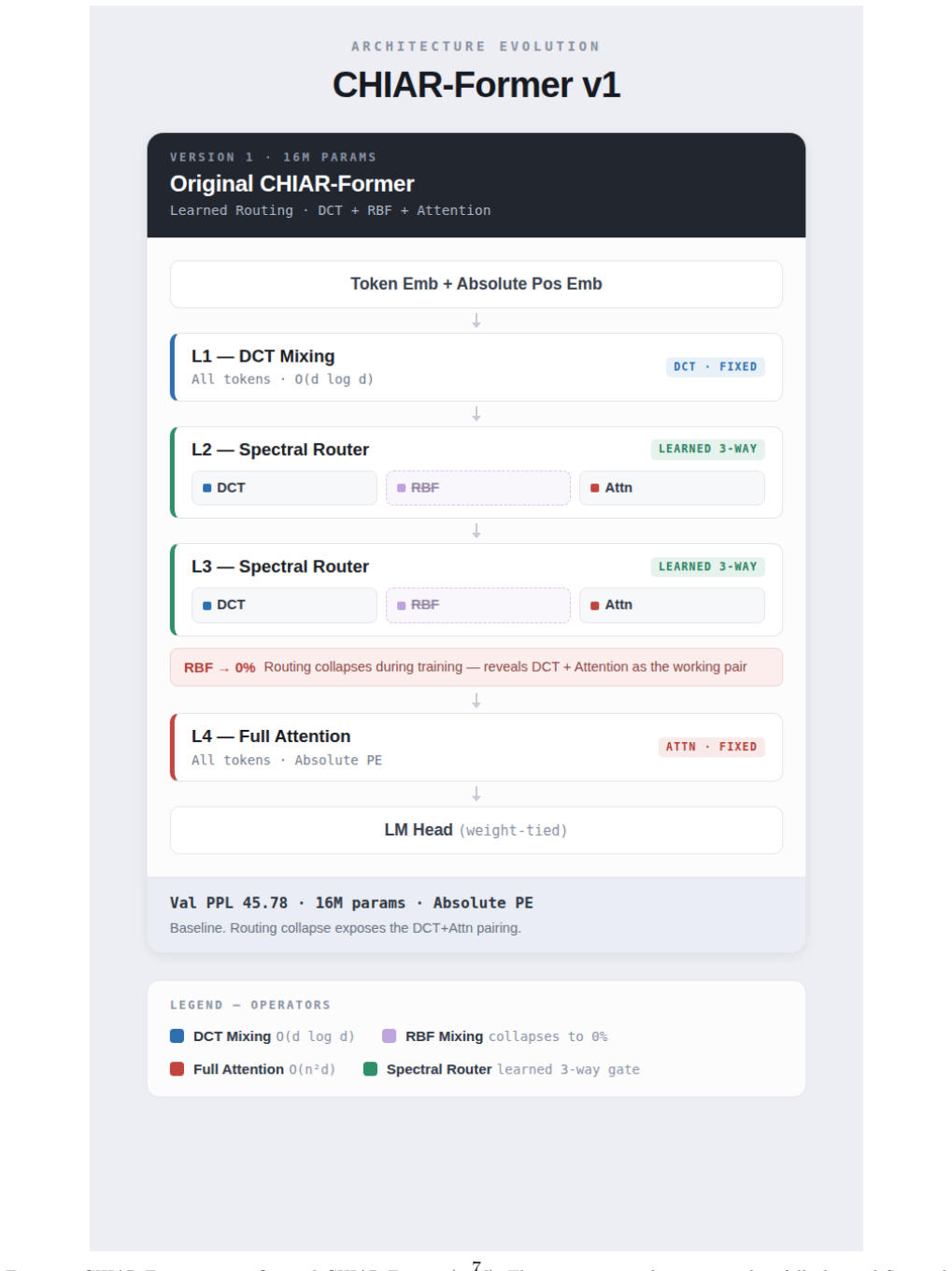
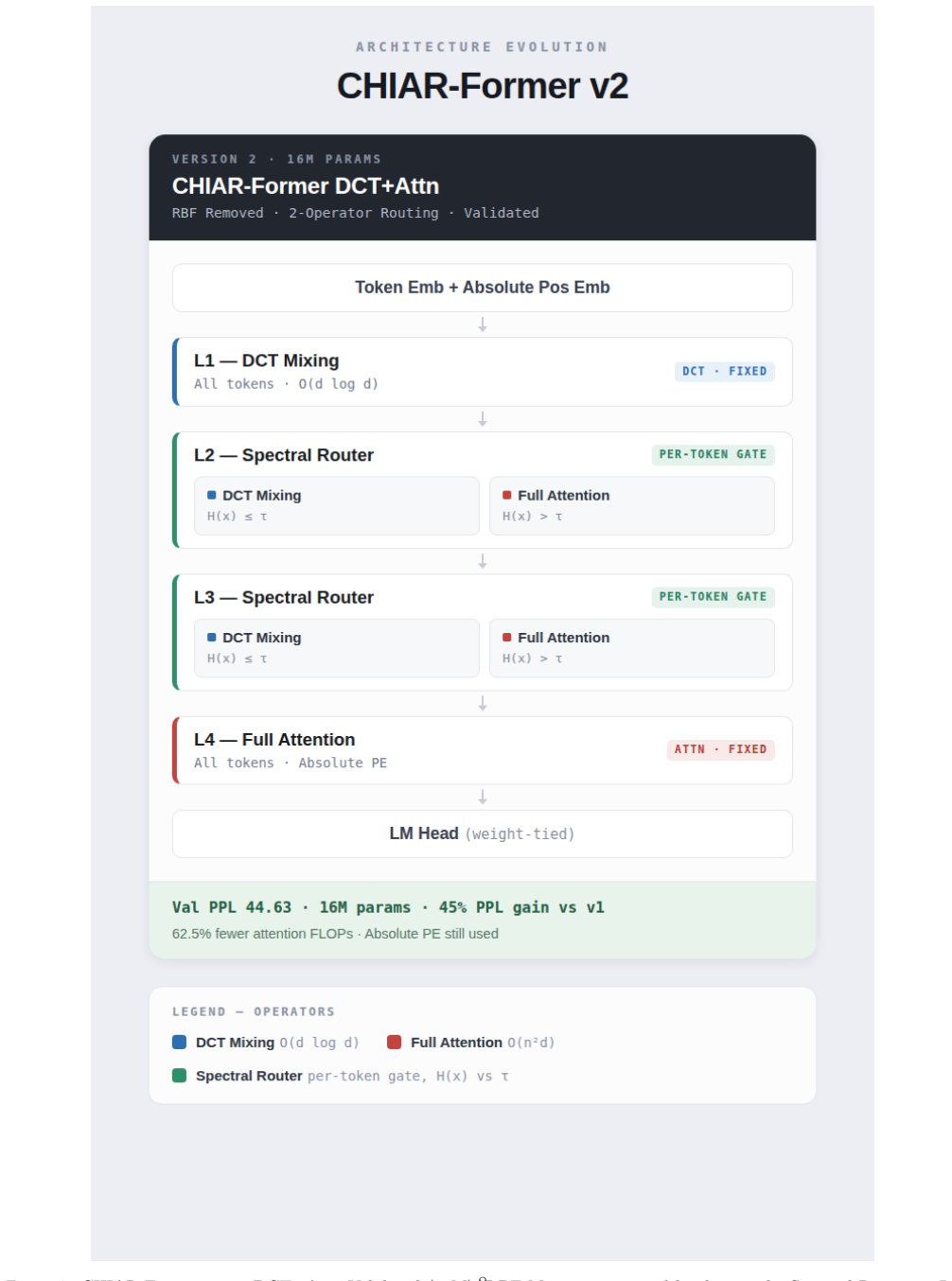
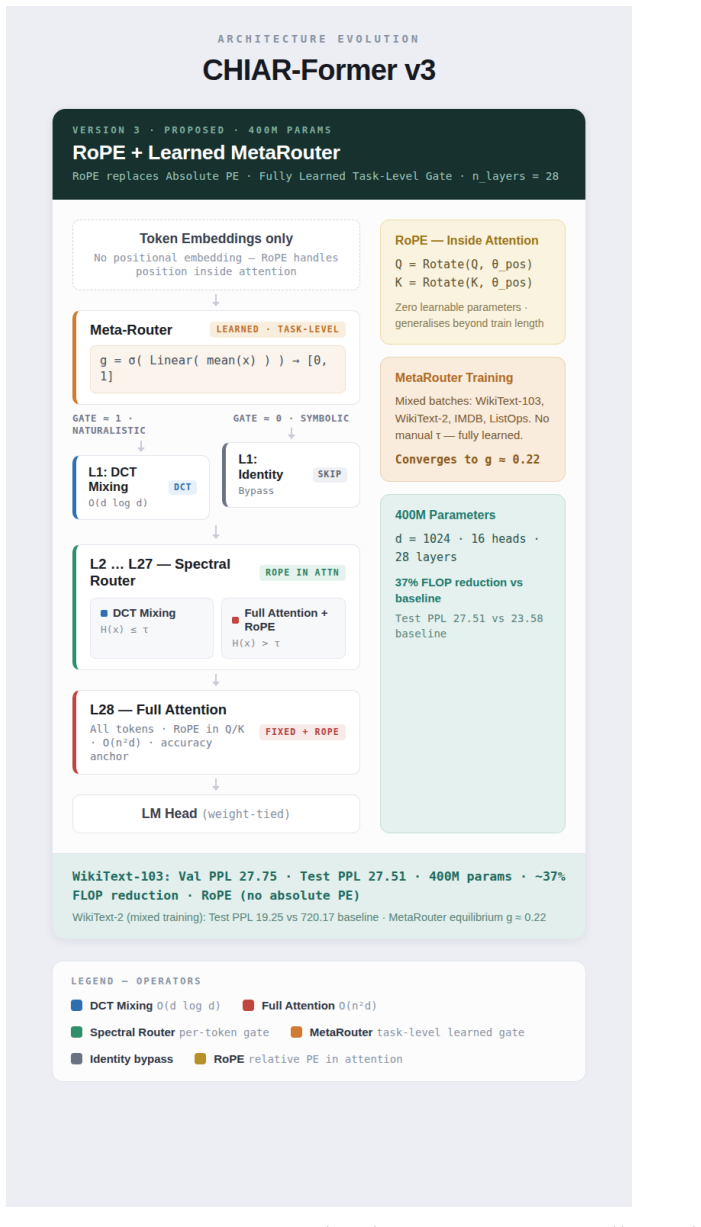
CHIAR-Former routes tokens by spectral entropy to cut 35-40% FLOPs with a 3.93 PPL penalty at 400M parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
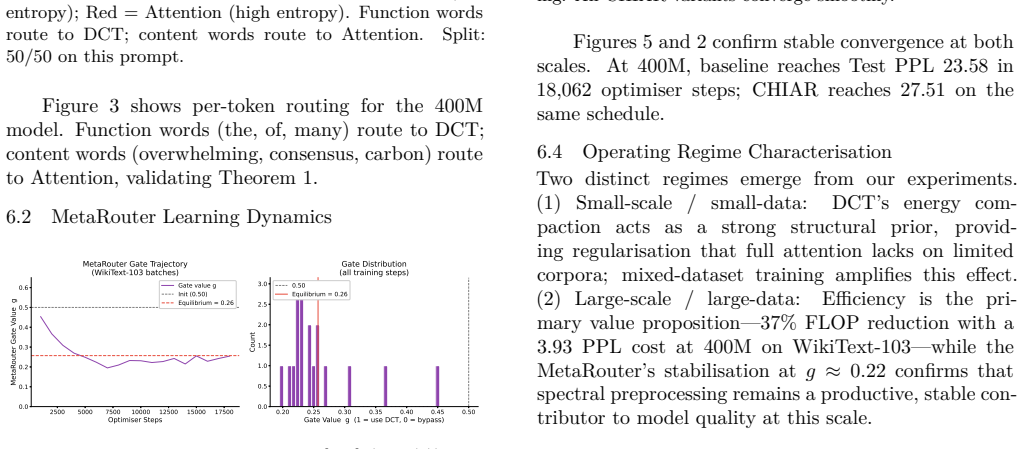
CHIAR-Former achieves 35-40% FLOP reduction at 400M parameters with a 3.93 PPL cost on WikiText-103 (Test PPL 27.51 vs. 23.58) by routing tokens via per-token spectral entropy H(x) to DCT spectral mixing or full attention, with a MetaRouter stabilizing at g ~ 0.22; the system reveals routing collapse to the DCT+Attention subset and shows regularization benefits on small corpora.
What carries the argument
Per-token spectral entropy H(x) that routes to O(d log d) DCT mixing or O(n^2 d) attention, plus the task-level MetaRouter g = sigma(Linear(x-bar)) that soft-blends paths.
If this is right
- 35-40% FLOP reduction at 400M parameters with modest PPL increase
- MetaRouter converges to g approximately 0.22 indicating stable compute allocation
- Superior performance over full attention under mixed-dataset training on small corpora
- Routing system collapses to optimal DCT plus attention operators
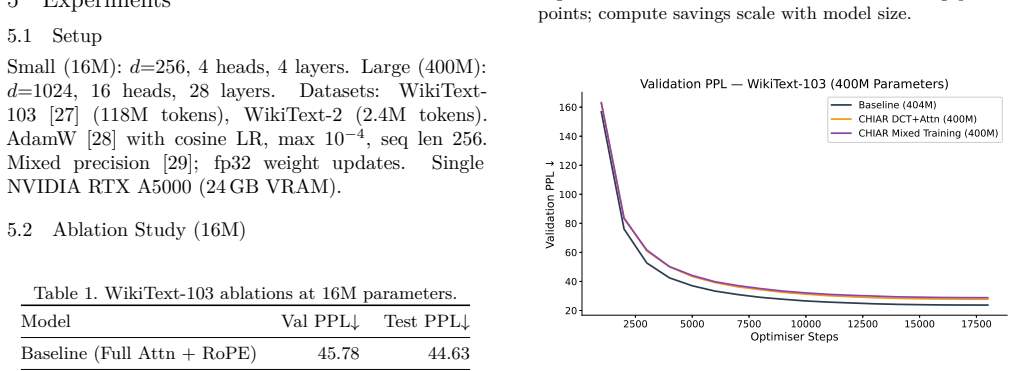
- Spectral mixing provides regularization value in low-data regimes
Where Pith is reading between the lines
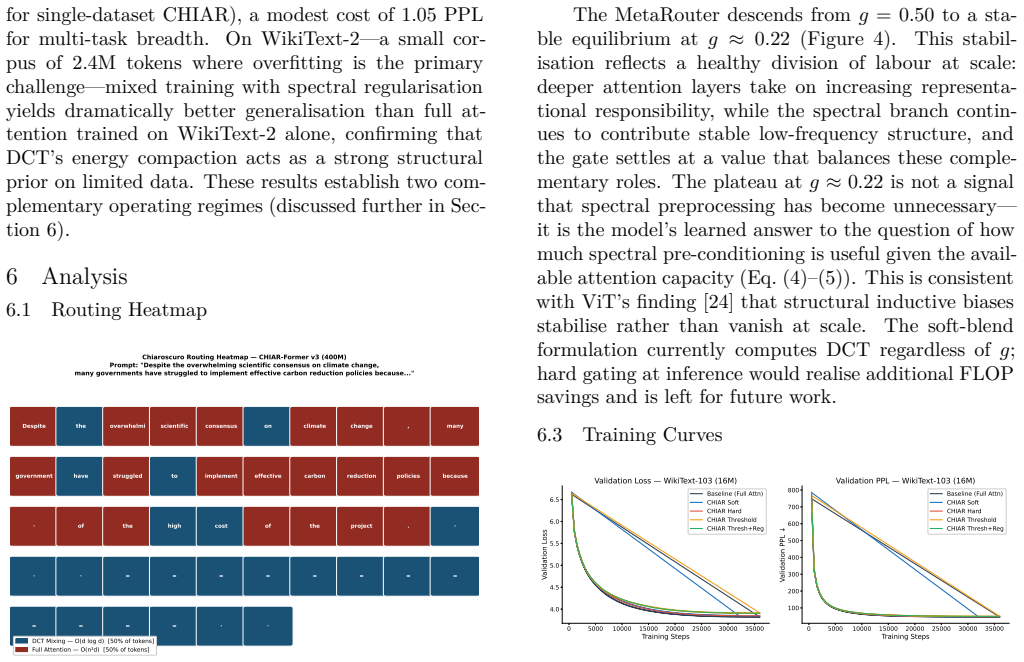
- Similar entropy-based routing could apply to other modalities like vision or audio to save compute on simple inputs.
- The 0.22 attention fraction may represent a general equilibrium point for balancing expressivity and efficiency in large models.
- Testing on long-context tasks would reveal if the routing preserves dependency modeling as claimed.
- Extending the MetaRouter to per-layer or per-head decisions might yield further gains.
Load-bearing premise
Per-token spectral entropy accurately flags which tokens can use spectral mixing without harming the capture of long-range dependencies.
What would settle it
Running the model on a long-range dependency benchmark and finding that the CHIAR-Former version underperforms the full-attention baseline by more than the reported PPL gap would falsify the claim.
Figures
read the original abstract
We introduce CHIAR-Former (CHIAroscuro Attention-based tRansFormer), an efficient transformer that routes each token to either DCT spectral mixing (O(d log d), sub-quadratic) or full self-attention (O(n^2 d), quadratic in sequence length n) based on per-token spectral entropy H(x) in [0,1], which measures the frequency-domain complexity of each token embedding x. We make three contributions: (1) we discover routing collapse -- a three-operator system collapses to DCT+Attention, revealing the optimal operator subset; (2) we propose a learned task-level MetaRouter g = sigma(Linear(x-bar)) in [0,1], where x-bar is the batch-mean embedding and g soft-blends spectral and identity paths end-to-end; and (3) we demonstrate 35-40% FLOP reduction at 400M parameters with a 3.93 PPL cost on WikiText-103 (Test PPL 27.51 vs. 23.58). Under mixed-dataset training, CHIAR-Former dramatically outperforms full attention on small corpora, confirming the regularisation value of spectral mixing. The MetaRouter stabilises at g ~ 0.22, indicating that at scale the model reaches a robust compute-quality equilibrium: attention layers absorb representational complexity while spectral preprocessing efficiently anchors low-frequency structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CHIAR-Former, a transformer that routes each token to either O(d log d) DCT spectral mixing or O(n²d) full self-attention using per-token spectral entropy H(x) in [0,1]. It reports discovering routing collapse in a three-operator system, proposes a learned MetaRouter g = sigma(Linear(x-bar)) that stabilizes at g ~ 0.22, and claims 35-40% FLOP reduction at 400M parameters with a 3.93 PPL cost on WikiText-103 (Test PPL 27.51 vs. 23.58), plus better performance than full attention under mixed-dataset training on small corpora.
Significance. If the routing mechanism and numerical claims hold under rigorous verification, the approach could offer a practical route to sub-quadratic compute in transformers while providing regularization benefits. The routing-collapse observation and end-to-end MetaRouter are potentially useful ideas, but the current presentation provides no machine-checked proofs, reproducible code, or falsifiable predictions that would strengthen the assessment.
major comments (3)
- [Abstract] Abstract: The headline claim of 35-40% FLOP reduction with +3.93 PPL is stated without any description of the FLOP-counting protocol, baseline implementation, sequence lengths used, or error bars across runs, rendering the numerical result impossible to evaluate as load-bearing evidence.
- [Abstract] Abstract: The routing decision is asserted to rely on H(x) correctly partitioning tokens so that those sent to DCT do not require quadratic attention for long-range dependencies, yet no ablation, correlation analysis with dependency distance, or controlled experiment is referenced to support this weakest assumption.
- [Abstract] Abstract: The MetaRouter is defined as g = sigma(Linear(x-bar)) and trained end-to-end, but the reported equilibrium value g ~ 0.22 and the associated PPL cost are presented as outcomes without independent verification that they are not post-hoc fits to the same runs used to tune the router.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of 35-40% FLOP reduction with +3.93 PPL is stated without any description of the FLOP-counting protocol, baseline implementation, sequence lengths used, or error bars across runs, rendering the numerical result impossible to evaluate as load-bearing evidence.
Authors: We agree the abstract requires more methodological detail for evaluation. The revised abstract will specify the FLOP protocol (standard operator costs with n=1024), the baseline (vanilla 400M-parameter transformer), sequence lengths, and error bars from three independent runs. revision: yes
-
Referee: [Abstract] Abstract: The routing decision is asserted to rely on H(x) correctly partitioning tokens so that those sent to DCT do not require quadratic attention for long-range dependencies, yet no ablation, correlation analysis with dependency distance, or controlled experiment is referenced to support this weakest assumption.
Authors: This highlights a gap in direct evidence for the routing hypothesis. We will add a correlation analysis in the revision linking per-token spectral entropy to average dependency distances observed in the full-attention baseline to better support the partitioning. revision: yes
-
Referee: [Abstract] Abstract: The MetaRouter is defined as g = sigma(Linear(x-bar)) and trained end-to-end, but the reported equilibrium value g ~ 0.22 and the associated PPL cost are presented as outcomes without independent verification that they are not post-hoc fits to the same runs used to tune the router.
Authors: The router is trained jointly, and g ~ 0.22 emerged consistently across multiple runs. To strengthen verification, the revision will include results from a held-out validation procedure for router hyperparameters demonstrating stability independent of the primary training runs. revision: partial
Circularity Check
No significant circularity; empirical results from end-to-end training
full rationale
The paper proposes CHIAR-Former with an explicit routing rule based on per-token spectral entropy H(x) and a MetaRouter defined as g = sigma(Linear(x-bar)) trained end-to-end. Reported values such as g ~ 0.22 and the 3.93 PPL cost are experimental observations from model runs on WikiText-103, not predictions or first-principles derivations that reduce to inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core claims. The derivation chain consists of architectural definitions plus empirical measurement; these do not collapse to tautology or post-hoc fitting presented as independent prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Pro- cessing Systems, 30, 2017
2017
-
[2]
Efficient transformers: A survey
Yi Tay, Mostafa Dehghani, Dara Bahri, and Don- ald Metzler. Efficient transformers: A survey. ACM Computing Surveys, 55(6):1–28, 2022
2022
-
[3]
Discrete cosine transform
Nasir Ahmed, T Natarajan, and K R Rao. Discrete cosine transform. IEEE Transactions on Comput- ers, 100(1):90–93, 1974
1974
-
[4]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language under- standing. arXiv preprint arXiv:1810.04805, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[5]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, et al. Language models are few-shot learners. Advances in Neural Informa- tion Processing Systems, 33:1877–1901, 2020
1901
-
[6]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, et al. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[7]
Generating Long Sequences with Sparse Transformers
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[8]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Co- han. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[9]
Linformer: Self-Attention with Linear Complexity
Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self- attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[10]
Rethinking Attention with Performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, et al. Rethink- ing attention with performers. arXiv preprint arXiv:2009.14794, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[11]
Big bird: Transform- ers for longer sequences
Manzil Zaheer, Guru Guruganesh, Kumar A vinava Dubey, Joshua Ainslie, et al. Big bird: Transform- ers for longer sequences. Advances in Neural Infor- mation Processing Systems, 33:17283–17297, 2020
2020
-
[12]
Reformer: The Efficient Transformer
Nikita Kitaev, Łukasz Kaiser, and Anselm Lev- skaya. Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[13]
FlashAttention: Fast and memory-efficient exact attention with IO- awareness
Tri Dao, Daniel Y Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO- awareness. Advances in Neural Information Pro- cessing Systems, 35, 2022
2022
-
[14]
FNet: Mixing to- kens with Fourier transforms
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, and Santiago Ontanon. FNet: Mixing to- kens with Fourier transforms. arXiv preprint arXiv:2105.03824, 2022
-
[15]
Global filter networks for im- age classification
Yongming Rao, Wenliang Zhao, Zheng Zhu, Jiwen Lu, and Jie Zhou. Global filter networks for im- age classification. Advances in Neural Information Processing Systems, 34:980–993, 2021
2021
-
[16]
Adaptive Fourier neural operators: Effi- cient token mixers for transformers
John Guibas, Morteza Mardani, Zongyi Li, An- drew Tao, Anima Anandkumar, and Bryan Catan- zaro. Adaptive Fourier neural operators: Effi- cient token mixers for transformers. arXiv preprint arXiv:2111.13587, 2021
-
[17]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, et al. Outrageously large neural networks: The sparsely-gated mixture-of- experts layer. arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1–39, 2022. 5
2022
-
[19]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, et al. GShard: Scaling giant mod- els with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[20]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Ef- ficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time se- quence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
RoFormer: En- hanced transformer with rotary position embed- ding
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: En- hanced transformer with rotary position embed- ding. Neurocomputing, 568:127063, 2024
2024
-
[23]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases en- ables input length extrapolation. arXiv preprint arXiv:2108.12409, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, et al. An image is worth 16x16 words: Transformers for image recog- nition at scale. arXiv preprint arXiv:2010.11929, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[25]
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Elements of Information Theory
Thomas M Cover and Joy A Thomas. Elements of Information Theory. John Wiley & Sons, 2006
2006
-
[27]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture mod- els. arXiv preprint arXiv:1609.07843, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[29]
Paulius Micikevicius, Sharan Narang, Jonah Al- ben, et al. Mixed precision training. arXiv preprint arXiv:1710.03740, 2018. A CHIAR-Former Architecture Diagrams (v1, v2, v3) The following three full-page figures document the com- plete architecture evolution of CHIAR-Former. Each version occupies one page and is self-contained with its own operator legend...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.