NAVIRA: Decoupled Stochastic Remasking for Masked Diffusion Language Models
Pith reviewed 2026-06-28 01:40 UTC · model grok-4.3
The pith
Decoupling token quality scoring from regeneration improves fluency in masked diffusion language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
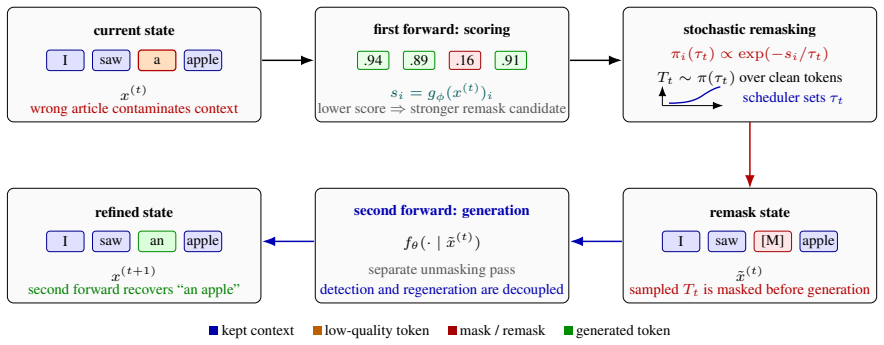
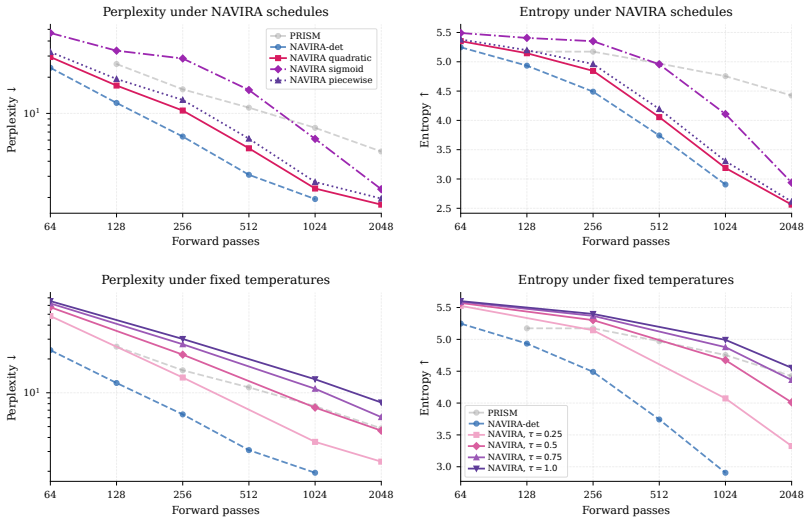
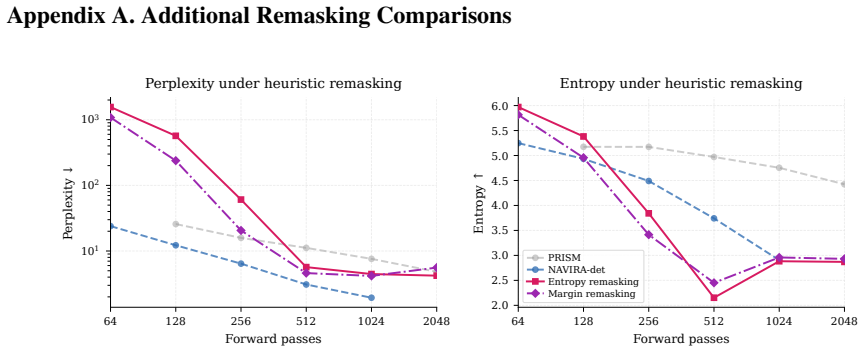
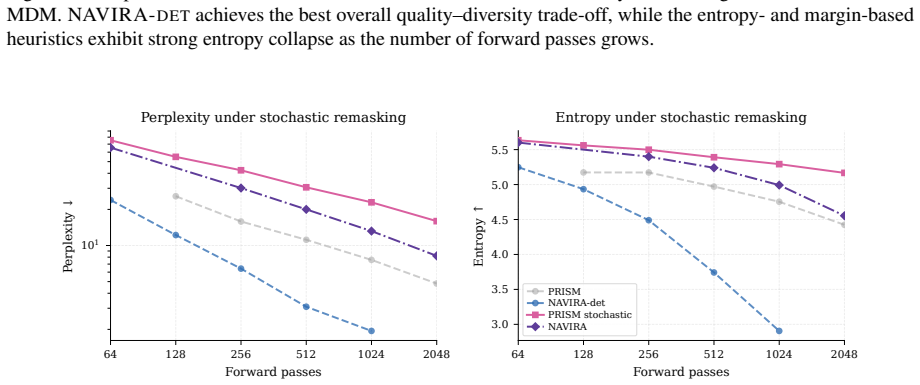
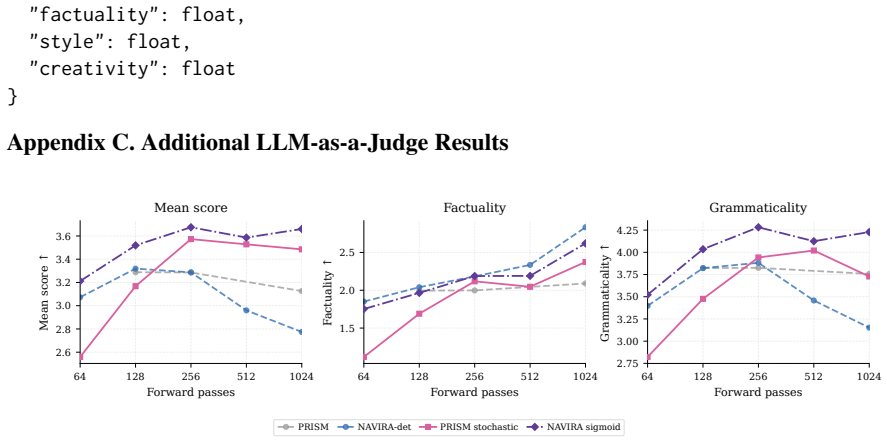
NAVIRA decouples the quality-scoring and regeneration operations plus temperature-controlled stochastic remasking. A first forward pass produces token quality scores; unreliable tokens are masked; a second forward pass then computes replacement logits from the cleaned context. Temperature-controlled stochastic remasking reduces repeated correction of the same positions and balances fluency against diversity. In controlled experiments decoupling improves fluency while scheduled stochastic remasking preserves entropy and achieves stronger LLM-judge scores under larger forward-pass budgets.
What carries the argument
Decoupled two-pass inference with temperature-controlled stochastic remasking, where scoring and logit computation occur in separate forward passes.
If this is right
- Regeneration occurs without the erroneous tokens still in context, reducing error propagation.
- Stochastic rather than deterministic remasking keeps output entropy from collapsing.
- LLM-judge scores rise when the budget allows the extra forward pass required by decoupling.
- Remasking policy itself, not only the learned quality signal, becomes a central lever for generation quality.
Where Pith is reading between the lines
- The same separation of scoring and regeneration passes could be tested on other iterative parallel decoding schemes that suffer from early local errors.
- Gains may depend on how well the quality scorer generalizes across domains or prompt lengths.
- If the two-pass overhead is small, the method could be combined with larger models without retraining.
Load-bearing premise
Token quality scores from the first forward pass reliably identify positions whose regeneration in the second pass will improve the final sequence.
What would settle it
Run the same 170M masked diffusion model with and without the second regeneration pass on identical prompts and check whether LLM-judge preference for the decoupled outputs disappears.
Figures
read the original abstract
Masked diffusion language models generate text by iteratively unmasking many tokens in parallel, but this speed comes with a correction problem: tokens generated in the same step are predicted from marginal distributions, and early local dependency errors can later contaminate the context. PRISM addresses this by learning token-level quality scores and remasking unreliable tokens, but its inference rule is coupled: the same forward pass both detects low-quality tokens and computes logits for their replacements, so the erroneous tokens still condition regeneration. We propose NAVIRA, an inference-time decoding policy that separates these two operations and samples remasking positions stochastically. A first forward pass scores tokens; selected tokens are masked; a second forward pass regenerates from the cleaned context. Temperature-controlled remasking reduces repeated correction of the same positions and balances fluency against diversity. In controlled experiments with a 170M masked diffusion language model, decoupling improves fluency, while scheduled stochastic remasking preserves entropy and achieves stronger LLM-judge scores under larger forward-pass budgets. These results show that remasking policy, not only the learned quality signal, is central to reliable masked-diffusion text generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NAVIRA, an inference-time decoding policy for masked diffusion language models that decouples token quality scoring from regeneration via two separate forward passes, with temperature-controlled stochastic remasking of low-quality tokens. This addresses contamination from early local errors in parallel unmasking (as in PRISM) by regenerating from cleaned context. Controlled experiments on a 170M model claim that decoupling improves fluency, while the stochastic schedule preserves entropy and yields stronger LLM-judge scores under increased forward-pass budgets, showing that remasking policy matters beyond the learned quality signal.
Significance. If the empirical results hold, the work highlights that inference-time remasking policies can meaningfully improve generation quality in masked diffusion LMs without retraining. The controlled experimental setup with a fixed 170M model and focus on LLM-judge metrics under varying budgets is a strength, as is the emphasis on balancing fluency and diversity via temperature scheduling. No machine-checked proofs or parameter-free derivations are present.
major comments (1)
- [Experiments] The central claim that decoupling plus stochastic remasking produces net gains (stronger LLM-judge scores) rests on the untested assumption that the first-pass quality scores identify positions where regeneration from cleaned context yields improvement rather than trading one set of marginal predictions for another. The manuscript provides no correlation analysis between quality scores and post-remask delta, nor a random-remasking control, which is load-bearing for attributing gains to the quality signal rather than extra compute.
minor comments (1)
- [Abstract] The abstract states performance gains but supplies no quantitative results, baseline details, statistical tests, or ablation tables; adding these (with exact metrics and model details) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Experiments] The central claim that decoupling plus stochastic remasking produces net gains (stronger LLM-judge scores) rests on the untested assumption that the first-pass quality scores identify positions where regeneration from cleaned context yields improvement rather than trading one set of marginal predictions for another. The manuscript provides no correlation analysis between quality scores and post-remask delta, nor a random-remasking control, which is load-bearing for attributing gains to the quality signal rather than extra compute.
Authors: We agree that the current experiments do not include an explicit correlation between quality scores and post-remask improvement deltas, nor a random-remasking ablation, leaving open the possibility that gains partly reflect extra compute rather than the quality signal. Our reported results compare NAVIRA against PRISM under matched forward-pass budgets on the same 170M model, isolating the effect of the second forward pass on cleaned context; the LLM-judge gains and fluency improvements are therefore tied to the decoupling mechanism rather than raw budget alone. Nevertheless, a random-remasking control would provide stronger causal evidence. We will add both the requested correlation analysis and a random-remasking baseline in the revised manuscript. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents NAVIRA as an inference-time decoding policy that decouples token quality scoring from regeneration via two separate forward passes plus stochastic remasking. All reported gains are measured empirically against baselines in controlled experiments on a 170M model; no equations, fitted parameters, or self-citations are invoked that would make the claimed improvements equivalent to the inputs by construction. The method description is procedural and externally falsifiable via the LLM-judge and fluency metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume =
Structured Denoising Diffusion Models in Discrete State-Spaces , author =. Advances in Neural Information Processing Systems , volume =. 2021 , url =
2021
-
[2]
Proceedings of the 41st International Conference on Machine Learning , pages =
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[3]
Advances in Neural Information Processing Systems , volume =
Simple and Effective Masked Diffusion Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2024 , doi =
2024
-
[4]
Large Language Diffusion Models
Large Language Diffusion Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2502.09992 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.09992 2025
-
[5]
Dream 7B: Diffusion Large Language Models
Ye, Jiacheng and Xie, Zhihui and Zheng, Lin and Gao, Jiahui and Wu, Zirui and Jiang, Xin and Li, Zhenguo and Kong, Lingpeng , year =. doi:10.48550/arXiv.2508.15487 , url =. 2508.15487 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.15487
-
[6]
Mercury: Ultra-Fast Language Models Based on Diffusion
Mercury: Ultra-Fast Language Models Based on Diffusion , author =. 2025 , eprint =. doi:10.48550/arXiv.2506.17298 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.17298 2025
-
[7]
Gong, Shansan and Zhang, Ruixiang and Zheng, Huangjie and Gu, Jiatao and Jaitly, Navdeep and Kong, Lingpeng and Zhang, Yizhe , year =. doi:10.48550/arXiv.2506.20639 , url =. 2506.20639 , archivePrefix =
-
[8]
doi:10.48550/arXiv.2602.01326 , url =
Wu, Zirui and Zheng, Lin and Xie, Zhihui and Ye, Jiacheng and Gao, Jiahui and Gong, Shansan and Feng, Yansong and Li, Zhenguo and Bi, Wei and Zhou, Guorui and Kong, Lingpeng , year =. doi:10.48550/arXiv.2602.01326 , url =. 2602.01326 , archivePrefix =
-
[9]
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference , author =. 2025 , eprint =. doi:10.48550/arXiv.2508.02193 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.02193 2025
-
[10]
doi:10.48550/arXiv.2503.00307 , url =
Wang, Guanghan and Schiff, Yair and Sahoo, Subham Sekhar and Kuleshov, Volodymyr , year =. doi:10.48550/arXiv.2503.00307 , url =. 2503.00307 , archivePrefix =
-
[11]
Fine-Tuning Masked Diffusion for Provable Self-Correction
Fine-Tuning Masked Diffusion for Provable Self-Correction , author =. 2025 , eprint =. doi:10.48550/arXiv.2510.01384 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.01384 2025
-
[12]
Gokaslan, Aaron and Cohen, Vanya and Pavlick, Ellie and Tellex, Stefanie , year =
-
[13]
2024 , eprint =. doi:10.48550/arXiv.2412.15115 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[14]
Gumbel Distillation for Parallel Text Generation , author =. 2026 , eprint =. doi:10.48550/arXiv.2603.22216 , url =
-
[15]
Advances in Neural Information Processing Systems , volume =
Simplified and Generalized Masked Diffusion for Discrete Data , author =. Advances in Neural Information Processing Systems , volume =. 2024 , doi =
2024
-
[16]
Mask-Predict: Parallel Decoding of Conditional Masked Language Models , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , month =. 2019 , address =. doi:10.18653/v1/D19-1633 , url =
-
[17]
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data , author =. 2024 , eprint =. doi:10.48550/arXiv.2406.03736 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.03736 2024
-
[18]
Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling , author =. 2024 , eprint =. doi:10.48550/arXiv.2409.02908 , url =
-
[19]
Advances in Neural Information Processing Systems , volume =
A Continuous Time Framework for Discrete Denoising Models , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[20]
Advances in Neural Information Processing Systems , volume =
Discrete Flow Matching , author =. Advances in Neural Information Processing Systems , volume =. 2024 , doi =
2024
-
[21]
Computer Vision -- ECCV 2022 , series =
Improved Masked Image Generation with Token-Critic , author =. Computer Vision -- ECCV 2022 , series =. 2022 , doi =
2022
-
[22]
Don't Settle Too Early: Self-Reflective Remasking for Diffusion Language Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2509.23653 , url =
-
[23]
Informed Correctors for Discrete Diffusion Models , author =. 2024 , eprint =. doi:10.48550/arXiv.2407.21243 , url =
-
[24]
Proceedings of the 42nd International Conference on Machine Learning , series =
Generalized Interpolating Discrete Diffusion , author =. Proceedings of the 42nd International Conference on Machine Learning , series =. 2025 , url =
2025
-
[25]
Path Planning for Masked Diffusion Model Sampling , author =. 2025 , eprint =. doi:10.48550/arXiv.2502.03540 , url =
-
[26]
Plan for Speed: Dilated Scheduling for Masked Diffusion Language Models
Plan for Speed: Dilated Scheduling for Masked Diffusion Language Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2506.19037 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.19037 2025
-
[27]
International Conference on Learning Representations , year =
The Curious Case of Neural Text Degeneration , author =. International Conference on Learning Representations , year =
-
[28]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , doi =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.