Kara: Efficient Reasoning LLM Serving via Sliding-Window KV Cache Compression
Pith reviewed 2026-07-04 01:21 UTC · model grok-4.3
The pith
Kara uses sliding-window compression on recent context to reduce KV cache size in reasoning LLMs while maintaining performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Kara is a sliding-window KV cache compression method that performs decoding-time compression only on the recently generated context. It leverages bidirectional attention to score and select informative KV pairs in the window and uses a Token2Chunk module to expand selected pairs into flexible chunks. Adapted to PagedAttention, it is implemented in KvLLM to reduce KV cache memory usage and improve output throughput for reasoning models with long CoT.
What carries the argument
Sliding-window KV cache compression that scores pairs with bidirectional attention and expands them via the Token2Chunk module into flexible chunks.
If this is right
- Reduces memory overhead from massive KV caches in long decoding sequences.
- Improves decoding throughput without the limitations of threshold-triggered policies.
- Preserves important flexible-sized semantic chunks at arbitrary positions.
- Avoids fully eliminating KV pairs from certain sequence blocks.
- Adapts to existing PagedAttention frameworks for practical deployment.
Where Pith is reading between the lines
- May enable serving larger batch sizes or longer contexts on the same hardware.
- Could reduce energy consumption in large-scale LLM inference deployments.
- Potential to extend to other attention-based models beyond standard transformers.
- Testing on a wider range of reasoning benchmarks might reveal task-specific benefits.
Load-bearing premise
Compressing only the recently generated context in a sliding window avoids significant information loss for future decoding steps.
What would settle it
Running Kara on a long CoT reasoning task and observing a substantial drop in final answer accuracy compared to the full KV cache baseline.
Figures
read the original abstract
Reasoning language models often generate long chain-of-thought (CoT), which accumulates a massive KV cache during the decoding phase and incurs high decoding latency and limited throughput. To address these issues, KV cache compression has emerged as a promising technique for reducing memory overhead by selectively removing unimportant KV pairs while preserving useful ones for subsequent decoding. Nevertheless, we identify two key limitations in existing KV cache compression methods: 1) their threshold-triggered compression policy may provide limited throughput improvement or even reduce throughput, and may fully eliminate KV pairs from certain blocks of the sequence, potentially worsening information loss. 2) they typically retain either isolated KV pairs or fixed-size chunks with rigid boundaries, failing to preserve important flexible-sized chunks at arbitrary token positions. To overcome these limitations, we propose Kara, a sliding-window KV cache compression method that performs decoding-time compression by operating only on the recently generated context. Kara leverages bidirectional attention to score and select informative KV pairs in the window. To enable flexible preservation of important semantic information, we design a Token2Chunk module to expand a subset of selected KV pairs into chunks. Furthermore, we adapt Kara to PagedAttention and develop KvLLM, an inference framework built upon vLLM, which reduces KV cache memory usage and effectively improves output throughput. Extensive experiments demonstrate consistent performance improvements of proposed Kara and KvLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
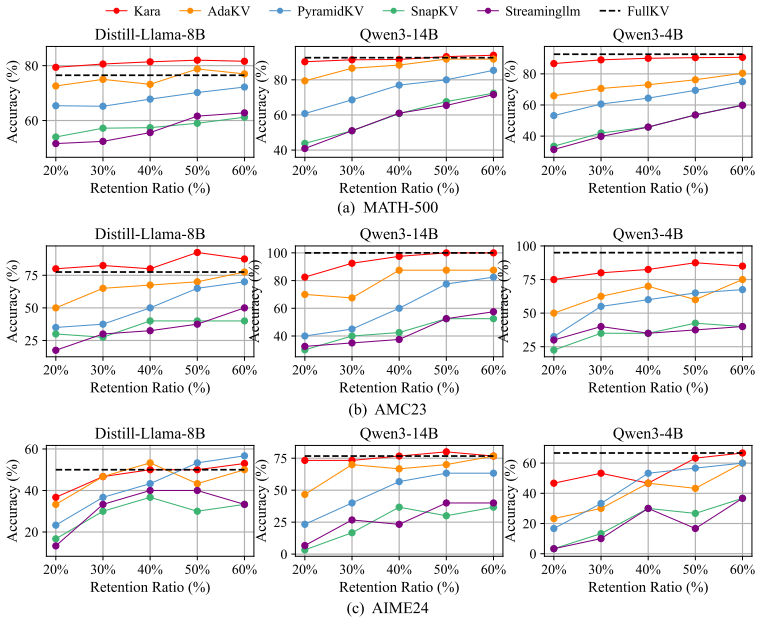
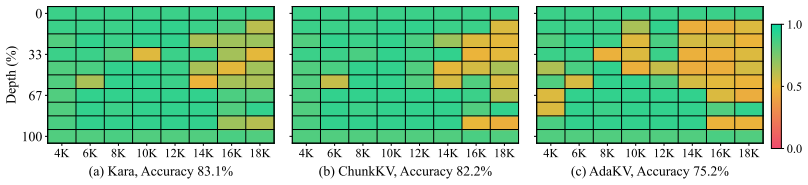
Summary. The paper identifies two limitations in prior KV cache compression for long-CoT reasoning LLMs (threshold-triggered policies that can hurt throughput or cause block-level KV elimination, and rigid isolated-pair or fixed-chunk retention) and proposes Kara: a sliding-window method that compresses only the recently generated context using bidirectional attention for KV scoring, a Token2Chunk module to expand selected pairs into flexible semantic chunks, and an adaptation to PagedAttention inside the KvLLM framework built on vLLM. It claims that this yields reduced KV memory usage and consistent performance improvements.
Significance. If the empirical claims hold, Kara would provide a practical, low-overhead route to higher throughput and lower memory for serving reasoning models whose CoT traces exceed typical context windows, directly addressing a growing deployment bottleneck.
major comments (3)
- [Abstract] Abstract: the central claim of 'consistent performance improvements' and 'effectively improves output throughput' is asserted without any quantitative results, baselines, error bars, or experimental protocol; this absence makes it impossible to assess whether the sliding-window restriction actually supports the claim or whether the identified limitations are resolved.
- [Abstract / method description] The design rests on the unexamined assumption that irreversible compression decisions made inside one sliding window on recent tokens will not produce cumulative information loss for later decoding steps that depend on earlier windows; no analysis, ablation, or long-CoT experiment tests cross-window dependency preservation (cf. the weakest assumption in the stress-test note).
- [Abstract] No equations, pseudocode, or complexity analysis are supplied for the bidirectional scoring, Token2Chunk expansion, or the PagedAttention integration, leaving open whether the claimed throughput gains are parameter-free or require additional tuning.
minor comments (2)
- [Abstract] The two limitations are stated clearly but the manuscript never returns to them with a direct head-to-head comparison showing how Kara avoids each failure mode.
- [Abstract] Terminology such as 'Token2Chunk module' and 'KvLLM' is introduced without a forward reference to the section that defines their implementation details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent performance improvements' and 'effectively improves output throughput' is asserted without any quantitative results, baselines, error bars, or experimental protocol; this absence makes it impossible to assess whether the sliding-window restriction actually supports the claim or whether the identified limitations are resolved.
Authors: We agree that the abstract would benefit from quantitative support. In the revised version, we will add specific metrics from our experiments (e.g., throughput gains and KV cache reductions relative to baselines), along with a brief reference to the evaluation protocol and models used. revision: yes
-
Referee: [Abstract / method description] The design rests on the unexamined assumption that irreversible compression decisions made inside one sliding window on recent tokens will not produce cumulative information loss for later decoding steps that depend on earlier windows; no analysis, ablation, or long-CoT experiment tests cross-window dependency preservation (cf. the weakest assumption in the stress-test note).
Authors: The sliding-window design with Token2Chunk is intended to limit cumulative loss by preserving semantic chunks from recent context. We will add a dedicated discussion of cross-window dependency preservation in Section 3 and include an ablation on long-CoT traces spanning multiple windows to empirically test this aspect. revision: yes
-
Referee: [Abstract] No equations, pseudocode, or complexity analysis are supplied for the bidirectional scoring, Token2Chunk expansion, or the PagedAttention integration, leaving open whether the claimed throughput gains are parameter-free or require additional tuning.
Authors: The full equations, pseudocode, and complexity analysis appear in Section 3 and the appendix. We will revise the abstract to briefly reference these components and state that the method operates without additional hyperparameters beyond the window size. revision: yes
Circularity Check
No circularity; purely algorithmic proposal without derivations or self-referential reductions
full rationale
The paper describes an engineering method (sliding-window KV cache compression with bidirectional scoring and Token2Chunk) to address stated limitations in prior KV compression techniques. No equations, parameter fits, uniqueness theorems, or self-citations appear in the provided text that would reduce any claim to its own inputs by construction. The central contribution is a new procedure whose performance is evaluated externally rather than derived from fitted values or prior author work invoked as axiomatic. This is the common case of a self-contained algorithmic paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022. 9
2022
-
[3]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Haoyang Li, Yiming Li, Anxin Tian, Tianhao Tang, Zhanchao Xu, Xuejia Chen, Nicole Hu, Wei Dong, Qing Li, and Lei Chen. A survey on large language model acceleration based on kv cache management.arXiv preprint arXiv:2412.19442, 2024
-
[5]
Llm inference unveiled: Survey and roofline model insights.arXiv preprint arXiv:2402.16363, 2024
Zhihang Yuan, Yuzhang Shang, Yang Zhou, Zhen Dong, Zhe Zhou, Chenhao Xue, Bingzhe Wu, Zhikai Li, Qingyi Gu, Yong Jae Lee, et al. Llm inference unveiled: Survey and roofline model insights.arXiv preprint arXiv:2402.16363, 2024
-
[6]
R-KV: Redundancy-aware KV cache compression for reasoning models
Zefan Cai, Wen Xiao, Hanshi Sun, Cheng Luo, Yikai Zhang, Ke Wan, Yucheng Li, Yeyang Zhou, Li-Wen Chang, Jiuxiang Gu, Zhen Dong, Anima Anandkumar, Abedelkadir Asi, and Junjie Hu. R-KV: Redundancy-aware KV cache compression for reasoning models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[7]
Ada-KV: Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S Kevin Zhou. Ada-KV: Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[8]
SnapKV: LLM knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. SnapKV: LLM knows what you are looking for before generation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[9]
KV cache compression, but what must we give in return? a comprehensive benchmark of long context capable approaches
Jiayi Yuan, Hongyi Liu, Shaochen Zhong, Yu-Neng Chuang, Songchen Li, Guanchu Wang, Duy Le, Hongye Jin, Vipin Chaudhary, Zhaozhuo Xu, Zirui Liu, and Xia Hu. KV cache compression, but what must we give in return? a comprehensive benchmark of long context capable approaches. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Associ...
2024
-
[10]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[11]
Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms
Qizhe Zhang, Aosong Cheng, Ming Lu, Renrui Zhang, Zhiyong Zhuo, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20857–20867, 2025
2025
-
[12]
Inference-time hyper-scaling with KV cache compression
Adrian Ła ´ncucki, Konrad Staniszewski, Piotr Nawrot, and Edoardo Ponti. Inference-time hyper-scaling with KV cache compression. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[13]
Lee, Sangdoo Yun, and Hyun Oh Song
Jang-Hyun Kim, Jinuk Kim, Sangwoo Kwon, Jae W. Lee, Sangdoo Yun, and Hyun Oh Song. KVzip: Query-agnostic KV cache compression with context reconstruction. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[14]
Alessio Devoto, Maximilian Jeblick, and Simon Jégou. Expected attention: Kv cache compres- sion by estimating attention from future queries distribution.arXiv preprint arXiv:2510.00636, 2025
-
[15]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[16]
Criticbench: Benchmarking llms for critique-correct reasoning
Zicheng Lin, Zhibin Gou, Tian Liang, Ruilin Luo, Haowei Liu, and Yujiu Yang. Criticbench: Benchmarking llms for critique-correct reasoning. InFindings of the Association for Computa- tional Linguistics: ACL 2024, pages 1552–1587, 2024. 10
2024
-
[17]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
ChunkKV: Semantic-preserving KV cache compression for efficient long-context LLM inference
Xiang Liu, Zhenheng Tang, Peijie Dong, Zeyu Li, Liuyue, Bo Li, Xuming Hu, and Xiaowen Chu. ChunkKV: Semantic-preserving KV cache compression for efficient long-context LLM inference. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[19]
Where does in-context learning \\ happen in large language models? InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
Suzanna Sia, David Mueller, and Kevin Duh. Where does in-context learning \\ happen in large language models? InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[20]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
A survey on large language model acceleration based on KV cache management.Transactions on Machine Learning Research, 2025
Haoyang LI, Yiming Li, Anxin Tian, Tianhao Tang, Zhanchao Xu, Xuejia Chen, Nicole HU, Wei Dong, Li Qing, and Lei Chen. A survey on large language model acceleration based on KV cache management.Transactions on Machine Learning Research, 2025
2025
-
[22]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. Sglang: efficient execution of structured language model programs. NIPS ’24, Red Hook, NY , USA,
-
[23]
Curran Associates Inc
-
[24]
Keydiff: Key similarity-based KV cache eviction for long-context LLM inference in resource-constrained environments
Junyoung Park, Dalton Jones, Matthew J Morse, Raghavv Goel, Mingu Lee, and Christopher Lott. Keydiff: Key similarity-based KV cache eviction for long-context LLM inference in resource-constrained environments. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2026
2026
-
[25]
ThinKV: Thought-adaptive KV cache compression for efficient reasoning models
Akshat Ramachandran, Marina Neseem, Charbel Sakr, Rangharajan Venkatesan, Brucek Khailany, and Tushar Krishna. ThinKV: Thought-adaptive KV cache compression for efficient reasoning models. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[26]
DefensiveKV: Taming the fragility of KV cache eviction in LLM inference
Yuan Feng, Haoyu Guo, Junlin Lv, S Kevin Zhou, and Xike Xie. DefensiveKV: Taming the fragility of KV cache eviction in LLM inference. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[27]
CAKE: Cascading and adaptive KV cache eviction with layer preferences
Ziran Qin, Yuchen Cao, Mingbao Lin, Wen Hu, Shixuan Fan, Ke Cheng, Weiyao Lin, and Jianguo Li. CAKE: Cascading and adaptive KV cache eviction with layer preferences. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
American invitational mathematics examination (aime) 2024, 2024
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024, 2024
2024
-
[29]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
QuoKA: Query-oriented KV selection for efficient LLM prefill
Dalton Jones, Junyoung Park, Matthew J Morse, Mingu Lee, Matthew Harper Langston, and Christopher Lott. QuoKA: Query-oriented KV selection for efficient LLM prefill. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[31]
Icecache: Memory-efficient KV-cache management for long-sequence LLMs
Yuzhen Mao, Qitong Wang, Martin Ester, and Ke Li. Icecache: Memory-efficient KV-cache management for long-sequence LLMs. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[32]
Cache what lasts: Token retention for memory-bounded KV cache in LLMs
Ngoc Bui, Shubham Sharma, Simran Lamba, Saumitra Mishra, and Rex Ying. Cache what lasts: Token retention for memory-bounded KV cache in LLMs. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[33]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
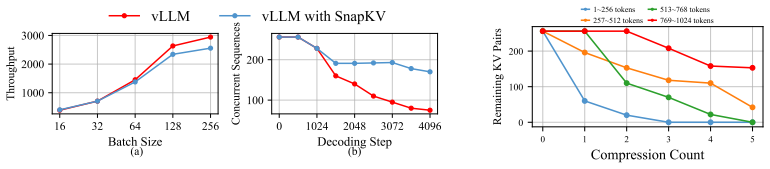
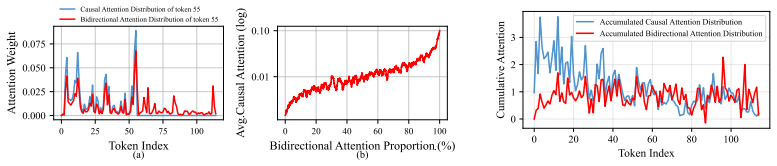
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026. 11 A Detailed Experimental Settings for Figure 1 and 2 This section provides detailed settings for the simple experiment shown in Figure 1 and 2. We run all experiments on the MATH-500 dataset using DeepSeek-R1-Distill-LLaMA-8B. In Figure 1, we vary the maximum nu...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.