Diffusion Transformer World-Action Model for AV Scene Prediction
Pith reviewed 2026-06-27 07:21 UTC · model grok-4.3
The pith
A latent Diffusion Transformer predicts future autonomous vehicle camera scenes from planned actions, achieving 4.8 times better distribution match than regression while remaining controllable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
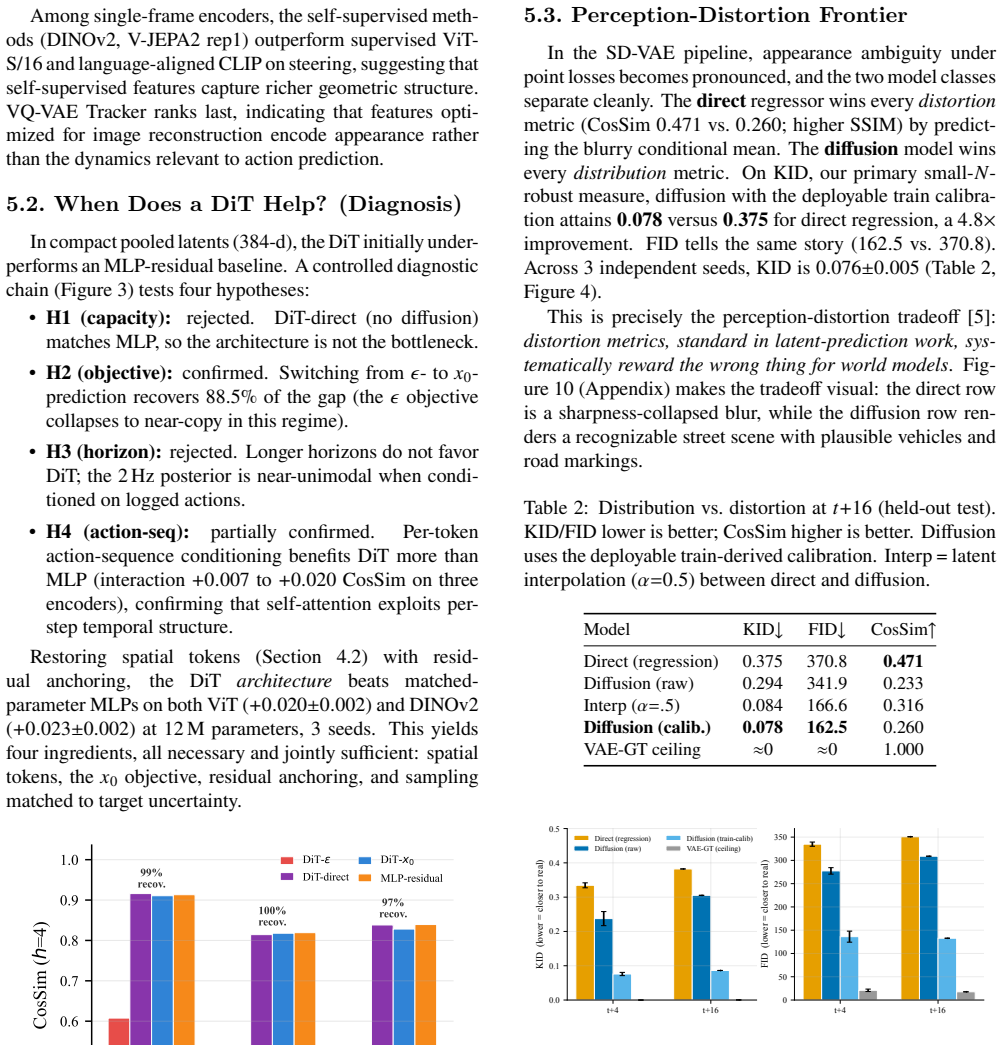
Core claim
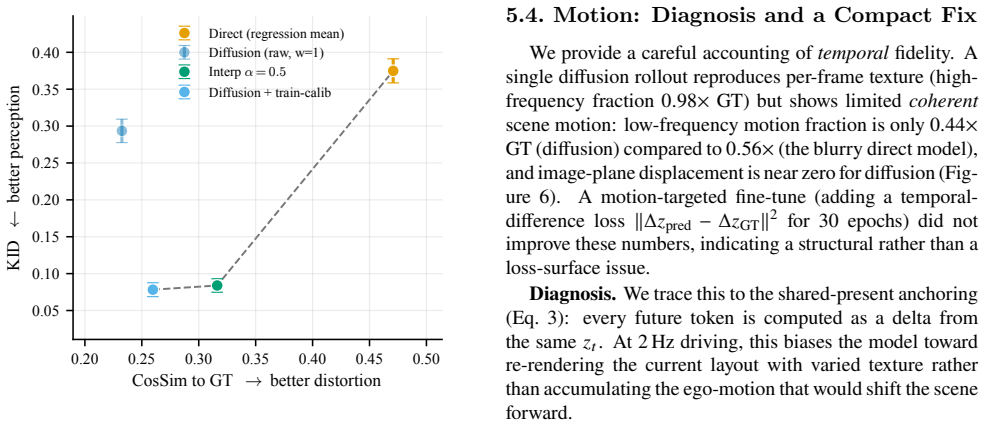
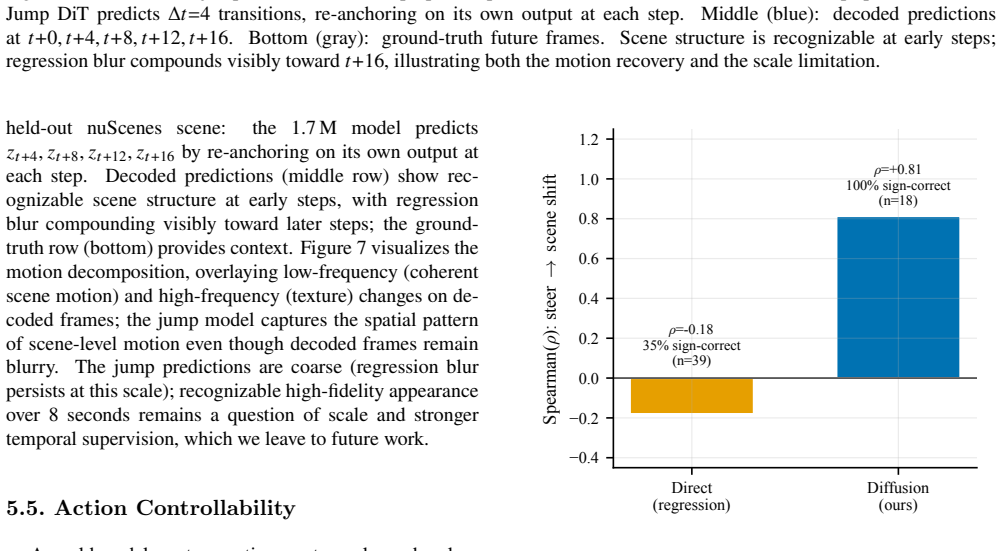
In a Stable-Diffusion-VAE encode-predict-decode pipeline the diffusion model attains KID 0.078 versus 0.375 for regression while remaining genuinely action-controllable (steering drives scene displacement, Spearman ρ = 0.81, vs −0.18 for regression); a deployable train-derived calibration makes this practical without test-time ground truth.
What carries the argument
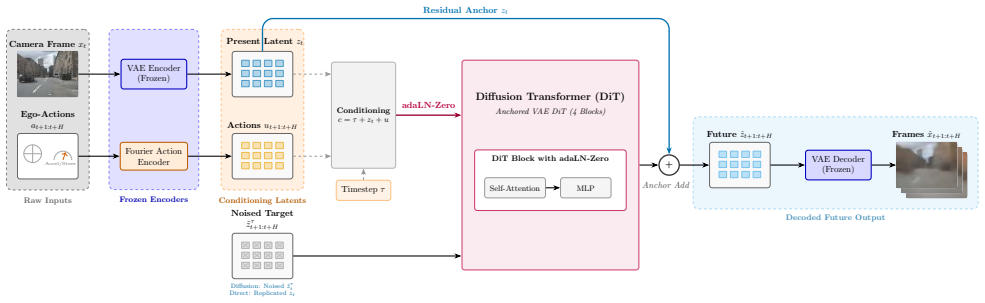
The Diffusion Transformer (DiT) with spatial tokens, x0 objective, residual anchoring, and sampling matched to target uncertainty, conditioned on ego-actions in the latent space from a frozen V-JEPA2 encoder.
If this is right
- The diffusion approach captures the real frame distribution on unseen scenes far better than regression.
- Action inputs genuinely control the predicted scene changes as shown by high Spearman correlation.
- A calibration derived from training data allows the model to be used without access to test ground truth.
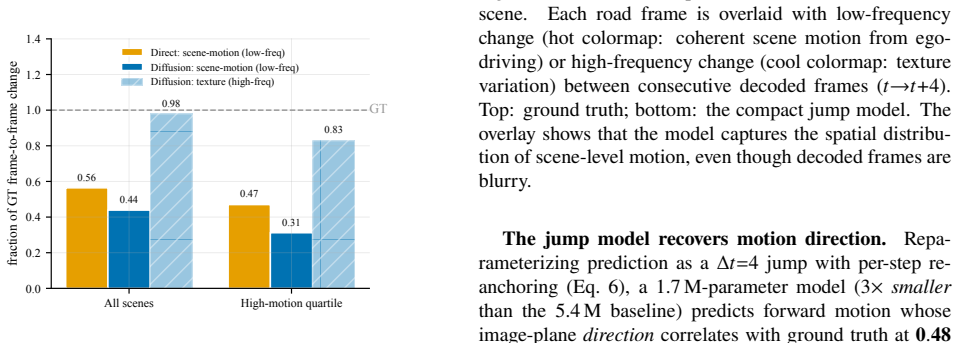
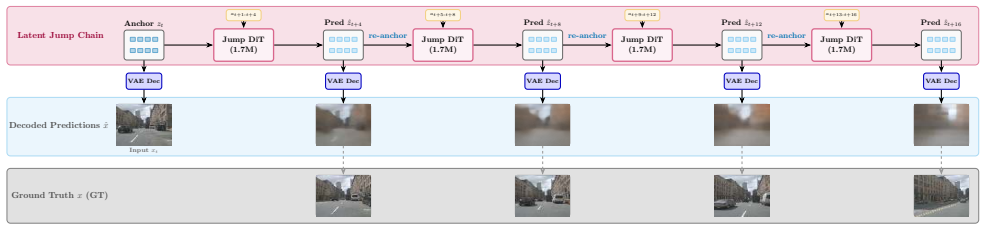
- The additional jump model recovers full ground-truth motion magnitude that single-pass models miss.
Where Pith is reading between the lines
- Such models could support more effective planning by generating diverse, realistic future scenarios instead of averaged ones.
- Applying the four DiT ingredients to other encoders or domains might yield similar gains in perceptual quality for prediction tasks.
- Combining this with reinforcement learning for planning could reduce the need for real-world testing in AV development.
Load-bearing premise
That the four DiT ingredients plus the frozen V-JEPA2 encoder produce latents whose decoded frames faithfully reflect real future scene distributions on unseen nuScenes scenes.
What would settle it
Measuring KID on decoded frames from the model versus real future frames on the 150 held-out nuScenes scenes and finding no significant improvement over regression.
Figures



read the original abstract
Action-conditioned world models let an autonomous vehicle predict future camera scenes from its own planned controls, enabling planning and simulation without real-world rollouts, but at compact, trainable scale the futures are ambiguous and the field's standard distortion metrics actively mislead: they reward a blurry regression mean over a realistic prediction. We confront this with a compact latent world model that, given the present front-camera latent and a sequence of ego-actions, predicts future scene latents a frozen decoder renders to $256 \times 256$ frames up to 8 seconds ahead, evaluated on 150 held-out nuScenes scenes. We first benchmark where to predict: across six frozen encoders spanning four representation families, V-JEPA2 with temporal context reduces steering RMSE by 40% over the best single-frame encoder. We then train a latent Diffusion Transformer (DiT) and, through a controlled diagnosis, identify the four ingredients it needs: spatial tokens, the $x_0$ objective, residual anchoring, and sampling matched to target uncertainty. In a Stable-Diffusion-VAE encode-predict-decode pipeline we expose the central tension: distortion metrics (cosine similarity, SSIM) favor the blurry mean, masking that the diffusion model is far closer to the real frame distribution. Inception-based FID and KID reveal a clean perception-distortion frontier: diffusion attains KID 0.078 versus 0.375 for regression ($4.8\times$ better), and a deployable train-derived calibration makes this practical without test-time ground truth. The model is genuinely action-controllable (steering drives scene displacement, Spearman $\rho = 0.81$, vs $-0.18$ for regression). We trace limited single-pass motion to a shared-present anchor and engineer a compact 1.7M-parameter "jump" model that recovers full ground-truth motion magnitude ($1.02\times$ GT), where single-pass models capture less than half.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a compact latent Diffusion Transformer (DiT) world model for action-conditioned prediction of future front-camera scenes in autonomous driving. Given current scene latents from a frozen encoder (best: V-JEPA2) and ego-action sequences, it predicts future latents decoded by a frozen Stable-Diffusion-VAE to 256x256 frames up to 8s ahead on 150 held-out nuScenes scenes. Through encoder benchmarks and a controlled DiT ablation, it identifies four key ingredients (spatial tokens, x0 objective, residual anchoring, uncertainty-matched sampling) and reports that the diffusion model achieves KID 0.078 vs. 0.375 for regression (4.8x better) while remaining action-controllable (steering Spearman ρ=0.81 vs. -0.18); a train-derived calibration enables deployment, and a 1.7M-param 'jump' model recovers full motion magnitude.
Significance. If the central KID and controllability results hold after addressing decoder fidelity, the work advances compact world models for AV planning and simulation by showing diffusion can match real scene distributions better than regression means, with explicit ablations and multi-encoder benchmarks providing reusable design guidance. The train-derived calibration and motion-magnitude recovery are practical strengths.
major comments (2)
- [Abstract / evaluation pipeline] Abstract and evaluation pipeline: the reported KID gap (0.078 vs 0.375) is computed on decoded frames from a frozen Stable-Diffusion-VAE trained on general images; without a reported VAE reconstruction KID/FID on nuScenes validation scenes or a control experiment swapping the decoder, it remains possible that decoder artifacts interact differently with sharp diffusion samples versus blurry regression outputs, undermining the claim that the gap reflects superior latent prediction of real future distributions.
- [Controllability experiments] Results on controllability (Spearman ρ=0.81): the metric is computed on steering-driven scene displacement, but the manuscript does not report whether this correlation holds after controlling for the shared-present anchor or on scenes with large motion; this is load-bearing for the claim that the model is 'genuinely action-controllable' rather than merely inheriting motion from the anchor.
minor comments (2)
- [Abstract] The 'jump model' is introduced in the abstract without a forward reference or parameter count justification relative to the main DiT; a brief methods subsection would clarify its scope.
- [DiT ablation] Notation for the four DiT ingredients is introduced via prose; an explicit enumerated list or table in the ablation section would improve traceability to the quantitative gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The two major comments identify important clarifications that strengthen the evaluation. We address each point below and will incorporate the suggested analyses into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / evaluation pipeline] Abstract and evaluation pipeline: the reported KID gap (0.078 vs 0.375) is computed on decoded frames from a frozen Stable-Diffusion-VAE trained on general images; without a reported VAE reconstruction KID/FID on nuScenes validation scenes or a control experiment swapping the decoder, it remains possible that decoder artifacts interact differently with sharp diffusion samples versus blurry regression outputs, undermining the claim that the gap reflects superior latent prediction of real future distributions.
Authors: We agree this is a valid concern for interpretability. Because the identical frozen decoder is used for both diffusion and regression outputs, any decoder-specific artifacts affect the two models equally and cannot explain the KID gap; the difference must originate in the latent predictions. Nevertheless, to make the claim fully robust we will add the VAE reconstruction KID/FID computed on the nuScenes validation scenes in the revised manuscript. We will also include a brief discussion of why a decoder-swap control is not required given the controlled experimental design. revision: yes
-
Referee: [Controllability experiments] Results on controllability (Spearman ρ=0.81): the metric is computed on steering-driven scene displacement, but the manuscript does not report whether this correlation holds after controlling for the shared-present anchor or on scenes with large motion; this is load-bearing for the claim that the model is 'genuinely action-controllable' rather than merely inheriting motion from the anchor.
Authors: We appreciate the referee's emphasis on this distinction. The manuscript already traces the limited single-pass motion magnitude to the shared-present anchor and introduces the 1.7 M-parameter jump model to recover full ground-truth motion (1.02× GT). To directly address the request, the revision will add (i) an explicit anchor-controlled analysis (correlation after subtracting the anchor-only baseline) and (ii) the Spearman ρ restricted to the subset of scenes exhibiting large motion. These additions will confirm that the reported controllability is not solely inherited from the anchor. revision: yes
Circularity Check
No circularity: held-out evaluation and independent metrics
full rationale
The paper evaluates its DiT world model on 150 held-out nuScenes scenes using distribution metrics (KID 0.078 vs 0.375, FID) and action-controllability (Spearman ρ = 0.81) computed directly against real frames. These are external benchmarks independent of the model's fitted parameters or internal definitions. The four DiT ingredients are identified via controlled diagnosis experiments, not by self-definition or renaming. No load-bearing self-citations, fitted inputs called predictions, or ansatzes smuggled via prior work appear in the derivation. The pipeline (frozen V-JEPA2 encoder + Stable-Diffusion-VAE) produces outputs verifiable against ground-truth distributions outside the training loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- train-derived calibration parameters
axioms (1)
- domain assumption Future scene uncertainty can be modeled by a diffusion process in latent space
invented entities (1)
-
jump model
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
A. Bardes et al. V-JEPA: Latent video prediction for visual representation learning.arXiv preprint arXiv:2404.08471, 2024
Pith/arXiv arXiv 2024
-
[3]
A. Bardes et al. V-JEPA 2: Self-supervised video models en- able understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[4]
Bi ´nkowski, D
M. Bi ´nkowski, D. J. Sutherland, M. Arbel, and A. Gretton. Demystifying MMD GANs. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[5]
Blau and T
Y. Blau and T. Michaeli. The perception-distortion tradeoff. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6228–6237, 2018
2018
-
[6]
Caesar et al
H. Caesar et al. nuScenes: A multimodal dataset for au- tonomous driving. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[7]
Dosovitskiy et al
A. Dosovitskiy et al. An image is worth 16x16 words: Trans- formers for image recognition at scale. InInternational Con- ference on Learning Representations (ICLR), 2021
2021
-
[8]
Esser, R
P. Esser, R. Rombach, and B. Ommer. Taming transformers for high-resolution image synthesis. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[9]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[10]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion proba- bilistic models.Advances in Neural Information Processing Systems, 2020
2020
-
[11]
J. Ho and T. Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[12]
A. Hu et al. GAIA-1: A generative world model with integrated action understanding.arXiv preprint arXiv:2309.17080, 2023
Pith/arXiv arXiv 2023
-
[13]
A. Q. Nichol and P. Dhariwal. Improved denoising diffusion probabilistic models.International Conference on Machine Learning (ICML), 2021
2021
-
[14]
Cosmos world foundation model platform for phys- ical ai.arXiv preprint arXiv:2501.03575, 2024
NVIDIA. Cosmos world foundation model platform for phys- ical ai.arXiv preprint arXiv:2501.03575, 2024
Pith/arXiv arXiv 2024
-
[15]
Oquab et al
M. Oquab et al. DINOv2: Learning robust visual features without supervision.Transactions on Machine Learning Re- search, 2024
2024
-
[16]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with trans- formers. InInternational Conference on Computer Vision (ICCV), 2023
2023
-
[17]
A. Polyak et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
Pith/arXiv arXiv 2024
-
[18]
Radford et al
A. Radford et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[19]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Om- mer. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[20]
C. Shi, J. Xu, S. Shi, K. Sheng, B. Zhang, and L. Jiang. DriveWAM: Video generative priors enable scalable world- action modeling for autonomous driving.arXiv preprint arXiv:2605.28544, 2026
Pith/arXiv arXiv 2026
-
[21]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Represen- tations (ICLR), 2021
2021
-
[22]
Tancik et al
M. Tancik et al. Fourier features let networks learn high fre- quency functions in low dimensional domains. InAdvances in Neural Information Processing Systems, 2020
2020
-
[23]
C. Yang et al. Driveworld: 4d pre-trained scene understanding via world models for autonomous driving.arXiv preprint arXiv:2405.04390, 2024
arXiv 2024
-
[24]
M. Yang et al. UniSim: Learning interactive real-world sim- ulators.arXiv preprint arXiv:2310.06114, 2023
Pith/arXiv arXiv 2023
-
[25]
X. Zhao et al. Drivedreamer: Towards real-world-driven world models for autonomous driving.arXiv preprint arXiv:2309.09777, 2024
arXiv 2024
-
[26]
J. Zheng et al. GenAD: Generalized predictive model for autonomous driving.arXiv preprint arXiv:2405.09349, 2024. 9 A. Additional Qualitative Results Camera (RGB) t+0 t+4 t+8 t+12 t+15 VAE-GT DiT-direct (regression) DiT-diffusion Figure 10: Qualitative V AE encode-predict-decode on a held-out nuScenes scene (𝑡+0 through𝑡+15). Row 1: camera RGB ground trut...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.