Does Topic Sentiment Cause Perceived Ideology? Comparing Human and LLM Annotations in Political News Articles
Pith reviewed 2026-06-28 01:15 UTC · model grok-4.3
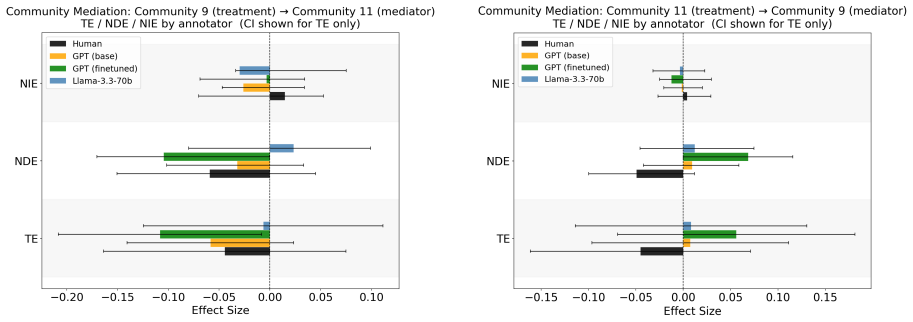
The pith
Fine-tuned GPT-4o-mini alone shows a causal effect of topic sentiment on perceived ideology that human annotators do not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
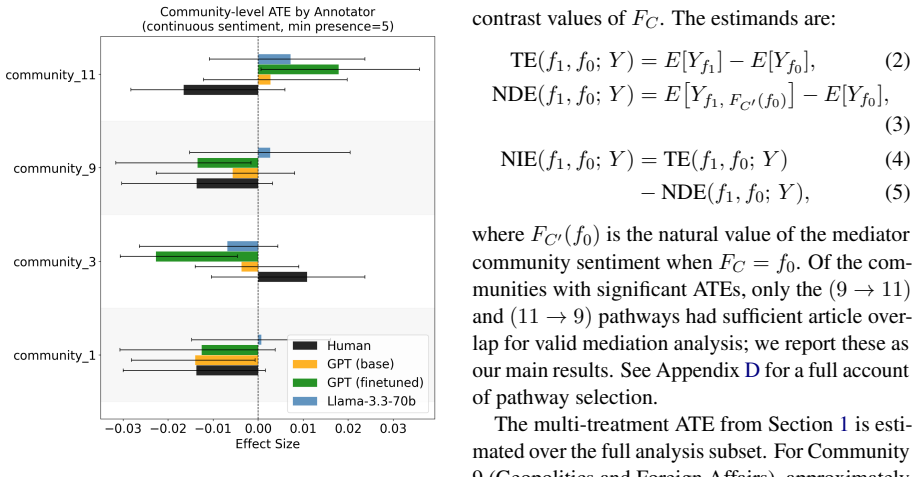
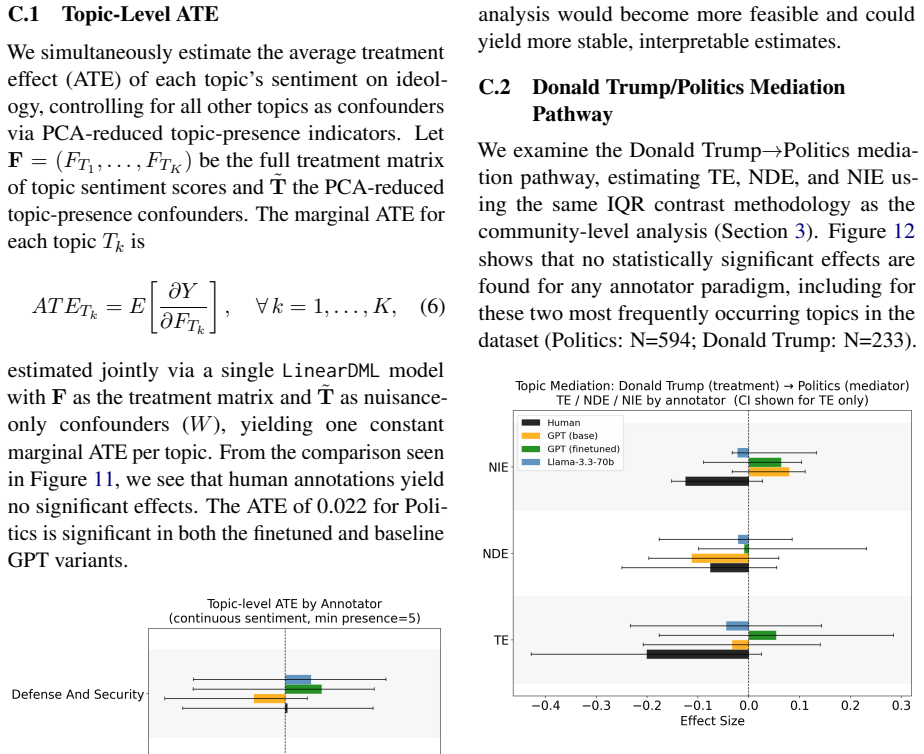
Fine-tuned GPT-4o-mini is the only annotator paradigm that produces significant community-level treatment effects and significant natural direct effects (NDEs) in mediation. We interpret this as evidence of shortcut learning: fine-tuning on ideology-labeled data causes the model to internalise a spurious sentiment-ideology coupling not operative in human judgment for this task.
What carries the argument
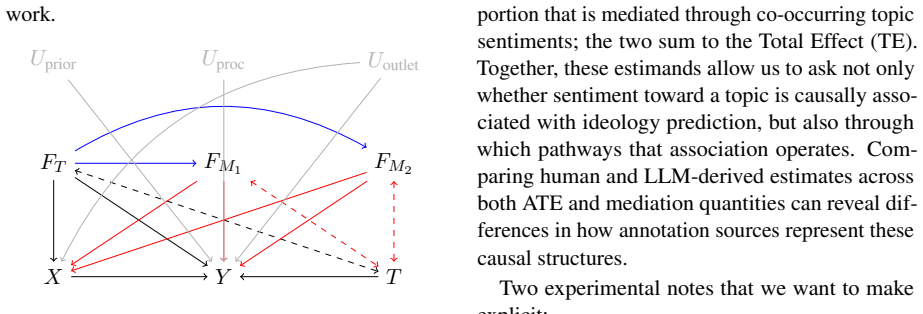
Double Machine Learning combined with community-level mediation analysis, applied separately to each of the four ideology annotation sources while holding sentiment labels fixed.
If this is right
- Human ideology annotations exhibit no causal response to topic sentiment.
- Standard classification accuracy metrics such as F1 miss the spurious coupling that appears in causal estimators.
- Fine-tuned LLM labels can function as silver labels for classification yet still distort downstream causal conclusions.
- The sentiment-ideology coupling is invisible to accuracy-based validation but surfaces under mediation analysis.
Where Pith is reading between the lines
- Researchers who substitute fine-tuned LLM labels for human labels in causal studies risk importing training artifacts that only become visible under mediation or DML.
- One practical check would be to compare causal estimates obtained from fine-tuned versus zero-shot LLM labels on the same task before treating the labels as interchangeable with human data.
- The same shortcut mechanism could appear in other paired annotation tasks where one variable is used both for fine-tuning and for later causal modeling.
Load-bearing premise
The shared sentiment annotations are independent of how ideology labels were produced and the estimators recover true causal effects without unmeasured confounding between sentiment and ideology.
What would settle it
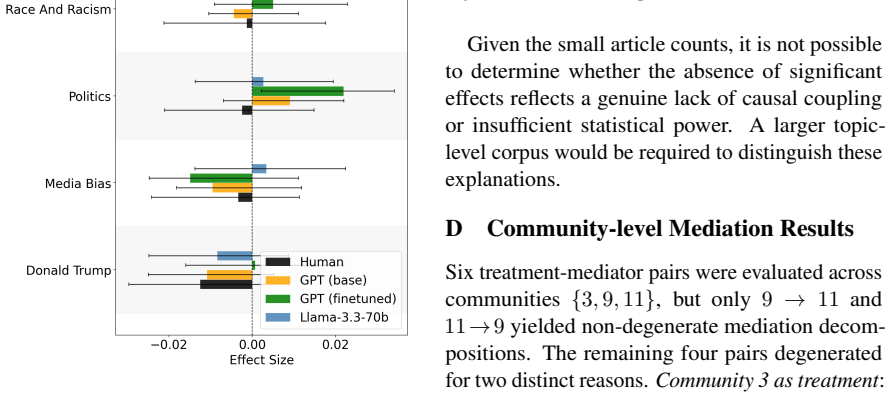
Re-running the identical DML and mediation pipeline on the same articles but with sentiment scores supplied by human raters instead of the LLM, and finding no significant NDE for the fine-tuned model, would falsify the shortcut-learning claim.
Figures



read the original abstract
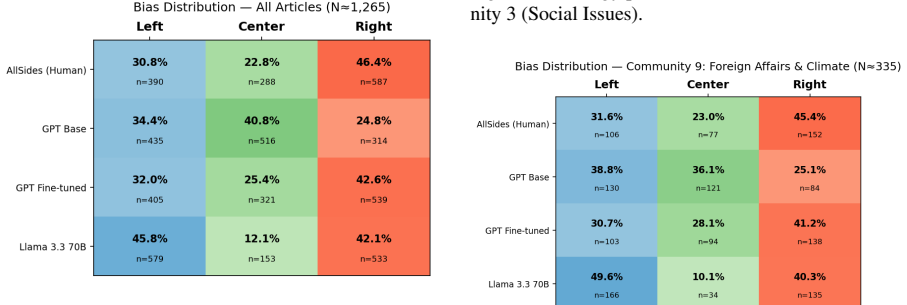
We ask whether topic sentiment has a causal effect on perceived political ideology, and whether the answer depends on who assigns the ideology label. Using articles from AllSides, paired with shared sentiment annotations from Llama-3.3-70b-versatile, we compare ideology labels from expert human annotators, GPT-4o-mini (baseline and finetuned), and Llama-3.3-70B. We apply Double Machine Learning (DML) and community-level mediation analysis across all four annotation paradigms. Human annotations yield no significant causal effects at the community level. Fine-tuned GPT-4o-mini achieves the highest classification accuracy (F1=72.48) and is the only annotator paradigm that produces significant community-level treatment effects and significant natural direct effects (NDEs) in mediation. We interpret this as evidence of shortcut learning: fine-tuning on ideology-labeled data causes the model to internalise a spurious sentiment--ideology coupling not operative in human judgment for this task. This coupling is structurally invisible to F1-based evaluation, with implications for the use of LLM annotations as silver labels and as proxies for human judgment in downstream causal analyses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines whether topic sentiment has a causal effect on perceived political ideology in news articles and whether this effect varies by annotator type (human experts, baseline and fine-tuned GPT-4o-mini, Llama-3.3-70B). Using shared Llama-3.3-70b sentiment annotations on AllSides articles, the authors apply Double Machine Learning (DML) and community-level mediation analysis. They report no significant causal effects for human annotations, but significant treatment effects and natural direct effects (NDEs) only for the fine-tuned GPT-4o-mini model (F1=72.48), interpreting this as evidence of shortcut learning induced by fine-tuning.
Significance. If the causal identification holds, the finding that fine-tuning introduces a spurious sentiment-ideology link not present in human annotations is significant for the field of LLM evaluation and causal inference using machine annotations. It suggests that accuracy metrics like F1 may miss important biases in downstream causal analyses, with implications for using LLMs as silver labels. The use of shared sentiment annotations across paradigms is a strength that allows direct comparison.
major comments (2)
- [DML implementation (methods section)] DML implementation (methods section): The paper provides no details on the covariate set used in the nuisance models for DML (e.g., whether article embeddings, topic indicators, or other text features beyond the Llama sentiment treatment are included). This is load-bearing for the central claim because both treatment (sentiment) and outcome (ideology label) derive from the same article text; omitted variables can induce confounding whose magnitude may differ across annotator paradigms, particularly for the fine-tuned model.
- [Mediation analysis results] Mediation analysis results: The claim that only the fine-tuned GPT-4o-mini yields significant community-level treatment effects and NDEs (supporting the shortcut-learning interpretation) rests on the no-unmeasured-confounding assumption without reported sensitivity analyses (e.g., e-values or alternative covariate specifications). The shared Llama sentiment is treated as exogenous, but the manuscript does not test or discuss whether this holds under the observed covariates alone.
minor comments (2)
- [Abstract] Abstract: The F1=72.48 for fine-tuned GPT-4o-mini is reported without the corresponding F1 scores for the other three annotation paradigms, making it impossible to assess the relative accuracy advantage.
- [Results] The manuscript would benefit from an explicit table reporting sample sizes, annotation agreement rates, and the exact number of articles per community for each paradigm.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify important gaps in the reporting of our identification strategy. We address each below and commit to revisions that strengthen the manuscript without altering its core claims or conclusions.
read point-by-point responses
-
Referee: [DML implementation (methods section)] DML implementation (methods section): The paper provides no details on the covariate set used in the nuisance models for DML (e.g., whether article embeddings, topic indicators, or other text features beyond the Llama sentiment treatment are included). This is load-bearing for the central claim because both treatment (sentiment) and outcome (ideology label) derive from the same article text; omitted variables can induce confounding whose magnitude may differ across annotator paradigms, particularly for the fine-tuned model.
Authors: We agree that explicit documentation of the nuisance-model covariates is required for readers to evaluate the plausibility of the conditional ignorability assumption. The current manuscript describes the DML procedure at a high level but does not enumerate the feature set passed to the outcome and treatment nuisance functions. In the revision we will add a dedicated subsection that lists all covariates (article-level embeddings from the shared Llama encoder, topic indicators, length, and publication metadata) together with the cross-fitting procedure and hyper-parameter choices. This addition will allow direct assessment of whether the same covariate specification is used across all four annotation paradigms. revision: yes
-
Referee: [Mediation analysis results] Mediation analysis results: The claim that only the fine-tuned GPT-4o-mini yields significant community-level treatment effects and NDEs (supporting the shortcut-learning interpretation) rests on the no-unmeasured-confounding assumption without reported sensitivity analyses (e.g., e-values or alternative covariate specifications). The shared Llama sentiment is treated as exogenous, but the manuscript does not test or discuss whether this holds under the observed covariates alone.
Authors: The referee correctly notes the absence of formal sensitivity checks for the no-unmeasured-confounding assumption that underpins both the DML and mediation results. While the shared Llama sentiment annotations are held fixed across paradigms, we did not report e-values, placebo tests, or alternative covariate sets. In the revised version we will add (i) e-value calculations for the significant NDE estimates obtained with the fine-tuned model and (ii) a brief discussion of how the results change when the covariate set is restricted to the observed text features alone. These additions will quantify the robustness of the reported community-level effects without requiring new data collection. revision: yes
Circularity Check
No circularity: empirical causal estimates rely on external AllSides data and standard DML/mediation methods without self-referential reduction
full rationale
The paper applies Double Machine Learning and community-level mediation analysis to compare ideology labels across human and LLM annotators, using shared Llama-3.3-70b sentiment annotations as the treatment variable. No equations or derivations within the paper reduce the reported treatment effects or NDEs to quantities defined by parameters fitted inside the study itself. The analysis depends on external article data from AllSides and off-the-shelf models; the interpretation of shortcut learning in the fine-tuned GPT-4o-mini is an empirical claim resting on the validity of the no-unmeasured-confounding assumption rather than any definitional or self-citational loop. No self-citations are load-bearing for the central results, and no ansatz, renaming, or fitted-input-as-prediction patterns appear.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Double Machine Learning assumptions (unconfoundedness, overlap, correct nuisance models) hold for the observed covariates
- domain assumption Sentiment annotations from Llama-3.3-70b are independent of the ideology annotation process
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 9th workshop on computational approaches to subjectivity, sentiment and social media analysis , pages=
Topic-specific sentiment analysis can help identify political ideology , author=. Proceedings of the 9th workshop on computational approaches to subjectivity, sentiment and social media analysis , pages=
-
[2]
, author=
A Preliminary Investigation into Sentiment Analysis of Informal Political Discourse. , author=. AAAI spring symposium: computational approaches to analyzing weblogs , pages=
-
[3]
Political Analysis , volume=
Sentiment is not stance: Target-aware opinion classification for political text analysis , author=. Political Analysis , volume=. 2023 , publisher=
2023
-
[4]
Discourse & Communication , volume=
Ideology through sentiment analysis: A changing perspective on Russia and Islam in NYT , author=. Discourse & Communication , volume=. 2017 , publisher=
2017
-
[5]
, title =
Rubin, Donald B. , title =. Journal of Educational Psychology , year =
-
[6]
The Econometrics Journal , year =
Chernozhukov, Victor and Chetverikov, Denis and Demirer, Mert and Duflo, Esther and Hansen, Christian and Newey, Whitney and Robins, James , title =. The Econometrics Journal , year =
-
[7]
Journal of the American Statistical Association , year =
Wager, Stefan and Athey, Susan , title =. Journal of the American Statistical Association , year =
-
[8]
Sensitivity Analysis for Causal Mediation through Text: an Application to Political Polarization
Tierney, Graham and Volfovsky, Alexander. Sensitivity Analysis for Causal Mediation through Text: an Application to Political Polarization. Proceedings of the First Workshop on Causal Inference and NLP. 2021. doi:10.18653/v1/2021.cinlp-1.5
-
[9]
Gentzkow, Matthew and Shapiro, Jesse M. and Taddy, Matt , title =. Econometrica , volume =. doi:https://doi.org/10.3982/ECTA16566 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.3982/ECTA16566 , abstract =
-
[10]
Spell, Gregory and Guay, Brian and Hillygus, Sunshine and Carin, Lawrence. An E mbedding M odel for E stimating L egislative P references from the F requency and S entiment of T weets. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.46
-
[11]
Keith, Katherine and Rice, Douglas and O ' Connor, Brendan. Text as Causal Mediators: Research Design for Causal Estimates of Differential Treatment of Social Groups via Language Aspects. Proceedings of the First Workshop on Causal Inference and NLP. 2021. doi:10.18653/v1/2021.cinlp-1.2
-
[12]
Conference on uncertainty in artificial intelligence , pages=
Adapting text embeddings for causal inference , author=. Conference on uncertainty in artificial intelligence , pages=. 2020 , organization=
2020
-
[13]
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Singer, Yaron and Shieber, Stuart , booktitle =. Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
-
[14]
Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning
Paul, Debjit and West, Robert and Bosselut, Antoine and Faltings, Boi. Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.882
-
[15]
Stolfo, Alessandro and Belinkov, Yonatan and Sachan, Mrinmaya. A Mechanistic Interpretation of Arithmetic Reasoning in Language Models using Causal Mediation Analysis. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.435
-
[16]
Beyond Surface Structure: A Causal Assessment of
Yujin Han and Lei Xu and Sirui Chen and Difan Zou and Chaochao Lu , booktitle=. Beyond Surface Structure: A Causal Assessment of. 2025 , url=
2025
-
[17]
Keith and Emaad Manzoor and Reid Pryzant and Dhanya Sridhar and Zach Wood-Doughty and Jacob Eisenstein and Justin Grimmer and Roi Reichart and Margaret E
Amir Feder and Katherine A. Keith and Emaad Manzoor and Reid Pryzant and Dhanya Sridhar and Zach Wood-Doughty and Jacob Eisenstein and Justin Grimmer and Roi Reichart and Margaret E. Roberts and Brandon M. Stewart and Victor Veitch and Diyi Yang , title =. 2022 , journal =
2022
-
[18]
Probabilistic and Causal Inference , year=
Direct and Indirect Effects , author=. Probabilistic and Causal Inference , year=
-
[19]
Neural Media Bias Detection Using Distant Supervision With BABE - Bias Annotations By Experts
Spinde, Timo and Plank, Manuel and Krieger, Jan-David and Ruas, Terry and Gipp, Bela and Aizawa, Akiko. Neural Media Bias Detection Using Distant Supervision With BABE - Bias Annotations By Experts. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.101
-
[20]
MBIC--A Media Bias Annotation Dataset Including Annotator Characteristics , author=
-
[21]
We Can Detect Your Bias: Predicting the Political Ideology of News Articles
Baly, Ramy and Da San Martino, Giovanni and Glass, James and Nakov, Preslav. We Can Detect Your Bias: Predicting the Political Ideology of News Articles. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.404
-
[22]
Moral Framing and Ideological Bias of News , ISBN=
Mokhberian, Negar and Abeliuk, Andrés and Cummings, Patrick and Lerman, Kristina , year=. Moral Framing and Ideological Bias of News , ISBN=. doi:10.1007/978-3-030-60975-7_16 , booktitle=
-
[23]
Entman , title =
Robert M. Entman , title =. Journalism , volume =. 2010 , doi =
2010
-
[24]
Wagner and Mike Gruszczynski , title =
Michael W. Wagner and Mike Gruszczynski , title =. Journalism & Communication Monographs , volume =. 2016 , doi =
2016
-
[25]
IEEE Transactions on Computational Social Systems , volume=
NewsSlant: Analyzing political news and its influence through a moral lens , author=. IEEE Transactions on Computational Social Systems , volume=. 2024 , publisher=
2024
-
[26]
Lin, Luyang and Wang, Lingzhi and Zhao, Xiaoyan and Li, Jing and Wong, Kam-Fai. I ndi V ec: An Exploration of Leveraging Large Language Models for Media Bias Detection with Fine-Grained Bias Indicators. Findings of the Association for Computational Linguistics: EACL 2024. 2024. doi:10.18653/v1/2024.findings-eacl.70
-
[27]
Ma, Bolei and Yoztyurk, Berk and Haensch, Anna-Carolina and Wang, Xinpeng and Herklotz, Markus and Kreuter, Frauke and Plank, Barbara and A enmacher, Matthias. Algorithmic Fidelity of Large Language Models in Generating Synthetic G erman Public Opinions: A Case Study. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics ...
-
[28]
Large language models can be used to estimate the latent positions of politicians , author=
-
[29]
Nature human behaviour , volume=
Testing theory of mind in large language models and humans , author=. Nature human behaviour , volume=. 2024 , publisher=
2024
-
[30]
Marketing Science , volume=
Frontiers: Determining the validity of large language models for automated perceptual analysis , author=. Marketing Science , volume=. 2024 , publisher=
2024
-
[31]
2023 , institution=
Large language models as simulated economic agents: What can we learn from homo silicus? , author=. 2023 , institution=
2023
-
[32]
Proceedings of the National Academy of Sciences122, 24 (June 2025), e2501660122
Yuan Gao and Dokyun Lee and Gordon Burtch and Sina Fazelpour , title =. Proceedings of the National Academy of Sciences , volume =. 2025 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.2501660122 , abstract =
-
[33]
Marcy Zipke , title =. Reading Psychology , volume =. 2007 , publisher =. doi:10.1080/02702710701260615 , URL =. https://doi.org/10.1080/02702710701260615 , abstract =
-
[34]
Vocabulary acquisition: Implications for reading comprehension , pages=
Metalinguistic awareness and the vocabulary-comprehension connection , author=. Vocabulary acquisition: Implications for reading comprehension , pages=. 2007 , publisher=
2007
-
[35]
Metalinguistic awareness in children: Theory, research, and implications , pages=
The development of metalinguistic awareness: A conceptual overview , author=. Metalinguistic awareness in children: Theory, research, and implications , pages=. 1984 , publisher=
1984
-
[36]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Do llms overcome shortcut learning? an evaluation of shortcut challenges in large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[37]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Explore spurious correlations at the concept level in language models for text classification , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[38]
Communications of the ACM , volume=
Shortcut learning of large language models in natural language understanding , author=. Communications of the ACM , volume=. 2023 , publisher=
2023
-
[39]
npj Digital Medicine , author=
Shortcut learning in medical AI hinders generalization: Method for estimating AI model generalization without external data , volume=. npj Digital Medicine , author=. 2024 , month=. doi:10.1038/s41746-024-01118-4 , number=
-
[40]
LLM s Are Prone to Fallacies in Causal Inference
Joshi, Nitish and Saparov, Abulhair and Wang, Yixin and He, He. LLM s Are Prone to Fallacies in Causal Inference. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.590
-
[41]
2025 , eprint=
Correlation or Causation: Analyzing the Causal Structures of LLM and LRM Reasoning Process , author=. 2025 , eprint=
2025
-
[42]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Can Large Language Models Infer Causation from Correlation? , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[43]
Moraffah, Raha and Karami, Mansooreh and Guo, Ruocheng and Raglin, Adrienne and Liu, Huan , title =. SIGKDD Explor. Newsl. , month = may, pages =. 2020 , issue_date =. doi:10.1145/3400051.3400058 , abstract =
-
[44]
Selçuk and Liu, Huan , journal=
Cheng, Lu and Guo, Ruocheng and Moraffah, Raha and Sheth, Paras and Candan, K. Selçuk and Liu, Huan , journal=. Evaluation Methods and Measures for Causal Learning Algorithms , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.