PORTER: Language-Grounded Event Representations for Portable Structured EHR Foundation Models
Pith reviewed 2026-06-26 00:43 UTC · model grok-4.3
The pith
PORTER uses frozen language descriptions to represent EHR events, matching fixed-vocabulary performance while transferring to entirely unseen event wording without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
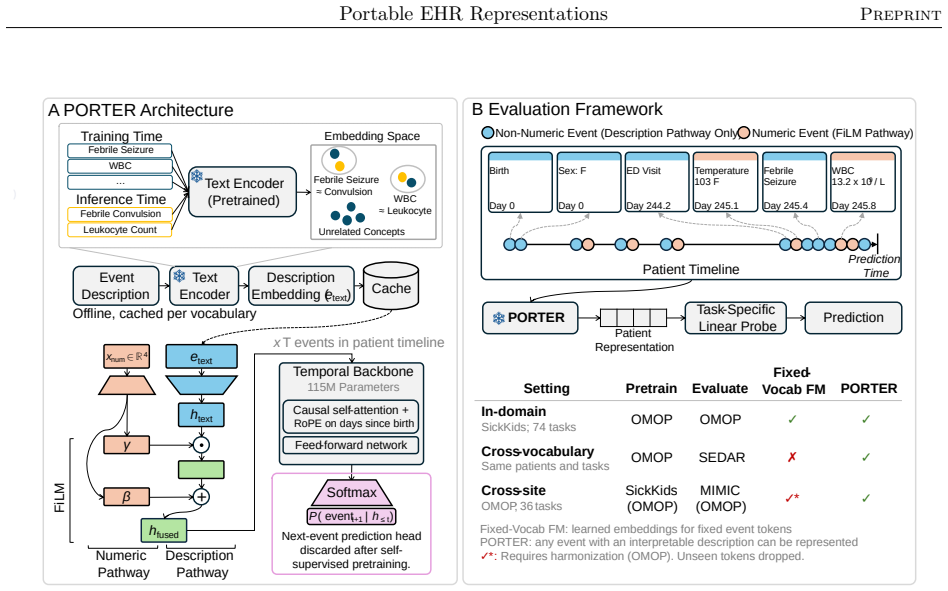
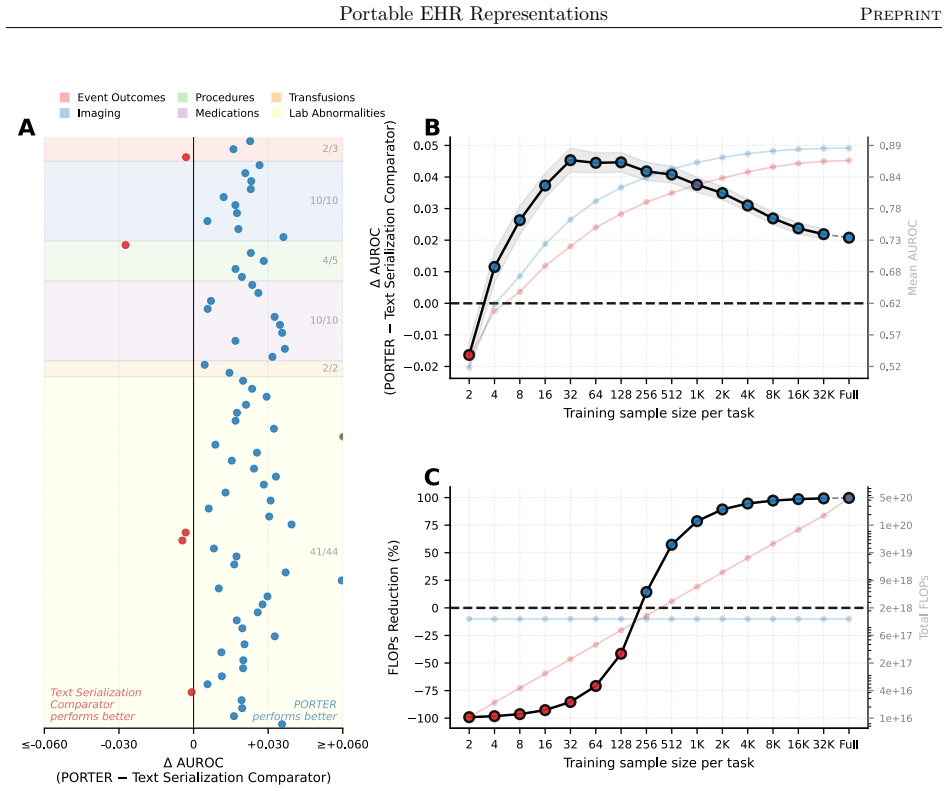
PORTER decouples event representation from any fixed token vocabulary by feeding event descriptions into a frozen text encoder, adding a dedicated numeric pathway, and pretraining an autoregressive temporal backbone on patient sequences. On 74 clinical prediction tasks the model reaches the same mean AUROC as a fixed-vocabulary counterpart with identical backbone and objective. When the same timelines are rewritten with event descriptions never seen in pretraining, PORTER recovers 97.1 percent of the target-vocabulary model's AUROC without any retraining or mapping. On MIMIC the language-grounded model outperforms the fixed-vocabulary baseline, which drops 69 percent of events whose tokens a
What carries the argument
The frozen text encoder that converts arbitrary event descriptions into embeddings processed by the autoregressive temporal backbone.
If this is right
- A single pretrained PORTER model can be deployed across institutions whose event coding differs without vocabulary harmonization or retraining.
- Numeric attributes such as lab values are incorporated without losing the identity of the underlying clinical concept.
- Patient-level representation geometry is preserved across vocabularies, which supports the observed transfer performance.
- Amortized compute for new tasks drops sharply compared with serializing each task into free text at inference time.
Where Pith is reading between the lines
- The same language-grounded route could be tested on non-clinical sequential records that also suffer from changing token sets, such as transaction logs.
- If geometry preservation is the key driver, swapping in larger text encoders should produce measurable gains only when those encoders better maintain sequence-level distances.
- Cross-vocabulary transfer may reduce the data volume needed for fine-tuning when moving between EHR systems.
Load-bearing premise
Embeddings from the frozen text encoder preserve the clinical meaning and temporal structure required for accurate downstream predictions even when the exact event wording and attribute combinations have never been observed during pretraining.
What would settle it
Running the same patient timelines with novel event descriptions and finding that mean AUROC falls below 90 percent of the directly trained target-vocabulary model would show the transfer claim does not hold.
Figures
read the original abstract
Most electronic health record (EHR) foundation models encode clinical events as discrete event tokens from a fixed vocabulary and therefore cannot directly represent events containing unseen concepts or new combinations of concepts and attributes such as numeric values. This limits transfer across institutions and even across deployment pipelines within the same institution. We introduce PORTER, a language-grounded structured EHR foundation model that decouples event representation from this fixed vocabulary. PORTER represents events through their descriptions using a frozen text encoder, integrates numeric values through a dedicated pathway, and learns clinical dynamics over patient timelines with an autoregressively pretrained temporal backbone. Across 74 clinical prediction tasks at a pediatric hospital, PORTER matched the mean AUROC of a fixed-vocabulary model with the same temporal backbone and pretraining objective. When the same patient timelines were rendered using event descriptions not seen during pretraining, PORTER transferred without retraining or vocabulary mapping, recovering 97.1% of the mean AUROC of a model trained directly on the target vocabulary. When transferred to MIMIC, PORTER outperformed the fixed-vocabulary model, which dropped 69% of events because their tokens were unseen. Mechanistic analyses showed cross-vocabulary transfer tracked preservation of patient-level representation geometry rather than the scale of the text encoder, and the numeric pathway improved sensitivity to magnitude without disrupting clinical concept identity. PORTER also achieved higher AUROC than a task-specific text serialization comparator, at 329-fold lower amortized compute. PORTER is a step toward vocabulary-independent EHR foundation models that reduce the need for vocabulary harmonization while preserving in-domain performance and enabling efficient cross-task reuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PORTER, a language-grounded structured EHR foundation model that decouples event representation from fixed vocabularies by using a frozen text encoder for clinical event descriptions, a dedicated pathway for numeric attributes, and an autoregressively pretrained temporal backbone on patient timelines. It claims to match the mean AUROC of a fixed-vocabulary model with the same backbone across 74 clinical prediction tasks, recover 97.1% of target-vocabulary AUROC when transferring to entirely unseen event descriptions without retraining or mapping, outperform the fixed-vocabulary baseline on MIMIC (where the latter drops 69% of events), achieve higher AUROC than a task-specific text serialization baseline at 329-fold lower amortized compute, and link transfer success via mechanistic analyses to preservation of patient-level representation geometry rather than text-encoder scale.
Significance. If the transfer and geometry-preservation results hold under rigorous evaluation, this would represent a meaningful step toward vocabulary-independent EHR foundation models that reduce harmonization overhead while maintaining in-domain performance. Strengths include the direct empirical comparison against a matched-backbone fixed-vocabulary baseline, the cross-institution MIMIC transfer experiment, the efficiency comparison, and the mechanistic analysis of representation geometry; these provide concrete, falsifiable evidence for the portability claim.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central transfer claim reports recovery of 97.1% mean AUROC on unseen-vocabulary event descriptions, but provides no details on statistical testing, confidence intervals, exact train/validation/test splits, or the procedure used to generate event descriptions and attribute combinations for the unseen test. These omissions are load-bearing because they prevent assessment of whether the reported recovery is robust or sensitive to particular choices in description rendering.
- [§5] §5 (Mechanistic Analyses): The claim that transfer success tracks preservation of patient-level representation geometry (rather than text-encoder scale) does not yet distinguish whether novel-description embeddings fall inside the convex hull of the pretraining distribution or whether the temporal backbone has learned genuinely vocabulary-agnostic dynamics. A concrete test (e.g., measuring distance of unseen embeddings to the training convex hull or ablation on out-of-hull synthetic descriptions) is needed to support the stronger interpretation.
minor comments (2)
- [§3] §3 (Model): Clarify whether the numeric pathway is applied before or after the text encoder and how its output is fused with the text embedding; the current description leaves the exact integration point ambiguous for replication.
- [Table 2] Table 2 or equivalent results table: Report the number of tasks and the distribution of AUROC differences rather than only the mean; this would strengthen the claim that PORTER “matched” the fixed-vocabulary baseline.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies opportunities to improve clarity and strengthen the mechanistic claims. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central transfer claim reports recovery of 97.1% mean AUROC on unseen-vocabulary event descriptions, but provides no details on statistical testing, confidence intervals, exact train/validation/test splits, or the procedure used to generate event descriptions and attribute combinations for the unseen test. These omissions are load-bearing because they prevent assessment of whether the reported recovery is robust or sensitive to particular choices in description rendering.
Authors: We agree that these details are necessary for rigorous evaluation. In the revised manuscript we will add: (1) bootstrap confidence intervals and paired statistical tests for the 97.1% recovery figure; (2) the exact patient-level train/validation/test splits (including any temporal or institutional partitioning); and (3) a precise description of the procedure used to render event descriptions and numeric attribute combinations for the unseen-vocabulary test set, including how synonyms, paraphrases, and attribute ranges were sampled. These additions will be placed in §4 and the appendix. revision: yes
-
Referee: [§5] §5 (Mechanistic Analyses): The claim that transfer success tracks preservation of patient-level representation geometry (rather than text-encoder scale) does not yet distinguish whether novel-description embeddings fall inside the convex hull of the pretraining distribution or whether the temporal backbone has learned genuinely vocabulary-agnostic dynamics. A concrete test (e.g., measuring distance of unseen embeddings to the training convex hull or ablation on out-of-hull synthetic descriptions) is needed to support the stronger interpretation.
Authors: We acknowledge that the current geometry analysis does not explicitly test whether unseen embeddings lie inside the pretraining convex hull. In revision we will add (i) the average Euclidean distance of unseen-description embeddings to the convex hull of the pretraining embedding set and (ii) a controlled ablation that inserts synthetic out-of-hull numeric-attribute combinations. These results will be reported in §5 with the existing geometry metrics. If the additional ablation proves computationally prohibitive we will note this limitation and retain the distance-to-hull measurement as the primary supporting evidence. revision: partial
Circularity Check
No circularity; empirical transfer results measured directly against baselines.
full rationale
The paper contains no equations, derivations, or claimed first-principles results. The 97.1% AUROC recovery on unseen event descriptions is an empirical measurement obtained by rendering the same patient timelines with novel descriptions and comparing AUROC to a fixed-vocabulary baseline trained directly on the target set. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described manuscript. The model architecture (frozen text encoder + autoregressive temporal backbone) is trained and evaluated in the standard supervised manner; success is not forced by construction but validated by out-of-vocabulary testing. This is the most common honest finding for empirical ML papers without mathematical claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ethan Steinberg, Ken Jung, Jason A. Fries, Conor K. Corbin, Stephen R. Pfohl, and Nigam H. Shah. Language models are an effective representation learning technique for electronic health record data. Journal of Biomedical Informatics, 113:103637, 2021. ISSN 1532-0464. doi: 10.1016/j.jbi.2020.103637. URLhttps://www.sciencedirect.com/science/article/pii/S153...
-
[2]
Samir, Jaroslaw Was, Quanzheng Li, David W
Pawel Renc, Yugang Jia, Anthony E. Samir, Jaroslaw Was, Quanzheng Li, David W. Bates, and Arkadiusz Sitek. Zero shot health trajectory prediction using transformer.npj Digital Medicine, 7(1):256, 2024. ISSN 2398-6352. doi: 10.1038/s41746-024-01235-0. URLhttps://doi.org/10.1038/s41746-024-01235-0
-
[3]
Generative medical event models improve with scale.arXiv, 2508.12104, 2025
Shane Waxler, Paul Blazek, Davis White, Daniel Sneider, Kevin Chung, Mani Nagarathnam, Patrick Williams, Hank Voeller, Karen Wong, Matthew Swanhorst, Sheng Zhang, Naoto Usuyama, Cliff Wong, 15 Portable EHR RepresentationsPreprint Tristan Naumann, Hoifung Poon, Andrew Loza, Daniella Meeker, Seth Hain, and Rahul Shah. Generative medical event models improve...
arXiv 2025
-
[4]
Laila Rasmy, Yang Xiang, Ziqian Xie, Cui Tao, and Degui Zhi. Med-BERT: pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction.npj Digital Medicine, 4(1):86, 2021. ISSN 2398-6352. doi: 10.1038/s41746-021-00455-y. URL https://doi.org/10.1038/ s41746-021-00455-y
-
[5]
MOTOR: A time-to-event foundation model for structured medical records.International Conference on Learning Representations, 2024
Ethan Steinberg, Jason Fries, Yizhe Xu, and Nigam Shah. MOTOR: A time-to-event foundation model for structured medical records.International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=NialiwI2V6
2024
-
[6]
Artem Shmatko, Alexander Wolfgang Jung, Kumar Gaurav, Søren Brunak, Laust Hvas Mortensen, Ewan Birney, Tom Fitzgerald, and Moritz Gerstung. Learning the natural history of human disease with generative transformers.Nature, 647(8088):248–256, 2025. ISSN 1476-4687. doi: 10.1038/ s41586-025-09529-3. URLhttps://doi.org/10.1038/s41586-025-09529-3
-
[7]
Charles Gadd, Krishna Gokhale, Aditya Acharya, Jennifer Cooper, Francesca Crowe, Leah Fitzsimmons, Thomas Jackson, Krishnarajah Nirantharakumar, Christopher Yau, Rebecca Birch, Marco Canducci, Dominic Danks, Alexander d’Elia, Alastair Denniston, Sarah Flanagan, Suzy Gallier, Naijie Guan, Xin Guan, Imane Guellil, Georgios Gkoutos, Shamil Haroon, Eleanor Ha...
-
[8]
ChaoPang, JiheumPark, XinzhuoJiang, NishanthParameshwarPavinkurve, KrishnaS.Kalluri, Shalmali Joshi, Noémie Elhadad, and Karthik Natarajan. CEHR-XGPT: A scalable multi-task foundation model for electronic health records.arXiv, 2509.03643, 2025. URLhttps://arxiv.org/abs/2509.03643
arXiv 2025
-
[9]
Pfohl, Nigam Shah, Jason Fries, and Lillian Sung
Lin Lawrence Guo, Ethan Steinberg, Scott Lanyon Fleming, Jose Posada, Joshua Lemmon, Stephen R. Pfohl, Nigam Shah, Jason Fries, and Lillian Sung. EHR foundation models improve robustness in the presence of temporal distribution shift.Scientific Reports, 13(1):3767, 2023. ISSN 2045-2322. doi: 10.1038/s41598-023-30820-8. URLhttps://doi.org/10.1038/s41598-02...
-
[10]
Joshua Lemmon, Lin Lawrence Guo, Ethan Steinberg, Keith E Morse, Scott Lanyon Fleming, Catherine Aftandilian, Stephen R Pfohl, Jose D Posada, Nigam Shah, Jason Fries, and Lillian Sung. Self-supervised machine learning using adult inpatient data produces effective models for pediatric clinical prediction tasks.Journal of the American Medical Informatics As...
-
[11]
Lin Lawrence Guo, Jason Fries, Ethan Steinberg, Scott Lanyon Fleming, Keith Morse, Catherine Aftandilian, Jose Posada, Nigam Shah, and Lillian Sung. A multi-center study on the adaptability of a shared foundation model for electronic health records.npj Digital Medicine, 7(1):171, 2024. ISSN 2398-6352. doi: 10.1038/s41746-024-01166-w. URL https://doi.org/1...
-
[12]
Systematic review of foundation models for structured electronic health records
Lin Lawrence Guo, Santiago Eduardo Arciniegas, Adam Paul Yan, Jason Fries, George A Tomlinson, and Lillian Sung. Systematic review of foundation models for structured electronic health records. Journal of the American Medical Informatics Association, 33(6):1190–1198, 2026. ISSN 1527-974X. doi: 10.1093/jamia/ocag033. URLhttps://doi.org/10.1093/jamia/ocag033
-
[13]
Tokenization tradeoffs in structured EHR foundation models.arXiv, 2603.15644, 2026
Lin Lawrence Guo, Santiago Eduardo Arciniegas, Joseph Jihyung Lee, Adam Paul Yan, George Tomlinson, Jason Fries, and Lillian Sung. Tokenization tradeoffs in structured EHR foundation models.arXiv, 2603.15644, 2026. URLhttps://arxiv.org/abs/2603.15644
arXiv 2026
-
[14]
Ilker Demirel, Lawrence Shi, Zeshan Hussain, and David Sontag. LLMs can construct powerful representations and streamline sample-efficient supervised learning.arXiv, 2603.11679, 2026. URL https://arxiv.org/abs/2603.11679
Pith/arXiv arXiv 2026
-
[15]
Sontag, Gerhard Hindricks, Roland Eils, and Benjamin Wild
Stefan Hegselmann, Georg von Arnim, Tillmann Rheude, Noel Kronenberg, David A. Sontag, Gerhard Hindricks, Roland Eils, and Benjamin Wild. Large language models are powerful electronic health record encoders.arXiv, 2502.17403, 2025. URLhttps://arxiv.org/abs/2502.17403. 16 Portable EHR RepresentationsPreprint
Pith/arXiv arXiv 2025
-
[16]
Churpek, Guanhua Chen, and Majid Afshar
Jifan Gao, Mahmudur Rahman, John Caskey, Madeline Oguss, Ann O’Rourke, Randall Brown, Anne Stey, Anoop Mayampurath, Matthew M. Churpek, Guanhua Chen, and Majid Afshar. MoMA: a mixture- of-multimodal-agents architecture for enhancing clinical prediction modelling.npj Digital Medicine, 9(1):46, 2026. ISSN 2398-6352. doi: 10.1038/s41746-025-02219-4. URL http...
-
[17]
Hejie Cui, Alyssa Unell, Bowen Chen, Jason Alan Fries, Emily Alsentzer, Sanmi Koyejo, and Nigam H. Shah. TIMER: temporal instruction modeling and evaluation for longitudinal clinical records.npj Digital Medicine, 8(1):577, 2025. ISSN 2398-6352. doi: 10.1038/s41746-025-01965-9. URL https: //doi.org/10.1038/s41746-025-01965-9
-
[18]
van de Water, Christoph Lippert, Andrea Ganna, and FinnGen
Matthias Kirchler, Matteo Ferro, Veronica Lorenzini, Robin P. van de Water, Christoph Lippert, Andrea Ganna, and FinnGen. Large language models improve transferability of electronic health record-based predictions across countries and coding systems.npj Digital Medicine, 9(1):177, 2026. ISSN 2398-6352. doi: 10.1038/s41746-026-02363-5. URLhttps://doi.org/1...
-
[19]
Unifying heterogeneous electronic health records systems via text-based code embedding
Kyunghoon Hur, Jiyoung Lee, Jungwoo Oh, Wesley Price, Younghak Kim, and Edward Choi. Unifying heterogeneous electronic health records systems via text-based code embedding. InProceedings of the Conference on Health, Inference, and Learning, volume 174 ofProceedings of Machine Learning Research, pages 183–203. PMLR, 2022. URLhttps://proceedings.mlr.press/v...
2022
-
[20]
Doudou Zhou, Han Tong, Linshanshan Wang, Suqi Liu, Xin Xiong, Ziming Gan, Romain Griffier, Boris P. Hejblum, Yun-Chung Liu, Chuan Hong, Clara-Lea Bonzel, Tianrun Cai, Kevin Pan, Yuk- Lam Ho, Lauren Costa, Vidul A. Panickan, J. Michael Gaziano, Kenneth D. Mandl, Vianney Jouhet, Rodolphe Thiebaut, Zongqi Xia, Kelly Cho, Katherine Liao, and Tianxi Cai. Repre...
-
[21]
Rethinking tokenization for clinical time series: When less is more.arXiv, 2512.05217, 2025
Rafi Al Attrach, Rajna Fani, David Restrepo, Yugang Jia, and Peter Schüffler. Rethinking tokenization for clinical time series: When less is more.arXiv, 2512.05217, 2025. URLhttps://arxiv.org/abs/ 2512.05217
arXiv 2025
-
[22]
GenHPF: General healthcare predictive framework for multi-task multi-source learning.IEEE Journal of Biomedical and Health Informatics, 28(1):502–513,
Kyunghoon Hur, Jungwoo Oh, Junu Kim, Jiyoun Kim, Min Jae Lee, Eunbyeol Cho, Seong-Eun Moon, Young-Hak Kim, Louis Atallah, and Edward Choi. GenHPF: General healthcare predictive framework for multi-task multi-source learning.IEEE Journal of Biomedical and Health Informatics, 28(1):502–513,
-
[23]
URLhttps://doi.org/10.1109/JBHI.2023.3327951
doi: 10.1109/JBHI.2023.3327951. URLhttps://doi.org/10.1109/JBHI.2023.3327951
-
[24]
Kyunghoon Hur, Heeyoung Kwak, Jinsu Jang, Nakhwan Kim, and Edward Choi. Multi-lingual multi- institutional electronic health record based predictive model.arXiv, 2604.00027, 2026. doi: 10.48550/ arXiv.2604.00027. URLhttps://arxiv.org/abs/2604.00027
arXiv 2026
-
[25]
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. FiLM: Visual reasoning with a general conditioning layer.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), 2018. doi: 10.1609/aaai.v32i1.11671. URLhttps://doi.org/10.1609/aaai.v32i1.11671
-
[26]
Development and validation of the SickKids enterprise-wide data in Azure repository (SEDAR)
Lin Lawrence Guo, Maryann Calligan, Emily Vettese, Sadie Cook, George Gagnidze, Oscar Han, Jiro Inoue, Joshua Lemmon, Johnson Li, Medhat Roshdi, Bohdan Sadovy, Steven Wallace, and Lillian Sung. Development and validation of the SickKids enterprise-wide data in Azure repository (SEDAR). Heliyon, 9(11):e21586, 2023. ISSN 2405-8440. doi: 10.1016/j.heliyon.20...
-
[27]
Bert Arnrich, Edward Choi, Jason Alan Fries, Matthew B. A. McDermott, Jungwoo Oh, Tom Pollard, Nigam Shah, Ethan Steinberg, Michael Wornow, and Robin van de Water. Medical event data standard (MEDS): Facilitating machine learning for health. InICLR 2024 Workshop on Learning from Time Series For Health, 2024. URLhttps://openreview.net/forum?id=IsHy2ebjIG
2024
-
[28]
Ethan Steinberg, Michael Wornow, Suhana Bedi, Jason Alan Fries, Matthew B. A. McDermott, and Nigam H. Shah. meds_reader: A fast and efficient EHR processing library.arXiv, 2409.09095, 2024. URLhttps://arxiv.org/abs/2409.09095
arXiv 2024
-
[29]
A. E. W. Johnson, L. Bulgarelli, L. Shen, A. Gayles, A. Shammout, S. Horng, T. J. Pollard, S. Hao, B. Moody, B. Gow, L. H. Lehman, L. A. Celi, and R. G. Mark. MIMIC-IV, a freely accessible electronic health record dataset.Sci Data, 10(1):1, 2023. ISSN 2052-4463. doi: 10.1038/s41597-022-01899-x
-
[30]
MIMIC (medical information mart for intensive care) - OMOP CDM ETL repository, 2024
OHDSI. MIMIC (medical information mart for intensive care) - OMOP CDM ETL repository, 2024. URLhttps://github.com/OHDSI/MIMIC. 17 Portable EHR RepresentationsPreprint
2024
-
[31]
Ary L. Goldberger, Luis A. N. Amaral, Leon Glass, Jeffrey M. Hausdorff, Plamen Ch. Ivanov, Roger G. Mark, Joseph E. Mietus, George B. Moody, Chung-Kang Peng, and H. Eugene Stanley. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation, 101(23):e215–e220, 2000. doi: 10.1161/01.CIR.101.2...
-
[32]
François Remy, Kris Demuynck, and Thomas Demeester. BioLORD-2023: Semantic textual repre- sentations fusing large language models and clinical knowledge graph insights.Journal of the Amer- ican Medical Informatics Association, 31(9):1844–1855, 2024. doi: 10.1093/jamia/ocae029. URL https://doi.org/10.1093/jamia/ocae029
-
[33]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M3-Embedding: Multi- linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. Findings of the Association for Computational Linguistics: ACL 2024, pages 2318–2335, 2024. doi: 10.18653/v1/2024.findings-acl.137. URLhttps://aclanthology....
-
[34]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv, 2506.05176, 2025. URL https: //arxiv.org/abs/2506.05176
Pith/arXiv arXiv 2025
-
[35]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Informa- tion Processing Systems, 30, 2017. URLhttps://papers.nips.cc/paper_files/paper/2017/hash/ 3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
2017
-
[36]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert- Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
1901
-
[37]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.arXiv, 2104.09864, 2021. doi: 10.48550/arXiv.2104.09864. URLhttps://arxiv.org/abs/2104.09864
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2104.09864 2021
-
[38]
Generating long sequences with sparse transformers.arXiv, 1904.10509, 2019
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers.arXiv, 1904.10509, 2019. URLhttps://arxiv.org/abs/1904.10509
Pith/arXiv arXiv 1904
-
[39]
Decoupled weight decay regularization.International Conference on Learning Representations, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.International Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[40]
Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel
Niklas Muennighoff, Alexander M. Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling data-constrained language models.Advances in Neural Information Processing Systems, 36, 2023. URLhttps://proceedings.neurips.cc/paper_ files/paper/2023/hash/9d89448b63ce1e2e8dc7af72c984c196-Abstract-Conf...
2023
-
[41]
Scikit- learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay. Scikit- learn: Machine learning in Python.Journal of Machine Learning Researc...
2011
-
[42]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv, 2001.08361, 2020. URLhttps://arxiv.org/abs/2001.08361
Pith/arXiv arXiv 2001
-
[43]
US Dollar Outlook: GBP/USD May Fall as USD/CAD Rises Amid Changes in Retail Exposure
Frank Wilcoxon. Individual comparisons by ranking methods.Biometrics Bulletin, 1(6):80–83, 1945. doi: 10.2307/3001968
-
[44]
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C. J. Carey, İlhan Polat, Yu Feng, Eric W. ...
-
[45]
A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6:65–70, 1979
Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6:65–70, 1979
1979
-
[46]
MTEB : Massive Text Embedding Benchmark
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. MTEB: Massive text embedding benchmark. InConference of the European Chapter of the Association for Computational Linguistics, pages 2014–2037, 2023. doi: 10.18653/v1/2023.eacl-main.148. URLhttps://aclanthology.org/2023. eacl-main.148/
-
[47]
Suchin Gururangan, Ana Marasovic, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. Don’t stop pretraining: Adapt language models to domains and tasks.Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360, 2020. doi: 10.18653/v1/2020.acl-main.740. URLhttps://aclanthology.org/2020.ac...
-
[48]
Joe Qin, Xiaohui Tao, and Fu Lee Wang
Lingling Xu, Haoran Xie, S. Joe Qin, Xiaohui Tao, and Fu Lee Wang. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment.IEEE Transactions on Pattern Analysis and Machine Intelligence, 48(6):6107–6126, 2026. doi: 10.1109/TPAMI.2026.3657354. URLhttps://doi.org/10.1109/TPAMI.2026.3657354
-
[49]
Measurement: {name}. Result: {result}
Zilin Jing, Vincent Jeanselme, Yuta Kobayashi, Simon A. Lee, Chao Pang, Aparajita Kashyap, Yanwei Li, Xinzhuo Jiang, and Shalmali Joshi. One loss to rule them all: Marked time-to-event for structured EHR foundation models.arXiv, 2602.00541, 2026. URLhttps://arxiv.org/abs/2602.00541. 19 Portable EHR RepresentationsPreprint Supplementary Material Supplement...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.