daVinci-kernel: Co-Evolving Skill Selection, Summarization, and Utilization via RL for GPU Kernel Optimization
Pith reviewed 2026-06-27 03:10 UTC · model grok-4.3
The pith
A single LLM backbone jointly trains three agents to select, generate, and summarize GPU kernel skills, building a verified library that beats prior RL models on KernelBench.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
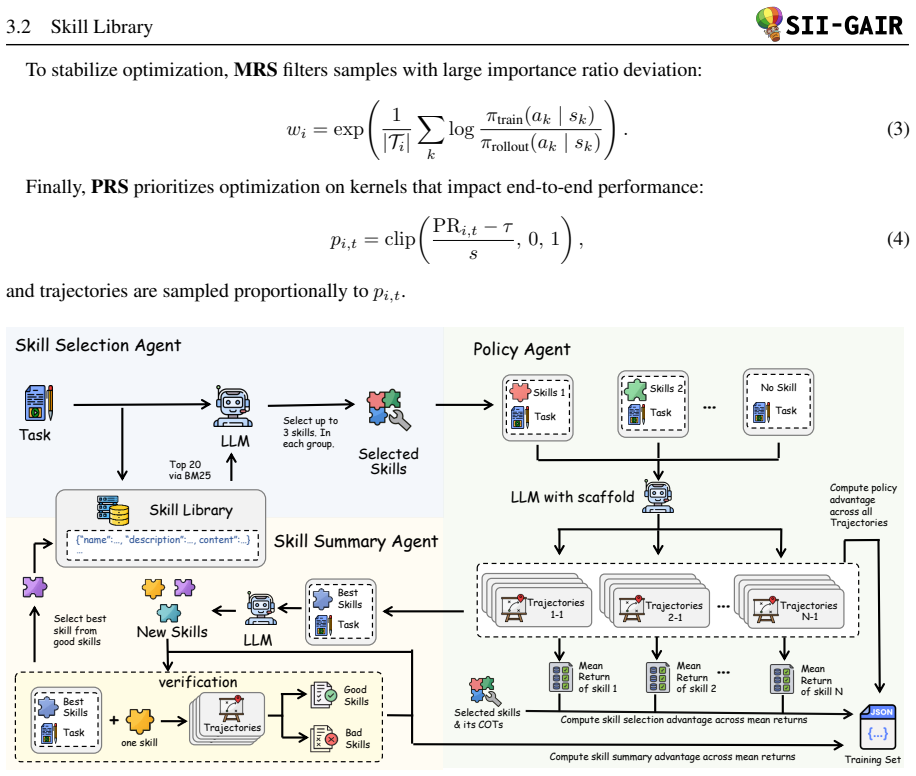
daVinci-kernel jointly trains a Skill Selection Agent, a Policy Agent, and a Skill Summary Agent that share a single LLM backbone; the selection agent retrieves skills, the policy agent produces multi-turn kernels, and the summary agent adds only those skills whose speedups survive execution-based verification. After an SFT cold start the three agents are optimized together via multi-turn REINFORCE with per-agent advantage estimation. On KernelBench the resulting 14B model records 37.2 percent, 70.6 percent, and 32.2 percent success under the Fast_1 threshold on Levels 1, 2, and 3, exceeding the strongest prior RL baseline Dr. Kernel-14B.
What carries the argument
The three-agent system with shared LLM backbone and execution-verified dynamic skill library, trained end-to-end by multi-turn REINFORCE.
If this is right
- Only kernels whose speedups survive repeated execution enter the skill library, limiting noise in the evolving set of techniques.
- A shared LLM backbone across selection, policy, and summary agents enables direct information flow during co-evolution.
- The SFT cold-start on diversity-filtered data supplies a stable initialization that supports subsequent joint REINFORCE optimization.
- Performance gains appear across three difficulty levels of KernelBench under the Fast_1 threshold.
Where Pith is reading between the lines
- The same three-agent pattern could be tested on CPU or accelerator code generation tasks outside GPU kernels.
- The skill library might be inspected to measure whether the discovered techniques generalize to new GPU architectures without retraining.
- Replacing BM25-plus-reranking retrieval with learned retrieval could be compared directly inside the same framework.
Load-bearing premise
Execution-based verification reliably identifies reproducible speedups and the joint REINFORCE training keeps the three agents from collapsing or overfitting to the verification signal.
What would settle it
Retraining the 14B model from the same SFT checkpoint on the same KernelBench split and measuring whether Level-1 Fast_1 success falls below 30 percent.
Figures


read the original abstract
GPU kernel optimization represents a paradigm where functional correctness is assumed and execution efficiency is the objective. We present daVinci-kernel, a reinforcement learning framework that couples skill discovery with skill exploitation through a dynamically evolving skill library. daVinci-kernel jointly trains three agents sharing one LLM backbone: a Skill Selection Agent that retrieves relevant techniques via BM25 and LLM reranking, a Policy Agent that generates multi-turn CUDA/Triton kernels conditioned on selected skills, and a Skill Summary Agent that distills successful rollouts into reusable skills. Candidate skills are added only after execution-based verification confirms reproducible speedups. All three agents share a single LLM backbone, are initialized via a structured SFT cold start on diversity-filtered data, and are then jointly optimized end-to-end with multi-turn REINFORCE and per-agent advantage estimation. On KernelBench, daVinci-kernel-14B achieves 37.2%, 70.6%, and 32.2% on Level 1, Level 2, and Level 3 under the Fast$_1$ threshold, outperforming the strongest prior RL-trained model, Dr\. Kernel-14B.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents daVinci-kernel, an RL framework for GPU kernel optimization that jointly trains three agents (Skill Selection via BM25/LLM reranking, Policy for multi-turn CUDA/Triton generation, and Skill Summary for distilling successful rollouts) sharing one LLM backbone. Agents are initialized with structured SFT and optimized end-to-end via multi-turn REINFORCE with per-agent advantage estimation; skills enter the library only after execution verification of reproducible speedups. On KernelBench the 14B model reports 37.2/70.6/32.2 % success on Levels 1/2/3 under the Fast_1 threshold, outperforming the prior RL baseline Dr. Kernel-14B.
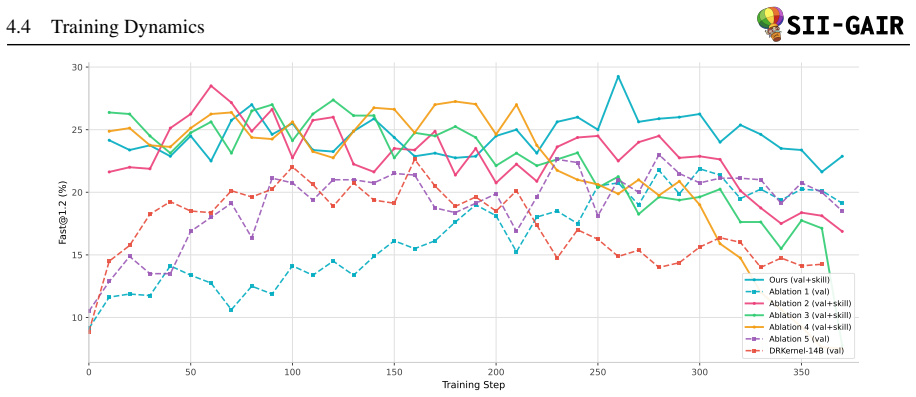
Significance. If the reported speedups are reproducible under controlled conditions and the joint training is shown to be stable, the co-evolution of skill discovery and exploitation via a shared backbone could meaningfully advance automated kernel optimization. The execution-verification gate and per-agent advantage design are potentially valuable if supported by ablations.
major comments (3)
- [Abstract] Abstract: the headline performance numbers (37.2 %, 70.6 %, 32.2 % on KernelBench Levels 1–3) are stated without any experimental protocol, baseline implementation details, number of seeds, error bars, or statistical tests, leaving the central claim of outperformance over Dr. Kernel-14B without visible supporting evidence.
- [Abstract] Abstract: the claim that the three agents co-evolve stably under shared-backbone multi-turn REINFORCE with per-agent advantage estimation is load-bearing for the method, yet no derivation, ablation, or analysis of credit assignment, collapse risk, or overfitting to verification signals is supplied.
- [Abstract] Abstract: the assertion that execution-based verification produces a reliable, non-overfit skill library lacks any description of statistical controls (multiple hardware runs, variability thresholds, or verification repetition), which directly affects the reproducibility of the reported speedups.
minor comments (1)
- [Abstract] Abstract: the terms 'Fast_1 threshold' and 'Dr. Kernel-14B' are used without definition or citation, reducing clarity for readers unfamiliar with KernelBench or the referenced baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, with proposed revisions to improve transparency in the abstract and supporting details in the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance numbers (37.2 %, 70.6 %, 32.2 % on KernelBench Levels 1–3) are stated without any experimental protocol, baseline implementation details, number of seeds, error bars, or statistical tests, leaving the central claim of outperformance over Dr. Kernel-14B without visible supporting evidence.
Authors: We agree that the abstract would benefit from additional context on the experimental protocol to support the reported numbers. The full manuscript details the KernelBench evaluation, Fast_1 threshold, and Dr. Kernel-14B comparison in Section 4. We will revise the abstract to concisely reference the evaluation protocol, note that results are averaged over multiple seeds, and indicate the outperformance margin. revision: yes
-
Referee: [Abstract] Abstract: the claim that the three agents co-evolve stably under shared-backbone multi-turn REINFORCE with per-agent advantage estimation is load-bearing for the method, yet no derivation, ablation, or analysis of credit assignment, collapse risk, or overfitting to verification signals is supplied.
Authors: Section 3 derives the multi-turn REINFORCE objective with per-agent advantage estimation and describes the shared-backbone joint optimization. We acknowledge that explicit ablations on credit assignment, collapse risk, and overfitting are not present. We will add a qualitative discussion of training stability and potential risks in a new paragraph in the Experiments section. revision: partial
-
Referee: [Abstract] Abstract: the assertion that execution-based verification produces a reliable, non-overfit skill library lacks any description of statistical controls (multiple hardware runs, variability thresholds, or verification repetition), which directly affects the reproducibility of the reported speedups.
Authors: Section 3.3 describes that skills enter the library only after execution verification of reproducible speedups. We agree that statistical controls merit more detail. We will revise the abstract to reference the verification gate and expand the methods description with repetition protocol and variability thresholds used. revision: yes
Circularity Check
No circularity in claimed derivation chain
full rationale
The paper describes an empirical RL framework with three jointly trained agents using multi-turn REINFORCE and execution-based verification on KernelBench. No equations, derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the abstract or method outline. Performance claims rest on external benchmarks and comparisons to prior models rather than any self-contained mathematical reduction. The central claims are statistically falsifiable via execution and do not reduce to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dayuan Fu, Shenyu Wu, Yunze Wu, Zerui Peng, Yaxing Huang, Jie Sun, Ji Zeng, Mohan Jiang, Lin Zhang, Yukun Li, et al. 2026. davinci-env: Open swe environment synthesis at scale.arXiv preprint arXiv:2603.13023
arXiv 2026
-
[2]
Siqi Guo, Ming Lin, and Tianbao Yang. 2026. Drtriton: Large-scale synthetic data reinforcement learning for triton kernel generation.arXiv preprint arXiv:2603.21465
Pith/arXiv arXiv 2026
-
[3]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
-
[4]
Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770
-
[5]
Jianling Li, Shangzhan Li, Zhenye Gao, Qi Shi, Yuxuan Li, Zefan Wang, Jiacheng Huang, WangHaojie Wang- Haojie, Jianrong Wang, Xu Han, et al. 2025a. Tritonbench: Benchmarking large language model capabilities for generating triton operators. InFindings of the Association for Computational Linguistics: ACL 2025, pages 23053–23066
2025
-
[6]
Shangzhan Li, Zefan Wang, Ye He, Yuxuan Li, Qi Shi, Jianling Li, Yonggang Hu, Wanxiang Che, Xu Han, Zhiyuan Liu, et al. 2025b. Autotriton: Automatic triton programming with reinforcement learning in llms.arXiv preprint arXiv:2507.05687
-
[7]
Yu Li, Rui Miao, Zhengling Qi, and Tian Lan. 2026. Arise: Agent reasoning with intrinsic skill evolution in hierarchical reinforcement learning.arXiv preprint arXiv:2603.16060
arXiv 2026
-
[8]
Xuechen Liang, Meiling Tao, Yinghui Xia, Jianhui Wang, Kun Li, Yijin Wang, Yangfan He, Jingsong Yang, Tianyu Shi, Yuantao Wang, et al. 2025. Sage: Self-evolving agents with reflective and memory-augmented abilities.Neurocomputing, 647:130470
2025
-
[9]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556
Pith/arXiv arXiv 2025
-
[10]
Wei Liu, Jiawei Xu, Yingru Li, Longtao Zheng, Tianjian Li, Qian Liu, and Junxian He. 2026. Dr. kernel: Reinforcement learning done right for triton kernel generations.arXiv preprint arXiv:2602.05885
arXiv 2026
-
[11]
Zhengxi Lu, Zhiyuan Yao, Jinyang Wu, Chengcheng Han, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. 2026. Skill0: In-context agentic reinforcement learning for skill internalization. arXiv preprint arXiv:2604.02268
Pith/arXiv arXiv 2026
-
[12]
Anne Ouyang, Simon Guo, Simran Arora, Alex L Zhang, William Hu, Christopher R´e, and Azalia Mirhoseini
-
[13]
Kernelbench: Can llms write efficient gpu kernels?arXiv preprint arXiv:2502.10517
-
[14]
2009.The probabilistic relevance framework: BM25 and beyond, volume 4
Stephen Robertson and Hugo Zaragoza. 2009.The probabilistic relevance framework: BM25 and beyond, volume 4. Now Publishers Inc
2009
-
[15]
Songjun Tu, Chengdong Xu, Qichao Zhang, Yaocheng Zhang, Xiangyuan Lan, Linjing Li, and Dongbin Zhao
-
[16]
Dynamic dual-granularity skill bank for agentic rl.arXiv preprint arXiv:2603.28716
-
[17]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291
Pith/arXiv arXiv 2023
-
[18]
Anjiang Wei, Tianran Sun, Yogesh Seenichamy, Hang Song, Anne Ouyang, Azalia Mirhoseini, Ke Wang, and Alex Aiken. 2025. Astra: A multi-agent system for gpu kernel performance optimization.arXiv preprint arXiv:2509.07506
arXiv 2025
-
[19]
Jiin Woo, Shaowei Zhu, Allen Nie, Zhen Jia, Yida Wang, and Youngsuk Park. 2025. Tritonrl: Training llms to think and code triton without cheating.arXiv preprint arXiv:2510.17891
arXiv 2025
-
[20]
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. 2026. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning. arXiv preprint arXiv:2602.08234
Pith/arXiv arXiv 2026
-
[21]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[22]
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. 2025. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471
Pith/arXiv arXiv 2025
-
[23]
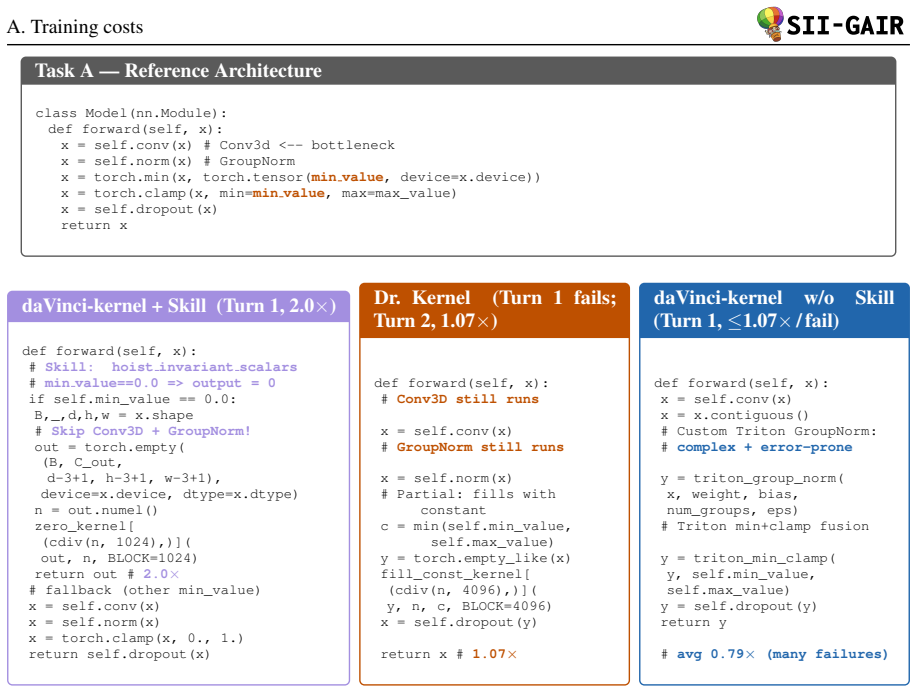
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2024. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642. 11 A. Training costs SII-GAIR Task A — Reference Architecture class Model(nn.Module): def forward(self, x): x = self.conv(x) # Co...
2024
-
[24]
Xinguo Zhu, Shaohui Peng, Jiaming Guo, Yunji Chen, Qi Guo, Yuanbo Wen, Hang Qin, Ruizhi Chen, Qirui Zhou, Ke Gao, et al. 2026. Qimeng-kernel: Macro-thinking micro-coding paradigm for llm-based high- performance gpu kernel generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 29168–29176. A Training costs Interacting...
2026
-
[25]
Run conv/matmul using PyTorch/library kernels
-
[26]
Ensure the output is contiguous
-
[27]
Flatten to numel() and launch masked 1D kernel
-
[28]
Pitfalls: .contiguous() erases gains if tail tiny
Fuse as many elementwise ops as possible. Pitfalls: .contiguous() erases gains if tail tiny. [2]name: fuse_only_contiguous_pointwise_tails description: Fuse memory-bound pointwise epilogues around vendor kernels; don’t replace heavy ops. tags: [fusion, pointwise, memory_bound, triton] --- \#\# Motivation Custom Triton underperforms when it replaces librar...
-
[29]
Ensure tail input is contiguous
-
[30]
Flatten to numel() and launch masked 1D grid
-
[31]
Fuse as many pointwise ops as possible
-
[32]
call .contiguous(), flat- ten to numel(), and launch a masked 1-D grid,
Avoid extra temporaries unless profiling justifies. Pitfalls: use masks for non-power-of-two sizes. [3]name: hotspot_aware_triton_selection description: Kernelize only bandwidth-bound tails that are actually hot. tags: [hotspot_analysis, fusion_strategy, triton] --- \#\# Motivation Custom Triton often underperforms when it targets only a tiny fraction of ...
-
[33]
Run conv/matmul in PyTorch
-
[34]
Make the output contiguous if needed
-
[35]
Flatten to numel(), launch 1D grid with mask (offs < n)
-
[36]
Pitfalls: .contiguous() can cost more than the tail
Fuse all pointwise ops before the final store. Pitfalls: .contiguous() can cost more than the tail
-
[37]
name: hoist invariant scalars out of kernel path←NEW description: Reduce overhead by hoisting invariant scalar/tensor params out of the hot kernel path. tags: [scalar hoisting, host overhead, fast path] --- ## Motivation A surprising amount of overhead comes from re-fetching tiny invariant scalars every call: clamp bounds, strides, shape constants. On sma...
-
[38]
Inspect constant params once in init
-
[39]
Convert scalar tensors to Python floats
-
[40]
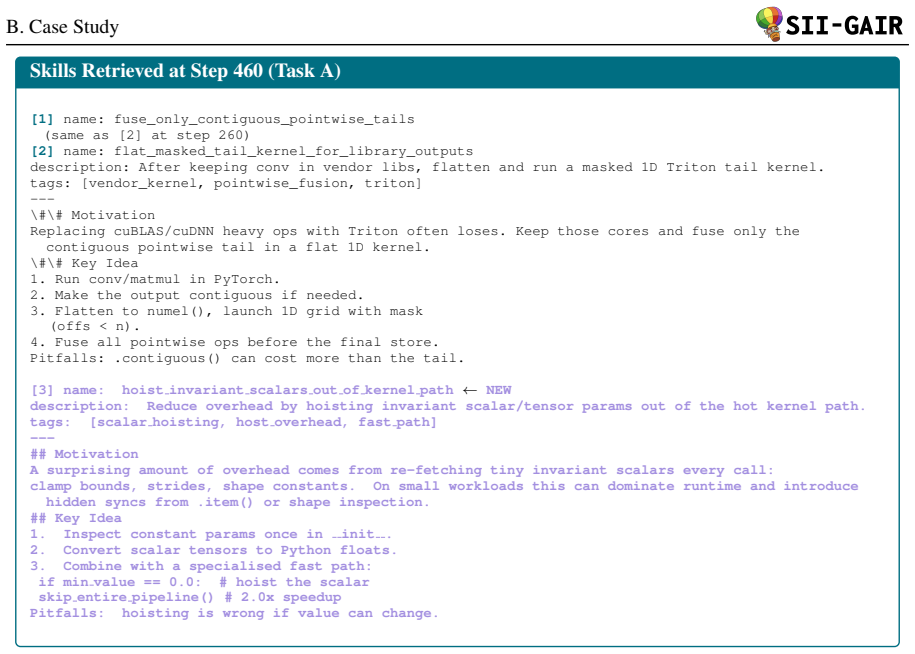
Combine with a specialised fast path: if min value == 0.0: # hoist the scalar skip entire pipeline() # 2.0x speedup Pitfalls: hoisting is wrong if value can change. Figure 5:Skill selection evolution on Task A a specific implementation idiom (flat-1D kernels for contiguous tails) substantially increase the fraction of samples producing valid, high-speedup...
-
[41]
Optionally call read_skill_files to inspect existing skills and avoid duplicates
-
[42]
Each skill body must contain: ## Motivation, ## Key Idea, ## Example (with code)
Call update_skill_library with at most {max_skills} new skill(s). Each skill body must contain: ## Motivation, ## Key Idea, ## Example (with code)
-
[43]
Rules: - Skills must be GENERAL (applicable beyond this specific task)
Your turn ends automatically after update_skill_library is called. Rules: - Skills must be GENERAL (applicable beyond this specific task). - Do NOT add task-specific hacks or solutions. - Respond in English only. Summary Agent user prompt (GPT series) ## Task {task_formatted} ## Existing Skills in Library ‘‘‘ {skill_library.get_file_tree()} ‘‘‘ ## Turn 1 ...
2000
-
[44]
A kernel optimization task (original PyTorch code + performance target). 15 C. System prompt SII-GAIR
-
[45]
use torch.compile
A numbered list of candidate optimization skills from the skill library. Each entry shows only the skill name, description, tags, and scope | NOT the full content. Your job: identify the top 3 skills most likely to help solve THIS specific task. ## Selection criteria - Relevance: the technique directly applies to the operator/pattern in the task. - Impact...
-
[46]
A kernel optimization task (original PyTorch code + performance target)
-
[47]
use torch.compile
A numbered list of candidate optimization skills from the skill library. Each entry shows only the skill name, description, tags, and scope | NOT the full content. Your job: identify the top __top_k_select__ skills most likely to help solve THIS specific task. ## Selection criteria - Relevance: the technique directly applies to the operator/pattern in the...
-
[48]
Ensures the inputs are contiguous on GPU
-
[49]
Calculates the grid (blocks) needed
-
[50]
"" assert x.is_cuda and y.is_cuda,
Launches the Triton kernel. """ assert x.is_cuda and y.is_cuda, "Tensors must be on CUDA." x = x.contiguous() y = y.contiguous() # Prepare output tensor out = torch.empty_like(x) # Number of elements in the tensor n_elements = x.numel() BLOCK_SIZE = 128 # Tunable parameter for block size # Determine the number of blocks needed grid = lambda meta: ((n_elem...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.