An Empirical Study of Security Calibration in Large Language Models for Code
Pith reviewed 2026-07-01 05:01 UTC · model grok-4.3
The pith
LLMs for code are overconfident, with calibration stronger for security outcomes than for functional correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
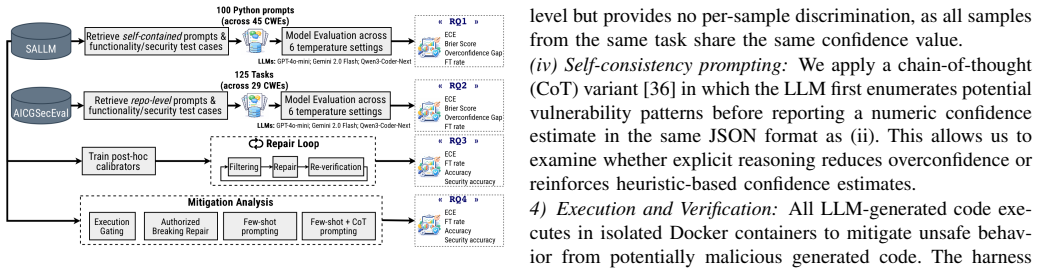
Overconfidence is prevalent across the evaluated LLMs. Functional calibration is consistently worse than security calibration, suggesting that models estimate security outcomes more reliably than functional correctness, potentially because functional correctness depends on complex execution behavior. Architectural gating improves calibration on controlled benchmarks but calibration deteriorates in realistic repository-level settings, increasing the risk of high-confidence vulnerable outputs.
What carries the argument
Security calibration versus functional calibration, quantified as the match between model-reported confidence and ground-truth outcomes on the two benchmark suites.
If this is right
- Calibration-guided repair produces only limited vulnerability fixes and frequently adds functional regressions.
- Architectural gating reduces false trust on controlled tasks but raises the rate of high-confidence vulnerable code in repository-level contexts.
- Models appear to estimate security outcomes more reliably than they estimate whether generated code will run correctly.
Where Pith is reading between the lines
- Developers using LLM confidence scores to decide whether to accept generated code may be accepting more functional risk than security risk.
- Calibration differences could be used to decide when to apply extra static analysis or testing before deployment.
- Training objectives that directly target functional execution traces might narrow the observed gap between the two calibration types.
Load-bearing premise
The two chosen benchmark suites give representative measures of both security vulnerabilities and functional correctness that extend to other code-generation tasks.
What would settle it
A follow-up evaluation on a different collection of security and functional tasks in which functional calibration matches or exceeds security calibration would undermine the central pattern reported.
Figures
read the original abstract
Large Language Models (LLMs) are rapidly transforming software development, yet their use in security-critical contexts raises a key question: do models know when their generated code is insecure? This property, known as calibration, measures whether a model's confidence aligns with the true correctness of its outputs. We present the first large-scale empirical study of security calibration in LLM-generated code. We evaluate GPT-4o-mini, Gemini-2.0-Flash, and Qwen3-Coder-Next across multiple temperature settings on two complementary benchmarks: self-contained security tasks and multi-language repository-level contexts. Our results suggest that overconfidence is prevalent across the evaluated LLMs. Functional calibration is consistently worse than security calibration, suggesting that models estimate security outcomes more reliably than functional correctness, potentially because functional correctness depends on complex execution behavior. We also examine whether calibration-guided automated repair can help remediate vulnerabilities in LLM-generated code, finding only limited improvements while frequently introducing functional regressions. Moreover, we study different mitigation strategies for reducing False Trust, where models assign high confidence to vulnerable code. The results show that although architectural gating improves calibration on controlled benchmarks, calibration deteriorates in realistic repository-level settings, increasing the risk of high-confidence vulnerable outputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first large-scale empirical study of security calibration in LLM-generated code. It evaluates GPT-4o-mini, Gemini-2.0-Flash, and Qwen3-Coder-Next across temperature settings on two benchmarks (self-contained security tasks and multi-language repository-level contexts), reporting prevalent overconfidence, consistently better security calibration than functional calibration, limited gains from calibration-guided repair (with frequent functional regressions), and deterioration of mitigation strategies like architectural gating when moving from controlled to realistic repository settings.
Significance. If the results hold, the work provides actionable evidence that LLMs tend to be overconfident about insecure code and that security self-assessment is more reliable than functional correctness assessment. This has direct implications for safe deployment of code-generating LLMs in security-critical contexts and motivates further research on calibration-aware generation and repair techniques.
major comments (2)
- [Evaluation Setup / Benchmarks] The central claims (prevalent overconfidence; security calibration reliably superior to functional) rest on the accuracy of ground-truth labels for vulnerability presence and functional correctness in the two benchmarks. The abstract and evaluation description provide no details on sample sizes, labeling procedures (automated vs. manual), inter-rater reliability, or error rates; without these, the reported calibration gap could be an artifact of noisy or non-representative labels rather than a model property.
- [Repair Experiments] The claim that calibration-guided automated repair yields "only limited improvements" while "frequently introducing functional regressions" requires quantitative support on the magnitude of regressions and the baseline repair success rate. The abstract does not report effect sizes, statistical significance, or controls for temperature and model, making it impossible to judge whether the limited benefit is robust.
minor comments (2)
- [Abstract] The abstract states results "suggest" overconfidence and a calibration gap; the manuscript should clarify whether these are statistically tested differences or descriptive observations.
- [Models] Model names (Qwen3-Coder-Next, Gemini-2.0-Flash) should be accompanied by exact version identifiers and access dates to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the positive assessment of the work's significance. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation Setup / Benchmarks] The central claims (prevalent overconfidence; security calibration reliably superior to functional) rest on the accuracy of ground-truth labels for vulnerability presence and functional correctness in the two benchmarks. The abstract and evaluation description provide no details on sample sizes, labeling procedures (automated vs. manual), inter-rater reliability, or error rates; without these, the reported calibration gap could be an artifact of noisy or non-representative labels rather than a model property.
Authors: We agree that the abstract and high-level evaluation description omit explicit details on labeling methodology, which is a valid concern for assessing label quality. The full manuscript describes the two benchmarks and their sources but does not dedicate sufficient space to sample sizes, automated vs. manual procedures, inter-rater metrics, or measured error rates. In the revised version we will add a dedicated subsection in the evaluation setup that reports these elements (including exact sample counts per benchmark, the static analysis tools employed, the size and protocol of any manual verification, and any available reliability statistics). This addition will directly address the possibility of label noise affecting the observed calibration differences. revision: yes
-
Referee: [Repair Experiments] The claim that calibration-guided automated repair yields "only limited improvements" while "frequently introducing functional regressions" requires quantitative support on the magnitude of regressions and the baseline repair success rate. The abstract does not report effect sizes, statistical significance, or controls for temperature and model, making it impossible to judge whether the limited benefit is robust.
Authors: We accept that the abstract summarizes the repair outcomes at a high level without the requested quantitative details. The full results section already breaks down repair success and regression rates by model and temperature, but does not include effect sizes or formal significance tests. In the revision we will augment the repair experiment subsection with effect-size calculations, statistical significance results, and explicit confirmation that all comparisons control for temperature and model. These additions will provide the quantitative support needed to evaluate the robustness of the "limited improvements" and "functional regressions" findings. revision: yes
Circularity Check
Empirical measurement study with no derivations or self-referential reductions
full rationale
The paper is a large-scale empirical evaluation of calibration in three LLMs across two benchmarks, reporting observed overconfidence rates, security-vs-functional differences, and mitigation outcomes. No equations, fitted parameters, uniqueness theorems, or ansatzes are presented as deriving new results; all claims rest on direct experimental measurements. The central findings (prevalent overconfidence; security calibration better than functional) are statistical summaries of the collected data rather than reductions to prior self-citations or input definitions. Benchmark labeling assumptions are external validity concerns, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected benchmarks accurately reflect real-world security vulnerabilities and functional correctness.
Reference graph
Works this paper leans on
-
[1]
Security in the age of ai teammates: An empirical study of agentic pull requests on github,
M. L. Siddiq, X. Zhao, V . C. Lopes, B. Casey, and J. C. S. Santos, “Security in the age of ai teammates: An empirical study of agentic pull requests on github,” 2026, under-review in Information and Software Technology
2026
-
[2]
An empirical study of code smells in transformer-based code generation techniques,
M. L. Siddiq, S. H. Majumder, M. R. Mim, S. Jajodia, and J. C. S. Santos, “An empirical study of code smells in transformer-based code generation techniques,” in2022 IEEE 22nd International Working Con- ference on Source Code Analysis and Manipulation (SCAM), 2022, pp. 71–82
2022
-
[3]
Asleep at the keyboard? assessing the security of github copilot’s code contributions,
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri, “Asleep at the keyboard? assessing the security of github copilot’s code contributions,” vol. 68, no. 2, Jan. 2025, p. 96–105. [Online]. Available: https://doi.org/10.1145/3610721
-
[4]
Do users write more insecure code with ai assistants?
N. Perry, M. Srivastava, D. Kumar, and D. Boneh, “Do users write more insecure code with ai assistants?” inProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’23, 2023, p. 2785–2799. [Online]. Available: https://doi.org/10.1145/3576915.3623157
-
[5]
Lost at c: A user study on the security implications of large language model code assistants,
G. Sandoval, H. Pearce, T. Nys, R. Karri, S. Garg, and B. Dolan-Gavitt, “Lost at c: A user study on the security implications of large language model code assistants,” in32nd USENIX Security Symposium (USENIX Security 23), 2023, pp. 2205–2222
2023
-
[6]
Sallm: Security assessment of generated code,
M. L. Siddiq, J. C. da Silva Santos, S. Devareddy, and A. Muller, “Sallm: Security assessment of generated code,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering Workshops, ser. ASEW ’24, 2024, p. 54–65. [Online]. Available: https://doi.org/10.1145/3691621.3694934
-
[7]
Truthfulqa: Measuring how models mimic human falsehoods,
S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how models mimic human falsehoods,” inProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), 2022, pp. 3214–3252
2022
-
[8]
2025.LLMs Meet Library Evolution: Evaluating Deprecated API Usage in LLM-Based Code Completion
C. Spiess, D. Gros, K. S. Pai, M. Pradel, M. R. I. Rabin, A. Alipour, S. Jha, P. Devanbu, and T. Ahmed, “Calibration and correctness of language models for code,” inProceedings of the IEEE/ACM 47th International Conference on Software Engineering, ser. ICSE ’25, 2025, p. 540–552. [Online]. Available: https://doi.org/10.1109/ICSE55347.2025.00040
-
[9]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, and C. Sutton, “Program synthesis with large language models,” 2021. [Online]. Available: https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
SWE-bench: Can language models resolve real- world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “SWE-bench: Can language models resolve real- world github issues?” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https: //openreview.net/forum?id=VTF8yNQM66
2024
-
[12]
A.s.e: A repository-level benchmark for evaluating security in ai-generated code,
K. Lian, B. Wang, L. Zhang, L. Chen, J. Wang, Z. Zhao, Y . Yang, M. Lin, H. Duan, H. Zhaoet al., “A.s.e: A repository-level benchmark for evaluating security in ai-generated code,” 2025. [Online]. Available: https://arxiv.org/abs/2508.18106
-
[13]
S. Ullah, M. Han, S. Pujar, H. Pearce, A. Coskun, and G. Stringhini, “LLMs cannot reliably identify and reason about security vulnera- bilities (yet?): A comprehensive evaluation, framework, and bench- marks,” inIEEE Symposium on Security and Privacy (SP), 2024, arXiv:2312.12575
-
[14]
On the definition of appropriate trust and the tools that come with it,
H. Löfström, “On the definition of appropriate trust and the tools that come with it,” in2023 Congress in Computer Science, Computer Engineering, & Applied Computing (CSCE). IEEE, 2023, pp. 1555– 1562
2023
-
[15]
Cyberseceval 2: A wide-ranging cybersecurity evaluation suite for large language models,
M. Bhatt, S. Chennabasappa, Y . Li, C. Nikolaidis, D. Song, S. Wan, F. Ahmad, C. Aschermann, Y . Chen, D. Kapilet al., “Cyberseceval 2: A wide-ranging cybersecurity evaluation suite for large language models,” Tech. Rep., 2024
2024
-
[16]
SafeGenBench: A benchmark framework for security vulnerability detection in LLM-generated code,
X. Li, J. Ding, C. Peng, B. Zhao, X. Gao, H. Gao, and X. Gu, “SafeGenBench: A benchmark framework for security vulnerability detection in LLM-generated code,”arXiv preprint arXiv:2506.05692, 2025
-
[17]
Obtaining well calibrated probabilities using bayesian binning,
M. P. Naeini, G. Cooper, and M. Hauskrecht, “Obtaining well calibrated probabilities using bayesian binning,” inProceedings of the AAAI conference on artificial intelligence, vol. 29, no. 1, 2015
2015
-
[18]
Verification of forecasts expressed in terms of probability,
W. B. Glennet al., “Verification of forecasts expressed in terms of probability,”Monthly weather review, vol. 78, no. 1, pp. 1–3, 1950
1950
-
[19]
OpenAI, “GPT-4 technical report,” OpenAI, Tech. Rep., 2024. [Online]. Available: https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Y . Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. D. Lago, T. Hubert, P. Choy, C. de Masson d’Autume, I. Babuschkin, X. Chen, P.-S. Huang, J. Welbl, S. Gowal, A. Cherepanov, J. Molloy, D. J. Mankowitz, E. S. Robson, P. Kohli, N. de Freitas, K. Kavukcuoglu, and O. Vinyals, “Competition-level code gene...
-
[21]
How Secure is Code Generated by ChatGPT?
R. Khoury, A. R. Avila, J. Brunelle, B. M. Coutureet al., “How secure is code generated by chatgpt?”arXiv preprint arXiv:2304.09655, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
M. L. Siddiq and J. C. S. Santos, “Securityeval dataset: mining vulnerability examples to evaluate machine learning-based code generation techniques,” inProceedings of the 1st International Workshop on Mining Software Repositories Applications for Privacy and Security, ser. MSR4P&S 2022, 2022, p. 29–33. [Online]. Available: https://doi.org/10.1145/3549035.3561184
-
[23]
CWE Top 25 Most Dangerous Software Weaknesses,
MITRE Corporation, “CWE Top 25 Most Dangerous Software Weaknesses,” 2023. [Online]. Available: https://cwe.mitre.org/top25/
2023
-
[24]
Understanding software vulnerabilities related to archi- tectural security tactics: An empirical investigation of chromium, php and thunderbird,
J. C. Santos, A. Peruma, M. Mirakhorli, M. Galstery, J. V . Vidal, and A. Sejfia, “Understanding software vulnerabilities related to archi- tectural security tactics: An empirical investigation of chromium, php and thunderbird,” in2017 IEEE International Conference on Software Architecture (ICSA). IEEE, 2017, pp. 69–78
2017
-
[25]
Codelm- sec benchmark: Systematically evaluating and finding security vulnera- bilities in black-box code language models,
H. Hajipour, K. Hassler, T. Holz, L. Schönherr, and M. Fritz, “Codelm- sec benchmark: Systematically evaluating and finding security vulnera- bilities in black-box code language models,” inSecond IEEE Conference on Secure and Trustworthy Machine Learning, 2024
2024
-
[26]
Re(Gex|DoS)eval: Evaluating generated regular expressions and their proneness to dos attacks,
M. L. Siddiq, J. Zhang, L. Roney, and J. C. Santos, “Re(Gex|DoS)eval: Evaluating generated regular expressions and their proneness to dos attacks,” inProceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineering: New Ideas and Emerging Results, 2024, pp. 52–56
2024
-
[27]
How can we know when language models know? on the calibration of language models for question answering,
Z. Jiang, J. Araki, H. Ding, and G. Neubig, “How can we know when language models know? on the calibration of language models for question answering,”Transactions of the Association for Computational Linguistics, vol. 9, pp. 962–977, 2021. [Online]. Available: https://aclanthology.org/2021.tacl-1.57/
2021
-
[28]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inInternational conference on machine learning. PMLR, 2017, pp. 1321–1330
2017
-
[29]
Mea- suring calibration in deep learning,
J. Nixon, M. W. Dusenberry, L. Zhang, G. Jerfel, and D. Tran, “Mea- suring calibration in deep learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Work- shops, June 2019
2019
-
[30]
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods,
J. Plattet al., “Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods,” Tech. Rep. 3, 1999
1999
-
[31]
Predicting good probabilities with supervised learning,
A. Niculescu-Mizil and R. Caruana, “Predicting good probabilities with supervised learning,” inProceedings of the 22nd international conference on Machine learning, 2005, pp. 625–632
2005
-
[32]
Language Models (Mostly) Know What They Know
S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, N. Schiefer, Z. Hatfield-Dodds, N. DasSarma, E. Tran-Johnsonet al., “Language models (mostly) know what they know,”arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
L. Kuhn, Y . Gal, and S. Farquhar, “Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,” arXiv preprint arXiv:2302.09664, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Teaching models to express their uncertainty in words,
S. Lin, J. Hilton, and O. Evans, “Teaching models to express their uncertainty in words,”Transactions on Machine Learning Research, 2022. [Online]. Available: https://openreview.net/forum?id= 8s8K2UZGTZ
2022
-
[35]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback,
K. Tian, E. Mitchell, A. Zhou, A. Sharma, R. Rafailov, H. Yao, C. Finn, and C. Manning, “Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds., Dec....
2023
-
[36]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdh- ery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” 2022
2022
-
[37]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inProceedings of the 36th International Conference on Neural Information Processing Systems, ser. NIPS ’22, 2022
2022
-
[38]
Calibration of pre-trained transformers,
S. Desai and G. Durrett, “Calibration of pre-trained transformers,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), B. Webber, T. Cohn, Y . He, and Y . Liu, Eds., Nov. 2020, pp. 295–302. [Online]. Available: https://aclanthology.org/2020.emnlp-main.21/
2020
-
[39]
Toward trustworthy neural program synthesis,
D. Key, W.-D. Li, and K. Ellis, “Toward trustworthy neural program synthesis,” 2023. [Online]. Available: https://arxiv.org/abs/2210.00848
-
[40]
On calibration of pre-trained code models,
Z. Zhou, C. Sha, and X. Peng, “On calibration of pre-trained code models,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ser. ICSE ’24, 2024. [Online]. Available: https://doi.org/10.1145/3597503.3639126
-
[41]
J. Liu, C. S. Xia, Y . Wang, and L. Zhang, “Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,”arXiv preprint arXiv:2305.01210, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
GPT-4o-mini Technical Overview,
OpenAI, “GPT-4o-mini Technical Overview,” https://openai.com, 2024, accessed February 2026
2024
-
[43]
Gemini Technical Report,
Google DeepMind, “Gemini Technical Report,” https://ai.google.dev, 2024, gemini-2.0-Flash API, accessed February 2026
2024
-
[44]
Qwen3-coder-next technical report,
Qwen Team, “Qwen3-coder-next technical report,” Tech. Rep., accessed: 2026-02-03. [Online]. Available: https://github.com/QwenLM/ Qwen3-Coder/blob/main/qwen3_coder_next_tech_report.pdf
2026
-
[45]
Breaking the silence: the threats of using llms in software engineering,
J. Sallou, T. Durieux, and A. Panichella, “Breaking the silence: the threats of using llms in software engineering,” inProceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineering: New Ideas and Emerging Results, ser. ICSE-NIER’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 102–106. [Online]. Available: htt...
-
[46]
Classifier calibration with roc- regularized isotonic regression,
E. Berta, F. Bach, and M. Jordan, “Classifier calibration with roc- regularized isotonic regression,” inInternational Conference on Artificial Intelligence and Statistics. PMLR, 2024, pp. 1972–1980
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.